
【分布式存储】HDFS
https://hadoop.apache.org/docs/r1.0.4/cn/hdfs_design.html
HDFS(Hadoop Distributed File System )Hadoop分布式文件系统。是根据google发表的论文翻版的。论文为GFS(Google File System)Google 文件系统
设计前提和目标:
硬件错误、
流式数据访问、
大规模数据集:运行在HDFS上的应用具有很大的数据集。HDFS上的一个典型文件大小一般都在G字节至T字节。因此,HDFS被调节以支持大文件存储。它应该能提供整体上高的数据传输带宽,能在一个集群里扩展到数百个节点。一个单一的HDFS实例应该能支撑数以千万计的文件。
简单的一致性模型:HDFS应用需要一个“一次写入多次读取”的文件访问模型。一个文件经过创建、写入和关闭之后就不需要改变。这一假设简化了数据一致性问题,并且使高吞吐量的数据访问成为可能。
架构:
HDFS采用master/slave架构。一个HDFS集群是由一个Namenode和一定数目的Datanodes组成。
Namenode是一个中心服务器,负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。集群中的Datanode一般是一个节点一个,负责管理它所在节点上的存储。HDFS暴露了文件系统的名字空间,用户能够以文件的形式在上面存储数据。
从内部看,一个文件其实被分成一个或多个数据块,这些块存储在一组Datanode上。Namenode执行文件系统的名字空间操作,比如打开、关闭、重命名文件或目录。它也负责确定数据块到具体Datanode节点的映射。Datanode负责处理文件系统客户端的读写请求。在Namenode的统一调度下进行数据块的创建、删除和复制。
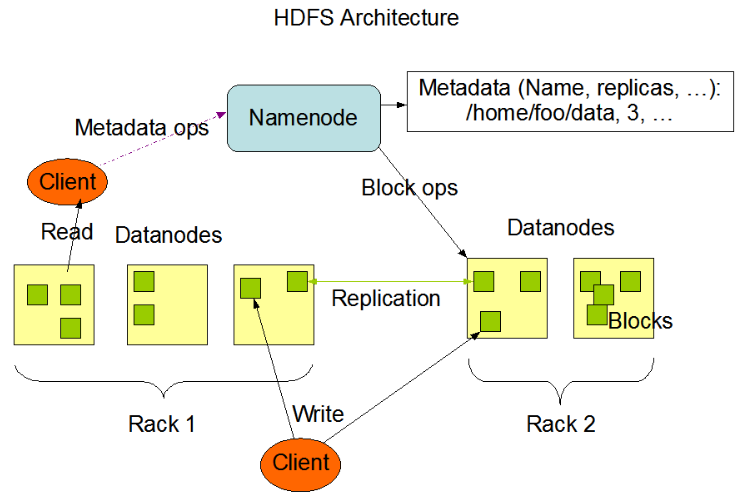
数据块
HDFS被设计成支持大文件,适用HDFS的是那些需要处理大规模的数据集的应用。这些应用都是只写入数据一次,但却读取一次或多次,并且读取速度应能满足流式读取的需要。HDFS支持文件的“一次写入多次读取”语义。一个典型的数据块大小是64MB。因而,HDFS中的文件总是按照64M被切分成不同的块,每个块尽可能地存储于不同的Datanode中。
Staging:
客户端创建文件的请求其实并没有立即发送给Namenode,事实上,在刚开始阶段HDFS客户端会先将文件数据缓存到本地的一个临时文件。应用程序的写操作被透明地重定向到这个临时文件。当这个临时文件累积的数据量超过一个数据块的大小,客户端才会联系Namenode。Namenode将文件名插入文件系统的层次结构中,并且分配一个数据块给它。然后返回Datanode的标识符和目标数据块给客户端。接着客户端将这块数据从本地临时文件上传到指定的Datanode上。当文件关闭时,在临时文件中剩余的没有上传的数据也会传输到指定的Datanode上。然后客户端告诉Namenode文件已经关闭。此时Namenode才将文件创建操作提交到日志里进行存储。如果Namenode在文件关闭前宕机了,则该文件将丢失。
文件的删除和恢复
当用户或应用程序删除某个文件时,这个文件并没有立刻从HDFS中删除。实际上,HDFS会将这个文件重命名转移到/trash目录。只要文件还在/trash目录中,该文件就可以被迅速地恢复。文件在/trash中保存的时间是可配置的,当超过这个时间时,Namenode就会将该文件从名字空间中删除。删除文件会使得该文件相关的数据块被释放。注意,从用户删除文件到HDFS空闲空间的增加之间会有一定时间的延迟。如果用户想恢复被删除的文件,他/她可以浏览/trash目录找回该文件。/trash目录仅仅保存被删除文件的最后副本。/trash目录与其他的目录没有什么区别,除了一点:在该目录上HDFS会应用一个特殊策略来自动删除文件。目前的默认策略是删除/trash中保留时间超过6小时的文件。将来,这个策略可以通过一个被良好定义的接口配置。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律
2022-12-31 【单元测试】Mockito
2022-12-31 【单元测试】jUnit框架
2022-12-31 【单元测试】SpringRunner执行原理
2022-12-31 【单元测试】基础理论