

【数据库优化】分库分表
参考:
亲历7年之变:一个单数据库架构演进史 https://www.sohu.com/a/733465509_411876 // 历史数据迁移,异构数据库
256变4096:分库分表扩容如何实现平滑数据迁移? https://blog.csdn.net/ok449a6x1i6qq0g660fV/article/details/114311628?spm=1001.2014.3001.5502
23讲搞定后台架构实战:分库分表章节(P9/) https://www.bilibili.com/video/BV1j24y1z7TS?p=9&vd_source=898d5514be58985430a49b46d5500c13
软件架构场景实战 22 讲: 分表分库:单表数据量大读写缓慢如何解决? https://www.bilibili.com/video/BV1jA411k7eG?p=5&vd_source=898d5514be58985430a49b46d5500c13
支持10X增长,携程机票订单库Sharding实践 https://cloud.tencent.com/developer/article/2021321 // 详细阅读,生产成功经验
分库分表:中间件方案对比 https://developer.aliyun.com/article/885876
理论:
垂直分库:按业务逻辑拆库,比如用户数据、商品数据、订单数据部署单独的数据库
垂直分表:不常用且占了大量空间的列拆分出去, [ID、name、age、sex],[ID、nickname、description]
水平分表:
分库分表注意点:
1、数据倾斜问题:
一个良好的分库分表方案,它的数据应该是需要比较均匀的分散在各个库表中的
反面:
a、某个数据库实例中,部分表的数据很多,而其他表中的数据却寥寥无几,业务上的表现经常是延迟忽高忽低,飘忽不定。
b、数据库集群中,部分集群的磁盘使用增长特别块,而部分集群的磁盘增长却很缓慢。每个库的增长步调不一致,这种情况会给后续的扩容带来步调不一致,无法统一操作的问题。
最大数据偏斜率为 :(数据量最大样本 - 数据量最小样本)/ 数据量最小样本。一般来说,如果我们的最大数据偏斜率在5%以内是可以接受的。
一、分库
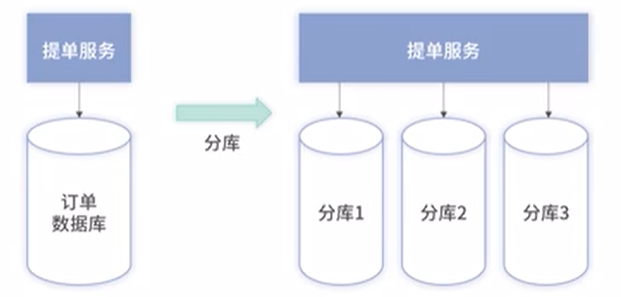
分库带来的问题:
1、分库数据间的数据无法通过数据库直接查询
2、分库越多,出现问题的可能性越大,维护成本也越高
3、事务问题:无法保障跨库间事务,只能借助其他中间件实现最终一致性
如何选择分库维度:
不同的分库维度决定部分查询是否能直接使用数据库 及 是否存在数据倾斜的问题
1、按直接满足最重要的业务场景划分
下面可能存在数据倾斜问题,比如超级用户,订单量大
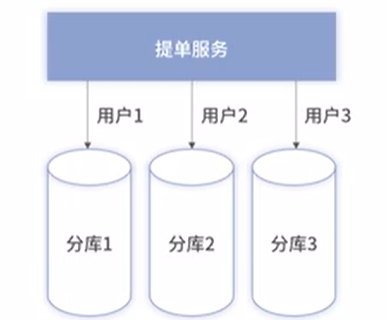
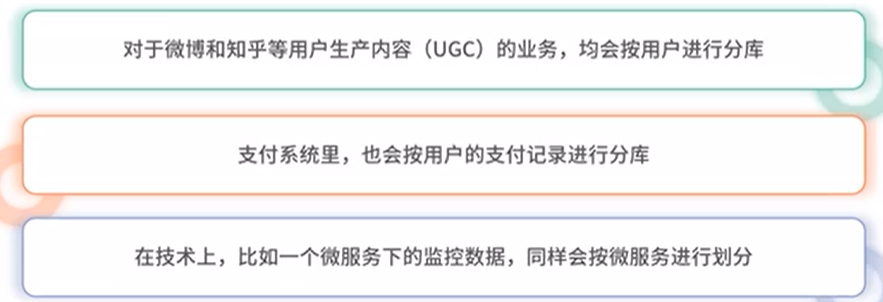
2、按最细粒度拆分
针对订单,唯一标识是订单号。基于订单号分库,用户订单按hash随机均匀分散到某个分库
针对微博:按用户每条微博随机分库
支付系统:按用户的每笔支付记录随机分库
带来的问题:
1、除细粒度查询外,其他任何维度查询均不支持;2)对于防重逻辑在数据库层面无法支持
没有一种方案可以解决所有问题,更多根据场景选择更适合的方案
二、分表
所有数据在同一个数据库实例。只是将原先一个大表按一定规则,划分成多个行数少的表
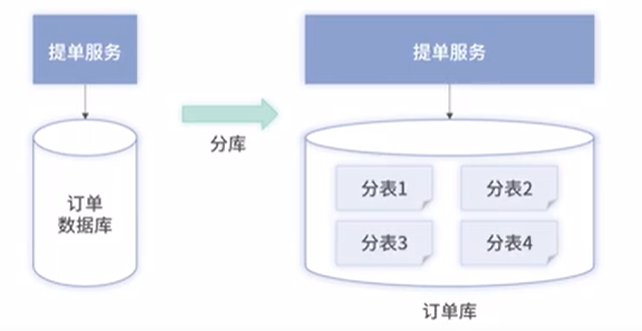
分表解决分库带来的3个问题:
1、分表后可以通过join等完成一个富查询,相对分库简单的多
2、分表的数据仍存在一个数据库,不会出现很多分库;无需引入分库中间件,因为维护和开发成本均低
3、同一个数据库,很好解决事务问题
单表进行切分后,是否要将切分后的多个表分散在不同的数据库服务器中,根据切分效果来确定,并不强制要求单表切分为多表后一定要分散到不同数据库中。原因在于单表切分为多表后,新的表即使在同一个数据库服务器中,也可能带来可观的性能提升,如果性能能够满足业务要求,是可以不拆分到多台数据库服务器的
水平分表复杂性
1、路由问题
1) 范围路由range
2) Hash:缺点是扩充新表麻烦
3)配置路由:建立一个独立的表记录路由信息,user_router;
优点:扩容时只迁移指定数据,并修改路由表
缺点:多查询一次,如果路由表太大一样需分库分表,继续面临路由算法问题
2、join操作
需要与其他表进行join查询,需要在业务代码或者数据库中间件中进行多次join查询,然后将结果合并。
3、count()操作
方案1:每个表都count()再相加,性能低
方案2:记录数表,新建表(tableName,rouCount),每次插入或删除子表数据成功后,更新;
缺点:1)针对“记录数表”的操作和针对子表的操作无法放在同一事务中进行处理,异常的情况下会出现操作子表成功了而操作记录数表失败,同样会导致数据不一致。
2)增加了数据库的写压力。
对于一些不要求记录数实时保持精确的业务,可以通过后台定时更新记录数表。
4、order_by操作:只能由业务代码或者数据库中间件分别查询每个子表中的数据,然后汇总进行排序
假设订单只是单量多,而每一单数据量较少,就适合分表
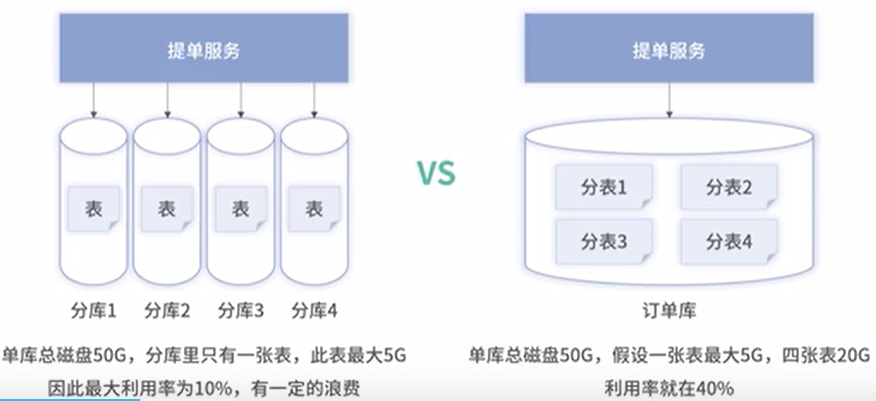
常见分库分表方案
https://www.cnblogs.com/vivotech/p/15457635.html
1、Range分库分表
通过数据的范围进行分库分表,该方案是最朴实的一种分库方案,它也可以和其他分库分表方案灵活结合使用。
下面我们看看该方案的缺点:
-
a、最明显的就是数据热点问题,例如上面案例中的订单表,很明显当前年度所在的库表属于热点数据,需要承载大部分的IO和计算资源。
-
b、新库和新表的追加问题。一般我们线上运行的应用程序是没有数据库的建库建表权限的,故我们需要提前将新的库表提前建立,防止线上故障。
表序号 = Hash(userId) % 表数量 + 起始表编号
int hash = userId.hashCode(); // 对库数量取余结果为库序号 int dbIdx = Math.abs(hash % DB_CNT); // 对表数量取余结果为表序号 int tblIdx = Math.abs(hash % TBL_CNT);
上述方案是初次使用者特别容易进入的误区,用Hash值分别对分库数和分表数取余,得到库序号和表序号。其实稍微思索一下,我们就会发现,以10库100表为例,如果一个Hash值对100取余为0,那么它对10取余也必然为0。
这就意味着只有0库里面的0表才可能有数据,而其他库中的0表永远为空!
类似的我们还能推导到,0库里面的共100张表,只有10张表中(个位数为0的表序号)才可能有数据。这就带来了非常严重的数据偏斜问题,因为某些表中永远不可能有数据,最大数据偏斜率达到了无穷大。
那么是不是只要库数量和表数量互质就可用用这种分库分表方案呢?比如我用11库100表的方案,是不是就合理了呢?
答案是否定的,我们除了要考虑数据偏斜的问题,还需要考虑可持续性扩容的问题,一般这种Hash分库分表的方案后期的扩容方式都是通过翻倍扩容法,那11库翻倍后,和100又不再互质。
常见错误案例二:扩容难以持续
我们把10库100表看成总共1000个逻辑表,将求得的Hash值对1000取余,得到一个介于[0,999)中的数,然后再将这个数二次均分到每个库和每个表中,大概逻辑代码如下:

public static ShardCfg shard(String userId) { // ① 算Hash int hash = userId.hashCode(); // ② 总分片数 int sumSlot = DB_CNT * TBL_CNT; // ③ 分片序号 int slot = Math.abs(hash % sumSlot); // ④ 计算库序号和表序号的错误案例 int dbIdx = slot % DB_CNT ; int tblIdx = slot / DB_CNT ; return new ShardCfg(dbIdx, tblIdx); }
但是该方案有个比较大的问题,那就是在计算表序号的时候,依赖了总库的数量,那么后续翻倍扩容法进行扩容时,会出现扩容前后数据不在同一个表中,从而无法实施。
结合一些实际场景案例介绍几种Hash分库分表的方案。
常用姿势一:标准的二次分片法
public static ShardCfg shard2(String userId) { // ① 算Hash int hash = userId.hashCode(); // ② 总分片数 int sumSlot = DB_CNT * TBL_CNT; // ③ 分片序号 int slot = Math.abs(hash % sumSlot); // ④ 重新修改二次求值方案 int dbIdx = slot / TBL_CNT ; int tblIdx = slot % TBL_CNT ; return new ShardCfg(dbIdx, tblIdx); }
【方案缺点】
1、翻倍扩容法前期操作性高,但是后续如果分库数已经是大几十的时候,每次扩容都非常耗费资源。
2、连续的分片键Hash值大概率会散落在相同的库中,某些业务可能容易存在库热点(例如新生成的用户Hash相邻且递增,且新增用户又是高概率的活跃用户,那么一段时间内生成的新用户都会集中在相邻的几个库中)。
常用姿势二:关系表冗余
我们可以将分片键对应库的关系通过关系表记录下来,我们把这张关系表称为"路由关系表"。
常用姿势三:基因法
常见扩容方案
https://www.cnblogs.com/vivotech/p/15457635.html
4.1 翻倍扩容法
4.2 一致性Hash扩容
分库中间件
https://developer.aliyun.com/article/885876
1、代理式(MyCAT/Sharding-proxy)
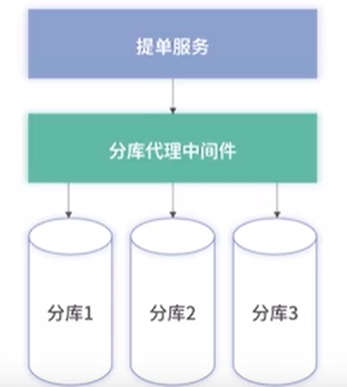
核心原理是在应用和数据库的连接之间搭起一个代理层,上层应用以标准的MySQL协议来连接代理层,然后代理层负责转发请求到底层的MySQL物理实例,这种方式对应用只有一个要求,就是只要用MySQL协议来通信即可,所以用MySQL Workbench这种纯的客户端都可以直接连接你的分布式数据库,自然也天然支持所有的编程语言。
在技术实现上除了和应用层依赖类中间件基本相似外,代理类的分库分表产品必须实现标准的MySQL协议,某种意义上讲数据库代理层转发的就是MySQL协议请求,就像Nginx转发的是Http协议请求。
上述无论哪种类型的产品,除了实现分库分表这一主要功能外,都会额外实现一些其他很有实用价值的功能,比如读写分离、负载均衡等。
存在的问题:
1、在业务和数据库间增加了一层,导致性能下降
2、需解析业务应用的SQL,并根据SQL中分库字段进行路由
3、单独进程,需部署占用资源,带来一定成本
2、内嵌式(Sharding Jdbc、TDDL)
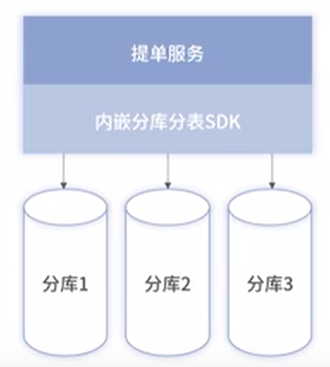
就是重新实现JDBC的API,通过重新实现DataSource、PrepareStatement等操作数据库的接口,让应用层在基本(注意:这里用了基本)不改变业务代码的情况下透明地实现分库分表的能力。
中间件给上层应用提供熟悉的JDBC API,内部通过sql解析、sql重写、sql路由等一系列的准备工作获取真正可执行的sql,然后底层再按照传统的方法(比如数据库连接池)获取物理连接来执行sql,最后把数据结果合并处理成ResultSet返回给应用层。
存在问题:
1、有一定侵入性,业务应用和原始单库模式相对,需进行一定改造是适配内嵌式的API
2、分库在故障转移、数据迁移等运维工作时,需业务应用感知
ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(计划中)这3款相互独立的产品组成。 他们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如Java同构、异构语言、容器、云原生等各种多样化的应用场景。
Sharding-JDBC: 定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
- 适用于任何基于Java的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
- 基于任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
- 支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer和PostgreSQL。
Sharding-Proxy:定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持。 目前先提供MySQL版本,它可以使用任何兼容MySQL协议的访问客户端(如:MySQL Command Client, MySQL Workbench等)操作数据,对DBA更加友好。
- 向应用程序完全透明,可直接当做MySQL使用。
- 适用于任何兼容MySQL协议的客户端。
常见问题应对策略:
1、是否一定要分库或分表?
不一定,90%以上系统发展到百万、千万数据量已经不错了。当数据量增长到一定量级后,可在业务层面做些处理
2、使用业务字段分库后,如何处理数据倾斜?
如果数据量不是特别大,可在分库基础上,再进行分表
3、如何满足富查询
引入ES
4、如何解决跨多库的修改导致的分布式事务?
5、跨分片查询


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 一文读懂知识蒸馏
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
2021-05-16 【性能调优】Arthas