

【分布式】日志链路追踪
参考: https://zhuanlan.zhihu.com/p/619861742
https://tech.meituan.com/2022/07/21/visualized-log-tracing.html 美团:可视化全链路日志追踪(传统方案ELK + 分布式会话链路追踪)
https://tech.meituan.com/tags/%E6%97%A5%E5%BF%97.html
https://tech.meituan.com/2018/01/15/satellite-system.html 美团MTrace
https://blog.csdn.net/ByteDanceTech/article/details/122076591?spm=1001.2014.3001.5501 字节的实现
https://cloud.tencent.com/developer/article/2418783 解锁潜在价值,智行日志治理的实践之路
业界:阿里Eagle Eye、Twitter的Zipkin
传统方案:基于日志的ELK方案
日志作为业务系统的必备能力,职责就是记录程序运行期间发生的离散事件,并且在事后阶段用于程序的行为分析,比如曾经调用过什么方法、操作过哪些数据等等。
在分布式系统中,ELK技术栈已经成为日志收集和分析的通用解决方案。伴随着业务逻辑的执行,业务日志会被打印,统一收集并存储至Elasticsearch(下称ES)。
传统的ELK方案需要开发者在编写代码时尽可能全地打印日志,再通过关键字段从ES中搜集筛选出与业务逻辑相关的日志数据,进而拼凑出业务执行的现场信息。然而该方案存在如下的痛点:
- 日志搜集繁琐:虽然ES提供了日志检索的能力,但是日志数据往往是缺乏结构性的文本段,很难快速完整地搜集到全部相关的日志。
- 日志筛选困难:不同业务场景、业务逻辑之间存在重叠,重叠逻辑打印的业务日志可能相互干扰,难以从中筛选出正确的关联日志。
- 日志分析耗时:搜集到的日志只是一条条离散的数据,只能阅读代码,再结合逻辑,由人工对日志进行串联分析,尽可能地还原出现场。
综上所述,随着业务逻辑和系统复杂度的攀升,传统的ELK方案在日志搜集、日志筛选和日志分析方面愈加的耗时耗力,很难快速实现对业务的追踪。
传统的ELK方案是一种滞后的业务追踪,需要事后从大量离散的日志中搜集和筛选出需要的日志,并人工进行日志的串联分析,其过程必然耗时耗力。
分布式会话跟踪方案
为了解决复杂链路排查困难的问题,“分布式会话跟踪方案”诞生。该方案的理论知识由Google在2010年《Dapper》论文[3]中发表,随后Twitter开发出了一个开源版本Zipkin。
Google Dapper通过一个分布式全局唯一的id(即traceId),将分布在各个服务节点上的同一次请求串联起来,还原调用关系、追踪系统问题、分析调用数据、统计系统指标。
分布式会话跟踪,是一种会话级别的追踪能力,如下图2所示,单个分布式请求被还原成一条调用链路,从客户端发起请求抵达系统的边界开始,记录请求流经的每一个服务,直到向客户端返回响应为止。
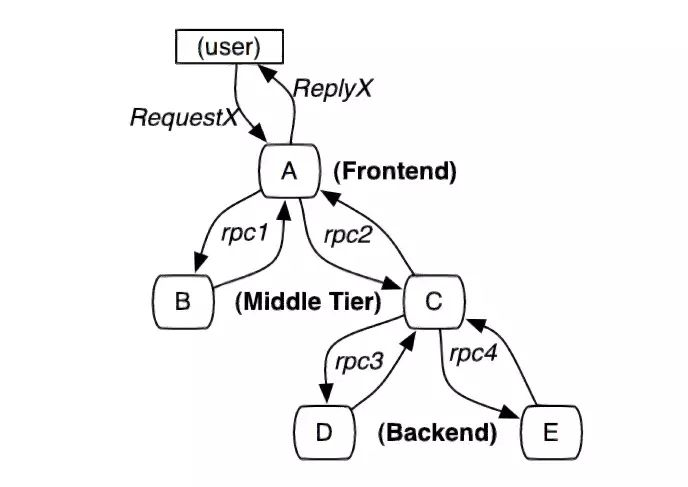
基于链路标识 TraceId 的筛选
- 前端请求 Header 或响应体 Response:大部分用户请求都是在端上设备发起的,因此 TraceId 生成的最佳地点也是在端上设备,通过请求 Header 透传给后端服务。因此,我们在通过浏览器开发者模式调试时,就可以获取当前测试请求 Header 中的 TraceId 进行筛选。如果端上设备没有接入分布式链路追踪埋点,也可以将后端服务生成的 TraceId 添加到 Response 响应体中返回给前端。这种方式非常适合前后端联调场景,可以快速找到每一次点击对应的 TraceId,进而分析行为背后的链路轨迹与状态。
- 网关日志:网关是所有用户请求发往后端服务的代理中转站,可以视为后端服务的入口。在网关的 access.log 访问日志中添加 TraceId,可以帮助我们快速分析每一次异常访问的轨迹与原因。比如一个超时或错误请求,到底是网关自身的原因,还是后端某个服务的原因,可以通过调用链中每个 Span 的状态得到确定性的结论。
- 应用日志:应用日志可以说是我们最熟悉的一种日志,我们会将各种业务或系统的行为、中间状态和结果,在开发编码的过程中顺手记录到应用日志中,使用起来非常方便。同时,它也是可读性最强的一类日志,即使是非开发运维人员也能大致理解应用日志所表达的含义。因此,我们可以将 TraceId 也记录到应用日志中进行关联,一旦出现某种业务异常,我们可以先通过当前应用的日志定位到报错信息,再通过关联的 TraceId 去追溯该应用上下游依赖的其他信息,最终定位到导致问题出现的根因节点。
- 组件日志:在分布式系统中,大部分应用都会依赖一些外部组件,比如数据库、消息、配置中心等等。这些外部组件也会经常发生这样或那样的异常,最终影响应用服务的整体可用性。但是,外部组件通常是共用的,有专门的团队进行维护,不受应用 Owner 的控制。因此,一旦出现问题,也很难形成有效的排查回路。此时,我们可以将 TraceId 透传给外部组件,并要求他们在自己的组件日志中进行关联,同时开放组件日志查询权限。举个例子,我们可以通过 SQL Hint 传播链 TraceId,并将其记录到数据库服务端的 Binlog 中,一旦出现慢 SQL 就可以追溯数据库服务端的具体表现,比如一次请求记录数过多,查询语句没有建索引等等。
分布式会话跟踪的主要作用是分析分布式系统的调用行为,并不能很好地应用于业务逻辑的追踪。
下图3是一个审核业务场景的追踪案例,业务系统对外提供审核能力,待审对象的审核需要经过“初审”和“复审”两个环节(两个环节关联相同的taskId),因此整个审核环节的执行调用了两次审核接口。如图左侧所示,完整的审核场景涉及众多“业务逻辑”的执行,而分布式会话跟踪只是根据两次RPC调用生成了右侧的两条调用链路,并没有办法准确地描述审核场景业务逻辑的执行,问题主要体现在以下几个方面:
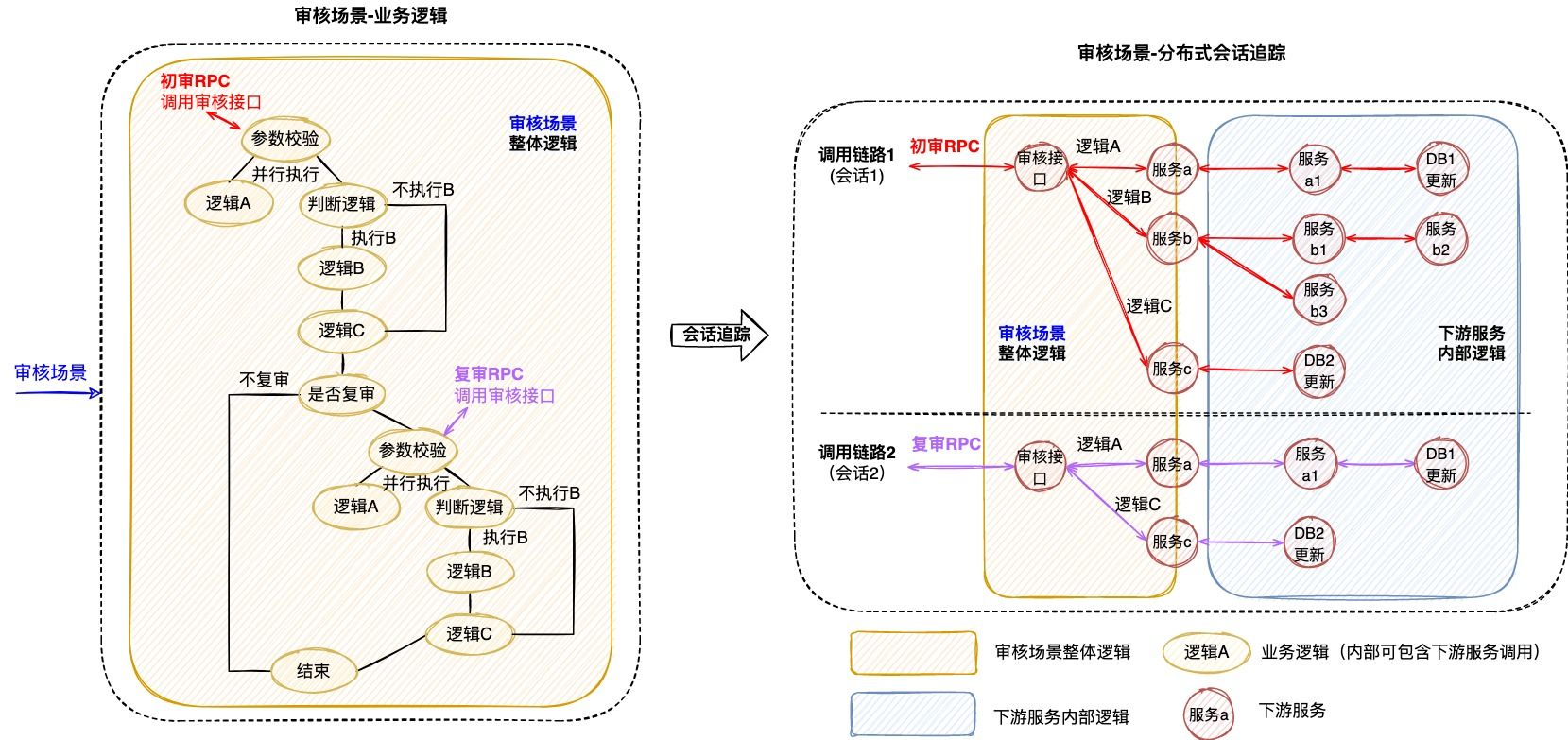
- 无法同时追踪多条调用链路:分布式会话跟踪仅支持单个请求的调用追踪,当业务场景包含了多个调用时,将生成多条调用链路;由于调用链路通过traceId串联,不同链路之间相互独立,因此给完整的业务追踪增加了难度。例如当排查审核场景的业务问题时,由于初审和复审是不同的RPC请求,所以无法直接同时获取到2条调用链路,通常需要额外存储2个traceId的映射关系。
- 无法准确描述业务逻辑的全景:分布式会话跟踪生成的调用链路,只包含单次请求的实际调用情况,部分未执行的调用以及本地逻辑无法体现在链路中,导致无法准确描述业务逻辑的全景。例如同样是审核接口,初审链路1包含了服务b的调用,而复审链路2却并没有包含,这是因为审核场景中存在“判断逻辑”,而该逻辑无法体现在调用链路中,还是需要人工结合代码进行分析。
- 无法聚焦于当前业务系统的逻辑执行:分布式会话跟踪覆盖了单个请求流经的所有服务、组件、机器等等,不仅包含当前业务系统,还涉及了众多的下游服务,当接口内部逻辑复杂时,调用链路的深度和复杂度都会明显增加,而业务追踪其实仅需要聚焦于当前业务系统的逻辑执行情况。例如审核场景生成的调用链路,就涉及了众多下游服务的内部调用情况,反而给当前业务系统的问题排查增加了复杂度。
而分布式会话跟踪方案则是在调用执行的同时,实时地完成了链路的动态串联,但由于是会话级别且仅关注于调用关系等问题,导致其无法很好地应用于业务追踪。
既然 TraceId 关联有这么多的好处,那么我们如何在日志输出时添加 TraceId 呢?主要有两种方式:
- 基于 SDK 手动埋点:链路透传的每个节点都可以获取当前调用生命周期内的上下文信息。最基础的关联方式就是通过 SDK 来手动获取 TraceId,将其作为参数添加至业务日志的输出中。
- 生成调用上下文;
- 同步调用上下文存放在ThreadLocal, 异步调用通过显式调用API的方式支持;
- 网络中传输关键埋点数据,用于中间件间的数据传递,支持Thrift, HTTP协议。
- 基于日志模板自动埋点:如果一个存量应用有大量日志需要关联 TraceId,一行行的修改代码添加 TraceId 的改造成本属实有点高,也很难被执行下去。因此,比较成熟的 Tracing 实现框架会提供一种基于日志模板的自动埋点方式,无需修改业务代码就可以在业务日志中批量注入 TraceId,使用起来极为方便。-- MDC
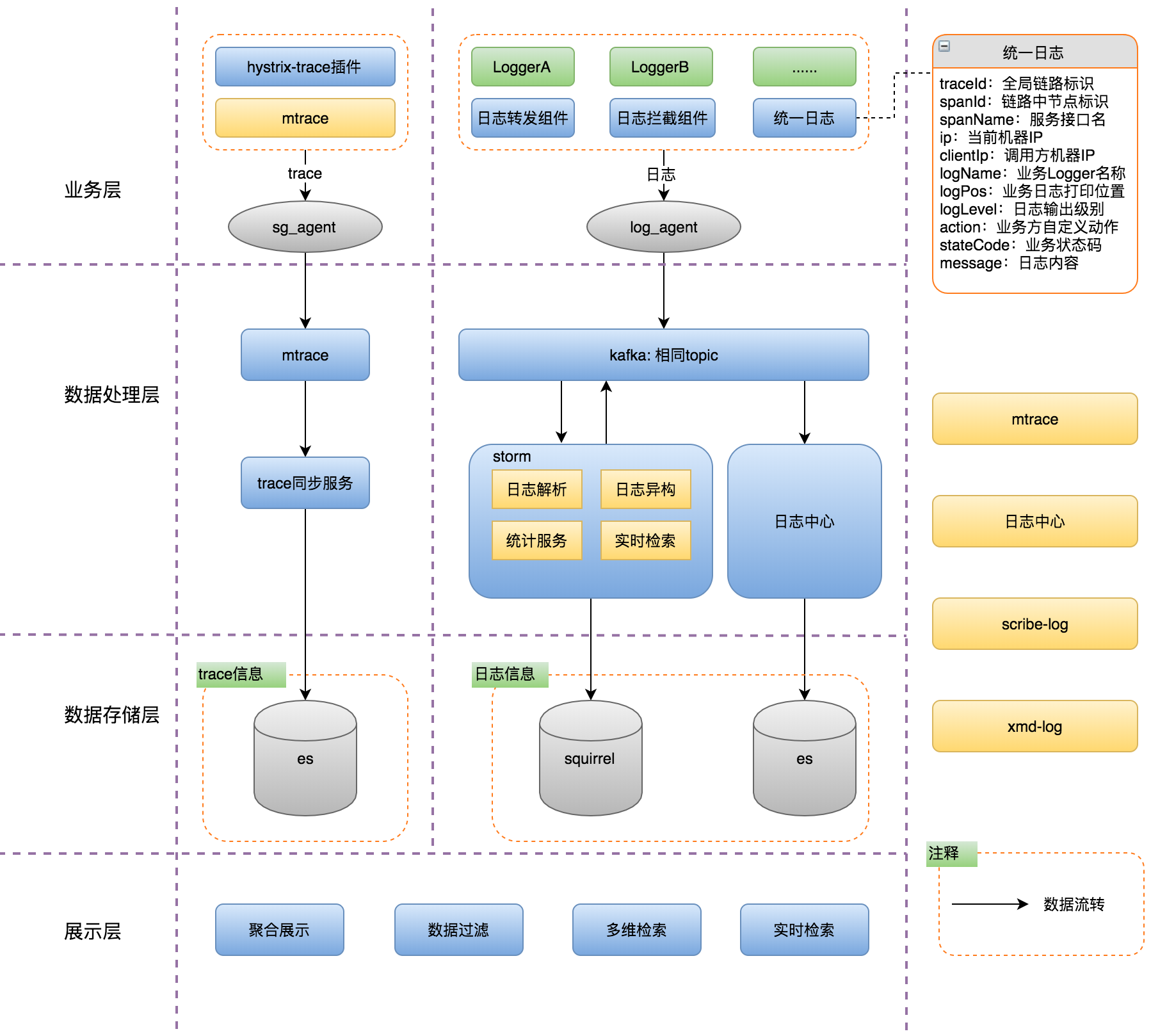
美团:可视化全链路日志追踪
参考:https://tech.meituan.com/2022/07/21/visualized-log-tracing.html
美团:卫星系统——酒店后端全链路日志收集工具介绍


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)
2020-04-11 【性能调优】CPU&内存&Core分析
2018-04-11 【Maven】
2018-04-11 【设计图绘制】