

【ELK】Logstatsh & FileBeat
Logstash:Data 转换,分析,提取,丰富及核心操作: https://blog.csdn.net/UbuntuTouch/article/details/100770828
Beats家族(如FileBeat)参考:
ES官方博客:Beats 入门教程 https://elasticstack.blog.csdn.net/article/details/104432643
ES官方博客:如何使用 Filebeat 将 MySQL 日志发送到 Elasticsearch https://elasticstack.blog.csdn.net/article/details/103954935
Filebeat和Logstash的关系
- Logstash:基于JVM,资源消耗比较大,
- Filebeat:Golang
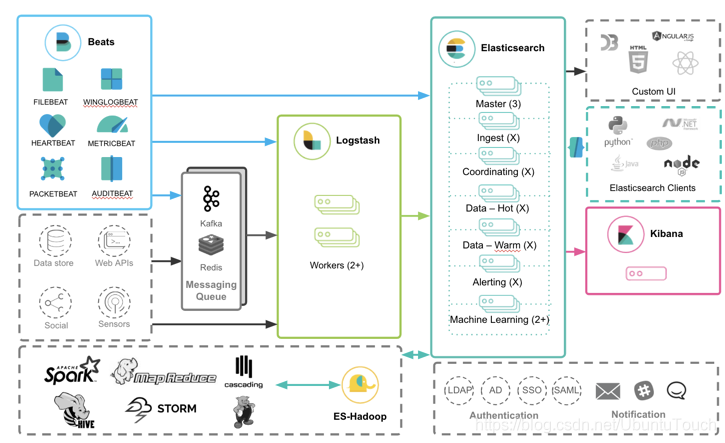
Beats如何和其它的 Elastic Stack 一起工作
见下图:Beats 的数据可以有如下的三种方式导入到 Elasticsearch 中:
-
- Beats ==> Elasticsearch:直接把 Beats 的数据传入到 Elasticsearch 中,甚至在现在的很多情况中,这也是一种比较受欢迎的一种方案。它甚至可以结合 Elasticsearch 所提供的 pipeline 一起完成更为强大的组合。
- Beats ==> Logstash ==> Elasticsearch:利用 Logstash 所提供的强大的filter组合对数据流进行处理:解析,丰富,转换,删除,添加等等。 参考 https://elasticstack.blog.csdn.net/article/details/116754424
- Beats ==> Kafka ==> Logstash ==> Elasticsearch:如果数据流具有不确定性,比如可能在某个时刻生产大量的数据,从而导致 Logstash 不能及时处理,我们可以通过 Kafka 或者 Redis 做为 Messaging Queue 来做一个缓存。参考 https://elasticstack.blog.csdn.net/article/details/117426436
Filebeat 是用于转发和集中日志数据的轻量级传送程序。 作为服务器上的代理安装,Filebeat 监视你指定的日志文件或位置,收集日志事件,并将它们转发到 Elasticsearch 或 Logstash 以进行索引
Filebeat 具有如下的一些特性:
- 正确处理日志旋转:针对每隔一个时间段生产一个新的日志的案例,Filebeat 可以帮我们正确地处理新生产的日志,并重新启动对新生成日志的处理
- 背压敏感:如果日志生成的速度过快,从而导致 Filebeat 生产的速度超过 Elasticsearch 处理的速度,那么 Filebeat 可以自动调节处理的速度,以达到 Elasticsearch 可以处理的范围内
- “至少一次”保证:每个日志生成的事件至少被处理一次
- 结构化日志:可以处理结构化的日志数据数据
- 多行事件:如果一个日志有多行信息,也可以被正确处理,比如错误信息往往是多行数据
- 条件过滤:可以有条件地过滤一些事件
Filebeat 的工作方式:
启动 Filebeat 时,它将启动一个或多个输入,这些输入将在为日志数据指定的位置中查找。 对于 Filebeat 所找到的每个日志,Filebeat 都会启动收集器(havester)。 每个收割机都读取一个日志以获取新内容,并将新日志数据发送到 libbeat。libbeat 会汇总事件,并将汇总的数据发送到为 Filebeat 配置的输出。
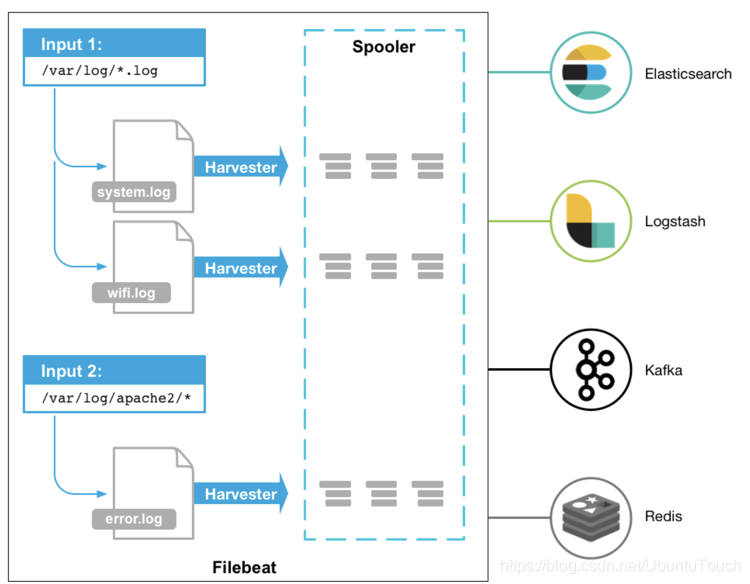
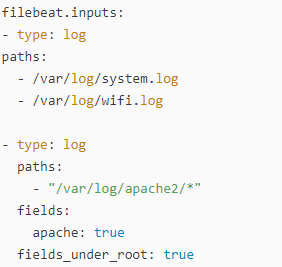
从上面有可以看出来在 spooler 里有一些缓存,这个可以用于重新发送以确保至少一次的事件消费,同时也可以用于背压敏感。一旦 Filebeat 生成的事件的速度超过 Elasticsearch 能够处理的极限,这个缓存可以用于存储一些事件。每个 Filebeat 可以配置多个 input,并且每个 input 可以配置来采集一个或多个文件路径的文件。 就像上面的图显示的那样,Filebeat 支持多种输入方式。你可以在 Filebeat 的配置文件 filebeat.yml 中进行多次的配置:
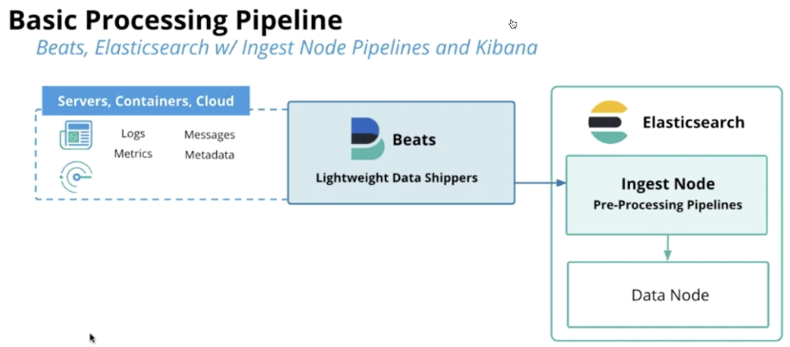
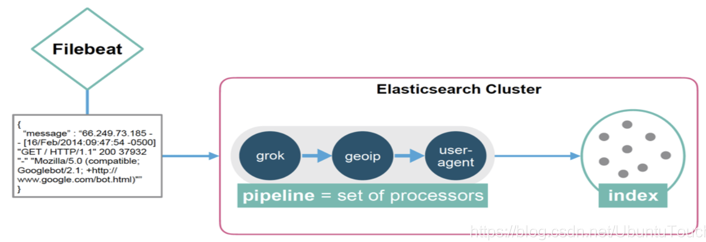
Ingest Line:它提供了在对文档建立索引之前对其进行预处理的功能:
- 解析,转换并丰富数据
- 管道允许你配置将要使用的处理器
Filebeat 的构成
Filebeat结构:由两个组件构成,分别是inputs(输入)和harvesters(收集器),这些组件一起工作来跟踪文件并将事件数据发送到您指定的输出,
- harvester:负责读取单个文件的内容。harvester逐行读取每个文件,并将内容发送到输出。为每个文件启动一个harvester。harvester负责打开和关闭文件,这意味着文件描述符在harvester运行时保持打开状态。如果在收集文件时删除或重命名文件,Filebeat将继续读取该文件。这样做的副作用是,磁盘上的空间一直保留到harvester关闭。默认情况下,Filebeat保持文件打开,直到达到close_inactive。
关闭harvester可以会产生的结果:
-
- 文件处理程序关闭,如果harvester仍在读取文件时被删除,则释放底层资源。
- 只有在scan_frequency结束之后,才会再次启动文件的收集。
- 如果该文件在harvester关闭时被移动或删除,该文件的收集将不会继续。
- input:负责管理harvesters和寻找所有来源读取。如果input类型是log,则input将查找驱动器上与定义的路径匹配的所有文件,并为每个文件启动一个harvester。每个input在它自己的Go进程中运行,Filebeat当前支持多种输入类型。每个输入类型可以定义多次。日志输入检查每个文件,以查看是否需要启动harvester、是否已经在运行harvester或是否可以忽略该文件。
Filebeat如何保存文件的状态
Filebeat保留每个文件的状态,并经常将状态刷新到磁盘中的注册表文件中。该状态用于记住harvester读取的最后一个偏移量,并确保发送所有日志行。如果无法访问输出(如Elasticsearch或Logstash),Filebeat将跟踪最后发送的行,并在输出再次可用时继续读取文件。当Filebeat运行时,每个输入的状态信息也保存在内存中。当Filebeat重新启动时,来自注册表文件的数据用于重建状态,Filebeat在最后一个已知位置继续每个harvester。对于每个输入,Filebeat都会保留它找到的每个文件的状态。由于文件可以重命名或移动,文件名和路径不足以标识文件。对于每个文件,Filebeat存储唯一的标识符,以检测文件是否以前被捕获。
Filebeat何如保证至少一次数据消费
Filebeat保证事件将至少传递到配置的输出一次,并且不会丢失数据。是因为它将每个事件的传递状态存储在注册表文件中。在已定义的输出被阻止且未确认所有事件的情况下,Filebeat将继续尝试发送事件,直到输出确认已接收到事件为止。
如果Filebeat在发送事件的过程中关闭,它不会等待输出确认所有事件后再关闭。
当Filebeat重新启动时,将再次将Filebeat关闭前未确认的所有事件发送到输出。这样可以确保每个事件至少发送一次,但最终可能会有重复的事件发送到输出。通过设置shutdown_timeout选项,可以将Filebeat配置为在关机前等待特定时间。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)