
【ELK】检索效率优化
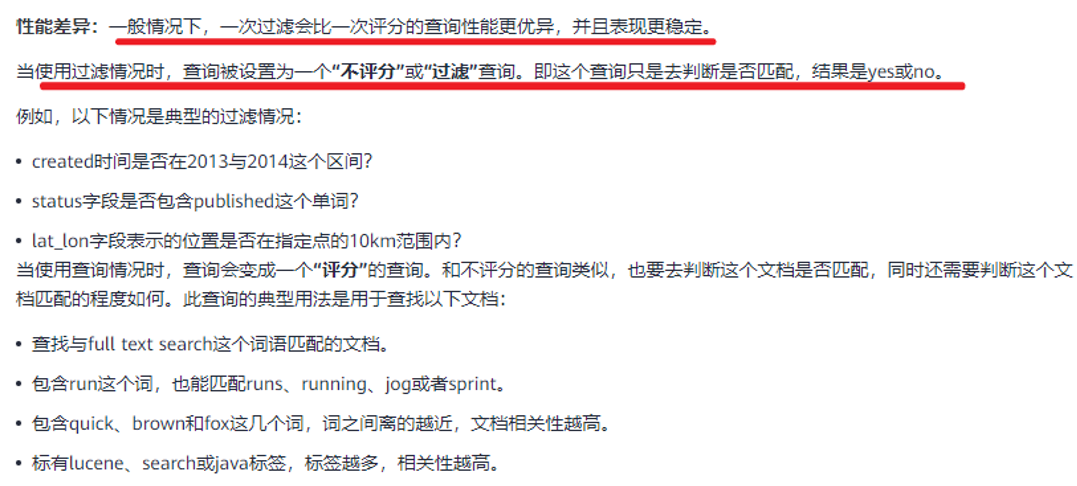
查询(query)与过滤(filter)的区别
如下为检索优化方案(部分内容有重复)
https://www.elastic.co/guide/en/elasticsearch/reference/current/tune-for-indexing-speed.html
使用bulk请求

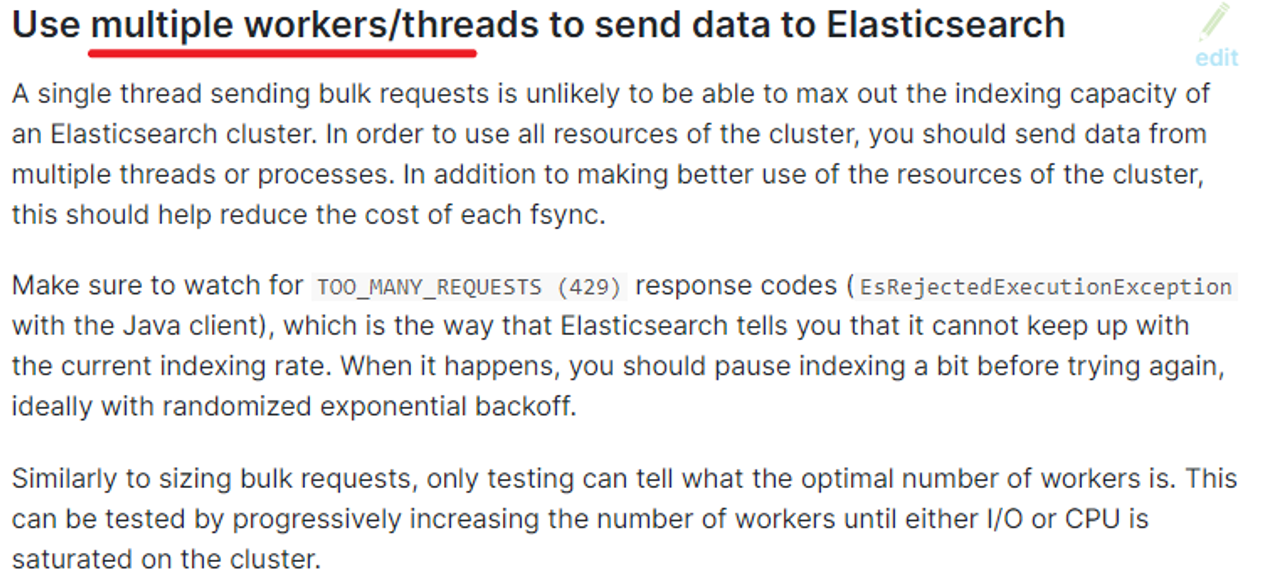
使用多线程发送数据
使用自增id

优化索引性能

优化检索性能

优化索引配置

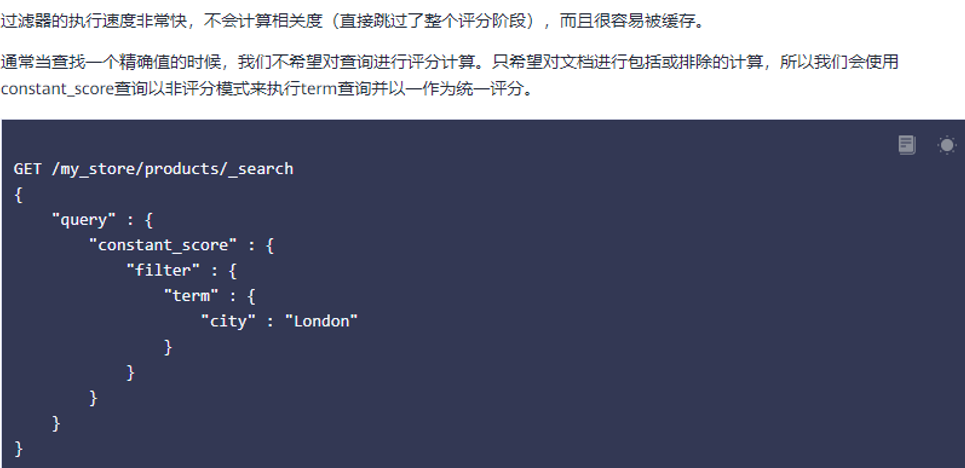
用过滤提高查询效率
采用scroll API返回大量数据,不使用from+size
当返回大量数据时,先查后取的过程支持用from和size参数分页,但有限制。结果集在返回之前需要在每个分片上先进行排序,然后合并之后再排序输出。使用足够大的from值,排序过程可能会变得非常沉重,使用大量的CPU、内存和带宽。因此,强烈建议不要使用深分页。
为了避免深度翻页,推荐采用scroll查询返回大量数据。scroll查询可以用来对Elasticsearch有效地执行大批量的文档查询,而又不用付出深度分页那种代价。scroll查询允许我们先做查询初始化,然后再批量地拉取结果。
避免深分页查询
ES集群的分页查询支持from和size参数,查询的时候,每个分片必须构造一个长度为from+size的优先队列,然后回传到网关节点,网关节点再对这些优先队列进行排序找到正确的size个文档。
假设在一个有6个主分片的索引中,from为10000,size为10,每个分片必须产生10010个结果,在网关节点中汇聚合并60060个结果,最终找到符合要求的10个文档。
由此可见,当from足够大的时候,就算不发生OOM,也会影响到CPU和带宽等,从而影响到整个集群的性能。所以应该避免深分页查询,尽量不去使用。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 上周热点回顾(3.3-3.9)