
【单元测试】基础理论
https://martinfowler.com/articles/practical-test-pyramid.html
https://developer.aliyun.com/article/792515 Java编程技巧之单元测试用例编写流程
https://developer.51cto.com/article/708764.html 淘系用户平台技术团队单元测试建设
https://martinfowler.com/articles/mocksArentStubs.html
https://www.baeldung.com/mockito-series
https://www.yrunz.com/p/%E6%B7%B1%E5%85%A5%E7%90%86%E8%A7%A3%E5%8D%95%E5%85%83%E6%B5%8B%E8%AF%95/
阿里系列文章
5个关键问题让单元测试的价值最大化
https://zhuanlan.zhihu.com/p/649220598
Java编程技巧之单元测试用例编写流程
https://developer.aliyun.com/article/783992
如何写出有效的单元测试
https://developer.aliyun.com/article/1002205
5个编写技巧,有效提高单元测试实践
https://developer.aliyun.com/article/1081898
阿里是如何进行单元测试培训的?(附回放视频)
https://mp.weixin.qq.com/s/wzGxqNv58Zig9_Izi3VhDg
那些年,我们写过的无效单元测试
https://mp.weixin.qq.com/s/R4ZKWcB4TMFAiQlnIRqNeQJava单元测试技巧之JSON序列化
单元测试技巧之JSON序列化
https://developer.aliyun.com/article/796000
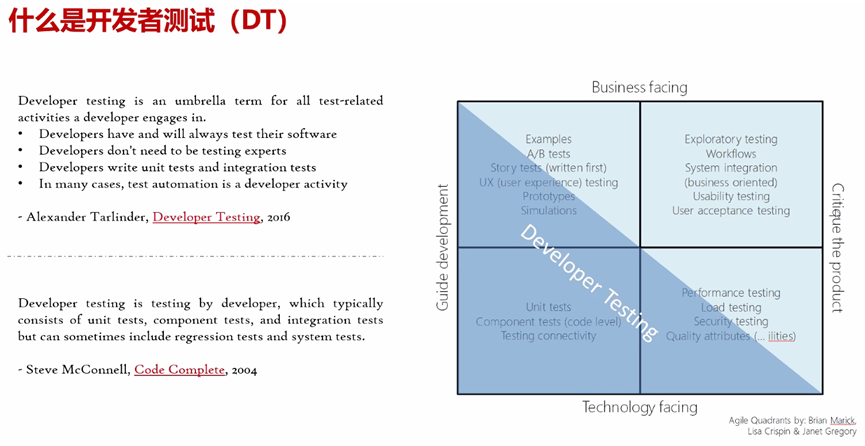
好单元测试的几个要点
摘自阿里巴巴开发规约:
l 单元测试必须遵守AIR原则,单元测试必须具备Automatic(自动化),Independent(独立性),Repeatable(可重复)性;
l 单元测试应该是全自动执行的,并且非交互式的。测试用例通常是被定期执行的,执行过程必须完全自动化才有意义。输出结果需要人工检查的测试不是一个好的单元测试;
l 单元测试要保证测试粒度足够小。单元测试测试粒度足够小,有助于精确定位问题。单测粒度至多是类级别,一般是方法级别;
l 单元测试要遵守BCDE原则,Border,边界值测试,包括循环边界、特殊取值、特殊时间点、数据顺序等;Correct,正确的输入,并得到预期的结果;Design,与设计文档相结合,来编写单元测试;Error,强制错误信息输入(如:非法数据、异常流程、非业务允许输入等),并得到预期的结果;
l 核心业务、核心应用、核心模块的增量代码要确保单元测试通过;
单元测试编码范式
这里主要以Mockito单元测试框架为模版
l Mock :通过when().thenReturn/thenAnswer/thenThrow 或者doReturn().when()等mock方式将依赖类方法进行模拟,模拟服务依赖或者中间结果。
l DO : 调用被测试类方法,执行测试链路。
l Verify : 校验执行结果正确性,通过Assert校验数据结果准确,通过Verify校验链路执行准确,通过expected=Exception.class校验异常链路。
单测要能报错
有些同学不喜欢用Assert,而喜欢在test case中写个System.out.println,人肉观察一下结果,确定结果是否正确。这种写法根本不是单测,原因是即使当时被测试代码是正确的,后续这些代码还有可能被修改,而一旦这些代码被改错了。println根本不会报错,测试正常通过只会带来虚假的自信心,这种所谓的"单测"连暴露错误的作用都起不到,根本就不应该存在。
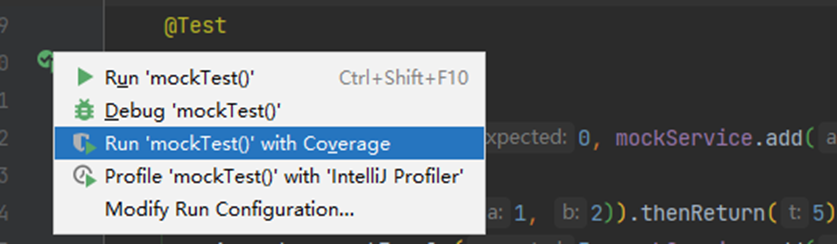
单测要有覆盖度(SUT)
IDEA支持覆盖度度量
强度是指单元测试中对结果的验证要全面,覆盖度则是指测试用例本身的设计要覆盖被测试程序(SUT, Sysem Under Test)尽可能多的逻辑。只有覆盖度和强度都比较高才能较好的实现单测的目的。
按照测试理论,SUT的覆盖度分为方法覆盖度,行覆盖度,分支覆盖度和组合分支覆盖度几类。不同的系统对单测覆盖度的要求不尽相同,但这是有底线的。一般来说,程序配套的 单测至少要达到>80%的方法覆盖以及>60%的行覆盖 ,才能起到"看门狗"的作用,也才是有维护价值的单测。
等价类划分可以帮助我们用更少的测试代码写出更高覆盖度的单测。 单元测试是典型的白盒测试 ,等价类的划分以及单元测试的编写最好都由SUT的编写者自己去完成,这样整体效率最高。
测试规则
-
FIRST
Fast:快速;测试执行越快越早发现问题
Isolated:独立,每个用例独立,没有依赖,从而可以并行甚至分布式执行;
Repeatable:可重复,每个用例不管执行多少次,执行结果一致,幂等;比如用例跟时间相关,可能结果不幂等。
Self-validation:自验证,测试用例必须告知断言结果,而不是人工判断,比如通过println打印。
Timely:及时,不要拖延
-
Right-BICEP
Right: 是否符合测试要求,验证待测试系统是否满足设计要求
Boundary:是否检测了所有边界行为
Inverse:是否需要反向检查,
Cross-checking:交叉检查,通过另一种方法对结果进行检查,比如需求的另一个解决方案
Error: 是否需要检查异常情况;如果异常是需要关注的,则需要覆盖异常路径;
Performance:是否需要检查性能,
-
CORRECT
Conformance:运行结果是否符合预期的规则
Ordering:值是否应该有序或无序
Range:结果在给定范围内是否符合预期
Reference:待测系统SUT是否正确引用了所依赖组件DOC
Existence:待测系统是否因关键要素存在性被影响,0-1-N问题
Cardinality:某些数值计算是否超出预期,如下标越界
Time:与时间相关的问题是否需要测试,比如耗时,并发问题
评估单元测试覆盖率
http://xunitpatterns.com/Test%20Double.html
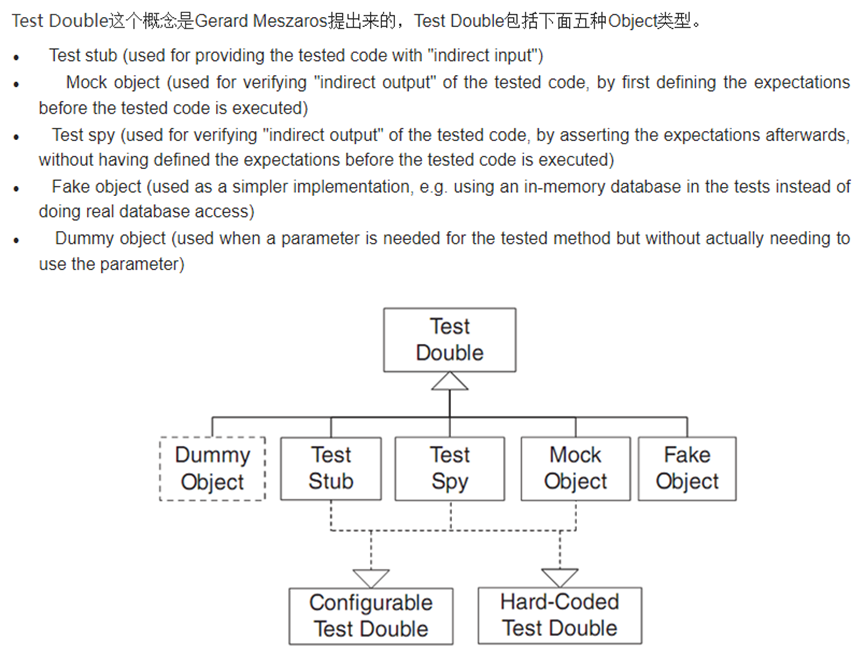
A stub has no logic, and only returns what you tell it to return.
A mock has expectations about the way it should be called, and a test should fail if it’s not called that way. Mocks are used to test interactions between objects, and are useful in cases where there are no other visible state changes or return results that you can verify (e.g. if your code reads from disk and you want to ensure that it doesn't do more than one disk read, you can use a mock to verify that the method that does the read is only called once).
A fake doesn’t use a mocking framework: it’s a lightweight implementation of an API that behaves like the real implementation, but isn't suitable for production


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 上周热点回顾(3.3-3.9)