
【Kafka】生产调优与面试题
Kafka万亿级消息实战!(包含各种业务应用场景举例) https://blog.51cto.com/u_15047392/4872419
上亿数据量下,Kafka是如何优化JVM GC问题的? https://blog.51cto.com/u_15009384/2566936
搞定这8个Kafka生产级容量评估,每日10亿+请求轻松拿捏 https://blog.csdn.net/weixin_70730532/article/details/125245222
Kafka在美团数据平台的实践 https://tech.meituan.com/2022/08/04/the-practice-of-kafka-in-the-meituan-data-platform.html
如何保证消息不丢失:多副本机制
如何保证消息处理有序:
如何保证不乱序:
消息存储结构:
如何保证百万级写入速度:
1、页缓存技术(PageCache) + 磁盘顺序写
2、零拷贝技术 sendFile
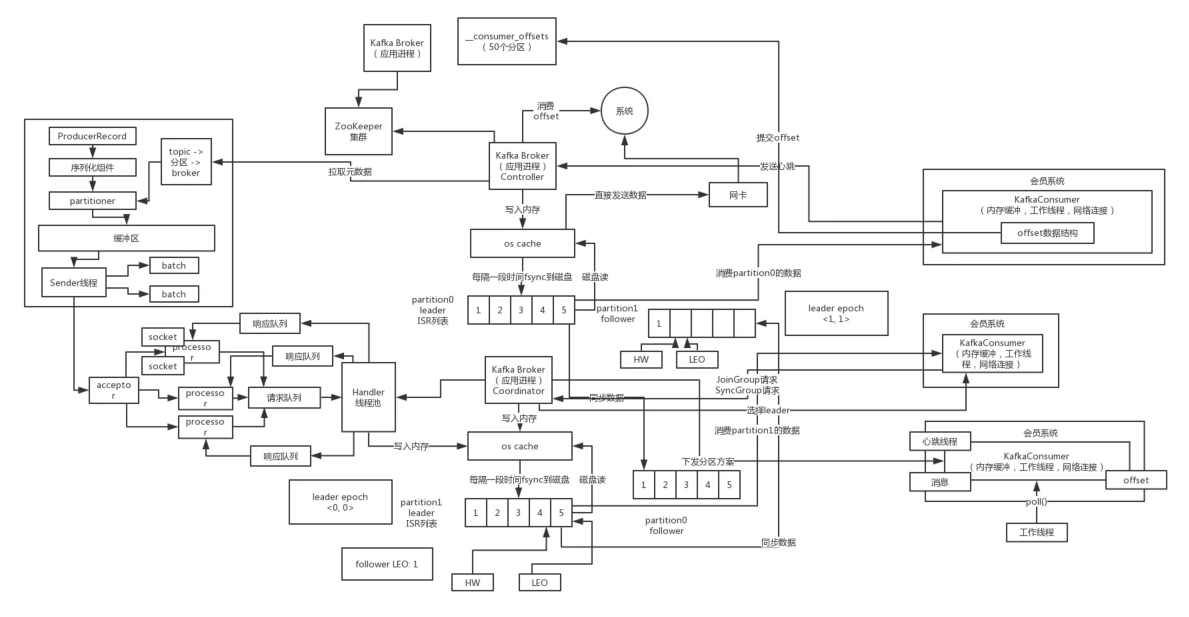
主从同步原理:
参考:https://blog.51cto.com/u_13270164/3062005
高可用:副本(Leader-》Follower机制)
ISR:
Kafka为什么不自己管理缓存,而非要用page cache?原因有如下三点:
- JVM中一切皆对象,数据的对象存储会带来所谓object overhead,浪费空间;
- 如果由JVM来管理缓存,会受到GC的影响,并且过大的堆也会拖累GC的效率,降低吞吐量;
- 一旦程序崩溃,自己管理的缓存数据会全部丢失。
Kafka底层原理之高吞吐、低延迟、零拷贝


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人