
【数据库】索引
参考:
https://mp.weixin.qq.com/s?__biz=MzI1MDU0MTc2MQ==&mid=2247484338&idx=1&sn=f753421c70f0e436c040af9e969c3331&chksm=e981e01cdef6690ae6e4bec7c92b436019f5f30e02f35524ca8e144a92b8aa743fc2c51d2c27#rd 用好MySQL索引,你必须知道的一些事情(极力推荐)
https://blog.csdn.net/xlgen157387/article/details/79572598 为什么你创建的数据库索引没有生效,索引失效的条件!
https://segmentfault.com/a/1190000021464570 一张图搞懂MySQL的索引失效
索引的存储格式
索引就是一棵B+树,每创建一个索引都需要创建一棵B+树,每一棵B+树的节点都是一个数据页,每一个数据页默认会占用16KB的磁盘空间,每一棵B+树又会包含许许多多的数据页。叶子节点包含真正数据
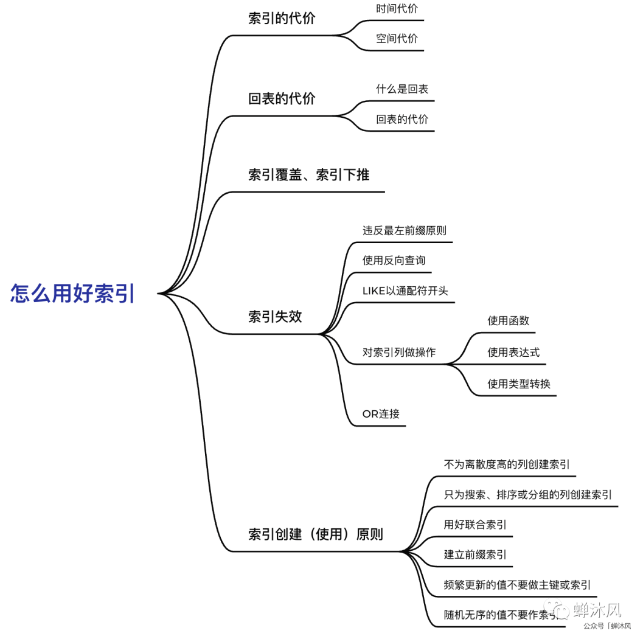
索引类型:
Hash索引:基于哈希表实现。哈希索引通过Hash算法(直接定址法、平方取中法、折叠法、除数取余法、随机数法)将数据库的索引列数据转换成定长的哈希码作为key,将这条数据的行的地址作为value一并存入Hash表的对应位置。
在MySQL中,只有Memeory引擎显式的支持哈希索引,
聚集和非聚集索引:不同存储引擎,myISAM,InnoDB
联合索引:
最左匹配原则,遇到范围会停止查找
https://www.cnblogs.com/rjzheng/p/12557314.html 按不同where场景掌握联合索引使用和执行原理
如下对属性 (a,b)建立联合索引:a全局有序,字段b全局无序,局部有序, 所以如果仅根据b来过滤则无法使用联合索引
而执行a > 1 and b = 2时,a字段能用到索引,b字段用不到索引。因为a的值此时是一个范围,不是固定的,在这个范围内b值不是有序的,因此b字段用不上索引。

联合索引测试: 参考 https://blog.csdn.net/xlgen157387/article/details/79572598
索引覆盖:
索引下推:
--------------- -------------- -------------- -------------- -------------- -------------- -------------- -------------- -------------- --------------
慢SQL治理
https://blog.51cto.com/u_15437298/4692683 阿里技术号强推:慢SQL治理分享
https://developer.aliyun.com/article/872429 慢sql治理经典案例分享
https://www.1024sou.com/article/624553.html 慢SQL引发MySQL高可用切换排查全过程
https://zhuanlan.zhihu.com/p/220028437 导致MySQL索引失效的几种常见写法 --- 重要参考
https://tech.meituan.com/2014/06/30/mysql-index.html
高性能索引
1、独立的列:索引列不能是表达式的一部分;
2、选择区分度高的列作为索引;
3、选择合适的索引列顺序:将选择性高的索引列放在最前列;
4、覆盖索引:查询的列均在索引中,不需要回查聚簇索引;
5、使用索引扫描来做排序;
6、在遵守最左前缀的原则下,尽量扩展索引,而不是创建索引
7、最左前缀匹配原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
8、=和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式。
索引失效场景
1、如何判断数据库索引是否生效 -- explain分析

table:顾名思义,显示这一行的数据是关于哪张表的;
type:这是重要的列,显示连接使用了何种类型。从最好到最差的连接类型为:const、eq_reg、ref、range、indexhe和ALL;
possible_keys:显示可能应用在这张表中的索引。如果为空,没有可能的索引。可以为相关的域从where语句中选择一个合适的语句;
key: 实际使用的索引。如果为NULL,则没有使用索引。很少的情况下,MySQL会选择优化不足的索引。这种情况下,可以在Select语句中使用USE INDEX(indexname)来强制使用一个索引或者用IGNORE INDEX(indexname)来强制MySQL忽略索引;
key_len:使用的索引的长度。在不损失精确性的情况下,长度越短越好;
ref:显示索引的哪一列被使用了,如果可能的话,是一个常数;
rows:MySQL认为必须检查的用来返回请求数据的行数;
Extra:关于MySQL如何解析查询的额外信息。
失效场景
1、OR查询左右有未命中索引的;
2、复合索引不满足最左匹配原则;
3、Like以%开头;
4、需要类型转换;
5、where中索引列有运算;
6、where中索引列使用了函数;
7、如果mysql觉得全表扫描更快时(数据少时)
更多:参考 https://zhuanlan.zhihu.com/p/220028437


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 上周热点回顾(3.3-3.9)