
【Kafka】理论
参考:https://www.cnblogs.com/rickiyang/p/11074194.html http://kafka.apache.org/quickstart http://kafka.apache.org/documentation
zookeeper作用 cloud.tencent.com/developer/article/1799525
----------------------------------------------------------------------------------
一、基础知识
适用场景:
动态图:https://blog.csdn.net/Go_ahead_forever/article/details/135524503
01 日志处理和分析
上图显示了一个典型的 ELK(Elastic-Logstash-Kibana)栈。Kafka 从每个服务实例高效地收集日志流。ElasticSearch 从 Kafka 中获取日志并编制索引。Kibana 在 ElasticSearch 的基础上提供搜索和可视化用户界面。
02 推荐系统中的数据流
亚马逊等电子商务网站利用用户过去的行为和相似用户分析来计算产品推荐。Kafka 传输原始点击流数据,Flink 对其进行处理,而模型训练则消耗数据湖中的汇总数据。这样就能不断改进针对每个用户的推荐相关性。
03 系统监控和警报
与日志分析系统类似,我们需要收集系统指标来进行监控和故障排除。不同的是,指标是结构化数据,而日志是非结构化文本。指标数据被发送到 Kafka 并在 Flink 中聚合。实时监控仪表板和警报系统(如 PagerDuty)将使用汇总的数据。
04 CDC(Change Data Capture)
CDC 将数据库的变更传输到其他系统,以便复制或更新缓存/索引。例如,在下图中,事务日志被发送到 Kafka,并被 ElasticSearch、Redis 和二级数据库摄取。
05 系统迁移
升级旧服务是一项具有挑战性的任务,比如编程语言陈旧、逻辑复杂、缺乏测试等等。我们可以利用消息中间件来降低风险。如上图所示,为了升级订单服务,我们更新了旧订单服务,以便从 Kafka 中消费输入,并将结果写入 ORDER Topic。新订单服务消耗相同的输入,并将结果写入 ORDERNEW Topic。对账服务会比较 ORDER 和 ORDERNEW 下收到的内容。如果它们完全相同,新服务就会通过测试。
与其他消息队列比较
-
分布式系统,集群方式运行,可自由伸缩; // 采用zookeeper作为集群选举
-
可复制、持久化、保留多长时间都可以; // 有配置文件可配置消息持久化规则
-
提供流式处理能力,极少代码动态处理派生流和数据集。
Kafka消息特征
-
数据分布在整个系统中,具备数据故障保护和性能伸缩能力。
-
按照一定顺序持久化保存,可按需读取。
-
消息:键(一致性Hash值),对主题分区数取模选择分区,保证相同键的消息总写到相同批次上。
-
Kafa消息序列化
对kafka来说,消息是难懂的字节数组,建议使用额外结构定义消息内容。
消息模式:JSON和XML虽然易用,但缺乏强类型处理能力。
推荐使用
-
- 模式和消息体分开,模式变化时不需要重新生成代码。
- 支持强类型和模式进化,支持前后向兼容。
数据格式一致性:消除消息读写操作之间耦合性。如果读写操作耦合,消费者必须升级应用程序才能同时处理新旧数据格式。
kafka.consumer.key.deserializer=io.confluent.kafka.serializers.KafkaAvroDeserializer
kafka.consumer.value.deserializer=io.confluent.kafka.serializers.KafkaAvroDeserializer
消息以追加方式写入分区,先入先出方式顺序读取。
由于一个主题包含几个分区,无法保证整个主题范围内消息顺序,仅保证消息在单个分区内内顺序。
Kafka通过分区实现数据冗余和伸缩性。

broker:
-
- 为消息者提供服务,对读取分区请求作出响应,返回已提交磁盘的消息。
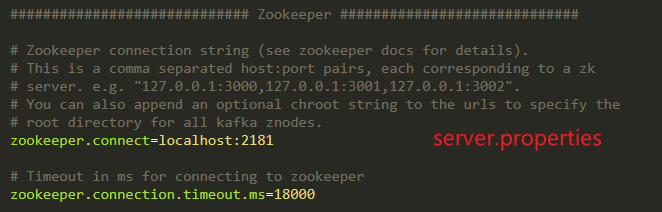
每个Kafka集群节点有一个全局唯一的broker-id(见server.properties中配置);

消费者和消费者组
消费者组: 保证每个分区只能被一个消费者使用,可以消费包含大量消息。
见下图:上述所有数字只代表offset,不是实际的内容。共计发送了15条消息。
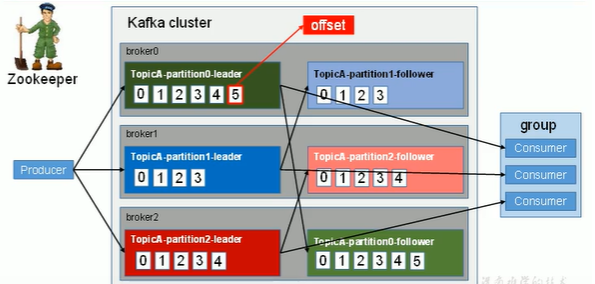
offset:
每个用户组通过自动提交或主动提交偏移量方式进行offset的提交
-
创建消息时,Kakfa添加到消息中。在给定分区中,每个消息偏移量是唯一的。
-
消费者偏移量其实并不复杂,无非就是记录消费者针对某个主题的消费进度,所以这个东西就是键值:
键:Group id + 主题 + 分区号
值:offset值
老版本的消费者偏移量都是放在Zookeeper上,新版本的消费者偏移量是放在单独的一个主题上,叫做__consumer_offsets,默认有50个分区,每个分区默认1个副本
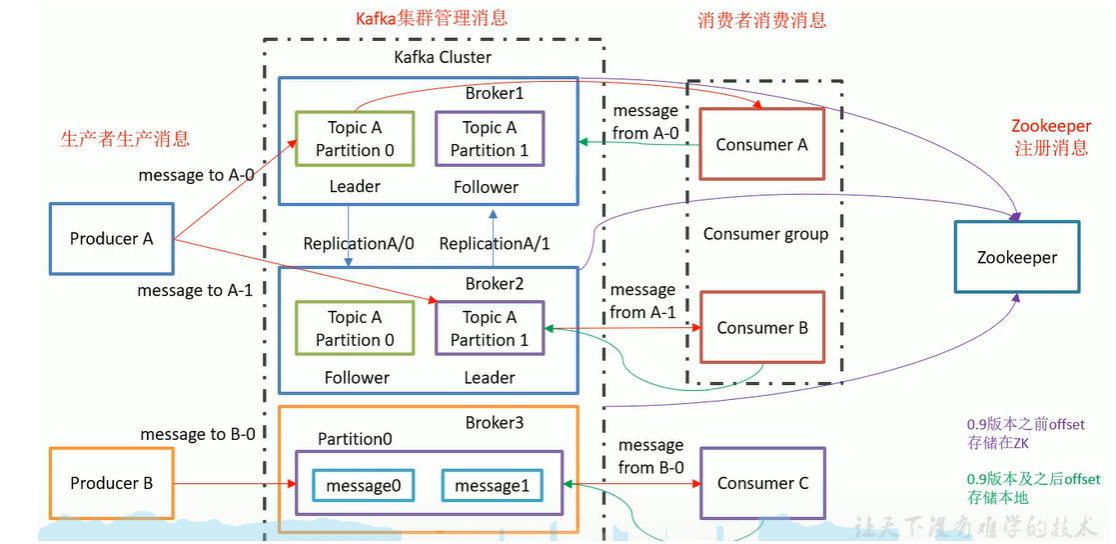
zk作用:1)Kafka集群工作,支撑Leader选举;2)0.9版本前消费者的offset(0.9后存储在Kafka磁盘中),降低对ZK的频繁交互;
Leader和Follower:面向具体Topic,而不是整体面向Broker。
broker:一个服务器是一个broker;一个集群由多个broker组成;一个broker可容纳多个topic。
Consumer Group:消费者组内每个消费者负责消费不同分区的数据。一个分区只能一个组内消费者消费。消费者组间互不影响。
Partition: 为实现扩展性,一个topic可分为多个Partition。每个partition是一个有序的队列。
Replication
Kafka Consumer 的架构设计
https://www.cnblogs.com/huazailiaojishu/p/15790780.html
Partition分配策略:
消费者组重分配机制:
consumer位移提交机制
Kafka高效读写数据的原因
- 顺序写磁盘,充分利用磁盘特性
- 充分利用 Page Cache
- 采用了零拷贝技术
- Producer 生产的数据持久化到 broker,采用 mmap 文件映射,实现顺序的快速写入
- Customer 从 broker 读取数据,采用 sendfile,将磁盘文件读到 OS 内核缓冲区后,转到 NIO buffer进行网络发送,减少 CPU 消耗
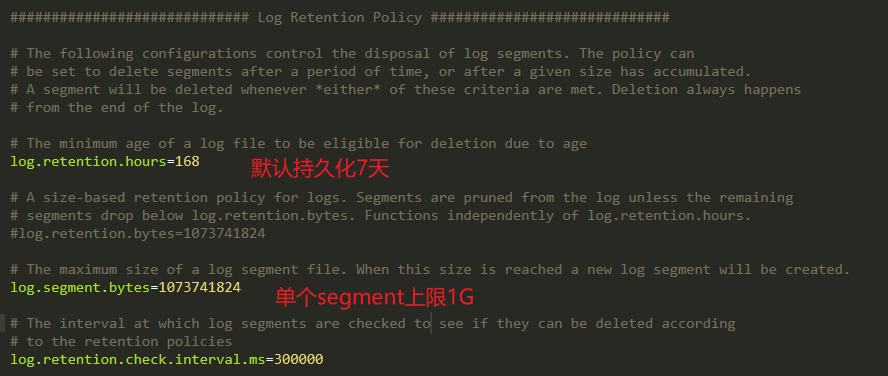
文件存储机制:
https://tech.meituan.com/2015/01/13/kafka-fs-design-theory.html
Partition->Segment:
由于生产者消息不断追加到log末尾,为防止log过大而导致数据定位效率问题。所以采用分片+索引机制:
-
将每个partition分为多个segment。
-
每个segment对应文件:index+log,位于同一目录(topic名称+分区号)
-

1、

3、index和log以当前segment第1条消息offset命名。

查找过程示意:1)定位segment;2)根据offset查找消息



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 上周热点回顾(3.3-3.9)