
【分布式】服务注册与发现(一致性协议与实际组件)
参考:https://mp.weixin.qq.com/s/KSpsa1viYz9K_-DYYQkmKA 阿里技术:一文总结:分布式一致性技术是如何演进的?
1、Paxos
Paxos达成一个决议至少需要两个阶段(Prepare阶段和Accept阶段)。
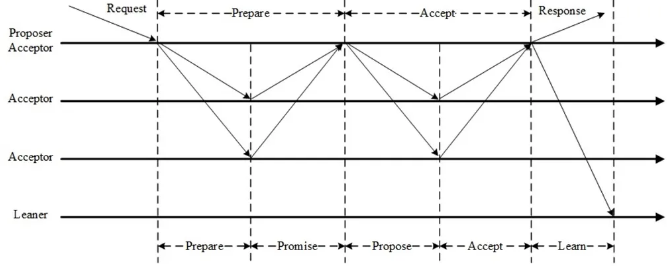
Prepare阶段的作用:
-
-
争取提议权,争取到了提议权才能在Accept阶段发起提议,否则需要重新争取。
-
-
-
学习之前已经提议的值。
-
Accept阶段:
使提议形成多数派,提议一旦形成多数派则决议达成,可以开始学习达成的决议。Accept阶段若被拒绝需要重新走Prepare阶段。
Multi-Paxos
Basic Paxos达成一次决议至少需要两次网络来回,并发情况下可能需要更多,极端情况下甚至可能形成活锁,效率低下,Multi-Paxos正是为解决此问题而提出。
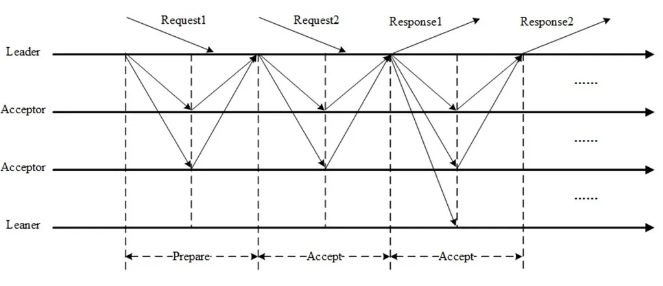
Multi-Paxos选举一个Leader,提议由Leader发起,没有竞争,解决了活锁问题。提议都由Leader发起的情况下,Prepare阶段可以跳过,将两阶段变为一阶段,提高效率。Multi-Paxos并不假设唯一Leader,它允许多Leader并发提议,不影响安全性,极端情况下 退化为Basic Paxos。 Multi-Paxos与Basic Paxos的区别并不在于Multi(Basic Paxos也可以Multi),只是在同一Proposer连续提议时可以优化跳过Prepare直接进入Accept阶段,仅此而已。
应用场景:
2、Raft
不同于Paxos直接从分布式一致性问题出发推导出来,Raft则是从多副本状态机的角度提出,使用更强的假设来减少需要考虑的状态,使之变的易于理解和实现。
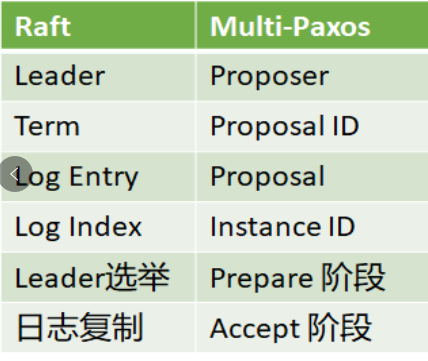
Raft与Multi-Paxos有着千丝万缕的关系,下面总结了Raft与Multi-Paxos的异同。 Raft与Multi-Paxos中相似的概念:
-
- Raft的Leader即Multi-Paxos的Proposer。
-
Raft的Term与Multi-Paxos的Proposal ID本质上是同一个东西。
-
-
Raft的Log Entry即Multi-Paxos的Proposal。
-
-
-
Raft的Log Index即Multi-Paxos的Instance ID。
-
-
-
Raft的Leader选举跟Multi-Paxos的Prepare阶段本质上是相同的。
-
-
-
Raft的日志复制即Multi-Paxos的Accept阶段。
-
Raft与Multi-Paxos的不同:

Raft假设系统在任意时刻最多只有一个Leader,提议只能由Leader发出(强Leader),否则会影响正确性;而Multi-Paxos虽然也选举Leader,但只是为了提高效率,并不限制提议只能由Leader发出(弱Leader)。 强Leader在工程中一般使用Leader Lease和Leader Stickiness来保证:
-
-
Leader Lease:上一任Leader的Lease过期后,随机等待一段时间再发起Leader选举,保证新旧Leader的Lease不重叠。
-
-
-
Leader Stickiness:Leader Lease未过期的Follower拒绝新的Leader选举请求。
-
Raft限制具有最新已提交的日志的节点才有资格成为Leader,Multi-Paxos无此限制。 Raft在确认一条日志之前会检查日志连续性,若检查到日志不连续会拒绝此日志,保证日志连续性,Multi-Paxos不做此检查,允许日志中有空洞。 Raft在AppendEntries中携带 Leader的commit index,一旦日志形成多数派,Leader更新本地的commit index即完成提交,下一条AppendEntries会携带新的commit index通知其它节点;Multi-Paxos没有日志连接性假设,需要额外的commit消息通知其它节点。
3、ZAB(Zookeeper Atomic Broadcast)-待补充
zookeeper(Dubbo通常选型):Leader+Follower两种角色;只有Leader可写(服务注册),并同步数据给Follower;
读时,Leader/Follower都可以读
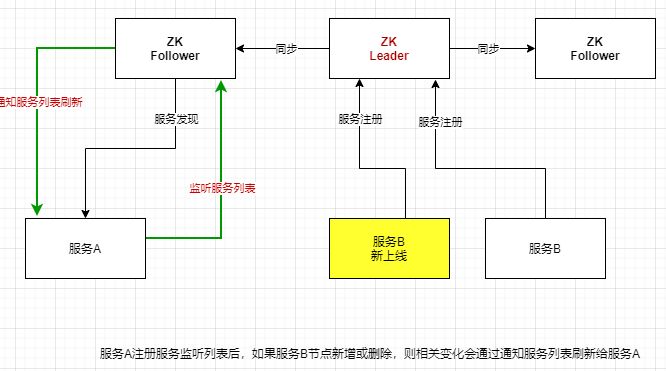
Euraka(Spring Cloud通常选型): peer-to-peer,部署一个集群,集群中每个机器地位是对等的;各服务可以向任何一个eureka实例进行服务注册和服务发现;集群中任何一个eureka实例收到写请求后,会自动同步给其他所有eureka实例
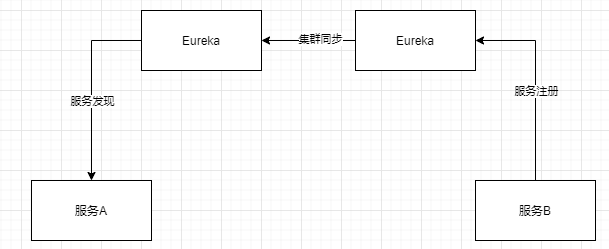
两者对比
一致性报障:CP or AP
- zk:有leader接收数据,并同步其他节点。如果leader挂掉,要重选leader,不可用一段时间;为了保证C,牺牲A。
- eureka:peer模式,可能还没数据同步过去,自己先挂掉;此时可以从其他机器拉取注册表,但是看到的不是最终数据,所以保证了可用性,最终一致性。
服务注册发现时效性:
- zk: 时效性更好,秒级就可感知到
- eureka: 默认配置糟糕,服务发现感知要几十秒,甚至分钟级别。上线一个服务实例,到其他人可发现,极端情况下,可能要1min时间(跟内部架构有关,有定时同步机制),ribbon去获取每个服务上缓存的eureka的注册表进行负载均衡。
容量:
- zk: 不适合大规模服务实例,因为服务上下线需要瞬间推动数据通知到所有其他服务实例,一旦服务规模扩大,几千实例时会对导致网络带宽被大量占用。
- eureka: 也很难支撑大规模服务实例,每个eureka实例都接受所有请求,实例多了压力大扛不住,也很难到几千级别。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 上周热点回顾(3.3-3.9)