
【Redis】核心知识点
https://www.cnblogs.com/wzh2010/p/17205505.html
支持多种数据类型,如字符串、列表、集合、有序集合、哈希表,并支持许多其他高级功能,如事务、消息订阅与发布 (Sub/Pub)。
主要应用场景:缓存(数据查询、短连接、新闻内容、商品内容等)、分布式会话(Session)、聊天室的在线好友列表、任务队列(秒杀、抢购、12306等)、应用排行榜、访问统计、数据过期处理(可以精确到毫秒)。
相对于Memcached,Redis具有如下
特点:
(1)速度快 不需要等待磁盘的IO,在内存之间进行的数据存储和查询,速度非常快。当然,缓存的数据总量不能太大,因为受到物理内存空间大小的限制。
(2)丰富的数据结构 除了string之外,还有list、hash、set、sortedset,一共五种类型。
(3)单线程,避免了线程切换和锁机制的性能消耗。
(4)可持久化 支持RDB与AOF两种方式,将内存中的数据写入外部的物理存储设备。
(5)支持发布/订阅。
(6)支持Lua脚本。
(7)支持分布式锁 在分布式系统中,如果不同的节点需要访同到一个资源,往往需要通过互斥机制来防止彼此干扰,并且保证数据的一致性。在这种情况下,需要使用到分布式锁。分布式锁和Java的锁用于实现不同线程之间的同步访问,原理上是类似的。
(8)支持原子操作和事务 Redis事务是一组命令的集合。一个事务中的命令要么都执行,要么都不执行。如果命令在运行期间出现错误,不会自动回滚。
(9)支持主-从(Master-Slave)复制与高可用(Redis Sentinel)集群(3.0 版本以上)
(10)支持管道 Redis管道是指客户端可以将多个命令一次性发送到服务器,然后由服务器一次性返回所有结果。管道技术的优点是:在批量执行命令的应用场景中,可以大大减少网络传输的开销,提高性能。
Redis系列1:深刻理解高性能Redis的本质
Redis系列2:数据持久化提高可用性
Redis系列3:高可用之主从架构
Redis系列4:高可用之Sentinel(哨兵模式)
Redis系列5:深入分析Cluster 集群模式
追求性能极致:Redis6.0的多线程模型
追求性能极致:客户端缓存带来的革命
Redis系列8:Bitmap实现亿万级数据计算
Redis系列9:Geo 类型赋能亿级地图位置计算
Redis系列10:HyperLogLog实现海量数据基数统计
Redis系列11:内存淘汰策略
Redis系列12:Redis 的事务机制
Redis系列13:分布式锁实现
Redis系列14:使用List实现消息队列
Redis系列15:使用Stream实现消息队列
Redis系列16:聊聊布隆过滤器(原理篇)
Redis系列17:聊聊布隆过滤器(实践篇)
Redis系列18:过期数据的删除策略
Redis系列19:LRU内存淘汰算法分析
Redis系列20:LFU内存淘汰算法分析
Redis系列21:缓存与数据库的数据一致性讨论
Redis系列22:Redis 的Pub/Sub能力
Redis系列23:性能优化指南
强烈建议参考:https://mp.weixin.qq.com/s/7ct-mvSIaT3o4-tsMaKRWA 阿里 一文搞懂Redis(从数据结构、存储原理,事务,持久化都有涉及,简单精炼)
支持数据类型
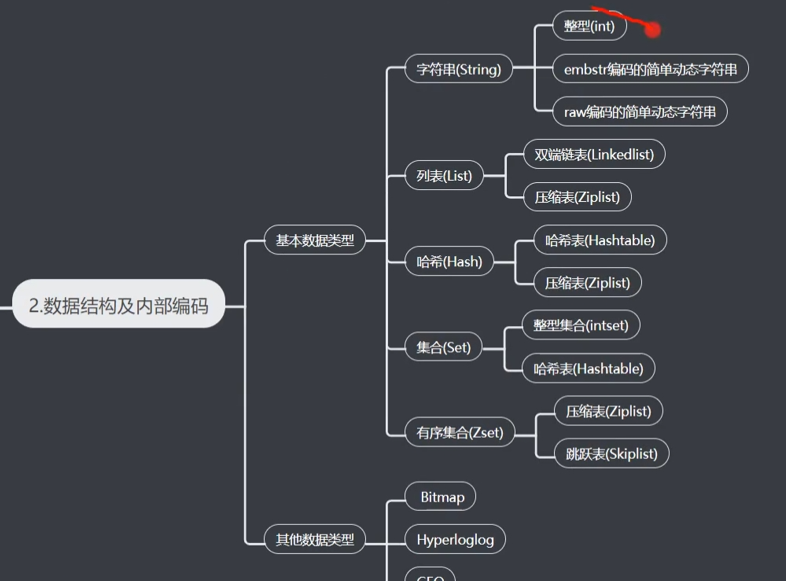
Redis针对不同数据类型的命令梳理和演示:参考 https://www.cnblogs.com/xinhuaxuan/p/9250680.html
zset:默认ziplist存储,在数据量达到一定数量下(配置文件可定制),使用跳表skipList实现
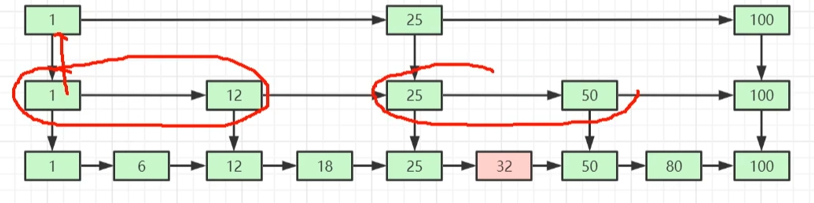
持久化:
方案:RDB、AOF(记录每个操作)、RDB+AOF(混合持久化)
https://redis.io/docs/management/persistence/ 注意了解每种方式的不足
RDB: Fork新子线程进行处理,通过 call the SAVE or BGSAVE 命令
SAVE 保存是阻塞主进程,客户端无法连接redis,等SAVE完成后,主进程才开始工作,客户端可以连接
BGSAVE 是fork一个save的子进程,在执行save过程中,不影响主进程,客户端可以正常链接redis,等子进程fork执行save完成后,通知主进程,子进程关闭。很明显BGSAVE方式比较适合线上的维护操作,两种方式的使用一定要了解清楚在谨慎选择。
配置:save 60 1000
-
Redis forks. We now have a child and a parent process.
-
The child starts to write the dataset to a temporary RDB file.
-
When the child is done writing the new RDB file, it replaces the old one.
劣势:
- RDB is NOT good if you need to minimize the chance of data loss in case Redis stops working (for example after a power outage). You can configure different save points where an RDB is produced (for instance after at least five minutes and 100 writes against the data set, you can have multiple save points). However you'll usually create an RDB snapshot every five minutes or more, so in case of Redis stopping working without a correct shutdown for any reason you should be prepared to lose the latest minutes of data.
- RDB needs to fork() often in order to persist on disk using a child process. fork() can be time consuming if the dataset is big, and may result in Redis stopping serving clients for some milliseconds or even for one second if the dataset is very big and the CPU performance is not great. AOF also needs to fork() but less frequently and you can tune how often you want to rewrite your logs without any trade-off on durability.
RDB+AOF(混合持久化): Redis 4.0新增
混合持久化同样也是通过bgrewriteaof完成的,不同的是当开启混合持久化时,fork出的子进程先将共享的内存副本全量的以RDB方式写入aof文件,然后在将aof_rewrite_buf重写缓冲区的增量命令以AOF方式写入到文件,写入完成后通知主进程更新统计信息,并将新的含有RDB格式和AOF格式的AOF文件替换旧的的AOF文件。
简单的说:新的AOF文件前半段是RDB格式的全量数据后半段是AOF格式的增量数据
三、应用场景
1、万亿级日访问量下,Redis在微博的9年优化历程 https://cloud.tencent.com/developer/news/462944 ~~干货满满
2、转载:https://blog.csdn.net/qq_42046105/article/details/95272836
首先介绍一下业务背景:总用户量大概是 5亿左右,月活 5kw,日活近 2kw 。服务端有 1000 多个 Redis 实例,100+ 集群,每个实例的内存控制在 20g 以下。
3、给你一个亿的keys,Redis如何统计? https://new.qq.com/omn/20210105/20210105A04VDK00.html


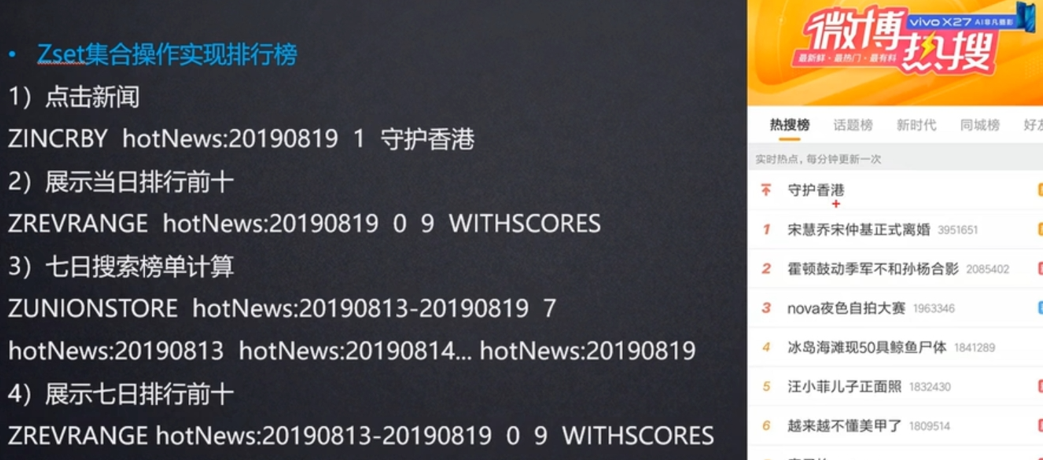
四、优秀实践
批量查询:字符串 MGET命令、哈希表 HMGET命令、管道技术、Lua 脚本 Redis 三种批量查询技巧,高并发场景下的利器
https://developer.aliyun.com/article/1432097?spm=a2c6h.12873639.article-detail.53.133d5f81QGQ6tr


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人