Vision-Based Positioning for Internet-of-Vehicles
Vision-Based Positioning for Internet-of-Vehicles
Introduction
Ego-positioning aims at locating an object in a global coordinate system based on its sensor inputs. With the growth of mobile or wearable devices, accurate positioning has be- come increasingly important. Unlike indoor positioning, considerably less efforts have been put into developing high-accuracy ego-positioning systems for outdoor environments. Global Positioning System (GPS) is the most widely used technology implemented in vehicles. However, the precision of GPS sensors is approximately 3 to 20 meters, which is not sufficient for distinguishing the traffic lanes and highway lane levels critical for intelligent vehicles. In addition, the existing GPS systems do not work properly in urban areas where signals are obstructed by high rise buildings. Although several positioning methods based on expensive sensors, such as radar sensors and Velodyne 3D laser scanners, can achieve high accuracy, they are not widely adopted because of cost issues. Hence, it is important to develop accurate ready-to-deploy IoV approaches for outdoor environments.
We presents an algorithm for ego-positioning by using a low-cost monocular camera for systems based on the Internet-of-Vehicles (IoV). To reduce the computational and memory requirements, as well as the communication load, we tackle the model compression task as a weighted k-cover problem for better preserving the critical structures. For real-world vision-based positioning applications, we consider the issue of large scene changes and introduce a model update algorithm to address this problem. A large positioning dataset containing data collected for more than a month, 106 sessions, and 14,275 images is constructed. Extensive experimental results show that sub- meter accuracy can be achieved by the proposed ego-positioning algorithm, which outperforms existing vision-based approaches.
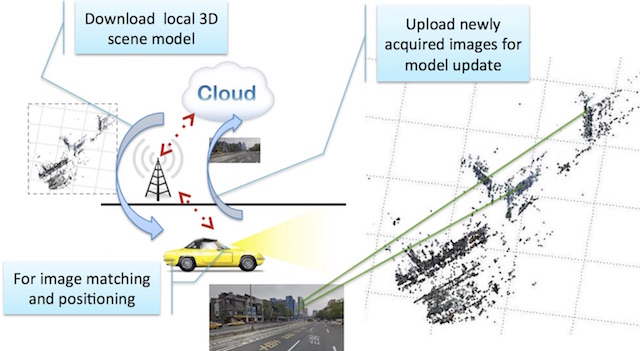
Overview of the algorithm
(a) training phase: images from passing vehicles are uploaded to a cloud server for model construction and compression;

(b) ego-positioning phase: SIFT features from images acquired on vehicles are matched against 3D models previously constructed for ego-positioning. In addition, the newly acquired images are used to update 3D models.
Result
Video on Youtube:http://www.youtube.com/embed/ZLjHGcqhbYA
Dataset
http://www.clarenceliang.com/dataset
Related Publications
[1] Kuan-Wen Chen, Chun-Hsin Wang, Xiao Wei, Qiao Liang, Ming-Hsuan Yang, Chu-Song Chen, and Yi-Ping Hung, “Vision-Based Positioning for Internet-of-Vehicles,” IEEE Transactions on Intelligent Transportation Systems, 2017.
[2] Kuan-Wen Chen, Chun-Hsin Wang, Xiao Wei, Qiao Liang, Ming-Hsuan Yang, Chu-Song Chen, and Yi-Ping Hung, “Vision-Based Positioning with Sub-meter Accuracy for Internet-of-Vehicles,” the 28th IPPR Conference on Computer Vision, Graphics, and Image Processing, Aug., 2015. (Best Paper Award)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号