
知识图谱 - 基础概念梳理
计算机专业刚入坑知识图谱,我大概是这种状态:
这里主要是为了开发时看懂需求,所以不做深入了解。

不过没办法- -从概念开始慢慢来吧。。。
1. 什么是知识图谱:
知识图谱(Knowledge Graph),在图书情报界称为知识域可视化或知识领域映射地图,是显示知识发展进程与结构关系的一系列各种不同的图形,用可视化技术描述知识资源及其载体,挖掘、分析、构建、绘制和显示知识及它们之间的相互联系。
个人理解就是展示复杂知识资源相互联系的一图形结构
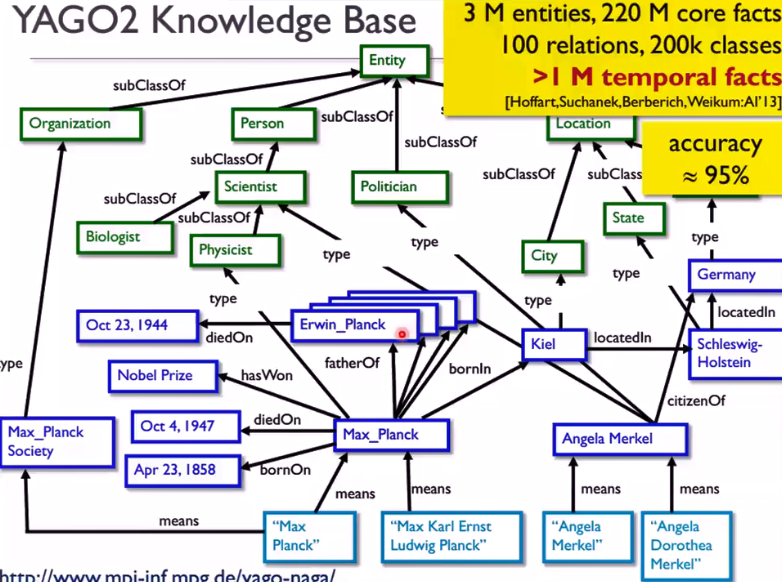
2. RDF:资源描述框架(Resource Description Framework) (知识表示的一种方式)
知识图谱是展示资源相互联系的结构,所以首先要能描述资源,以及资源的联系。然后通过各种处理来发现其中的直接关系(我们用RDF已经存储的)和可能的隐藏关系(推导出来的)。
最简单的应用:你淘宝搜个卫生巾,然后淘宝知识图谱里:卫生巾是大姨妈的 “需要” 属性之一,大姨妈的其他 “需要” 属性还包含了:绿豆汤,卫生棉,热水壶。。。然后你第二天就发现你的淘宝主页上各种暖水壶,卫生棉,绿豆汤。。。
或者:特朗普是美国总统,特朗普是房地产商 -》 美国总统是一个房地产商 然后进一步推导出别的隐藏关系。
资源(Resource):所有以RDF表示法来描述的东西都叫做资源,它可能是一个网站,可能是一个网页,可能只是网页中的某个部分,甚至是不存在于网络的东西,如纸本文献、器物、人等。在RDF中,资源是以统一资源标识(URI,Uniform Resource Indentifiers)来命名,统一资源定位器(URL,Uniform Resource Locators)、统一资源名称(URN,Uniform Resource Names)都是URI的子集。
属性(Properties):属性是用来描述资源的特定特征或关系,每一个属性都有特定的意义,用来定义它的属性值(Value)和它所描述的资源形态,以及和其它属性的关系。RDF的(Property,Property value)在概念上和传统的(Attribute,Attribute value)是相同的。
陈述(Statements):特定的资源以一个被命名的属性与相应的属性值来描述,称为一个RDF陈述,其中资源是主词(Subject),属性是述词(Predicate),属性值则是受词(Object),陈述的受词除了可能是一个字符串,也可能是其它的资料形态或是一个资源。
先举一个例子:
用xml语法来描述一个东西:
e.g:
<Description about=http://www.dlib.org/dlib/may98/miller> <- http://www.dlib.org/dlib/may98/miller 这个唯一标识了这个资源(统一资源标识) <DC:title> <- 属性标签 An introduction to the Resource Description Framework <--属性的描述 (陈述) </DC:title> <DC:creator> Eric Miller </DC:creator> <DC:date> 1998-0501 </DC:date> </Description>这种描述一个东西的方式就是RDF(不等同于XML语法,只能说所有RDF可以用xml来描述, xml有固定格式,而rdf只是一种框架,感觉有点像jvm和hotspot,一个是一种规范,一个是这种规范的一种主要实现方式)
不过xml相对来说太过正规,所以现在不用这种方式,而是直接用三元组(“主 谓 宾” 的直接排列) (也可以理解为 资源 的xx属性是 描述)
类似于这种:
<http://www.dlib.org/dlib/may98/miller> <DC:title> "An introduction to the Resource Description Framework".
<http://www.dlib.org/dlib/may98/miller> <DC:creator> "Eric Miller".
<http://www.dlib.org/dlib/may98/miller> <DC:date> "1998-0501".
或者用turtle方式来描述:
@prefix Description: <"http://www.dlib.org/dlib/may98/miller/">. //这里要注意。。。下面那些语句的主语是这个url,不是Description,相当于java里面声明了一个变量Description指向它。。。
Description :title "An introduction to the Resource Description Framework".
Description :creator "Eric Miller". //或者表示成主谓宾: Description :的creator是 "Eric Miller".
Description :date "1998-0501".
这样可以用更少的空间,更简洁的方式来存储一个资源了。
RDF的描述方式有很多。。。总之只要是用 资源,属性,描述的方式来描述的方法就是RDF(不是这方面专业的知道这个就差不多了- -)
三元组的个人理解:这玩意类似于关系数据库中的关联查询。。。A中包含的属性B,然后B有描述C。 ((A,B),C) --> 变成RDF就成了(A,B,C),只不过默认了ABC有着固定的关系。
3元组其实就是2元组基础上外面多套了一层关系,因此再套一层就会变成4元组。。。以此类推。
3. OWL, RDFS
RDF的扩展,加了一点新功能。
4. SPARQL
RDFS查询语句(Java中有SPARQL处理器:ARQ)
貌似很常用,有需要的话准备单独写一篇。
基本语句:
PREFIX exp:http://www.baidu.com
select ?student where {
?student exp:studies exp:CS328
}
差不多等于:
var exp = http://www.baidu.com
select student from exp where studies = CS328
5. 知识抽取:
想要完成知识图谱,第一步就是获取知识和知识之间的关系。
1. 命名实体识别:
找出信息中的名字和实体 (确定主语和宾语)
2. 术语抽取:
分辨并抽取信息中的专业术语
3. 关系抽取:
抽取资源之间的关系。(王健林之子王思聪 -> 王健林 的儿子是 王思聪)
4.共指消解:
分辨合并同类项(“比如小明出去玩,他没去成”,要找出:其中的“他”是指的小明)
如果还没有概念可以举个例子:
我们要处理一句话,并梳理成知识图谱:
王健林之子王思聪宣布破产
1. 我们数据库里存放了各种词组,可以先分词: 王健林 之子 王思聪 宣布 破产
2,抽出其中的名词: 王健林, 王思聪 (名词的确定可以是存储,也可能是某种算法: 比如分词时,王xx + 之子 可能是一个姓名 + 之子 这种,基本上每种抽取算法都可以单独开课= =。)
3.抽取关系: 名词之间一般是动词或者关系词。 然后分析: 之子不是动词,说明王建林 的儿子是 王思聪(建立关系1)
4.抽取事件:找到动词: 宣布 可以知道动词前后是主语和宾语
5.建立关系:王思聪 宣布 破产(建立关系2)
然后建立知识图谱: 比如百度建立了这个图谱,当你搜王思聪的百科,百度根据关系查找,然后就会显示相关词条: 王健林, 破产。
这只是举个例子,实际分析肯定不会这么简单,还要考虑很多东西。
6.确定关系的方法:
1. 模板: 储存常用词的词性和上下文可能出现的词性,然后得到一个树形结构的模型(储存各种句子结构分支)进行分析。
这种方式查的准,但是可能不全。(因为你不可能列举出所有可能,但是基本准确)
比如 王思聪 是 富豪 (模型中“是” 肯定是表示一种 is 关系)所以直接可以得出 王思聪 是 富豪 这种关系
2. 监督学习: 利用大量的数据对算法进行训练(俗称找规律- -),然后得到一个树形结构的模型。 (感觉这个和上面那个区别不大。。。)
Pipleline: 先找出实体,再分析关系。 (先找出名词,然后根据位置推测其他词的词性,确定两者之间的关系)
Joint Model:实体和关系一起分析。 (一步到位进行分析,确定两者之间关系)
这种方式需要大量数据和标注来进行训练,工作量很大。(所以叫监督学习= =要有人给答案。。。机器才能学习)
先输入 王思聪是富豪,然后输入结果:王思聪 是 富豪。
机器分析记住了“是”前后是名词时代表一种关系
输入 王健林是富豪, 机器可以得出 王健林 是 富豪 这种关系。
3. 半监督学习:
最开始知识图谱里面有: 王思聪 创立 熊猫TV
知道 A 创立 B 可以抽取关系: B 的创始人是 A。
之后碰到句子: 王思聪 建立了 熊猫TV
知识图谱查到王思聪,熊猫TV,根据已有结果确定: 建立了 = 创立
然后加入图谱。
图谱增加: A 建立了 B 可以抽取关系: B 的创始人是 A
之后碰到句子: 王健林 建立了 万达
图谱增加: 王健林 和 万达之间有建立关系
之后碰到句子: 王健林带领万达走向辉煌
图谱增加: A 带领 B 走向辉煌: B 的创始人是 A (大部分时候带领人就是创始人,但是也有例外,这时候已经有可能出现分析错误了)
半监督算法就是这样不断迭代增加,但是也可以看出来:代多了可能就会出现分析准确率逐渐跑偏的可能。。。
所以新增时需要人工检测审查(因此是半监督,人不负责告诉答案了,但是仍然要责审查机器得到的答案)
4.无监督(纯自学)
目前基本不会用这种方式。。。因为很难保证正确性。
7. 知识存储
一般使用图形数据库: 最常用的比如mongodb,nodejs等
8. 知识融合
知识融合是指对来自不同地方的相同实例进行合并(比如百度的特朗普 和 wifi的Trump, 或者百度中的 唐僧 和 唐三藏)。
创建知识图谱,需要的数据资源往往来自于各种数据库,所以需要合并同类项。
主要有两种情况的融合:
主要是实体融合,也叫知识对齐(判断两个实体是不是同一个)
不同别称 (唐僧 唐三藏):
比如唐僧的关系中有: 徒弟是 孙悟空, 是 唐朝人, 等等
然后唐三藏的关系也有:徒弟是 孙悟空, 是唐朝人, 等等
当重合性达到一定比率,就可以大概判断出这两个是同一个实体。(低于一定比率就说明不是)
不同语言(比如特朗普 Trump): 主要是通过翻译, 然后也可以翻译后进行补充。
当然,实际操作起来有很多步骤:
1. 预处理 (语言,标点等正规化,去重去错等)
2. 分块
把目标对象群体分组,目的很简单,减少每次需要处理的数据数量。
1. 根据hash算法(比如字符串前几个字母,或者算hashcode是不是一样)
2.生成某些关键字,然后排序等(比如动物根据纲,科这类的分组)
分组后为了多线操作可能要做负载均衡(数据多的,或者比较重要的数据占用更多资源来处理)。
尽量保证块中的数据数量相当
3. 记录链接
主要是计算相似度:
属性相似度:属性有多少是一样的。
计算相似距离:用动态规划计算两个描述语句之间的差别大小等技术(字符串A变成字符串B需要最少需要修改多少个字符(类似于这种))
计算集合相似度: 比如两个乐队,比较成员然后看相似度。 两个单词,看做字母的集合,比较相似度。
向量相似度:实体A和B之间关系可以看做是个从A指向B的向量,比较两个向量的相似度。
4. 评估
根据相似度确定是不是同一个(设定一个标准)
5. 结果输出
合并实体或者不合并
主要挑战: 保证数据质量, 处理大量数据
9.知识推理 (最好看一下离散数学,感觉很像。。。)
TBOX: 描述概念和关系的知识,被称之为公理
说人话就是:一类东西的定义。 比如: 富豪 = 资产超过1000万的人
ABOX: 包含外延知识,描述论域中的个体
说人话:就是具体某个事物的关系(A是B的什么)和概念(A是什么)。
一类东西中的某些实体。 比如 王思聪是富豪: 富豪(王思聪)。 (逼格高点就: richer(Sicong Wang))
或者关系。比如: 王思聪的爸爸是王健林: father_is(王思聪,王健林)。 其实你要想写写成: 王健林的儿子(王思聪),王思聪的爸爸(王健林)也没问题。
这两种写法只是为了区分关系(A是B的什么)和概念(A是什么),可以相互转化,至于具体怎么用= =自己体会。。。
这个专业人士一般会用离散数学表达式来表示:
符号表
比如:
TBOX:
有100万的是富豪
has(A,100万) <=> 富豪(A) (这里是定义为了等价关系,实际可能会更严格一些,比如用包含于(⊆)这类的,表示富豪包括了所有有100万的人: 有100万的都在富豪这个集合里,但是富豪集合里的不一定都有100万)
ABOX:
王思聪有1000万。
has(王思聪, 100万)。
这个逻辑库信息都存好后,就可以进行推导了。。。因为富豪和有100万是等价的,所以王思聪有100万 => 王思聪是富豪
(<has(person,100万) <=> 富豪) ∧ has(王思聪, 100万)> => 富豪(王思聪)
∧: 与运算, 可以理解为把条件串联成: 条件A是真, 而且条件B是真时。
上面那句推导就是: 有100万的人事富豪,而且王思聪有100万,所以王思聪是富豪。
大概这么个意思,你要想再严谨点,可能还要加上条件 person(王思聪)
一个逻辑库一般是:M=<Tbox,Abox>
TBOX定义了某种概念集合(什么是富豪),ABOX描述具体的个体概念或者关系(王思聪是富豪,王思聪与王健林是父子)。
10.语义搜索
定义:语义搜索的本质是通过数学来拜托当今搜索中使用的猜测和近似,并为词语的含义以及它们如何关联到我们在搜索引擎输入框中所找的东西引进一种清晰的理解方式。
其实就是查询。。。
基于IR:Sindice, FalconS;是单一数据结构和查询算法,针对文本数据进行排序检索来优化。它的数据是高度可压缩的,可访问的。排序是组成部分。但不能处理简单的select,join等操作。
比如文章中某个单词出现的位置。
主要方式:倒排索引。
倒排索引: 比如有30篇文章,存储时采用关键字+位置的方式存储。
王思聪:1,2,6,18,26,19. (也就是说王思聪在第1,2,6,18,26,19文章中出现过,可以快速定位)。
主要工具elasticsearch:https://www.cnblogs.com/clamp7724/p/12710326.html
基于DB:Oracle的RDF扩展,DB2的SOR;具有各种索引和查询算法,以适应各种对结构化数据的复杂查询。优点是能够完成复杂的selects,joins,…(SQL, SPARQL),能够对高动态场景(许多插入/删除)。缺点是由于使用B+树,空间的开销大和访问的局限性。同时来自叶子节点的结果没有集成对检索结果的排序。
传统关系数据库。根据属性值和范围等进行查询。
原生存储(Native stores):Dataplore, YARS, RDF-3x;优点是高度可压缩,可访问。类似于IR的检索排序。类似于DB的selects和joins操作。可在亚秒级实践内在单台机器上完成对TB数据的查询。支持高动态操作。缺点是没有事务、恢复等。
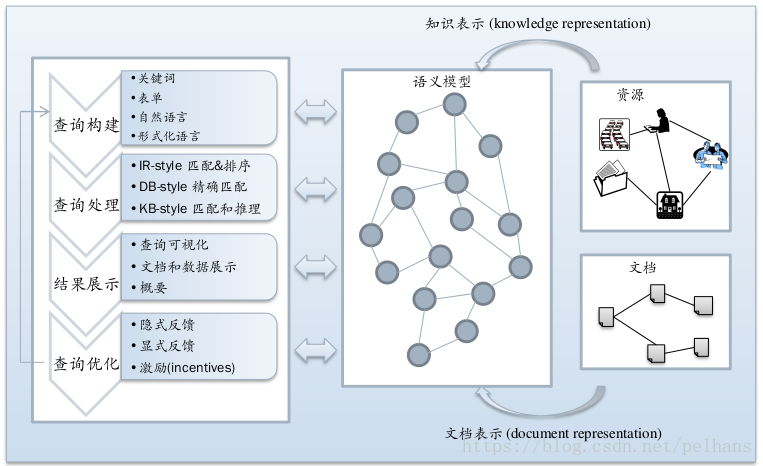
1. 查询构建:预处理,知道要用到的条件和准备查的结果
2. 进行查询
3. 显示结果
4. 后续处理:比如你百度个 wangsicong, 百度给结果后还会显示: 你要查找的是否是 王思聪

 浙公网安备 33010602011771号
浙公网安备 33010602011771号