
java - 线程池
线程的作用:充分利用CPU,并发高效地做多件事情
CPU: 中央处理器
同一时间只能做一件事情,所以说所谓的多线程并不是多个线程同时执行,还是有时间差的,只不过是CPU每个都执行一点,来回切换,逻辑上的同步执行(不过为了理解方便就当成一起执行的吧)。
创建线程的方法:
new Thread (继承了Runnable)
Runnable 接口 (线程的本质就是把Runnable中的run()方法中的代码作为任务执行)
使用Callable和Future 接口
线程的状态:(大部分会说5中,java源码中是定义为6种)
网上大部分教程:
创建线程: new Thread
就绪状态:start()
执行状态:run() //cpu自动执行,如果手动执行则会先把它运行完后再执行其他的线程(变成单线程)
等待/挂起:wait() ---》 notify,notifyAll 方法唤醒后返回就绪状态
异常/死亡:抛出异常Exception,或者人为强制结束(以前用stop,现在已经过时了),线程结束
java的Thread中源码:(我自己的翻译的源代码注释,凑合看吧-。-)
定义了一个枚举类(enum),里面的成员:new,runnable,blocked,waiting,timed_waiting,terminated
根据注释:
new:
尚未启动的线程的线程状态。
runnable:
可运行线程的线程状态。一个线程正在Java虚拟机(JVM)中运行,但它可能要等待操作系统的其他资源 -- 例如处理器(CPU)。
blocked:
等待监视器锁的阻塞线程的线程状态。
处于阻塞状态的线程正在等待 监视器锁输入一个synchronized(同步)块/方法
或在 {@link Object#wait() Object.wait} 之后调用synchronized (同步)块/方法。
(这段java的注解有点歧义- - 这段不知道翻译的对不对)
大概就是有人在用,所以上了锁,我觉得应该就是run()在执行中。
/** * Thread state for a thread blocked waiting for a monitor lock. * A thread in the blocked state is waiting for a monitor lock * to enter a synchronized block/method or * reenter a synchronized block/method after calling * {@link Object#wait() Object.wait}. */
wait:
等待线程的线程状态。
一个线程由于调用以下方法的其中一个而处于等待状态
@link Object#wait() Object.wait 并且没有超时
@link #join() Thread.join 并且没有超时
@link LockSupport#park() LockSupport.park
一个处于等待状态的线程是指:它正在等待另一个线程执行执行一个特定的动作。
timed_waiting
指定等待时间的等待线程的线程状态。
一个线程由于调用下列指定正等待时间的方法的其中一个而处于定时等待状态:
<li>{@link #sleep Thread.sleep}</li>
<li>{@link Object#wait(long) Object.wait} 并且超时了</li>
<li>{@link #join(long) Thread.join} 并且超时了</li>
<li>{@link LockSupport#parkNanos LockSupport.parkNanos}</li>
<li>{@link LockSupport#parkUntil LockSupport.parkUntil}</li>
terminated:
终止线程的线程状态。
线程已经完成执行。
这里可以看出,java的比我之前找网上资料整理的多了一个timed_wait
wait是等待cpu有资源就会执行,timed_wait是过一定时间后才会开始等待,这段时间里处于类似sleep中的状态,即使cpu有资源也不会开始运行,所以没有算做等待阶段,而是单独拿出来了。
而且wait等待了一定时间后超时了还没有执行,它会进入timed_wait阶段,过一会再开始等。
sleep属于timed_wait的一种。
线程池 (ThreadPoolExcutor)
主要结构是一个阻塞线程队列(BlockingQueue<Runnable>),先进先出,线程安全
本质就是利用一个队列控制多个线程的运行(数量,状态等)。
BlockingQueue属性的源代码:
/** * The queue used for holding tasks and handing off to worker * threads. We do not require that workQueue.poll() returning * null necessarily means that workQueue.isEmpty(), so rely * solely on isEmpty to see if the queue is empty (which we must * do for example when deciding whether to transition from * SHUTDOWN to TIDYING). This accommodates special-purpose * queues such as DelayQueues for which poll() is allowed to * return null even if it may later return non-null when delays * expire. */ private final BlockingQueue<Runnable> workQueue;
注释主要说明了两点:
1.这个玩意里面没东西也不会返回null,所以要用isEmpty判断是否为空
2.这个玩意的poll() 方法可能因为延迟的原因返回null,即使它可能等过一会延迟结束后并不是空的。
他的操作有:
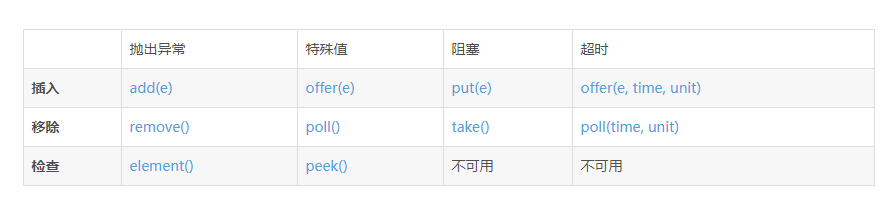
这里指的是操作和失败后对应的反馈。
线程池中主要是offer 和 take
offer会在插入失败后返回false,这样可以用 if(offer(task)){ }else{ },写成功和失败后的后续处理办法
take会在取值成功前阻塞队列(不能被操作),从而保证了线程安全,防止多个线程取同一个数据。
线程池的基本流程: 提交任务excute(Runnable runnable),如果当前线程池中已使用的core线程数量没有超过上限coreSize (还有空闲的core线程),则让core线程来处理任务。
如果core全部被使用了,把任务加入线程队列 - 等前面的都执行完了,core线程会调用任务线程的start开始执行这个线程,结束后再从队列取新的线程start。
如果core和队列都满了,启用备用线程
如果备用线程也用完了,整个线程打到饱和,启用饱和策略,这个java中有4中策略,后面会写出详细解释和运行流程。
线程池主要是个逻辑上的线程队列。
可以理解为,仓库中存有很多线程任务,这些线程都是傻逼不会自己执行自己,需要有几个正常人(core线程)负责教他们执行,每次其中一个正常人人执行完了自己负责的傻逼线程,就会从仓库中再拉一个新的傻逼出来教他执行。
下面尝试自己写一个线程池帮助理解
package threadPool; import java.util.concurrent.LinkedBlockingQueue; public class MyThreadPool { //自己写一个线程池 int currentPoolSize; //当前正在使用的线程数量 int corePoolSize; //当前最多可以使用的线程的数量, 正式工,常驻线程,有活就一直干活。 int maxPoolsize; //线程池的最大数量,正式工不够用的时候可以征集临时工。 // 这里我没写maxPoolsize相关内容,源代码中有一些关于什么时候加临时工,什么时候销毁的内容。 LinkedBlockingQueue<Runnable> workingQueue = null; //线程池队列(也叫线程仓库),用来储存准备执行的线程任务, // java源代码中是BlockingQueue,是个接口,全部重写了方法,这里我没那么复杂的内容,就直接用他的子类来代替了= =。 //构造方法 public MyThreadPool(int corePoolSize, int maxPoolsize, int workingQueueSize){ this.corePoolSize = corePoolSize; this.maxPoolsize = maxPoolsize; this.workingQueue = new LinkedBlockingQueue<Runnable>(workingQueueSize); } //excute 添加任务进入线程池,准备执行任务, 源码中有大量代码都是用来判断线程数量,防止多线程导致的错误。这里我就简单写写了。 public void excute(Runnable task){ if(currentPoolSize < corePoolSize){//线程池还没满 currentPoolSize++; new Worker(task).start(); //把任务交给一个新的线程用来执行。(相当于多了一个线程处理任务,而且优先处理给与的任务) return; } else{ System.out.println("线程已经满了,不能增加新的线程了,去线程仓库排队吧!"); if(workingQueue.offer(task)){//尝试把任务加到队列中,false则说明失败了。 return } else{ System.out.println("线程仓库也满了,滚蛋吧!不管你了!"); } } } //一个内部类,继承runnable成为线程,用来执行queue中的任务 public class Worker extends Thread { private Runnable firstTask; public Worker(Runnable firstTask) { this.firstTask = firstTask; } @Override public void run() { try { Runnable task = firstTask; while (task != null || (task = workingQueue.take()) != null) { //当task不为空,或者task从队列中取值成功的时候,开始执行task task.run(); //开始执行,不执行完这个线程不会继续往下 task = null; //任务结束后删掉这个任务,while的第一个条件不成立,执行第二个条件,开始从队列中取下一个任务直到队列中没有任务为止。 //这个就是线程池的核心思路。 } } catch(Exception e){ System.out.println("线程执行出现异常:"); e.printStackTrace(); } } } //内部类结束 }
main函数:
MyThreadPool mtp = new MyThreadPool(3,5,8); for(int i=0; i<15; i++) { try { Thread.sleep(50); } catch (InterruptedException e) { e.printStackTrace(); } mtp.excute(new ThreadTest());
}
mtp.shutdown();
常用面试题:
1.线程池的工作原理
1、线程池判断核心线程池里的线程是否都在执行任务。如果不是,则创建一个新的工作线程来执行任务。如果核心线程池里的线程都在执行任务,则执行第二步。
2、线程池判断工作队列是否已经满。如果工作队列没有满,则将新提交的任务存储在这个工作队列里进行等待。如果工作队列满了,则执行第三步
3、线程池判断线程池的线程(包括替补)是否都处于工作状态。如果没有,则创建一个新的工作线程来执行任务。如果已经满了,则交给饱和策略来处理这个任务
上面这个就是我自己写的线程池的基本处理task方法。
在java底层线程池的源码中也有提到。
2.饱和策略 和 线程的具体处理流程
java中线程池的构造方法:
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler)
参数意思:
corePoolSize: 核心线程个数
maximumPoolSize: 最大线程数
KeepAliveTime: 存活时间,这个是指,超过核心线程数后,新加的临时工线程没活干了以后最多活多久。 (一般会设成0)
TimeUnit: 存活时间的时间单位,秒,分钟,小时,年这类的。
workQueue:线程池队列,一般直接 new LinkedBlockingQueue<Runnable>( 线程池容量 )
threadFactory:线程工厂 (不写也行,系统会给个默认的,用来生成线程处理线程队列中的任务)
handler: java线程池饱和策略,比如: new ThreadPoolExecutor.DiscardPolicy()
测试
1.DiscardPolicy 丢弃任务不抛出异常
2.DiscardOldestPolicy 丢弃队列最前面的任务,重新尝试执行任务(高概率加入到队列里)
3.AbortPolicy 丢弃任务并抛出RejectedExecutionException异常
4.CallerRunsPolicy 由调用线程处理该任务
1. core线程执行:1,2,3,4,5
2. core线程 全部被使用, 新线程开始进入线程队列: 6,7,8,9,10,11,12,13,14,15
3. 队列满了,开始启动临时线程执行:16,17,18
4. maxSize是8,此时core+临时 = 5 +3 = 8,线程也满了,18之后的线程全部扔掉
5. 当1,2,3,4,5,16,17,18执行完后,core 和 临时线程 开始处理线程队列中剩余的线程:6 - 15
1. core线程执行:1,2,3,4,5
2. core线程 全部被使用, 新线程开始进入线程队列: 6,7,8,9,10,11,12,13,14,15
3. 队列满了,开始启动临时线程执行:16,17,18
4.maxSize是8,此时core+临时 = 5 +3 = 8,线程也满了,19申请执行,把队列第一个线程6扔了,把19插入队列,队列变成7,8,9,10,11,12,13,14,15,19
5.maxSize是8,此时core+临时 = 5 +3 = 8,线程依旧是满的,20申请执行,把队列第一个线程6扔了,把20插入队列,队列变成8,9,10,11,12,13,14,15,19,20
6重复上面的步骤,直到所有任务插入。
7.假设插入队列的时候没有任何线程被执行完,则最后队列里面是:21 - 30 (19和20开始把6和7踢了,自己排到队列后面,又被最后插入的29和30踢了)
1. core线程执行:1,2,3,4,5
2. core线程 全部被使用, 新线程开始进入线程队列: 6,7,8,9,10,11,12,13,14,15
3. 队列满了,开始启动临时线程执行:16,17,18
4. maxSize是8,此时core+临时 = 5 +3 = 8,线程也满了,18之后的线程全部扔掉,抛出异常。
Exception in thread "main" java.util.concurrent.RejectedExecutionException: Task Thread[Thread-18,5,main] rejected from java.util.concurrent.ThreadPoolExecutor@1ae369b7[Running, pool size = 8, active threads = 8, queued tasks = 10, completed tasks = 0]
5. 当1,2,3,4,5,16,17,18执行完后,core 和 临时线程 开始处理线程队列中剩余的线程:6 - 15
4.CallerRunsPolicy
1. core线程执行:1,2,3,4,5
2. core线程 全部被使用, 新线程开始进入线程队列: 6,7,8,9,10,11,12,13,14,15
3. 队列满了,开始启动临时线程执行:16,17,18
4. maxSize是8,此时core+临时 = 5 +3 = 8,线程也满了,19请求执行,当前线程(正在运行线程池的线程,比如我是main方法里for循环添加任务测试的,那么main方法先不添加任务了,开始自己处理任务19,等19执行完了再开始添加20)
之后重复上面的步骤,线程池不饱和的情况下就正常添加,饱和了,主函数所在线程停止添加开始帮忙处理任务。
这里注意的是,这样开始处理新任务的是当前提交新任务请求的这个线程,其他线程还是可以尝试往里面添加东西,然后在线程池空出来之前谁提交任务谁自己处理!
之后可能出现的情况:(我把第19个任务设成了其他线程执行时间的5倍)
core和临时线程执行完了 1,2,3,4,5,16,17,18,这时core和临时线程开始处理线程队列里的线程,
然后队列里的线程都被处理完了,主线程还在处理19,
没人添加新的线程,core线程就会都等着19处理完,而临时线程因为暂时没活干就被干掉了(工具人太惨了)!
之后主线程处理19结束,开始执行20-30
之后过程就和上面的步骤1,2,3,4差不多了
core线程开始处理 20,21,22,23,24
25 - 30存入队列等着被处理

 浙公网安备 33010602011771号
浙公网安备 33010602011771号