
学习笔记 07 --- JUC集合
1. List的实现类主要有: LinkedList, ArrayList, Vector, Stack。
(01) LinkedList是双向链表实现的双端队列;它不是线程安全的。仅仅适用于单线程。
(02) ArrayList是数组实现的队列,它是一个动态数组。它也不是线程安全的,仅仅适用于单线程。
(03) Vector是数组实现的矢量队列,它也一个动态数组;只是和ArrayList不同的是。Vector是线程安全的,它支持并发。
(04) Stack是Vector实现的栈;和Vector一样,它也是线程安全的。
2. Set的实现类主要有: HastSet和TreeSet。
(01) HashSet是一个没有反复元素的集合,它通过HashMap实现的;HashSet不是线程安全的。仅仅适用于单线程。
(02) TreeSet也是一个没有反复元素的集合,只是和HashSet不同的是,TreeSet中的元素是有序的。它是通过TreeMap实现的。TreeSet也不是线程安全的,仅仅适用于单线程。
3.Map的实现类主要有: HashMap,WeakHashMap, Hashtable和TreeMap。
(01) HashMap是存储“键-值对”的哈希表;它不是线程安全的,仅仅适用于单线程。
(02) WeakHashMap是也是哈希表。和HashMap不同的是,HashMap的“键”是强引用类型,而WeakHashMap的“键”是弱引用类型,也就是说当WeakHashMap 中的某个键不再正常使用时,会被从WeakHashMap中被自己主动移除。WeakHashMap也不是线程安全的,仅仅适用于单线程。
(03) Hashtable也是哈希表。和HashMap不同的是。Hashtable是线程安全的,支持并发。
(04) TreeMap也是哈希表。只是TreeMap中的“键-值对”是有序的,它是通过R-B Tree(红黑树)实现的;TreeMap不是线程安全的。仅仅适用于单线程。
1. List和Set
JUC集合包中的List和Set实现类包含: CopyOnWriteArrayList, CopyOnWriteArraySet和ConcurrentSkipListSet。
ConcurrentSkipListSet稍后在说明Map时再说明,CopyOnWriteArrayList 和 CopyOnWriteArraySet的框架例如以下图所看到的:
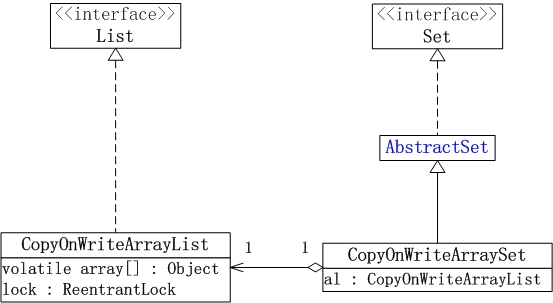
(01) CopyOnWriteArrayList相当于线程安全的ArrayList。它实现了List接口。
CopyOnWriteArrayList是支持高并发的。
(02) CopyOnWriteArraySet相当于线程安全的HashSet,它继承于AbstractSet类。CopyOnWriteArraySet内部包括一个CopyOnWriteArrayList对象,它是通过CopyOnWriteArrayList实现的。
2. Map
JUC集合包中Map的实现类包含: ConcurrentHashMap和ConcurrentSkipListMap。它们的框架例如以下图所看到的:

(01) ConcurrentHashMap是线程安全的哈希表(相当于线程安全的HashMap)。它继承于AbstractMap类。而且实现ConcurrentMap接口。ConcurrentHashMap是通过“锁分段”来实现的,它支持并发。
(02) ConcurrentSkipListMap是线程安全的有序的哈希表(相当于线程安全的TreeMap); 它继承于AbstractMap类,而且实现ConcurrentNavigableMap接口。
ConcurrentSkipListMap是通过“跳表”来实现的,它支持并发。
(03) ConcurrentSkipListSet是线程安全的有序的集合(相当于线程安全的TreeSet)。它继承于AbstractSet,并实现了NavigableSet接口。ConcurrentSkipListSet是通过ConcurrentSkipListMap实现的。它也支持并发。
3. Queue
JUC集合包中Queue的实现类包含: ArrayBlockingQueue, LinkedBlockingQueue, LinkedBlockingDeque, ConcurrentLinkedQueue和ConcurrentLinkedDeque。
它们的框架例如以下图所看到的:
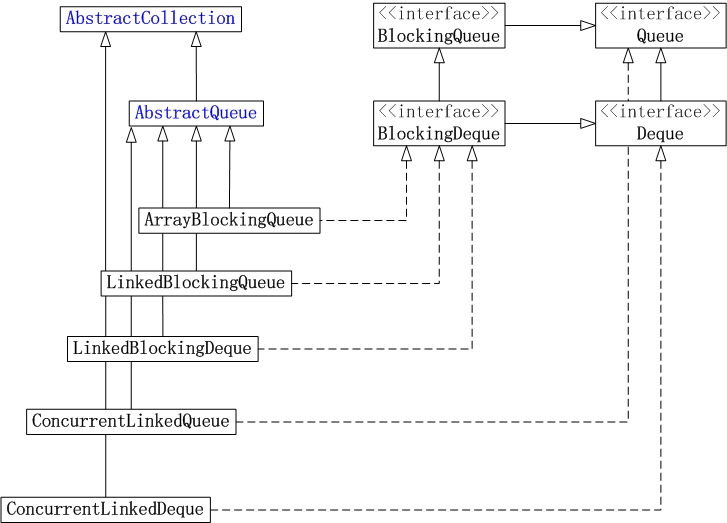
(01) ArrayBlockingQueue是数组实现的线程安全的有界的堵塞队列。
(02) LinkedBlockingQueue是单向链表实现的(指定大小)堵塞队列。该队列按 FIFO(先进先出)排序元素。
(03) LinkedBlockingDeque是双向链表实现的(指定大小)双向并发堵塞队列,该堵塞队列同一时候支持FIFO和FILO两种操作方式。
(04) ConcurrentLinkedQueue是单向链表实现的无界队列。该队列按 FIFO(先进先出)排序元素。
(05) ConcurrentLinkedDeque是双向链表实现的无界队列,该队列同一时候支持FIFO和FILO两种操作方式。
CopyOnWriteArrayList
CopyOnWriteArrayList与ArrayList相比具有的特性例如以下:
1.
它最适合于具有下面特征的应用程序:List 大小通常保持非常小,仅仅读操作远多于可变操作,须要在遍历期间防止线程间的冲突。
2. 它是线程安全的。
3. 由于通常须要复制整个基础数组,所以可变操作(add()、set() 和 remove() 等等)的开销非常大。
4. 迭代器支持hasNext(), next()等不可变操作,但不支持可变 remove()等操作。
5. 使用迭代器进行遍历的速度非常快,而且不会与其它线程发生冲突。在构造迭代器时,迭代器依赖于不变的数组快照。
// 创建一个空列表。 CopyOnWriteArrayList() // 创建一个按 collection 的迭代器返回元素的顺序包括指定 collection 元素的列表。 CopyOnWriteArrayList(Collection<?extends E> c) // 创建一个保存给定数组的副本的列表。
CopyOnWriteArrayList(E[] toCopyIn)// 将指定元素加入到此列表的尾部。boolean add(E e) // 在此列表的指定位置上插入指定元素。 void add(int index, E element) // 依照指定 collection 的迭代器返回元素的顺序,将指定 collection 中的全部元素加入此列表的尾部。
boolean addAll(Collection<?
extends E> c) // 从指定位置開始,将指定 collection 的全部元素插入此列表。 boolean addAll(int index, Collection<? extends E> c) // 依照指定 collection 的迭代器返回元素的顺序,将指定 collection 中尚未包括在此列表中的全部元素加入列表的尾部。
int addAllAbsent(Collection<? extends E> c) // 加入元素(假设不存在)。 boolean addIfAbsent(E e) // 从此列表移除全部元素。 void clear() // 返回此列表的浅表副本。 Object clone() // 假设此列表包括指定的元素。则返回 true。 boolean contains(Object o) // 假设此列表包括指定 collection 的全部元素。则返回 true。
boolean containsAll(Collection<?> c) // 比較指定对象与此列表的相等性。 boolean equals(Object o) // 返回列表中指定位置的元素。 E get(int index) // 返回此列表的哈希码值。 int hashCode() // 返回第一次出现的指定元素在此列表中的索引。从 index 開始向前搜索,假设没有找到该元素,则返回 -1。 int indexOf(E e, int index) // 返回此列表中第一次出现的指定元素的索引。假设此列表不包括该元素,则返回 -1。
int indexOf(Object o) // 假设此列表不包括不论什么元素,则返回 true。 boolean isEmpty() // 返回以恰当顺序在此列表元素上进行迭代的迭代器。 Iterator<E> iterator() // 返回最后一次出现的指定元素在此列表中的索引,从 index 開始向后搜索,假设没有找到该元素,则返回 -1。 int lastIndexOf(E e, int index) // 返回此列表中最后出现的指定元素的索引。假设列表不包括此元素,则返回 -1。 int lastIndexOf(Object o) // 返回此列表元素的列表迭代器(按适当顺序)。 ListIterator<E> listIterator() // 返回列表中元素的列表迭代器(按适当顺序),从列表的指定位置開始。 ListIterator<E> listIterator(int index) // 移除此列表指定位置上的元素。
E remove(int index) // 从此列表移除第一次出现的指定元素(假设存在)。
boolean remove(Object o) // 从此列表移除全部包括在指定 collection 中的元素。
boolean removeAll(Collection<?> c) // 仅仅保留此列表中包括在指定 collection 中的元素。 boolean retainAll(Collection<?> c) // 用指定的元素替代此列表指定位置上的元素。
E set(int index, E element) // 返回此列表中的元素数。 int size() // 返回此列表中 fromIndex(包括)和 toIndex(不包括)之间部分的视图。 List<E> subList(int fromIndex, int toIndex) // 返回一个按恰当顺序(从第一个元素到最后一个元素)包括此列表中全部元素的数组。
Object[] toArray() // 返回以恰当顺序(从第一个元素到最后一个元素)包括列表全部元素的数组;返回数组的执行时类型是指定数组的执行时类型。 <T> T[] toArray(T[] a) // 返回此列表的字符串表示形式。 String toString()
之所以大部分操作都须要复制一份数组。所以须要复制的数组数据庞大的话,开销会非常大。
CopyOnWriteArraySet
CopyOnWriteArraySet和HashSet一样都继承了AbstractSet,可是HashSet是通过散列表HashMap来实现的。而CopyOnWriteArraySet是通过动态数组CopyOnWriteArrayList来实现的。
所以CopyOnWriteArraySet和CopyOnWriteArrayList一样有例如以下特性:
1. 它最适合于具有下面特征的应用程序:List 大小通常保持非常小,仅仅读操作远多于可变操作,须要在遍历期间防止线程间的冲突。
2. 它是线程安全的。
3. 由于通常须要复制整个基础数组,所以可变操作(add()、set() 和 remove() 等等)的开销非常大。
4. 迭代器支持hasNext(), next()等不可变操作,但不支持可变 remove()等操作。
5. 使用迭代器进行遍历的速度非常快,而且不会与其它线程发生冲突。在构造迭代器时。迭代器依赖于不变的数组快照。

2. CopyOnWriteArraySet包括CopyOnWriteArrayList对象,它是通过CopyOnWriteArrayList实现的。而CopyOnWriteArrayList本质是个动态数组队列,所以CopyOnWriteArraySet相当于通过通过动态数组实现的“集合”!
CopyOnWriteArrayList中同意有反复的元素。可是。CopyOnWriteArraySet是一个集合。它不能有反复集合。
因此。CopyOnWriteArrayList额外提供了addIfAbsent()和addAllAbsent()这两个加入元素的API,通过这些API来加入元素时。仅仅有当元素不存在时才运行加入操作。
// 创建一个空 set。CopyOnWriteArraySet() // 创建一个包括指定 collection 全部元素的 set。 CopyOnWriteArraySet(Collection<? extends E> c) // 假设指定元素并不存在于此 set 中。则加入它。
boolean add(E e) // 假设此 set 中没有指定 collection 中的全部元素,则将它们都加入到此 set 中。 boolean addAll(Collection<? extends E> c) // 移除此 set 中的全部元素。 void clear() // 假设此 set 包括指定元素,则返回 true。 boolean contains(Object o) // 假设此 set 包括指定 collection 的全部元素。则返回 true。 boolean containsAll(Collection<?
> c) // 比較指定对象与此 set 的相等性。 boolean equals(Object o) // 假设此 set 不包括不论什么元素。则返回 true。 boolean isEmpty() // 返回依照元素加入顺序在此 set 中包括的元素上进行迭代的迭代器。
Iterator<E> iterator() // 假设指定元素存在于此 set 中,则将其移除。 boolean remove(Object o) // 移除此 set 中包括在指定 collection 中的全部元素。
boolean removeAll(Collection<?> c) // 仅保留此 set 中那些包括在指定 collection 中的元素。 boolean retainAll(Collection<?> c) // 返回此 set 中的元素数目。 int size() // 返回一个包括此 set 全部元素的数组。 Object[] toArray() // 返回一个包括此 set 全部元素的数组。返回数组的执行时类型是指定数组的类型。 <T> T[] toArray(T[] a)
多线程对同一个片段的訪问。是相互排斥的;可是,对于不同片段的訪问,却是能够同步进行的。
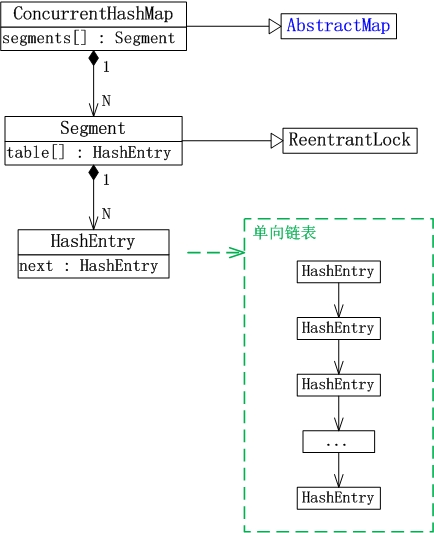

(01) ConcurrentHashMap继承于AbstractMap抽象类。
(02) Segment是ConcurrentHashMap中的内部类。它就是ConcurrentHashMap中的“锁分段”相应的存储结构。ConcurrentHashMap与Segment是组合关系。1个ConcurrentHashMap对象包括若干个Segment对象。在代码中。这表现为ConcurrentHashMap类中存在“Segment数组”成员。
(03) Segment类继承于ReentrantLock类。所以Segment本质上是一个可重入的相互排斥锁。
(04) HashEntry也是ConcurrentHashMap的内部类。是单向链表节点,存储着key-value键值对。Segment与HashEntry是组合关系,Segment类中存在“HashEntry数组”成员,“HashEntry数组”中的每一个HashEntry就是一个单向链表。
对于多线程訪问对一个“哈希表对象”竞争资源。Hashtable是通过一把锁来控制并发。而ConcurrentHashMap则是将哈希表分成很多片段。对于每个片段分别通过一个相互排斥锁来控制并发。
ConcurrentHashMap对并发的控制更加细腻,它也更加适应于高并发场景。
ConcurrentHashMap的源代码:
ConcurrentHashMap相关属性:
/** * 用于分段 */ // 依据这个数来计算segment的个数,segment的个数是仅小于这个数且是2的几次方的一个数(ssize) static final int DEFAULT_CONCURRENCY_LEVEL = 16; // 最大的分段(segment)数(2的16次方) static final int MAX_SEGMENTS = 1 << 16; /** * 用于HashEntry */ // 默认的用于计算Segment数组中的每个segment的HashEntry[]的容量,可是并非每个segment的HashEntry[]的容量 static final int DEFAULT_INITIAL_CAPACITY = 16; // 默认的载入因子(用于resize) static final float DEFAULT_LOAD_FACTOR = 0.75f; // 用于计算Segment数组中的每个segment的HashEntry[]的最大容量(2的30次方) static final int MAXIMUM_CAPACITY = 1 << 30; /** * segments数组 * 每个segment元素都看做是一个HashTable */ final Segment<K, V>[] segments; /** * 用于扩容 */ final int segmentMask;// 用于依据给定的key的hash值定位到一个Segment final int segmentShift;// 用于依据给定的key的hash值定位到一个SegmentSegment类(ConcurrentHashMap的内部类):
/** * 一个特殊的HashTable */ static final class Segment<K, V> extends ReentrantLock implements Serializable { private static final long serialVersionUID = 2249069246763182397L; transient volatile int count;// 该Segment中的包括的全部HashEntry中的key-value的个数 transient int modCount;// 并发标记 /* * 元素个数超出了这个值就扩容 threshold==(int)(capacity * loadFactor) * 值得注意的是,仅仅是当前的Segment扩容,所以这是Segment自己的一个变量,而不是ConcurrentHashMap的 */ transient int threshold; transient volatile HashEntry<K, V>[] table;// 链表数组 final float loadFactor; /** * 这里要注意一个非常不好的编程习惯,就是小写l,easy与数字1混淆,所以最好不要用小写l。能够改为大写L */ Segment(int initialCapacity, float lf) { loadFactor = lf;//每一个Segment的载入因子 setTable(HashEntry.<K, V> newArray(initialCapacity)); } /** * 创建一个Segment数组,容量为i */ @SuppressWarnings("unchecked") static final <K, V> Segment<K, V>[] newArray(int i) { return new Segment[i]; } /** * Sets table to new HashEntry array. Call only while holding lock or in * constructor. */ void setTable(HashEntry<K, V>[] newTable) { threshold = (int) (newTable.length * loadFactor);// 设置扩容值 table = newTable;// 设置链表数组 }HashEntry类(ConcurrentHashMap的内部类):
/** * Segment中的HashEntry节点 类比HashMap中的Entry节点 */ static final class HashEntry<K, V> { final K key;// 键 final int hash;//hash值 volatile V value;// 实现线程可见性 final HashEntry<K, V> next;// 下一个HashEntry HashEntry(K key, int hash, HashEntry<K, V> next, V value) { this.key = key; this.hash = hash; this.next = next; this.value = value; } /* * 创建HashEntry数组。容量为传入的i */ @SuppressWarnings("unchecked") static final <K, V> HashEntry<K, V>[] newArray(int i) { return new HashEntry[i]; } }ConcurrentHashMap(int initialCapacity,float loadFactor,int concurrencyLevel):
1 /** 2 * 创建ConcurrentHashMap 3 * @param initialCapacity 用于计算Segment数组中的每个segment的HashEntry[]的容量。 可是并非每个segment的HashEntry[]的容量 4 * @param loadFactor 5 * @param concurrencyLevel 用于计算Segment数组的大小(能够传入不是2的几次方的数,可是依据下边的计算,终于segment数组的大小ssize将是2的几次方的数) 6 * 7 * 步骤: 8 * 这里以默认的无參构造器參数为例,initialCapacity==16,loadFactor==0.75f,concurrencyLevel==16 9 * 1)检查各參数是否符合要求 10 * 2)依据concurrencyLevel(16),计算Segment[]的容量ssize(16)与扩容移位条件sshift(4) 11 * 3)依据sshift与ssize计算将来用于定位到对应Segment的參数segmentShift与segmentMask 12 * 4)依据ssize创建Segment[]数组,容量为ssize(16) 13 * 5)依据initialCapacity(16)与ssize计算用于计算HashEntry[]容量的參数c(1) 14 * 6)依据c计算HashEntry[]的容量cap(1) 15 * 7)依据cap与loadFactor(0.75)为每个Segment[i]都实例化一个Segment 16 * 8)每个Segment的实例化都做以下这些事儿: 17 * 8.1)为当前的Segment初始化其loadFactor为传入的loadFactor(0.75) 18 * 8.2)创建一个HashEntry[]。容量为传入的cap(1) 19 * 8.3)依据创建出来的HashEntry的容量(1)和初始化的loadFactor(0.75),计算扩容因子threshold(0) 20 * 8.4)初始化Segment的table为刚刚创建出来的HashEntry 21 */ 22 public ConcurrentHashMap(int initialCapacity,float loadFactor,int concurrencyLevel) { 23 // 检查參数情况 24 if (loadFactor <= 0f || initialCapacity < 0 || concurrencyLevel <= 0) 25 throw new IllegalArgumentException(); 26 27 if (concurrencyLevel > MAX_SEGMENTS) 28 concurrencyLevel = MAX_SEGMENTS; 29 30 /** 31 * 找一个能够正好小于concurrencyLevel的数(这个数必须是2的几次方的数) 32 * eg.concurrencyLevel==16==>sshift==4,ssize==16 33 * 当然,假设concurrencyLevel==15也是上边这个结果 34 */ 35 int sshift = 0; 36 int ssize = 1;// segment数组的长度 37 while (ssize < concurrencyLevel) { 38 ++sshift; 39 ssize <<= 1;// ssize=ssize*2 40 } 41 42 segmentShift = 32 - sshift;// eg.segmentShift==32-4=28 用于依据给定的key的hash值定位到一个Segment 43 segmentMask = ssize - 1;// eg.segmentMask==16-1==15 用于依据给定的key的hash值定位到一个Segment 44 this.segments = Segment.newArray(ssize);// 构造出了Segment[ssize]数组 eg.Segment[16] 45 46 /* 47 * 以下将为segment数组中加入Segment元素 48 */ 49 if (initialCapacity > MAXIMUM_CAPACITY) 50 initialCapacity = MAXIMUM_CAPACITY; 51 int c = initialCapacity / ssize;// eg.initialCapacity==16,c==16/16==1 52 if (c * ssize < initialCapacity)// eg.initialCapacity==17,c==17/16=1,这时1*16<17,所以c=c+1==2 53 ++c;// 为了少运行这一句。最好将initialCapacity设置为2的几次方 54 int cap = 1;// 每个Segment中的HashEntry[]的初始化容量 55 while (cap < c) 56 cap <<= 1;// 创建容量 57 58 for (int i = 0; i < this.segments.length; ++i) 59 // 这一块this.segments.length就是ssize。为了不去计算这个值,能够直接改成i<ssize 60 this.segments[i] = new Segment<K, V>(cap, loadFactor); 61 }ConcurrentHashMap():
/** * 创建ConcurrentHashMap */ public ConcurrentHashMap() { this(DEFAULT_INITIAL_CAPACITY, // 16 DEFAULT_LOAD_FACTOR, // 0.75f DEFAULT_CONCURRENCY_LEVEL);// 16 }
- 传入的concurrencyLevel仅仅是用于计算Segment数组的大小(能够传入不是2的几次方的数。可是依据下边的计算,终于segment数组的大小ssize将是2的几次方的数)。并非真正的Segment数组的大小
- 传入的initialCapacity仅仅是用于计算Segment数组中的每个segment的HashEntry[]的容量, 可是并非每个segment的HashEntry[]的容量,而每个HashEntry[]的容量不是2的几次方
- 很值得注意的是。在默认情况下。创建出的HashEntry[]数组的容量为1。并非传入的initialCapacity(16)。证实了上一点。而每个Segment的扩容因子threshold,一開始算出来是0。即開始put第一个元素就要扩容,不太理解JDK为什么这样做。
- 想要在初始化时扩大HashEntry[]的容量,能够指定initialCapacity參数,且指定时最好指定为2的几次方的一个数,这种话。在代码运行中可能会少运行一句"c++",详细參看三參构造器的凝视
- 对于Concurrenthashmap的扩容而言,仅仅会扩当前的Segment,而不是整个Concurrenthashmap中的全部Segment都扩
/** * 往当前segment中加入key-value * 注意: * 1)onlyIfAbsent-->false假设有旧值存在,新值覆盖旧值,返回旧值;true假设有旧值存在,则直接返回旧值,相当于不加入元素(不可加入反复key的元素) * 2)ReentrantLock的使用方法 * 3)volatile仅仅能配合锁去使用才干实现原子性 */ V put(K key, int hash, V value, boolean onlyIfAbsent) { lock();//加锁:ReentrantLock try { int c = count;//当前Segment中的key-value对(注意:因为count是volatile型的。所以读的时候工作内存会从主内存又一次载入count值) if (c++ > threshold) // 须要扩容 rehash();//扩容 HashEntry<K, V>[] tab = table; int index = hash & (tab.length - 1);//按位与获取数组下标:与HashMap同样 HashEntry<K, V> first = tab[index];//获取对应的HashEntry[i]中的头节点 HashEntry<K, V> e = first; //一直遍历到与插入节点的hash和key同样的节点e。若没有,最后e==null while (e != null && (e.hash != hash || !key.equals(e.key))) e = e.next; V oldValue;//旧值 if (e != null) {//table中已经有与将要插入节点同样hash和key的节点 oldValue = e.value;//获取旧值 if (!onlyIfAbsent) e.value = value;//false 覆盖旧值 true的话,就不加入元素了 } else {//table中没有与将要插入节点同样hash或key的节点 oldValue = null; ++modCount; tab[index] = new HashEntry<K, V>(key, hash, first, value);//将头节点作为新节点的next,所以新加入的元素也是加入在链头 count = c; //设置key-value对(注意:因为count是volatile型的,所以写的时候工作内存会马上向主内存又一次写入count值) } return oldValue; } finally { unlock();//手工释放锁 } }rehash():
/** * 步骤: * 须要注意的是:同一个桶下边的HashEntry链表中的每个元素的hash值不一定同样。仅仅是hash&(table.length-1)的结果同样 * 1)创建一个新的HashEntry数组,容量为旧数组的二倍 * 2)计算新的threshold * 3)遍历旧数组的每个元素。对于每个元素 * 3.1)依据头节点e又一次计算将要存入的新数组的索引idx * 3.2)若整个链表仅仅有一个节点e,则是直接将e赋给newTable[idx]就可以 * 3.3)若整个链表还有其它节点,先算出最后一个节点lastRun的位置lastIdx。并将最后一个节点赋值给newTable[lastIdx] * 3.4)最后将从头节点開始到最后一个节点之前的全部节点计算其将要存储的索引k,然后创建新节点,将新节点赋给newTable[k],并将之前newTable[k]上存在的节点作为新节点的下一节点 */ void rehash() { HashEntry<K, V>[] oldTable = table; int oldCapacity = oldTable.length; if (oldCapacity >= MAXIMUM_CAPACITY) return; HashEntry<K, V>[] newTable = HashEntry.newArray(oldCapacity << 1);//扩容为原来二倍 threshold = (int) (newTable.length * loadFactor);//计算新的扩容临界值 int sizeMask = newTable.length - 1; for (int i = 0; i < oldCapacity; i++) { // We need to guarantee that any existing reads of old Map can // proceed. So we cannot yet null out each bin. HashEntry<K, V> e = oldTable[i];//头节点 if (e != null) { HashEntry<K, V> next = e.next; int idx = e.hash & sizeMask;//又一次按位与计算将要存放的新数组中的索引 if (next == null)//假设是仅仅有一个头节点,仅仅需将头节点设置到newTable[idx]就可以 newTable[idx] = e; else { // Reuse trailing consecutive sequence at same slot HashEntry<K, V> lastRun = e; int lastIdx = idx;//存放最后一个元素将要存储的数组索引 //查找到最后一个元素,并设置相关信息 for (HashEntry<K, V> last = next; last != null; last = last.next) { int k = last.hash & sizeMask; if (k != lastIdx) { lastIdx = k; lastRun = last; } } newTable[lastIdx] = lastRun;//存放最后一个元素 // Clone all remaining nodes for (HashEntry<K, V> p = e; p != lastRun; p = p.next) { int k = p.hash & sizeMask; HashEntry<K, V> n = newTable[k];//获取newTable[k]已经存在的HashEntry,并将此HashEntry赋给n //创建新节点,并将之前的n作为新节点的下一节点 newTable[k] = new HashEntry<K, V>(p.key, p.hash, n,p.value); } } } } table = newTable; }Segment的get(Object key, int hash):
/** * 依据key和hash值获取value */ V get(Object key, int hash) { if (count != 0) { // read-volatile HashEntry<K, V> e = getFirst(hash);//找到HashEntry[index] while (e != null) {//遍历整个链表 if (e.hash == hash && key.equals(e.key)) { V v = e.value; if (v != null) return v; /* * 假设V等于null,有可能是当下的这个HashEntry刚刚被创建。value属性还没有设置成功, * 这时候我们读到是该HashEntry的value的默认值null,所以这里加锁。等待put结束后,返回value值 */ return readValueUnderLock(e); } e = e.next; } } return null; }Segment的remove(Object key, int hash, Object value):
V remove(Object key, int hash, Object value) { lock(); try { int c = count - 1;//key-value对个数-1 HashEntry<K, V>[] tab = table; int index = hash & (tab.length - 1); HashEntry<K, V> first = tab[index];//获取将要删除的元素所在的HashEntry[index] HashEntry<K, V> e = first; //从头节点遍历到最后,若未找到相关的HashEntry。e==null,否则,有 while (e != null && (e.hash != hash || !key.equals(e.key))) e = e.next; V oldValue = null; if (e != null) {//将要删除的节点e V v = e.value; if (value == null || value.equals(v)) { oldValue = v; // All entries following removed node can stay // in list, but all preceding ones need to be // cloned. ++modCount; HashEntry<K, V> newFirst = e.next; /* * 从头结点遍历到e节点,这里将e节点删除了,可是删除节点e的前边的节点会倒序 * eg.原本的顺序:E3-->E2-->E1-->E0,删除E1节点后的顺序为:E2-->E3-->E0 * E1前的节点倒序排列了 */ for (HashEntry<K, V> p = first; p != e; p = p.next) newFirst = new HashEntry<K, V>(p.key, p.hash, newFirst, p.value); tab[index] = newFirst; count = c; // write-volatile } } return oldValue; } finally { unlock(); } }
对于ConcurrentHashMap的加入,删除操作。在操作開始前,线程都会获取Segment的相互排斥锁;操作完成之后,才会释放。
而对于读取操作。它是通过volatile去实现的,HashEntry数组是volatile类型的。而volatile能保证“即对一个volatile变量的读。总是能看到(随意线程)对这个volatile变量最后的写入”,即我们总能读到其他线程写入HashEntry之后的值。
以上这些方式。就是ConcurrentHashMap线程安全的实现原理。
ArrayBlockingQueue是数组实现的线程安全的有界的堵塞队列。
线程安全是指。ArrayBlockingQueue内部通过“相互排斥锁”保护竞争资源。实现了多线程对竞争资源的相互排斥訪问。
而有界,则是指ArrayBlockingQueue相应的数组是有界限的。
堵塞队列,是指多线程訪问竞争资源时。当竞争资源已被某线程获取时。其他要获取该资源的线程须要堵塞等待;并且。ArrayBlockingQueue是按 FIFO(先进先出)原则对元素进行排序,元素都是从尾部插入到队列,从头部開始返回。
注意:ArrayBlockingQueue不同于ConcurrentLinkedQueue。ArrayBlockingQueue是数组实现的。而且是有界限的。必须指定队列大小;而ConcurrentLinkedQueue是链表实现的,是无界限的。
ArrayBlockingQueue的原理和数据结构以及源码:
private final E[] items;//底层数据结构 private int takeIndex;//用来为下一个take/poll/remove的索引(出队) private int putIndex;//用来为下一个put/offer/add的索引(入队) private int count;//队列中元素的个数 /* * Concurrency control uses the classic two-condition algorithm found in any * textbook. */ /** Main lock guarding all access */ private final ReentrantLock lock;//锁 /** Condition for waiting takes */ private final Condition notEmpty;//等待出队的条件 /** Condition for waiting puts */ private final Condition notFull;//等待入队的条件
/** * 创造一个队列,指定队列容量。指定模式 * @param fair * true:先来的线程先操作 * false:顺序随机 */ public ArrayBlockingQueue(int capacity, boolean fair) { if (capacity <= 0) throw new IllegalArgumentException(); this.items = (E[]) new Object[capacity];//初始化类变量数组items lock = new ReentrantLock(fair);//初始化类变量锁lock notEmpty = lock.newCondition();//初始化类变量notEmpty Condition notFull = lock.newCondition();//初始化类变量notFull Condition } /** * 创造一个队列。指定队列容量。默认模式为非公平模式 * @param capacity <1会抛异常 */ public ArrayBlockingQueue(int capacity) { this(capacity, false); }说明:
1. ArrayBlockingQueue继承于AbstractQueue,而且它实现了BlockingQueue接口。
2. ArrayBlockingQueue内部是通过Object[]数组保存数据的。也就是说ArrayBlockingQueue本质上是通过数组实现的。ArrayBlockingQueue的大小,即数组的容量是创建ArrayBlockingQueue时指定的。
3. ArrayBlockingQueue与ReentrantLock是组合关系。ArrayBlockingQueue中包括一个ReentrantLock对象(lock)。ReentrantLock是可重入的相互排斥锁,ArrayBlockingQueue就是依据该相互排斥锁实现“多线程对竞争资源的相互排斥訪问”。并且,ReentrantLock分为公平锁和非公平锁。关于详细使用公平锁还是非公平锁,在创建ArrayBlockingQueue时能够指定。并且,ArrayBlockingQueue默认会使用非公平锁。
4. ArrayBlockingQueue与Condition是组合关系。ArrayBlockingQueue中包括两个Condition对象(notEmpty和notFull)。并且。Condition又依赖于ArrayBlockingQueue而存在,通过Condition能够实现对ArrayBlockingQueue的更精确的訪问 --(01)若某线程(线程A)要取数据时,数组正好为空,则该线程会执行notEmpty.await()进行等待;当其他某个线程(线程B)向数组中插入了数据之后,会调用notEmpty.signal()唤醒“notEmpty上的等待线程”。
此时,线程A会被唤醒从而得以继续执行。
此时,线程H就会被唤醒从而得以继续执行。
// 创建一个带有给定的(固定)容量和默认訪问策略的 ArrayBlockingQueue。ArrayBlockingQueue(int capacity) // 创建一个具有给定的(固定)容量和指定訪问策略的 ArrayBlockingQueue。 ArrayBlockingQueue(int capacity, boolean fair) // 创建一个具有给定的(固定)容量和指定訪问策略的 ArrayBlockingQueue。它最初包括给定 collection 的元素,并以 collection 迭代器的遍历顺序加入元素。
ArrayBlockingQueue(int capacity, boolean fair, Collection<? extends E> c) // 将指定的元素插入到此队列的尾部(假设马上可行且不会超过该队列的容量),在成功时返回 true,假设此队列已满。则抛出 IllegalStateException。
boolean add(E e) // 自己主动移除此队列中的全部元素。
void clear() // 假设此队列包括指定的元素,则返回 true。 boolean contains(Object o) // 移除此队列中全部可用的元素,并将它们加入到给定 collection 中。
int drainTo(Collection<? super E> c) // 最多从此队列中移除给定数量的可用元素,并将这些元素加入到给定 collection 中。 int drainTo(Collection<? super E> c, int maxElements) // 返回在此队列中的元素上按适当顺序进行迭代的迭代器。
Iterator<E> iterator() // 将指定的元素插入到此队列的尾部(假设马上可行且不会超过该队列的容量),在成功时返回 true,假设此队列已满。则返回 false。 boolean offer(E e) // 将指定的元素插入此队列的尾部。假设该队列已满。则在到达指定的等待时间之前等待可用的空间。 boolean offer(E e, long timeout, TimeUnit unit) // 获取但不移除此队列的头;假设此队列为空,则返回 null。 E peek() // 获取并移除此队列的头,假设此队列为空,则返回 null。
E poll() // 获取并移除此队列的头部,在指定的等待时间前等待可用的元素(假设有必要)。
E poll(long timeout, TimeUnit unit) // 将指定的元素插入此队列的尾部,假设该队列已满,则等待可用的空间。 void put(E e) // 返回在无堵塞的理想情况下(不存在内存或资源约束)此队列能接受的其它元素数量。 int remainingCapacity() // 从此队列中移除指定元素的单个实例(假设存在)。 boolean remove(Object o) // 返回此队列中元素的数量。
int size() // 获取并移除此队列的头部,在元素变得可用之前一直等待(假设有必要)。 E take() // 返回一个按适当顺序包括此队列中全部元素的数组。 Object[] toArray() // 返回一个按适当顺序包括此队列中全部元素的数组。返回数组的执行时类型是指定数组的执行时类型。 <T> T[] toArray(T[] a) // 返回此 collection 的字符串表示形式。 String toString()
三种入队对照:
- offer(E e):假设队列没满,马上返回true; 假设队列满了,马上返回false-->不堵塞
- put(E e):假设队列满了,一直堵塞,直到数组不满了或者线程被中断-->堵塞
- offer(E e, long timeout, TimeUnit unit):在队尾插入一个元素,,假设数组已满。则进入等待,直到出现下面三种情况:-->堵塞
- 被唤醒
- 等待时间超时
- 当前线程被中断
三种出对对照:
- poll():假设没有元素。直接返回null;假设有元素,出队
- take():假设队列空了,一直堵塞。直到数组不为空或者线程被中断-->堵塞
- poll(long timeout, TimeUnit unit):假设数组不空。出队;假设数组已空且已经超时,返回null;假设数组已空且时间未超时。则进入等待,直到出现下面三种情况:
- 被唤醒
- 等待时间超时
- 当前线程被中断
LinkedBlockingQueue是一个单向链表实现的堵塞队列。
该队列按 FIFO(先进先出)排序元素。新元素插入到队列的尾部,而且队列获取操作会获得位于队列头部的元素。链接队列的吞吐量通常要高于基于数组的队列,可是在大多数并发应用程序中,其可预知的性能要低。
此外,LinkedBlockingQueue还是可选容量的(防止过度膨胀)。即能够指定队列的容量。假设不指定,默认容量大小等于Integer.MAX_VALUE。
LinkedBlockingQueue的原理和数据结构:
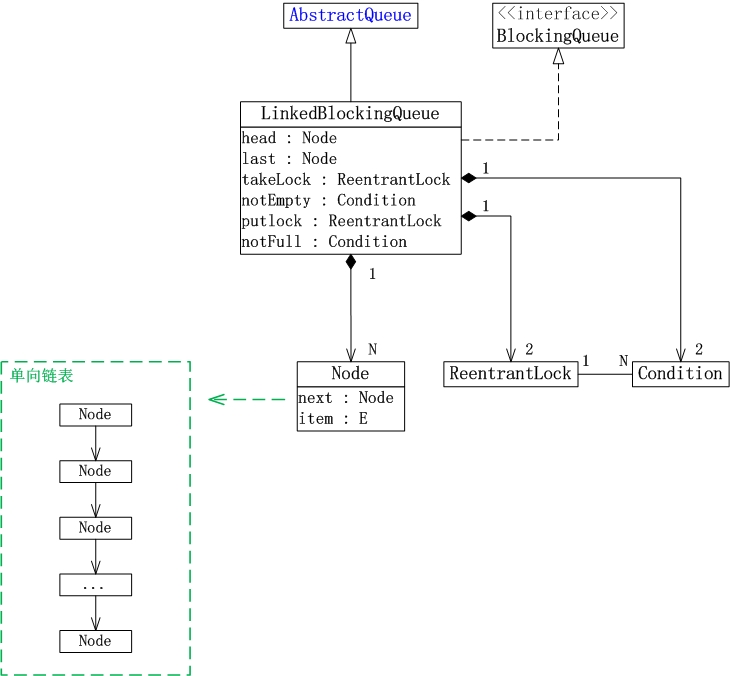
1. LinkedBlockingQueue继承于AbstractQueue,它本质上是一个FIFO(先进先出)的队列。
2. LinkedBlockingQueue实现了BlockingQueue接口。它支持多线程并发。当多线程竞争同一个资源时。某线程获取到该资源之后。其他线程须要堵塞等待。
3. LinkedBlockingQueue是通过单链表实现的。
(01) head是链表的表头。取出数据时。都是从表头head处插入。
(02) last是链表的表尾。
新增数据时。都是从表尾last处插入。
(03) count是链表的实际大小,即当前链表中包括的节点个数。
(04) capacity是列表的容量。它是在创建链表时指定的。
(05) putLock是插入锁,takeLock是取出锁;notEmpty是“非空条件”。notFull是“未满条件”。通过它们对链表进行并发控制。
LinkedBlockingQueue在实现“多线程对竞争资源的相互排斥訪问”时。对于“插入”和“取出(删除)”操作分别使用了不同的锁。对于插入操作。通过“插入锁putLock”进行同步;对于取出操作。通过“取出锁takeLock”进行同步。
此外,插入锁putLock和“非满条件notFull”相关联,取出锁takeLock和“非空条件notEmpty”相关联。
通过notFull和notEmpty更细腻的控制锁。
-- 若某线程(线程A)要取出数据时。队列正好为空。则该线程会运行notEmpty.await()进行等待;当其他某个线程(线程B)向队列中插入了数据之后,会调用notEmpty.signal()唤醒“notEmpty上的等待线程”。此时。线程A会被唤醒从而得以继续运行。 此外。线程A在运行取操作前,会获取takeLock,在取操作运行完成再释放takeLock。
-- 若某线程(线程H)要插入数据时,队列已满,则该线程会它运行notFull.await()进行等待。当其他某个线程(线程I)取出数据之后,会调用notFull.signal()唤醒“notFull上的等待线程”。此时,线程H就会被唤醒从而得以继续运行。 此外,线程H在运行插入操作前,会获取putLock,在插入操作运行完成才释放putLock。
// 创建一个容量为 Integer.MAX_VALUE 的 LinkedBlockingQueue。LinkedBlockingQueue() // 创建一个容量是 Integer.MAX_VALUE 的 LinkedBlockingQueue。最初包括给定 collection 的元素。元素按该 collection 迭代器的遍历顺序加入。 LinkedBlockingQueue(Collection<?
extends E> c) // 创建一个具有给定(固定)容量的 LinkedBlockingQueue。 LinkedBlockingQueue(int capacity) // 从队列彻底移除全部元素。 void clear() // 移除此队列中全部可用的元素。并将它们加入到给定 collection 中。 int drainTo(Collection<?
super E> c) // 最多从此队列中移除给定数量的可用元素。并将这些元素加入到给定 collection 中。 int drainTo(Collection<?
super E> c, int maxElements) // 返回在队列中的元素上按适当顺序进行迭代的迭代器。
Iterator<E> iterator() // 将指定元素插入到此队列的尾部(假设马上可行且不会超出此队列的容量),在成功时返回 true,假设此队列已满,则返回 false。
boolean offer(E e) // 将指定元素插入到此队列的尾部。如有必要,则等待指定的时间以使空间变得可用。
boolean offer(E e, long timeout, TimeUnit unit) // 获取但不移除此队列的头;假设此队列为空,则返回 null。 E peek() // 获取并移除此队列的头,假设此队列为空,则返回 null。
E poll() // 获取并移除此队列的头部,在指定的等待时间前等待可用的元素(假设有必要)。 E poll(long timeout, TimeUnit unit) // 将指定元素插入到此队列的尾部,如有必要。则等待空间变得可用。 void put(E e) // 返回理想情况下(没有内存和资源约束)此队列可接受而且不会被堵塞的附加元素数量。 int remainingCapacity() // 从此队列移除指定元素的单个实例(假设存在)。
boolean remove(Object o) // 返回队列中的元素个数。 int size() // 获取并移除此队列的头部。在元素变得可用之前一直等待(假设有必要)。 E take() // 返回按适当顺序包括此队列中全部元素的数组。 Object[] toArray() // 返回按适当顺序包括此队列中全部元素的数组;返回数组的执行时类型是指定数组的执行时类型。 <T> T[] toArray(T[] a) // 返回此 collection 的字符串表示形式。 String toString()
三种入队对照:
- offer(E e):假设队列没满,马上返回true; 假设队列满了,马上返回false-->不堵塞
- put(E e):假设队列满了,一直堵塞。直到队列不满了或者线程被中断-->堵塞
- offer(E e, long timeout, TimeUnit unit):在队尾插入一个元素,,假设队列已满。则进入等待,直到出现下面三种情况:-->堵塞
- 被唤醒
- 等待时间超时
- 当前线程被中断
三种出队对照:
- poll():假设没有元素,直接返回null;假设有元素,出队
- take():假设队列空了。一直堵塞,直到队列不为空或者线程被中断-->堵塞
- poll(long timeout, TimeUnit unit):假设队列不空,出队;假设队列已空且已经超时,返回null;假设队列已空且时间未超时。则进入等待,直到出现下面三种情况:
- 被唤醒
- 等待时间超时
- 当前线程被中断
ArrayBlockingQueue与LinkedBlockingQueue对照:
- ArrayBlockingQueue:
- 一个对象数组+一把锁+两个条件
- 入队与出队都用同一把锁
- 在仅仅有入队高并发或出队高并发的情况下。由于操作数组,且不须要扩容,性能非常高
- 採用了数组。必须指定大小,即容量有限
- LinkedBlockingQueue:
- 一个单向链表+两把锁+两个条件
- 两把锁。一把用于入队,一把用于出队,有效的避免了入队与出队时使用一把锁带来的竞争。
- 在入队与出队都高并发的情况下,性能比ArrayBlockingQueue高非常多
- 採用了链表,最大容量为整数最大值。可看做容量无限
功能类似于:一直等待,来一个及时处理一个。但不能同一时候处理两个。比方queue.take()方法会堵塞。queue.offer(element)插入一个元素,插入的元素立即就被queue.take()处理掉。
所以它没有容纳元素的能力,isEmpty方法总是返回true。可是给人的感觉像是能够暂时容纳一个元素。
平时非常少使用。可是在线程池的地方用到了该队列。
SynchronousQueue支持2种策略:公平和非公平,默觉得非公平。
1) 公平策略:内部实现为TransferQueue,即一个队列.(consumer和productor将会被队列化)
2) 非公平策略:内部实现为TransferStack,即一个stack(内部模拟了一个单向链表。同意闯入行为)
内部实现比較复杂。虽然支持线程安全。可是其内部并没有使用lock(其实无法使用lock)。使用了LockSupport来控制线程。使用CAS来控制栈的head游标(非公平模式下)。
**********************************************未完待续*********************************************
该文为本人学习的笔记,方便以后自己查阅。參考网上各大帖子,取其精华整合自己的理解而成。
如有不正确的地方。请多多指正!自勉!
共勉!
**************************************************************************************************

