
自动化测试--实现一套完全解耦的简单测试框架
selenium中有提供pageObject,支持将页面元素和动作单独封装到一个类中。
但是,当页面元素发生变化的时候(在项目的维护过程中,很很容易发生的),就需要去修改源代码。为了解决这个问题,可以实现一套完全解耦的简单测试框架。
该框架的主要思想,是 将各个测试页面的定位信息存放到xml中,解析后的xml信息映射到相应的类中。当页面定位信息改变的时候,只需修改xml文件即可。
下面是项目框架: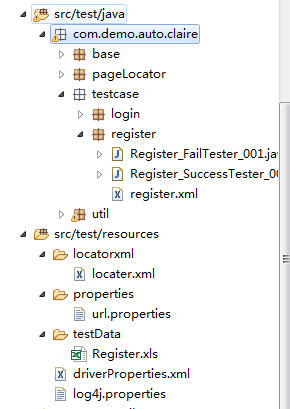
base:用来存放一些测试初始化操作以及对selenuim部分功能的2次封装,之后会上代码。
pageLocator:用来存放一个页面定位器的类,该类包含by、value、desc三个属性。方便将页面定位元素的信息映射到我们这个类上。
testCase:测试用例
util:帮助类。存放 如之前博客中封装的getDriver等
下面是该框架的具体实现:
1.先使用maven引入各jar包
selenium、TESTNG(管理用例)、log4j(记录日志)、dom4j(解析xml)、poi(读取excel)。下面是笔者的pom.xml


1 <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> 2 <modelVersion>4.0.0</modelVersion> 3 <groupId>com.claire.leafly</groupId> 4 <artifactId>projectLemon</artifactId> 5 <version>0.0.1-SNAPSHOT</version> 6 <dependencies> 7 8 <dependency> 9 <groupId>org.seleniumhq.selenium</groupId> 10 <artifactId>selenium-java</artifactId> 11 <version>3.4.0</version> 12 </dependency> 13 14 <!-- https://mvnrepository.com/artifact/org.testng/testng --> 15 <dependency> 16 <groupId>org.testng</groupId> 17 <artifactId>testng</artifactId> 18 <version>6.9.10</version> 19 <scope>test</scope> 20 </dependency> 21 22 <!-- https://mvnrepository.com/artifact/dom4j/dom4j --> 23 <dependency> 24 <groupId>dom4j</groupId> 25 <artifactId>dom4j</artifactId> 26 <version>1.6.1</version> 27 </dependency> 28 29 30 <!-- https://mvnrepository.com/artifact/log4j/log4j --> 31 <dependency> 32 <groupId>log4j</groupId> 33 <artifactId>log4j</artifactId> 34 <version>1.2.17</version> 35 </dependency> 36 37 <!-- https://mvnrepository.com/artifact/org.apache.poi/poi-ooxml --> 38 <dependency> 39 <groupId>org.apache.poi</groupId> 40 <artifactId>poi-ooxml</artifactId> 41 <version>3.17</version> 42 </dependency> 43 44 </dependencies> 45 <build> 46 <plugins> 47 <!-- 1:解决每次右键项目名-maven->update project 时候,项目jdk版本变了,变回1.5版本或者其他版本 48 2: 解决使用maven编译其他问题:如提示不能在内部类访问外部非final局部变量 49 --> 50 <plugin> 51 <groupId>org.apache.maven.plugins</groupId> 52 <artifactId>maven-compiler-plugin</artifactId> 53 <version>3.5.1</version> 54 <configuration> 55 <source>1.8</source> 56 <target>1.8</target> 57 <encoding>UTF-8</encoding> 58 </configuration> 59 </plugin> 60 </plugins> 61 </build> 62 63 </project>
2.按照上面项目结构图来创建一个maven工程
3.封装driver的方法,之前的博客中已经详细说明,这里不再赘述。直接上代码
实现一个读取浏览器驱动配置文件的帮助类
1 package com.demo.auto.claire.util; 2 3 4 5 import java.util.List; 6 import org.dom4j.Document; 7 import org.dom4j.DocumentException; 8 import org.dom4j.Element; 9 import org.dom4j.io.SAXReader; 10 import org.openqa.selenium.WebDriver; 11 import org.openqa.selenium.remote.DesiredCapabilities; 12 13 public class SeleniumUtil { 14 private static Class clazz; 15 private static Object obj ; 16 17 public static void main(String[] args) { 18 getDriver(); 19 } 20 21 22 23 public static WebDriver getDriver() { 24 Document document = null; 25 Element driverNameElement= null; 26 String driverName =null; 27 28 SAXReader reader = new SAXReader(); 29 try { 30 document = reader.read(SeleniumUtil.class.getResourceAsStream("/driverProperties.xml")); 31 } catch (DocumentException e) { 32 33 e.printStackTrace(); 34 } 35 36 /** 37 * 下面是通过解析XML,获取到驱动的类全名 38 */ 39 Element rootElement = document.getRootElement(); //获取到根节点 40 int index = Integer.parseInt(rootElement.attributeValue("driverIndex"));//获取到根节点上的driverIndex并转成int类型 41 42 43 //获取到所有"name"子节点,遍历,找出与根节点中的driverIndex相同的,将其value属性值获取出来,作为类全名用于反射 44 List<Element> driverNameElements = rootElement.elements("name"); 45 for (Element driverNameElement1 : driverNameElements) { 46 int i = Integer.parseInt(driverNameElement1.attributeValue("index")); 47 if (i == index) { 48 driverName = driverNameElement1.attributeValue("value");//获取到name子节点的“value”属性值 49 driverNameElement = driverNameElement1;//将该节点赋值给driverElement,后续根据它来获得子节点 50 } 51 52 } 53 54 55 /** 56 * 通过类全名,反射出驱动类来 57 */ 58 try { 59 clazz = Class.forName(driverName); 60 } catch (ClassNotFoundException e) { 61 62 e.printStackTrace(); 63 } 64 65 /** 66 * 下面是解析XML中的系统参数以及能力参数 67 */ 68 69 Element propertiesElement = driverNameElement.element("properties"); 70 List<Element> propertyElements = propertiesElement.elements("property"); 71 72 //设置系统参数 73 for (Element property : propertyElements) { 74 75 System.setProperty(property.attributeValue("name"), property.attributeValue("value")); 76 77 } 78 79 //设置能力(ie的话,需要设置忽略域设置等级 以及忽略页面百分比的能力) 80 Element capabilitiesElement = driverNameElement.element("capabilities"); 81 if (capabilitiesElement != null) { 82 //创建能力对象 83 DesiredCapabilities realCapabilities = new DesiredCapabilities(); 84 //获得能力列表 85 List<Element> capabilitiesElements = capabilitiesElement.elements("capability"); 86 for (Element capability : capabilitiesElements) { 87 //遍历能力列表,并给能力赋值 88 realCapabilities.setCapability(capability.attributeValue("name"), true); 89 } 90 } 91 92 93 /* 94 * 通过反射,创建驱动对象 95 */ 96 97 try { 98 obj = clazz.newInstance(); 99 } catch (InstantiationException e) { 100 e.printStackTrace(); 101 } catch (IllegalAccessException e) { 102 e.printStackTrace(); 103 } 104 105 WebDriver driver = (WebDriver) obj; 106 return driver; 107 } 108 109 }
下面是驱动器配置文件:
<?xml version="1.0" encoding="UTF-8"?> <!-- 只需要修改下面的driverIndex 就可以去创建对应index的驱动--> <driver driverIndex="0"> <!-- 谷歌浏览器配置文件 --> <name value="org.openqa.selenium.chrome.ChromeDriver" index="0"> <properties> <property name="ChromeDriverService.CHROME_DRIVER_EXE_PROPERTY" value="E:/driver/chromedriver.exe" /> </properties> </name> <!-- 火狐浏览器 对应的selenium3.x版本 的配置文件 --> <name value="org.openqa.selenium.firefox.FirefoxDriver" seleniumVersion="3.x" index="1"> <properties> <property name="SystemProperty.BROWSER_BINARY" value="C:\Program Files (x86)\Mozilla Firefox\firefox.exe" /> <property name="GeckoDriverService.GECKO_DRIVER_EXE_PROPERTY" value="E:/driver/geckodriver.exe" /> </properties> </name> <!-- 火狐浏览器 对应的selenium2.x版本 的配置文件 --> <name value="org.openqa.selenium.firefox.FirefoxDriver" seleniumVersion="2.x" index="2"> <properties> <property name="SystemProperty.BROWSER_BINARY" value="C:\Program Files (x86)\Mozilla Firefox\firefox.exe" /> </properties> </name> <!--IE浏览器配置文件 --> <name value="org.openqa.selenium.ie.InternetExplorerDriver" index="3"> <properties> <property name="InternetExplorerDriverService.IE_DRIVER_EXE_PROPERTY" value="E:/driver/IEDriverServer.exe" /> </properties> <capabilities> <capability name="InternetExplorerDriver.IGNORE_ZOOM_SETTING" /> <capability name="InternetExplorerDriver.INTRODUCE_FLAKINESS_BY_IGNORING_SECURITY_DOMAINS" /> </capabilities> </name> </driver>
4.log4j的配置文件
###根logger设置###
log4j.rootLogger = INFO,console,file
### 输出信息到控制台###
log4j.appender.console = org.apache.log4j.ConsoleAppender
log4j.appender.console.Target = System.out
log4j.appender.console.layout = org.apache.log4j.PatternLayout
log4j.appender.console.Threshold = info
log4j.appender.console.layout.ConversionPattern = [%p] %d{yyyy-MM-dd HH:mm:ss} method: %l----%m%n
###输出INFO 级别以上的日志文件设置###
log4j.appender.file = org.apache.log4j.DailyRollingFileAppender
log4j.appender.file.File = E:/log/web.log
log4j.appender.file.Append = true
log4j.appender.file.Threshold = info
log4j.appender.file.layout = org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern = %d{yyyy-MM-dd HH:mm:ss} method: %l - [ %p ]----%m%n
5.将测试数据写到excel中,并提供一个读取excel的帮助类
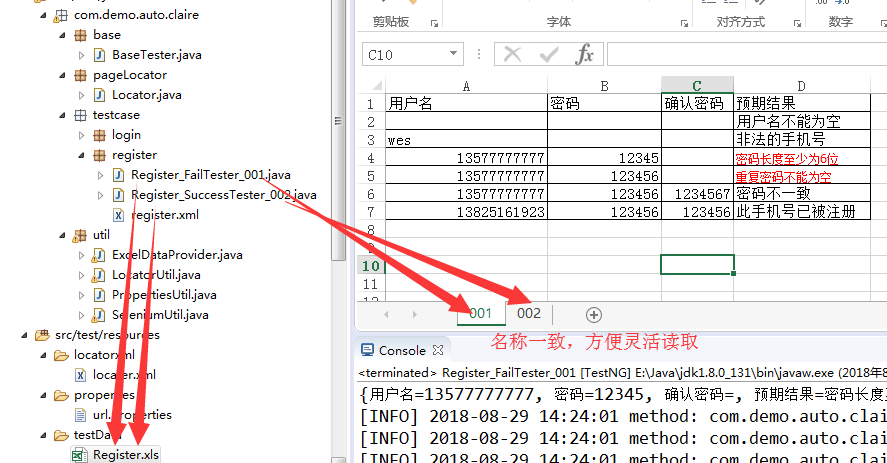
使用poi读取excel。读取出来的数据,可以封装成二维数组object[][]或者iterator(object[]),作为数据提供者,给测试用例使用。
由于二维数组的方式是一次性将所有的测试用例全部读出来的,当测试过程中出现问题或者数据量巨大的时候,再使用这种方式,会造成内存浪费。笔者建议大家使用迭代器的方式来实现。
下面是迭代器的方式(推荐使用):
package com.demo.auto.claire.util; import java.io.IOException; import java.io.InputStream; import java.util.Arrays; import java.util.HashMap; import java.util.Iterator; import java.util.LinkedHashMap; import java.util.Map; import org.apache.poi.EncryptedDocumentException; import org.apache.poi.openxml4j.exceptions.InvalidFormatException; import org.apache.poi.ss.usermodel.Cell; import org.apache.poi.ss.usermodel.CellType; import org.apache.poi.ss.usermodel.Row; import org.apache.poi.ss.usermodel.Row.MissingCellPolicy; import org.apache.poi.ss.usermodel.Sheet; import org.apache.poi.ss.usermodel.Workbook; import org.apache.poi.ss.usermodel.WorkbookFactory; /** * 解析存放到excel中的测试数据,提供给测试case使用。 * 读取的excel名称是取测试case的前半部分,如Register_SuccessTester_002,取的是 Register * 所以测试数据的excel取名必须注意!!! * @author cuijing * */ public class ExcelDataProvider implements Iterator<Object[]> { /** * example,测试使用: */ public static void main(String[] args) throws EncryptedDocumentException, InvalidFormatException, IOException { ExcelDataProvider dataProvider = new ExcelDataProvider("002","RegisterTester.xls"); while(dataProvider.hasNext()) { dataProvider.next(); } } Iterator<Row> itRow; Row currentRow ; Cell currentCell; String[] cloumnName; /** *该构造方法,通过指定的excel和该excel的指定sheet初始化列名数组 初始化行迭代器 * @param index */ public ExcelDataProvider(String sheetName,String fileName) { InputStream inp = ExcelDataProvider.class.getResourceAsStream("/testData/"+fileName+".xls"); Workbook workbook =null; try { workbook = WorkbookFactory.create(inp); } catch (EncryptedDocumentException | InvalidFormatException | IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } Sheet sheet = workbook.getSheet(sheetName); itRow = sheet.iterator(); if (itRow.hasNext()) { //获取到第一行 currentRow = itRow.next(); int length = currentRow.getLastCellNum(); cloumnName=new String[length]; /*//获取到第一行的每个单元格内容 for (int i = 0; i < cloumnName.length; i++) { cloumnName[i] = currentRow.getCell(i+1).getStringCellValue(); }*/ //得到第一行的迭代器 Iterator<Cell> cellIt = currentRow.iterator(); //将第一行的数据,填充到列名数组中 for (int i = 0; cellIt.hasNext(); i++) { currentCell=cellIt.next(); cloumnName[i]=currentCell.getStringCellValue(); } System.out.println(Arrays.toString(cloumnName)); } } /** * 通过行迭代器判断是否还有下一行 */ @Override public boolean hasNext() { if (itRow.hasNext()) { return true; } return false; } /** * 通过行迭代器获取到下一行,遍历下一行的所有单元格,将数据放到map中,再将map包装成object的数组 */ @Override public Object[] next() { //指向下一行 currentRow = itRow.next(); //遍历该行的单元格,并将单元格数据填充到map中 Map<String, String> map = new LinkedHashMap<>(); for (int i = 0; i < cloumnName.length; i++) { currentCell = currentRow.getCell(i, MissingCellPolicy.CREATE_NULL_AS_BLANK); currentCell.setCellType(CellType.STRING); map.put(cloumnName[i], currentCell.getStringCellValue()); } Object[] objects = {map}; System.out.println(map); return objects; } }
下面是二维数组的方式:
package com.claire.jing.utils; import java.io.IOException; import java.io.InputStream; import java.util.Arrays; import org.apache.poi.EncryptedDocumentException; import org.apache.poi.openxml4j.exceptions.InvalidFormatException; import org.apache.poi.ss.usermodel.CellType; import org.apache.poi.ss.usermodel.Row.MissingCellPolicy; import org.apache.poi.ss.usermodel.Sheet; import org.apache.poi.ss.usermodel.Workbook; import org.apache.poi.ss.usermodel.WorkbookFactory; public class ExcelDataProviderPOI { public static void main(String[] args) throws EncryptedDocumentException, InvalidFormatException, IOException { Object[][] objects = getDataProvider("001"); } public static Object[][] getDataProvider(String sheetName) throws EncryptedDocumentException, InvalidFormatException, IOException { Object[][] objects =null; InputStream inp = ExcelDataProviderPOI.class.getResourceAsStream("/testData/competitionSearch.xls"); Workbook workbook = WorkbookFactory.create(inp); Sheet sheet = workbook.getSheet(sheetName); int rowNum = sheet.getLastRowNum(); objects = new Object[rowNum][]; for (int i = 1; i <=rowNum; i++) { int columnNum = sheet.getRow(i).getLastCellNum(); System.out.println("第"+i +"行有"+columnNum+"列数据"); objects[i-1] = new Object[columnNum]; for (int j = 0; j < columnNum; j++) { sheet.getRow(i).getCell(j).setCellType(CellType.STRING); objects[i-1][j] = sheet.getRow(i).getCell(j,MissingCellPolicy.RETURN_NULL_AND_BLANK).getStringCellValue(); } } System.out.println(Arrays.deepToString(objects)); return objects; } }
6.将页面元素的定位信息写到xml中,并提供相应的解析帮助类,将其映射到指定对象中。
下面是xml文件
<?xml version="1.0" encoding="UTF-8"?> <pages> <!-- 代码是通过下面的pageName来定位去读取哪个页面的定位信息 pageName是取测试case的类名前半部分 如Register_SuccessTester_002,取的是 Register--> <!-- 注册页面 --> <page pageName="Register"> <locaters> <locator by="id" value="mobilephone" des="手机号输入框"></locator> <locator by="id" value="password" des="密码输入框"></locator> <locator by="id" value="pwdconfirm" des="确认密码输入框"></locator> <locator by="id" value="signup-button" des="注册按钮"></locator> <locator by="className" value="tips" des="提示信息"></locator> </locaters> </page> <!-- 登录页面 --> <page pageName="Login"> <locaters> <locator by="id" value="mobilephone" des="手机号输入框"></locator> <locator by="id" value="password" des="密码输入框"></locator> <locator by="id" value="login" des="登录按钮"></locator> <locator by="id" value="reset" des="重置按钮"></locator> </locaters> </page> </pages>
下面是xml文件的解析帮助类
package com.demo.auto.claire.util; import java.util.HashMap; import java.util.List; import java.util.Map; import org.dom4j.Document; import org.dom4j.DocumentException; import org.dom4j.Element; import org.dom4j.io.SAXReader; import com.demo.auto.claire.pageLocator.Locator; /** * 1.解析页面定位信息的Url,将解析内容装到map中 * <代码是通过下面的pageName来定位去读取哪个页面的定位信息 * pageName是取测试case的类名前半部分如Register_SuccessTester_002,取的是 Register * 所以页面定位信息的xml文件 取名必须注意!!! * * 2.将项目中用到的测试页面都写到一个xml中的,所以固定读取的是 /locatorxml/locater.xml * @author cuijing * */ public class LocatorUtil { public static void main(String[] args) { Locator locator = getLocator("RegisterTester", "手机号输入框"); System.out.println(locator.getBy()); } //将页面元素的定位信息存储在map中 //通过页面名称,获取到指定页面的所有定位信息 //通过定位元素的描述,获取到locator对象 private static Map<String,Map<String, Locator>> pageMap = new HashMap<>(); //该类第一次被使用,就会去读取指定xml文件(读取页面的所有元素定位信息) static { readXml(); } /** * * @param pageName * 页面名称 * @param desc * 元素的关键字描述 * @return */ public static Locator getLocator(String pageName,String desc) { //获取到指定页面的所有定位信息 Map<String, Locator> map = pageMap.get(pageName); //System.out.println("通过页面名称获取到页面所有定位信息"+map); //返回指定描述locator对象 Locator locator = map.get(desc); //System.out.println("通过关键字"+desc +"获取到locator对象"+locator); return locator; } /** * 读取xml文件 */ public static void readXml() { SAXReader reader = new SAXReader(); Document doucment = null; try { doucment = reader.read(LocatorUtil.class.getResourceAsStream("/locatorxml/locater.xml")); } catch (DocumentException e) { System.out.println("读取xml失败"); e.printStackTrace(); } //获取到根节点pages Element rootEleent = doucment.getRootElement(); //System.out.println("获取到根节点"+rootEleent.getName()); //获取到子节点page List<Element> elements = rootEleent.elements(); //System.out.println("获取到"+elements.size()+"个页面"); //遍历所有的page for (Element element : elements) { String pageName = element.attribute("pageName").getStringValue(); //System.out.println("pageName为" +pageName); //获取到page的子节点 locators Element locatorsElement = element.element("locaters"); //获取到所有的locator List<Element> locatorElements = locatorsElement.elements(); //创建map Map<String, Locator> LocatorMap = new HashMap<>(); for (Element locatorElement : locatorElements) { Locator locatorObj = new Locator(locatorElement.attributeValue("by"),locatorElement.attributeValue("value"),locatorElement.attributeValue("des")); //System.out.println(locatorObj); //通过描述信息,获取到locator对象 LocatorMap.put(locatorElement.attributeValue("des"), locatorObj); } pageMap.put(pageName, LocatorMap); System.out.println(pageMap); } } }
解析完成后映射到Locator类:
package com.demo.auto.claire.pageLocator; public class Locator { String by; String value; String desc; //getter setter public String getBy() { return by; } public void setBy(String by) { this.by = by; } public String getValue() { return value; } public void setValue(String value) { this.value = value; } public String getDesc() { return desc; } public void setDesc(String desc) { this.desc = desc; } //construction public Locator(String by, String value, String desc) { super(); this.by = by; this.value = value; this.desc = desc; } //toString @Override public String toString() { return "Locator [by=" + by + ", value=" + value + ", desc=" + desc + "]"; } }
7.BaseTester的设计
在每个测试进行之前,都要启动浏览器驱动--------将启动浏览器放到baseTester中
在每次测试执行之后,都要退出浏览器驱动,并关闭所有的相关窗口------------------将退出驱动放到BaseTester中
使用智能等待的方式获取元素,在获取元素的时候,使用xml文件的解析帮助类提供的方法,获取到Locator类,并通过反射获取到对应的定位元素方法。
可以对一些selenium的简单方法进行二次封装,使得测试脚本更加简洁,后续维护也更加简单。
还可以实现一个检查点技术(其实就是Assert,封装自己需要的assert方法)
下面是笔者部分的BaseTester代码,可以根据需要自行封装。
package com.demo.auto.claire.base; import java.lang.reflect.Method; import java.util.Iterator; import java.util.Map; import org.apache.log4j.Logger; import org.openqa.selenium.By; import org.openqa.selenium.WebDriver; import org.openqa.selenium.WebElement; import org.openqa.selenium.support.ui.ExpectedCondition; import org.openqa.selenium.support.ui.WebDriverWait; import org.testng.Assert; import org.testng.annotations.AfterSuite; import org.testng.annotations.BeforeSuite; import org.testng.annotations.DataProvider; import com.demo.auto.claire.pageLocator.Locator; import com.demo.auto.claire.util.ExcelDataProvider; import com.demo.auto.claire.util.LocatorUtil; import com.demo.auto.claire.util.PropertiesUtil; import com.demo.auto.claire.util.SeleniumUtil; public class BaseTester { public static WebDriver driver; static Map<String, Map<String, Locator>> pagesMap; Logger logger= Logger.getLogger(BaseTester.class); /** * 套件执行前,启动浏览器驱动 */ @BeforeSuite public void BeforSuit() { driver = SeleniumUtil.getDriver(); } /** * 套件执行后,退出当前浏览器驱动,关闭所有相关窗口 * @throws InterruptedException */ @AfterSuite public void afterSuit() throws InterruptedException { Thread.sleep(5000); driver.quit(); } /****************************数据提供者*****************************************/ public static void main(String[] args) { String className = "Register_FailTester_001"; int firstIndex = className.indexOf("_"); int lastIndex = className.lastIndexOf("_"); System.out.println(lastIndex); //获取到当前excel的名称(规定excel的名称与我们的类名第一个“_”前字符串相同) String excelName = className.substring(0, firstIndex); System.out.println("当前页面名称为"+excelName); String sheetName = className.substring(lastIndex+1); System.out.println("当前sheet名称为"+sheetName); } /** * 数据提供者。ExcelDataProvider是通过poi从excel读取的测试数据 * @return */ @DataProvider(name="dataProvider") public Iterator<Object[]> dataProvider(){ String className = this.getClass().getSimpleName(); int firstIndex = className.indexOf("_"); int lastIndex = className.lastIndexOf("_"); //获取到当前excel的名称(规定excel的名称与我们的类名第一个“_”前字符串相同) String excelName = className.substring(0, firstIndex); // System.out.println("当前excel名称为"+excelName); String sheetName = className.substring(lastIndex+1); // System.out.println("当前sheet名称为"+sheetName); return new ExcelDataProvider(sheetName,excelName); } /*****************************智能等待获取元素*****************************/ /** * 获取元素 * @param timeOut * 超时时间 * @param by * 获取元素方法 * @return * 返回获取到的元素 */ public WebElement getElement(int timeOut,By by) { WebDriverWait wait = new WebDriverWait(driver, timeOut); return wait.until(new ExpectedCondition<WebElement>() { @Override public WebElement apply(WebDriver driver) { return driver.findElement(by); } }); } /** * 获取元素,指定等待时间为5S * @param by * 获取元素 方法 * @return */ public WebElement getElement(By by) { return getElement(10, by); } /** * 通过关键字定位元素 * @param timeOut * 超时时间 * @param keyword * 元素关键字,通过该关键字定位到元素 * @return */ public WebElement getElement(int timeOut,String keyword) { //通过反射,获取到运行该方法对象的类名 //谁继承了该BaseTester类就获取到谁的类名 String className = this.getClass().getSimpleName(); int index = className.indexOf("_"); String pageName = className.substring(0, index); //System.out.println("当前页面名称为"+pageName); WebElement element = getElement(pageName, keyword, timeOut); return element; } /** * 获取指定页面名称和关键字的元素 * @param pageName * 页面名称 * @param keyword * 元素关键字 * @param timeOut * 超时时间 * @return * WebElement,返回查找到的元素 */ public WebElement getElement(String pageName,String keyword,int timeOut) { //locatorUtil类读取xml,并提供获取Locator的方法,locator对象里装的是by,value,desc //是通过当前运行对象的类名来当做pageName的 Locator locator = LocatorUtil.getLocator(pageName, keyword); //获取到定位方式 String byStr = locator.getBy();//这个对应到By类中的方法名,如id,name等(8大定位方法) String value = locator.getValue();//对应定位的值,如:By.id(value) WebDriverWait wait = new WebDriverWait(driver, timeOut); return wait.until(new ExpectedCondition<WebElement>() { @Override public WebElement apply(WebDriver driver) { By by = null; //通过反射,获取到By类的字节码文件。 Class<By> clazz = By.class; try { //通过反射,获取到指定名称的方法。 Method method = clazz.getDeclaredMethod(byStr, String.class); //调用获取到的方法。由于By中的方法是静态的,通过类调用。这里的对象为null。invoke之后返回的是object对象,强制类型转换为By对象 by = (By) method.invoke(null, value); }catch (Exception e) { e.printStackTrace(); } return driver.findElement(by); } }); } /** * 通过关键字定位元素,固定等待时间为5S(获取的是当前页面的元素) * @param keyword * 元素关键字,通过该关键字定位到元素 * @return */ public WebElement getElement(String keyword) { return getElement(5, keyword); } /************************selenium简单方法的二次封装***********************************/ /** * 向指定元素输入内容,对sendKeys方法的二次包装 * @param keyWord * 元素关键字,通过该关键字定位到元素 * @param context * 要输入的内容 */ public void sendkeys(String keyword,String context) { WebElement targetElement = null; try { targetElement = getElement(keyword); targetElement.sendKeys(context); logger.info("成功向元素"+targetElement +"输入内容"+context); } catch (Exception e) { logger.error("向元素"+targetElement +"输入内容"+context+"失败"); e.printStackTrace(); } } /** * 获取到指定元素,并点击 * @param keyword * 元素关键字,通过该关键字定位到元素 */ public void click(String keyword) { WebElement targetElement=null; try { targetElement = getElement(keyword); targetElement.click(); logger.info("点击元素"+targetElement); } catch (Exception e) { logger.error("点击元素"+targetElement+"失败"); e.printStackTrace(); } } /** * 获取指定元素上的文本信息 * @param keyword * 元素关键字,通过该关键字定位到元素 * @return */ public String getText(String keyword) { WebElement targetElement = null; String text = null; try { targetElement = getElement(keyword); logger.info("获取元素文本信息"); text = targetElement.getText(); } catch (Exception e) { logger.error("获取元素文本信息失败"); e.printStackTrace(); } return text; } public void toUrl(String propertiesKey) { String url = PropertiesUtil.getProperties(propertiesKey); driver.get(url); } /**********************************************检查点Assert************************************************************/ /** * 检查元素文本与预期文本是否相同 * @param keyword * 元素关键字,通过该关键字定位到元素 * @param expected * 预期文本 */ public void assertTextEquals(String keyword,String expected) { WebElement targetElement = getElement(keyword); String actual = targetElement.getText(); Assert.assertEquals(actual, expected); } public void assertCanGetPointElement(String pageName,String keyword) { WebElement targetElement = getElement(pageName,keyword,5); Assert.assertFalse(targetElement==null); } /*********************************************************/ }
上述BaseTester类中,封装了一个打开指定url的方法,其中是将url写到了url.properties文件中,并提供了解析帮助类。
url.properties文件
register=http://XXXX.html
login=http://XXXX.html
解析帮助类:
package com.demo.auto.claire.util;
import java.io.IOException;
import java.util.Properties;
/**
* 该类专门用来处理properties文件
* @author cuijing
*
*/
public class PropertiesUtil {
public static void main(String[] args) {
System.out.println(getProperties("register"));
}
static Properties properties = new Properties();
//只加载一次配置文件
static {
readURLProperties();
}
/**
* 加载配置文件
*/
private static void readURLProperties() {
try {
properties.load(PropertiesUtil.class.getResourceAsStream("/properties/url.properties"));
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 通过配置文件中的 key获取到value
* @param propertiesKey
* 配置文件中的key
* @return
*/
public static String getProperties(String propertiesKey) {
return properties.getProperty(propertiesKey);
}
}
5.编写测试cese
编写测试用例的时候,通常都分为正向测试用例和反向测试用例。将登录页面的测试case分为Register_FailTester_001和Register_SuccessTester_002。
每一个测试脚本都继承自BaseTester
注意:该类名的第一个字段Register 必须与测试数据的excel文件和页面定位信息中的pageName一致,第三个字段001或002必须与测试数据的excel中的sheet同名。
方便后期灵活的去读取相应的测试数据和元素定位信息
反向测试脚本:
package com.demo.auto.claire.testcase.register; import java.util.Map; import org.testng.annotations.Test; import com.demo.auto.claire.base.BaseTester; public class Register_FailTester_001 extends BaseTester{ /** * 注册失败的用例 * @param data * @throws InterruptedException */ @Test(dataProvider="dataProvider") public void test_register_failure_001(Map<String, String> data) throws InterruptedException { //到指定页面去 toUrl("register"); //向手机号码输入框输入测试数据 sendkeys("手机号输入框", data.get("用户名")); sendkeys("密码输入框", data.get("密码")); sendkeys("确认密码输入框", data.get("确认密码")); //点击注册按钮 click("注册按钮"); Thread.sleep(1000); //断言用例是否成功 assertTextEquals("提示信息", data.get("预期结果")); } }
正向测试脚本:
package com.demo.auto.claire.testcase.register; import java.util.Map; import org.testng.annotations.Test; import com.demo.auto.claire.base.BaseTester; public class Register_SuccessTester_002 extends BaseTester{ /** * 注册成功的用例 * @param data * @throws InterruptedException */ @Test(dataProvider="dataTestersuccess",enabled=false) public void test_register_success_002(Map<String, String> data) throws InterruptedException { toUrl("register"); sendkeys("手机号输入框", data.get("用户名")); sendkeys("密码输入框", data.get("密码")); sendkeys("确认密码输入框", data.get("确认密码")); click("注册按钮");//此时会跳转到登录页面 Thread.sleep(1000);//等待页面成功跳转 assertCanGetPointElement("LoginTester", "登录按钮"); } }
可以看到,此时的测试脚本非常的清晰易读。
该框架还未实现截图、发邮件、定时跑的功能。后期更新。。。

