
1.用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)进行词频统计。
(1)我下载了英文小说《追风筝的人》,改成story.txt,来进行操作
首先,启动hadoop
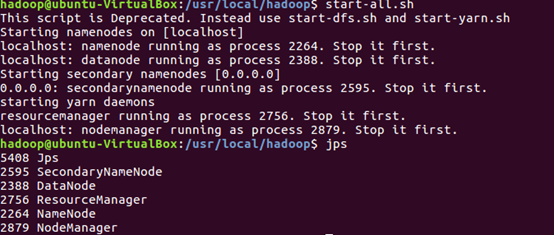
Hdfs上创建文件夹

上传文件到HDFS

启动hive

在story数据库建表storydocs,
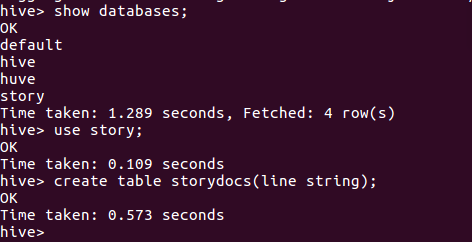
导入文件内容到storydocs并查看

select * from storydocs;

用HQL进行词频统计,结果放在表storydocs_count里
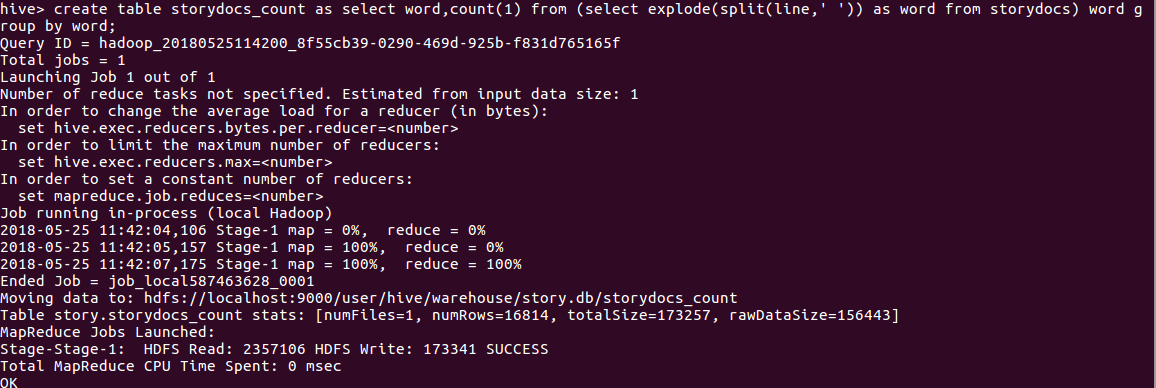
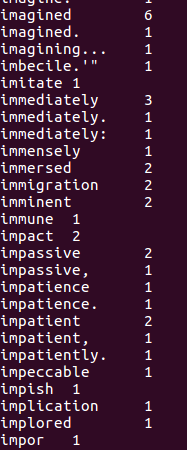
查看统计结果(截图为部分截图)
2.用Hive对爬虫大作业产生的csv文件进行数据分析,写一篇博客描述你的分析过程和分析结果。
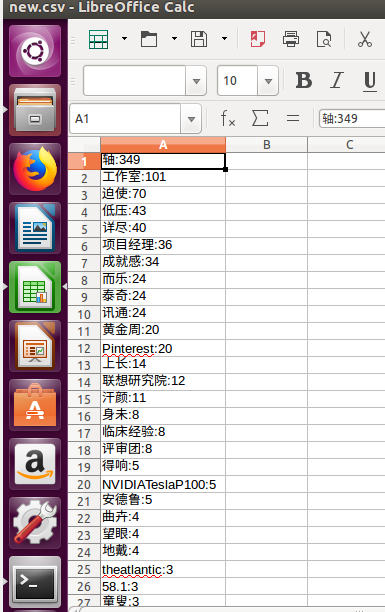
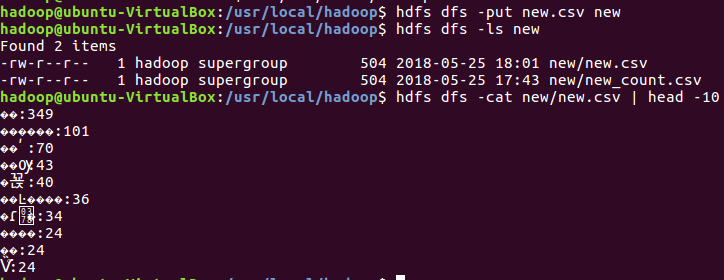
1.将大数据产生的csv文件改名new.csv,存到虚拟机,然后上传到hdfs 并查看前十条数据

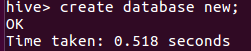
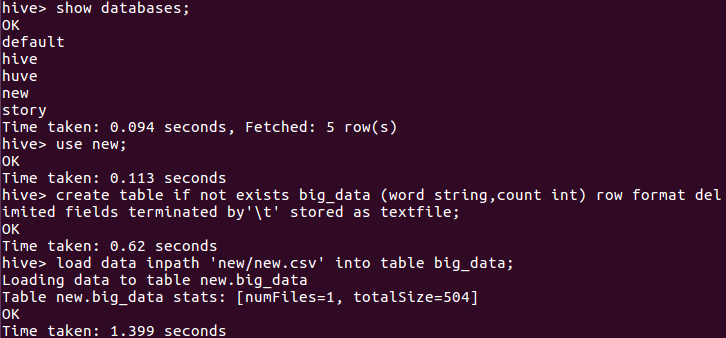
2.启动hive,启动hive,建new数据库,建表格big_data,把wordcount.csv里的数据导进该表并查询前10条记录
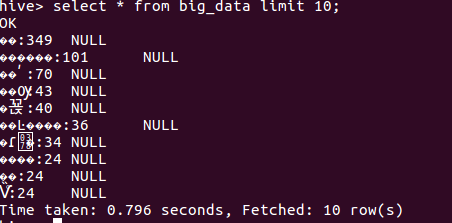
结论:数据能够进行正常的数据统计分析。
问题:由于编码问题,导致上传到hdfs的csv文件是乱码,尚未找到解决办法
