9 文本处理工具
9 文本处理工具
1 文本处理工具介绍
Linux上文本处理三剑客:
- grep,egrep,fgrep :文本过滤工具(以模式:pattern 进行过滤)
- grep:支持基本正则表达式,-E 选项可以支持扩展正则表达式,-F 选项支持 fgrep
- egrep:扩展正则表达式,-G 选项可以支持基本正则表达式,-F 选项支持 fgrep
- fgrep:不支持正则表达式
- sed:stream editor,流编辑;文本编辑工具
- awk:Linux上的实现为gawk,文本报告生成器(格式化文本)
2 grep
2.1 grep
2.1.1 grep 简介
grep:Global search REgular expression and Print out the line
作用:文本搜索工具,根据用户指定的模式对目标文本逐行进行匹配检查,打印匹配到的行
模式:由正则表达式元字符及文本字符所编写出的过滤条件
正则表达式相关内容可参考博文:https://www.cnblogs.com/ckh2014/p/14100791.html
2.1.1 grep 使用格式
grep [OPTIONS] PATTERN [FILE...]
grep [OPTIONS] [-e PATTERN | -f FILE] [FILE...]
常用选项:
- --color=auto :对匹配到的文本着色后高亮显示
- -i :ignorecase,忽略字符大小写
- -o :仅显示匹配到的字符串本身
- -v,--invert-match :显示不能够被pattern匹配到的行
- -E :支持使用扩展的正则表达式元字符
- -q,--quiet,--slient :静默模式,即不输出任何信息
- -A #:after,后#行
- -B #:before,前#行
- -C #:context,前后各#行
2.1.2 grep 示例
1、显示/etc/passwd文件中不以/bin/bash结尾的行
[root@node2 ~]# grep -v /bin/bash$ /etc/passwd
2、找出/etc/passwd文件中两位数或三位数
[root@node2 ~]# grep "\<[0-9]\{2,3\}\>" /etc/passwd
3、找出/etc/rc.d/rc.sysinit或/etc/grub2.cfg文件中,以至少一个空白字符开头,且后面非空白字符的行
[root@node2 ~]# grep "^[[:space:]]\+[^[:space:]]" /etc/grub2.cfg
4、找出"netstat -atn"命令的结果中以"LISTEN"后跟0、1或多个空白字符结尾的行
[root@node2 ~]# netstat -atn | grep "LISTEN[[:space:]]*$"
2.2 egrep
2.2.1 egrep 简介
egrep 支持扩展的正则表达式实现类似于grep文本过滤功能;grep -E
2.2.2 egrep 使用格式
egrep [OPTIONS] PATTERN [FILE...]
egrep [OPTIONS] [-e PATTERN | -f FILE] [FILE...]
常用选项:
- --color=auto :对匹配到的文本着色后高亮显示
- -i :ignorecase,忽略字符大小写
- -o :仅显示匹配到的字符串本身
- -v,--invert-match :显示不能够被pattern匹配到的行
- -G:支持基本正则表达式
- -q,--quiet,--slient :静默模式,即不输出任何信息
- -A #:after,后#行
- -B #:before,前#行
- -C #:context,前后各#行
2.2.3 egrep示例
练习1:
1、显示/etc/passwd文件中不以/bin/bash结尾的行
[root@node2 ~]# egrep -v "/bin/bash$" /etc/passwd
2、找出/etc/passwd文件中两位数或三位数
[root@node2 ~]# egrep "[0-9]{2,3}" /etc/passwd
3、找出/etc/rc.d/rc.sysinit或/etc/grub2.cfg文件中,以至少一个空白字符开头,且后面非空白字符的行
[root@node2 ~]# egrep "^[[:space:]]+[^[:space:]]" /etc/grub2.cfg
4、找出"netstat -atn"命令的结果中以"LISTEN"后跟0、1或多个空白字符结尾的行
[root@node2 ~]# netstat -atn | egrep "LISTEN[[:space:]]*$"
练习2:
1、找出 /proc/meminfo 文件中,所有以大写或小写S开头的行;至少有三种实现方式;
[root@node2 ~]# grep -i "^[Ss]" /proc/meminfo
[root@node2 ~]# grep -i ^s /procmeminfo
[root@node2 ~]# egrep -i ^S /proc/meminfo
[root@node2 ~]# grep -E "^(s|S)" /proc/meminfo
2、显示当前系统上root、centos或user1用户的相关信息;
[root@node2 ~]# egrep "^(root|centos|user1)\>" /etc/passwd
3、找出 /etc/rc.d/init.d/functions 文件中某单词后面跟一个小括号的行;
[root@node2 ~]# egrep "^[_[:alnum:]]+\(\)" /etc/rc.d/init.d/functions
4、使用echo命令输出一绝对路径,使用egrep取出基名;
[root@node2 ~]# echo "/proc/sys/net/ipv4/ip_forward" | grep -E -o "[^/]+/?$"
进一步,取出其路径名:
[root@node2 ~]# echo "/proc/sys/net/ipv4/ipforward/" | grep -E -o "^/.*/\b"
5、找出ifconfig 命令结果中的 1-255 之间的数值;
[root@node2 ~]# ifconfig | grep -E -o "\<([1-9]|[1-9][0-9]|1[1-9][0-9]|2[0-4][0-9]|25[0-5])\>"
6、找出ifconfig命令结果中的IP地址;
[root@node2 ~]# ifconfig | grep -E -o "\<([1-9]|[1-9][0-9]|1[1-9][0-9]|2[0-4][0-9]|25[0-5])\>.\<([1-9]|[1-9][0-9]|1[1-9][0-9]|2[0-4][0-9]|25[0-5])\>.\<([1-9]|[1-9][0-9]|1[1-9][0-9]|2[0-4][0-9]|25[0-5])\>.\<([1-9]|[1-9][0-9]|1[1-9][0-9]|2[0-4][0-9]|25[0-5])\>"
172.26.255.255
172.17.255.255
192.168.2.12
192.168.2.255
[root@node2 ~]# ifconfig | grep -E -o "(\<([1-9]|[1-9][0-9]|1[1-9][0-9]|2[0-4][0-9]|25[0-5])\>.){3}(\<([1-9]|[1-9][0-9]|1[1-9][0-9]|2[0-4][0-9]|25[0-5])\>)"
7、添加用户 bash,testbash,basher以及nologin(其shell为/sbin/nologin);而后找出/etc/passwd文件中用户名同shell名的行;
[root@node2 ~]# grep -E "^([[:alnum:]_]+\b).*\1$" /etc/passwd
[root@node2 ~]# grep -E "^([^:]+\>).*\1$" /etc/passwd
2.3 fgrep
fgrep 不支持正则表达式元字符。
当无需用到元字符去编写模式时,使用 fgrep 性能更好。
3 文本查看及处理工具:wc,cut,sort,uniq,diff,patch
3.1 wc
wc - word count,print newline, word, and byte counts for each file
使用格式:wc [OPTION]... [FILE]...
常用选项:
-
-l :lines,统计行数
-
-w :words,统计单词数
-
-c :bytes,统计字节数
3.2 cut
cut - 文本截取工具,remove sections from each line of files
使用格式:cut OPTION... [FILE]...
常用选项:
-
-d CHAR:以指定的字符为分隔符
-
-f fields: 挑选出的字段
-
#:指定的单个字段
-
#,#[,#]:离散的多个字段
-
#-# :连续的多个字段
-
--output-delimiter=STRING :指明输出时的分隔符
-
3.3 sort
sort - sort lines of text files
使用格式:sort [OPTION]... [FILE]...
常用选项:
-
-f :忽略字母大小写
-
-r :逆序显示
-
-t CHAR :指定字段分隔符
-
-k # :以指定字段为标准排序
-
-n :以数值大小进行排序
-
-u :uniq,重复的行只保留一份
- 重复的行:连续且相同方为重复
3.4 unique
uniq - report or omit repeated lines,报告或移除重复的行
使用格式:uniq [OPTION]... [INPUT [OUTPUT]]
-
-c :显示每行重复出现的次数
-
-d :仅显示重复过的行
-
-u :仅显示不曾重复的行
练习:以冒号分隔,取出/etc/passwd文件的第6至第10行的各自的第1个字段,并将这些信息按第三个字段的数值大小排序
head -10 /etc/passwd | tail -5 | sort -t: -k3 -n | cut -d:-f1
练习:取出 ifconfig ens33 命令结果中的 ip 地址
[root@node2 ~]# ifconfig ens33 | grep "inet\>" | cut -d" " -f10
192.168.2.12
3.5 diff 和 patch
diff - compare files line by line,逐行比较文件中的内容
使用格式:diff [OPTION]... FILES
dff /PATH/TO/OLDFILE /PATH/TO/NEWFILE > /PATH/TO/PATCH_FILE
- -u :使用 unfield 机制,即显示要修改的行的上下文,默认为3行
patch - apply a diff file to an original,向文件打补丁
使用格式:
patch [OPTIONS] -i /PATH/TO/PATCH_FILE /PATH/TO/OLDFILE
patch /PATH/TO/OLDFILE < /PATH/TO/PATCH_FILE
范例:
[root@node2 ~]# cp /etc/fstab ./
[root@node2 ~]# cp fstab fstab.new
[root@node2 ~]# vim fstab.new
[root@node2 ~]# diff fstab fstab.new
2c2
< #
---
> # comment
[root@node2 ~]# diff fstab fstab.new > fstab.patch # 比较原文件和新文件的不同之处,将结果保存在 补丁文件中
[root@node2 ~]# patch -i fstab.patch fstab # 对原文件打补丁
patching file fstab
[root@node2 ~]# patch -R -i fstab.patch fstab # 还原文件,逆向打补丁
patching file fstab
4 sed
4.1 sed 工作模式
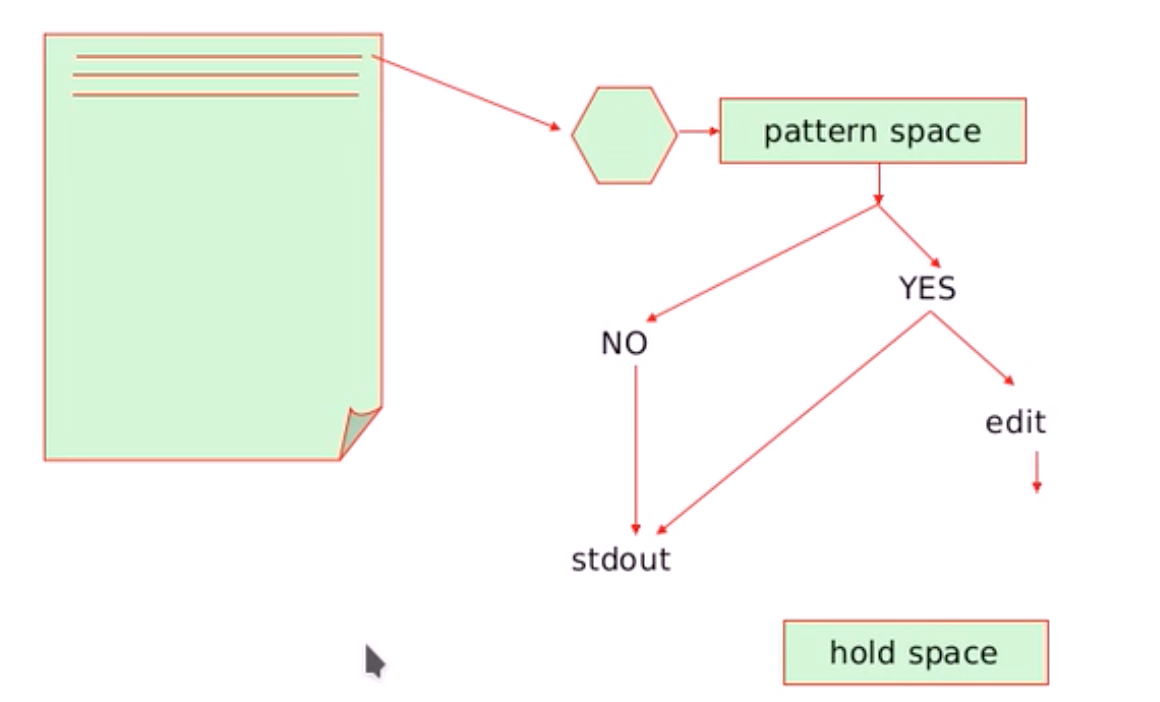
4.2 sed 使用格式
使用格式:sed [option]... 'script' inputfile...
script:
- 地址定界编辑命令
常用选项:
- -n:不输出模式空间中的内容至屏幕
- -i[SUFFIX], --in-place[=SUFFIX]:直接编辑原文件,慎用
- -e script,--expression=script:多点编辑
- -f /PATH/TO/SED_SCRIPT_FILE:从指定文件中读取编辑脚本
- 每行一个编辑命令
- -r:支持使用扩展正则表达式
地址定界:
(1)空地址,是对全文进行处理
(2)单地址
-
#:指定行
-
/pattern/:被此处模式所能匹配到的每一行
(3)地址范围
-
#,# :从第几行到第几行
-
#,+# :从第几行加多少行为止
-
#,/pat1/:从指定的行开始到第一次能够被模式所匹配到的行结束
-
/pat1/,/pat2/:从pat1模式匹配到pat2模式匹配
(4)步进:~
- 1~2:从第一行开始,每两行进行处理,即所有奇数行
- 2~2:从第二行开始,每两行进行处理,即所有偶数行
(5)$:最后一行
编辑命令:
- d:删除模式空间中匹配到的行
- p:显示模式空间中匹配到的行
- a \text:模式空间中匹配到的行后面添加内容,支持使用\n 实现多行追加
- i \text:模式空间中匹配到的行前面插入内容,支持使\n 实现多行插入
- c \text:将匹配到的行替换为此处指定的文本”text“
- w /PATH/TO/SOMEFILE:保存模式空间中匹配到的行至指定文件中
- r /PATH/FORM/SOMEFILE:读取指定文件的内容至模式空间中匹配到的行后面;文件合并;
- =:为模式空间中匹配到的行打印行号
- !:取反条件
- 地址定界!编辑命令
- s///:查找替换,其分隔符可自行指定,常用的有s@@@,s###等
- 替换标记:
- g:行内全局替换
- p:显示替换成功的行
- w /PATH/TO/SOMEFILE:将替换成功的结果保存至指定文件中
4.3 sed 示例
-
d命令
删除uuid开头的行
[root@localhost ~]# sed '/^UUID/d' /etc/fstab
删除空白行
[root@localhost ~]# sed '/^$/d' /etc/fstab
删除指定行,比如删除1-4行
[root@localhost ~]# sed '1,4d' /etc/fstab -
p命令
显示UUID开头的行
[root@localhost ~]# sed '/^UUID/p' /etc/fstab
这样的结果中不匹配到的行也会打印而且匹配到的行会打印两遍,可以使用-n不显示默认打印 -
a \text
[root@localhost ~]# sed '/^UUID/a \hello\nworld' /etc/fstab //可以添加多行,\n -
i \text
[root@localhost ~]# sed '/^UUID/i \helloworld\nmy' /etc/fstab //可以添加多行,\n -
c \text
[root@localhost ~]# sed '/^UUID/c \uuid' /etc/fstab -
w FILE
[root@localhost ~]# sed '/^UUID/w /tmp/a.txt' /etc/fstab -
r FILE
[root@localhost ~]# sed '6r /etc/issue' /etc/fstab -
=
[root@localhost ~]# sed '/^UUID/=' /etc/fstab -
!
[root@node2 ~]# sed '/^#/!d' /etc/fstab //删除不以#开头的行 -
sed
将UUID替换为小写
[root@localhost ~]# sed 's@UUID@uuid@' /etc/fstab
删除/boot/grub/grub.conf文件中所有以空白开头的行行首的空白字符
[root@localhost ~]# sed 's@^[[:space:]]\+@@' /boot/grub/grub.conf
删除/etc/fstab文件中所有以#开头,后面至少跟一个空白字符的行的行首的#和空白字符
[root@localhost ~]# sed 's@^#[[:space:]]*@@' /etc/fstab
echo一个绝对路径给sed命令,取出其基名,取出其目录名
路径名:[root@localhost ~]# echo "/etc/rc.d/rc3.d/init/" | sed 's@[^/]\+/\?$@@'
基名:[root@localhost ~]# echo "/etc/rc.d/rc3.d/init/" | sed 's@^/.*/\([^/]\+/\?\)@\1@' -
-e 多点编辑
[root@node2 ~]# sed -e 's@^#[[:space:]]*@@' -e '/^UUID/d' /etc/fstab
高级编辑命令:
- h:将模式空间中的内容覆盖至保持空间中
- H:将模式空间中的内容追加至保持空间中
- g:将保持空间中的内容覆盖至模式空间中
- G:将保持空间中的内容追加至模式空间中
- n:覆盖读取匹配到的行的下一行至模式空间中,此时,原有的行被覆盖掉
- N:追加读取匹配到的行的下一行至模式空间中
- d:删除模式空间中匹配到的行
- D:删除多行模式空间中的所有行
- x:把模式空间中的内容与保持空间中的内容互换
示例:
sed -n 'n;p' FILE:显示偶数行
sed '1!G;h;$!d' FILE: 逆序显示文件内容
sed '$!N;$!D' FILE:取出文件后两行
sed '$!d' FILE: 取出最后一行
sed 'G' FILE: 每行下面添加一个空白行
sed '/^$/d;G' FILE 删除原有的所有空白行,而后为所有的非空白行后添加一个空白行
sed 'n;d' FILE: 显示奇数行
sed -n '1!G;h;$p' FILE:逆向显示文件中的每一行
5 AWk
5.1 awk 简介
awk:报告生成器,格式化文本输出
AWK:Aho,Weinberger,Kernighan --> New AWK,NAWK
gawk - pattern scanning and processing language
在 linux系统上,awk 是指向 gawk 命令的链接。
5.2 awk 工作模式
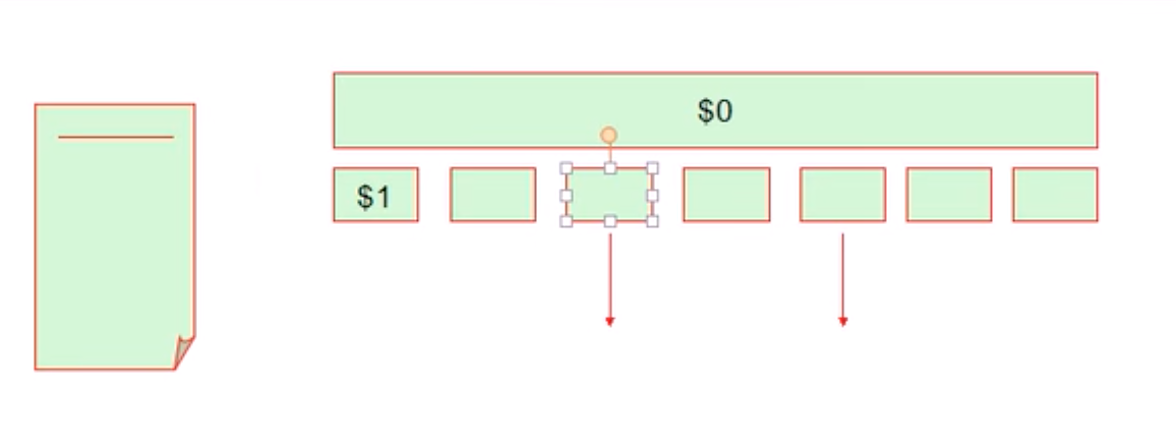
它的工作模式是对文本逐行进行处理,将每一行文本按照输入时分隔符(默认分隔符为空白字符)切片,把每一个切片直接保存在用awk内建的变量中,然后可以对每一片内容进行输出、循环等操作。如果要显示整行内容用 $0 来表示。
5.3 awk 使用格式 和 常用选项
基本用法:awk [options] 'program' FILE...
program: PATTERN{ACTION STATEMENTS},语句之间用分号分隔
常用选项:
- -F:指明输入时用到的字段分隔符
- -v var=VALUE:自定义变量
示例:
1、/etc/fstab 文件中以 UUID 开头的行,打印第2 和 第 4个字段
[root@localhost scripts]# awk '/^UUID/{print $2,$4}' /etc/fstab
/boot defaults
swap defaults
2、指明输入时字段分隔符为 : ,打印第1个切片内容,比如对/etc/passwd处理
[root@localhost scripts]# awk -F: '{print $1}' /etc/passwd
root
bin
daemon
3、使用内建变量FS指明输入时的分给福为冒号,打印第一个片段的内容
[root@node2 ~]# awk -v FS=":" '{print $1}' /etc/passwd
root
bin
daemon
5.4 常用命令
5.4.1 print
使用格式:print item1,item2,...
要点:
(1)item之间用逗号分隔
(2)输出的各item可以是字符串,也可以是数值;也可以是当前记录的字段、变量或awk的表达式;
(3)如果省略item,相当于 print $0,打印整行内容
范例:
print后面不跟 item 时,是将整行内容输出,相当于 print $0
[root@node2 ~]# awk '{print}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
对比一下:如果是 print "",结果是?
[root@node2 ~]# awk '{print ""}' /etc/passwd 显示空白行
5.4.2 变量
5.4.2.1 内建变量
-
FS:input field seperator,输入时的分隔符,默认为空白字符
-
OFS:output field seperator,输出时的分隔符,默认为空白字符
-
RS:input record seperator,输入时的换行符
-
ORS:output record seperator,输出时的换行符
-
NF:number of field,字段数量
-
NR:number of record,行数
-
FNR:各文件分别计数:行数
-
FILENAME:当前文件名
-
ARGC:命令行参数的个数
-
ARGV:数组,保存的是命令行所给定的各参数
内建变量相关示例
1、FS:指明输入时的分隔符为冒号,打印第一个片段
[root@node2 ~]# awk -v FS=':' '{print $1}' /etc/passwd
root
bin
2、OFS:指明输入时分隔符为冒号,输出时分隔符为@@,打印第2、3、7 字段
[root@node2 ~]# awk -F: -v OFS='@@' '{print $2,$3,$7}' /etc/passwd
x@@0@@/bin/bash
x@@1@@/sbin/nologin
x@@2@@/sbin/nologin
3、RS:指明输入时的换行符为'o',打印第1、3 片段
[root@localhost scripts]# awk -v RS='o' '{print $1,$3}' /etc/passwd
4、ORS:指明输出时的换行符为'##'
[root@node2 ~]# awk -v RS=':' -v ORS='##' '{print $0}' /etc/passwd
root##x##0##0##root##/root##/bin/bash
bin##x##1##1##bin##/bin##/sbin/nologin
5、NF
显示每行多少段
[root@node2 ~]# awk -F: '{print NF}' /etc/passwd
7
7
显示最后一个片段的值
[root@node2 ~]# awk -F: '{print $NF}' /etc/passwd
/bin/bash
/sbin/nologin
/sbin/nologin
6、NR
显示每一行的行数
[root@localhost scripts]# awk '{print NR}' /etc/passwd
1
2
对比一下 $NR 打印的值
[root@node2 ~]# awk -F: '{print $NR}' /etc/passwd
root
x
2
4
lp
/sbin
/sbin/shutdown
7、FNR
显示 /etc/passwd 和 /etc/fstab 两个文件的行号
[root@node2 ~]# awk '{print FNR}' /etc/passwd /etc/fstab
1
2
3
1
2
3
4
8、FILENAME
[root@node2 ~]# awk '{print FILENAME}' /etc/fstab
/etc/fstab
/etc/fstab
9、ARGC 和 ARGV
[root@node2 ~]# awk 'BEGIN{print ARGC}' /etc/fstab /etc/passwd
3
[root@node2 ~]# awk 'BEGIN{print ARGV[0]}' /etc/fstab /etc/passwd
awk
[root@node2 ~]# awk 'BEGIN{print ARGV[1]}' /etc/fstab /etc/passwd
/etc/fstab
[root@node2 ~]# awk 'BEGIN{print ARGV[2]}' /etc/fstab /etc/passwd
/etc/passwd
5.4.2.2 自定义变量
(1)-v var=value
(2)在program中直接定义
示例:
[root@node2 ~]# awk -v test="hello awk" 'BEGIN{print test}'
hello awk
[root@node2 ~]# awk 'BEGIN{test="hello awk";print test}'
hello awk
5.4.3 printf
格式化输出:printf FORMAT,item1,item2,...
要点:
(1)FORMAT 必须给出
(2)不会自动换行,需要显示给出换行控制符,\n
(3)FORMAT中需要分别为后面的每个item指定一个格式化符号
格式符:
- %c:显示字符的ASCII码
- %d,%i:显示十进制整数
- %e,%E:科学计数法数值显示
- %f:显示为浮点数
- %g,%G:以科学计数法或浮点形式显示数值
- %s:显示字符串
- %u:无符号整数
- %%:显示%自身
修饰符:
- #[.#]:第一个#数字控制显示的宽度,第二个#表示小数点后的精度,比如 %3.1f
- 默认是右对齐
- - :左对齐
- + :显示数值的符号
范例:
[root@node2 ~]# awk -F: '{printf "username:%s\n",$1}' /etc/passwd
username:root
username:bin
username:daemon
username:adm
username:lp
如果要显示两个字段:默认是右对齐
[root@node2 ~]# awk -F: '{printf "Username:%s,Uid:%d\n",$1,$3}' /etc/passwd
Username:root,Uid:0
Username:bin,Uid:1
Username:daemon,Uid:2
第一个字段设置字符串宽度为 15:
[root@node2 ~]# awk -F: '{printf "Username:%15s,Uid:%d\n",$1,$3}' /etc/passwd
Username: root,Uid:0
Username: bin,Uid:1
Username: daemon,Uid:2
第一个字段设置宽度为 15,并且设置为左对齐:
[root@node2 ~]# awk -F: '{printf "Username:%-15s,Uid:%d\n",$1,$3}' /etc/passwd
Username:root ,Uid:0
Username:bin ,Uid:1
Username:daemon ,Uid:2
5.4.4 操作符
- 算术操作符
- x+y,x-y,x*y,x/y,x^y,x%y
- -x :把一个整数转为负数
- +x :把一个字符串转换为数值
- 字符串操作符 :没有符号的操作符,字符串连接之意
- 赋值操作符
- =,+=,-=,*=,/=,%=,^=
- ++,--
- 比较操作符
- >,>=,<,<=,!=,==
- 模式匹配符
- ~:左侧的字符串是否能够被右侧的模式所匹配
- !~:左侧的字符串是否不能够被右侧的模式所匹配
- 逻辑操作符
- &&
- ||
- !
- 函数调用
- function_name(arg1,arg2,...)
- 条件表达式
- selector?if-true-expression:if-false-expression
- 条件表达式示例
条件表达式示例:
显示 id 号大于1000 为系统用户,小于等于1000为普通用户
[root@node2 ~]# awk -v FS=':' '{$3>1000?usertype="common user":usertype="sysadm";printf "%-15s:%-15s,Uid:%d\n",usertype,$1,$3}' /etc/passwd
sysadm :root ,Uid:0
sysadm :chrony ,Uid:997
common user :hadoop ,Uid:1001
common user :centos ,Uid:1002
5.4.5 PATTERN
(1)empty:空模式,匹配每一行
示例:空模式,即匹配到每一行
[root@node2 ~]# awk -F: '{print $1}' /etc/passwd
root
bin
daemon
(2)/regular expression/:仅处理能够被此处的模式匹配到的行
示例:显示以 UUID 开头的行:
[root@node2 ~]# awk -F: '/^UUID/{print}' /etc/fstab
UUID=f1a9b50d-7606-449c-90ae-a39f421cc685 /boot ext4 defaults 1 2
UUID=74a2b3e5-775e-48d5-b26d-48358ebdd1c8 swap swap defaults 0 0
(3)relational expression:关系表达式,结果有”真“有“假”;结果为”真“才会被处理
- 真:结果为非0值,非空字符串
示例:显示 uid 大于 1000 的行:
[root@node2 ~]# awk -F: '$3>1000{print}' /etc/passwd
hadoop:x:1001:1001::/home/hadoop:/bin/bash
centos:x:1002:1002::/home/centos:/bin/bash
判断最后一个片段的值是否为 /bin/bash,如果是就打印出第 1 和 7 个片段:
[root@node2 ~]# awk -F: '$NF=="/bin/bash"{print $1,$7}' /etc/passwd
root /bin/bash
chegnkaihua /bin/bash
hadoop /bin/bash
判断最后一个片段能够被右侧的模式所匹配,匹配的话就打印第1和第7个字段:
[root@node2 ~]# awk -F: '$NF~/bash$/{print $1,$7}' /etc/passwd
root /bin/bash
chegnkaihua /bin/bash
hadoop /bin/bash
(4)line ranges:行范围
- startline,endline;/pat1/,/pat2/
注意:不支持直接给出数字的格式
示例:显示 第10行到第15行范围内的内容:
[root@node2 ~]# awk -F: 'NR>10&&NR<=15{print}' /etc/passwd
games:x:12:100:games:/usr/games:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
nobody:x:99:99:Nobody:/:/sbin/nologin
systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
dbus:x:81:81:System message bus:/:/sbin/nologin
显示 匹配root开头的行到匹配daemon开头的行中间的内容:
[root@node2 ~]# awk -F: '/^root/,/^daemon/{print}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
(5)BEGIN/END模式
- BEGIN{}:仅在开始处理文本之前执行一次
- END{}:仅在文本处理完成之后执行一次
[root@localhost scripts]# awk -F: 'BEGIN{print " USERNAME UID \n-------------------------------"}{printf "%15s,%10d", $1,$3}END{print "====================\n end"}' /etc/passwd
示例:
[root@node2 ~]# awk -F: 'BEGIN{print " Username Uid \n------------------------"}{printf "%15s,%10d\n",$1,$3}END{print "=======================\n end "}' /etc/passwd
Username Uid
------------------------
root, 0
bin, 1
daemon, 2
adm, 3
lp, 4
=========================
end
5.4.6 常用的action
(1)Expresstions
(2)Control statements:if,while等
(3)Compound statements:组合语句
(4)input statements
(5)output statements
5.4.7 控制语句
if(condition) {statements}
if(condition) {statements} else {statements}
while(condition) {statements}
do{statements} while(condition)
for(expr1;expr2;expr3) {statements}
break
continue
delete aray[index]
delete array
exit
{ statements }
7.1 if-else
语法:if(condition) statement [else statement]
使用场景: 对awk取得的整行或某个字段做条件判断;
示例:
- id号大于500为普通用户,其他为系统用户
[root@node2 ~]# awk -F: -v OFS=':' '{if($3>500){usertype="common user"} else {usertype="Sysadm"} print usertype,$1,$3}' /etc/passwd
Sysadm:root:0
Sysadm:ntp:38
common user:chrony:997
common user:hadoop:1001
common user:centos:1002
- 以/bin/bash结尾的字段
[root@node2 ~]# awk -F: '{if($NF=="/bin/bash"){print}}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
chegnkaihua:x:1000:1000:chegnkaihua:/home/chegnkaihua:/bin/bash
hadoop:x:1001:1001::/home/hadoop:/bin/bash
- 每行片段大于5个,则显示整行
[root@node2 ~]# awk -F: '{if(NF>5){print}}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
- df命令中use大于百分之20的设备
[root@node2 ~]# df -h | awk -F% '/^\/dev/{print $1}' | awk '{if($NF>20){print $0}}'
/dev/mapper/centos-root 4.8G 3.5G 1.1G 77
/dev/sda1 190M 99M 77M 57
/dev/mapper/centos-var 2.9G 2.3G 524M 82
7.2 while循环
语法:while(condition)statement
条件为"真",进入循环,条件为"假",退出循环
使用场景: 对一行内的多个字段逐一类似处理时使用;对数组中的各元素逐一处理时使用
示例:
- 对空白字符开头的行,每个片段的字符个数统计
[root@node2 ~]# awk '/^[[:space:]]*/{i=1;while(i<=NF){print $i,length($i);i++}}' /etc/grub2.cfg
# 1
the 3
'exec 5
tail' 5
line 4
above. 6
### 3
END 3
[root@node2 ~]# awk '/^[[:space:]]*linux16/{i=1;while(i<=NF) {if(length($i)>=7){print $i,length($i)}; i++}}' /etc/grub2.cfg
7.3 do-while循环
语法:do statement while(condition)
意义:至少执行一次循环体
7.4 for循环
语法:for(expr1;expr2;epr3) statement
示例:
[root@node2 ~]# awk '/^[[:space:]]*linux16/{for(i=1;i<=NF;i++){print $i,length($i)}}' /etc/grub2.cfg
linux16 7
/vmlinuz-5.12.0-1.el7.elrepo.x86_64 35
root=/dev/mapper/centos-root 28
ro 2
crashkernel=auto 16
console=ttyS0 13
console=tty0 12
panic=5 7
linux16 7
/vmlinuz-0-rescue-41c2d068d302c7418c1eea55178030b5 50
root=/dev/mapper/centos-root 28
ro 2
crashkernel=auto 16
console=ttyS0 13
console=tty0 12
panic=5 7
特殊用法:能够遍历数组中的元素
语法:for(var in array) {for-body}
7.5 switch语句
语法: switch(expression) {case VALUE1 or /REGEXP1/:statement;case VALUE2 or /REGEXP2/;statement;...;default:statement}
7.6 break 和 continue
break [n]
continue
7.7 next
提前结束对本行的处理而直接进入下一行
示例:显示偶数行
[root@localhost scripts]# awk -F: '{if($3%2!=0) next;print $1,$3}' /etc/passwd
root 0
daemon 2
lp 4
5.4.8 array
支持关联数组:array[index-expression]
index-expression:
(1)可使用任意字符串;字符串要使用双引号;
(2)如果某数组元素事先不存在,在引用时,awk会自动创建此元素,并将其值初始化为"空串"
若要判断数组中是否存在某元素,要使用"index in array"格式进行
示例:
- 给数组赋值并打印第一个值
[root@localhost scripts]# awk 'BEGIN{weekdays["mon"]="Monday";weekdays["tue"]="Tuesday";print weekdays["mon"]}'
Monday
- 若要遍历数组中的每个元素,要使用for循环
[root@localhost scripts]# awk 'BEGIN{weekdays["mon"]="Monday";weekdays["tue"]="Tuesday";for(i in weekdays){print weekdays[i]}}'
Monday
Tuesday
注意:var 会遍历array的每个索引
- 统计 netstat -atn 命令结果中各状态结果的出现次数
[root@node2 ~]# netstat -atn | awk '/^tcp\>/{state[$NF]++}END{for(i in state){print i,state[i]}}'
LISTEN 6
ESTABLISHED 2
SYN_SENT 11
- 统计每个 ip 访问了多少次
[root@node2 ~]# awk '{ip[$1]++}END{for(i in ip){print i,ip[i]}}' /var/log/httpd/access_log
192.168.2.11 2
192.168.2.12 2
192.168.2.122 1
192.168.2.13 4
192.168.2.1 8
192.168.2.133 1
- 统计/etc/fstab文件中各文件系统类型出现的次数
[root@node2 ~]# awk '/^[^#]/{fstype[$3]++}END{for(i in fstype){print i,fstype[i]}}' /etc/fstab
swap 1
ext4 4
- 统计 /etc/fstab 文件中每个单词出现的次数
[root@node2 ~]# awk '{for(i=1;i<=NF;i++){words[$i]++}}END{for(i in words){print i,words[i]}}' /etc/fstabman 12021 1and/or 1maintained 1/dev/mapper/centos-root 1UUID=f1a9b50d-7606-449c-90ae-a39f421cc685 1/var 1Accessible 1# 7/dev/mapper/centos-home 1Apr 1
5.4.9 函数
9.1 内置函数
-
数值处理
- rand():返回0和1之间一个随机数
-
字符串处理
- length([s]):返回指定字符串的长度
- sub(r,s,[t]):以 r 表示的模式来查找 t 所表示的字符中的匹配的内容,并将其第一次出现替换为 s 所表示的内容.也就是将t中的内容 r替换为 s
- gsub(r,s,[t]):以 r 表示的模式来查找 t 所表示的字符中的匹配的内容,并将其所有出现替换为 s 所表示的内容.也就是将t中的内容 r替换为 s
- split(s,a[],r):以 r 为分隔符切割字符串 s,并将切割后的结果保存至 a 所表示的数组中
注意:awk中的数组从1开始编号
示例:返回 0 和 1 之间的一个随机数:
[root@localhost ~]# awk 'BEGIN{print rand()}'
0.237788
示例:/etc/passwd 中第一个片段中的 o 替换为 O:
[root@node2 ~]# awk -F: 'BEGIN{print sub(o,O,$1)}' /etc/passwd
1
示例:统计 netstat -atn 命令中客户端连接的 ip出现次数,采用 split 分隔符
[root@node2 ~]# netstat -atn | awk '/^tcp\>/{split($4,ip,":");count[ip[1]]++}END{for(i in count){print i,count[i]}}'
127.0.0.1 5
0.0.0.0 1
192.168.2.12 14
9.2 自定义函数
参考书籍:<<sed和awk>>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号