Java集合 Collection、Set、Map、泛型 、迭代器
1.集合
1.1什么是集合?
概念
对象的容器,实现了对对象常用的操作
集合和数组的区别
1.数组长度固定,集合长度不固定
2.数组可以存储基本类型和引用类型,集合只能存储引用类型
1.2collection体系
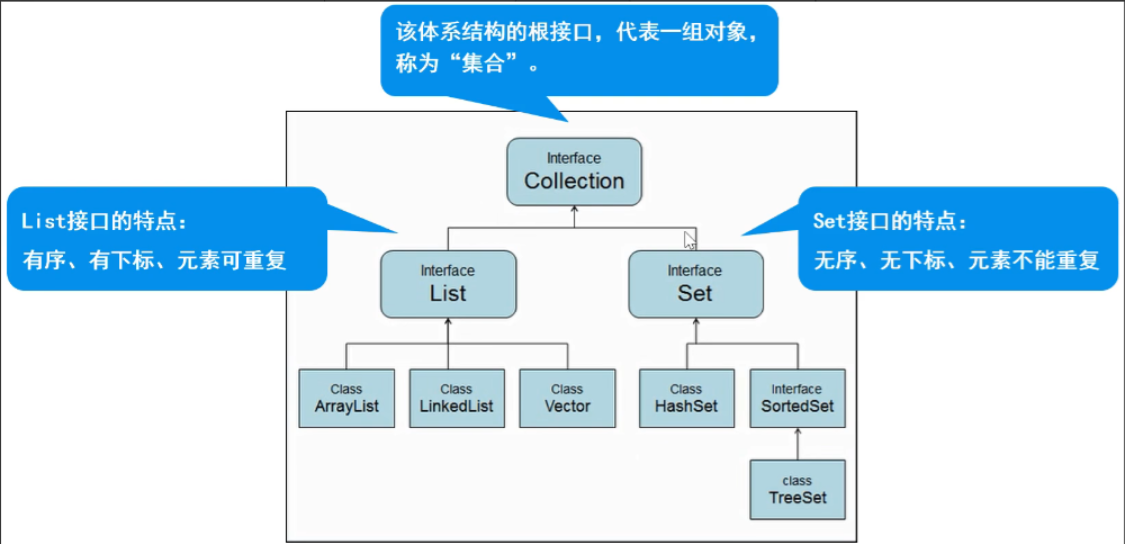
特点:代表一组任意类型的对象,无序、无下标、不能重复。
常用方法:
-
添加元素
collection.add(); -
删除元素
collection.remove();collection.clear(); -
遍历元素(重点)
-
使用增强for(因为无下标)
for(Object object : collection){ } -
使用迭代器
//haNext(); 有没有下一个元素 //next(); 获取下一个元素 //remove(); 删除当前元素 Iterator it = collection.iterator(); while(it.hasNext()){ String object = (String)it.next(); //强转 // 可以使用it.remove(); 进行移除元素 // collection.remove(); 不能用collection其他方法 会报并发修改异常 }
-
-
判断
collection.contains();collection.isEmpty();
list集合
常用方法
-
添加元素
list.add( );会对基本类型进行自动装箱 -
删除元素 可以用索引
list.remove(0)当删除数字与索引矛盾时 对数字强转
list.remove((Object) 10) 或 list.remove(new Integer(10)) -
遍历
-
使用for遍历
for(int i = 0; i < lise.size(); i++){ sout(list.get(i)); }
-
使用增强for
for(Object list: collection){ } -
使用迭代器
Iterator it = collection.iterator(); while(it.hasNext()){ String object = (String)it.next(); //强转 // 可以使用it.remove(); 进行移除元素 // collection.remove(); 不能用collection其他方法 会报并发修改异常 }
-
-
-
获取
list.indexOf( ); -
返回子集合
sublist(x, y);左闭右开List subList = list.subList(1, 3);返回索引 1、2
list实现类
- ArrayList 【重点】 数组结构实现,必须要连续空间,查询快、增删慢
- jdk1.2版本,运行效率块、线程不安全
- Vector
- 数组结构实现,查询快、增删慢
- jdk1.0版本,运行
- LinkedList
- 双向链表结构实现,无需连续空间,增删快,查询慢
ArrayList
创建集合 ArrayList arrayList = new ArrayList<>();
-
添加元素
arrayList.add(); -
删除元素
arrayList.remove(new Student("name", 10));这里重写了 equals(this == obj) 方法
-
遍历元素【重点】
-
使用迭代器
Iterator it = arrayList.iterator(); while(it.hasNext()){ Student s = (Student)it.next(); //强转 }
-
列表迭代器
ListIterator li = arrayList.listIterator(); while(li.hasNext()){ Student s = (Student)li.next(); //从前往后遍历 } while(li.hasPrevious()){ Student s = (Student)li.previous();//从后往前遍历 }
-
-
判断
arrayList.contains();和arrayList.isEmpty(); -
查找
arrayList.indexof();
原码分析
Vector
创建集合 Vector vector = new Vector<>();
增加、删除、判断同上
遍历中枚举器遍历
LinkedList
创建链表集合LinkedList li = new LinkedList<>();
常用方法与List一致
1.3泛型
- 本质是参数化类型,把类型作为参数传递
- 常见形式有泛型类、泛型接口、泛型方法
- 语法 T成为类型占位符,表示一种引用类型,可以写多个逗号隔开
- 好处 1. 提高代码重用性 2. 防止类型转换异常,提高代码安全性
泛型类
// 写一个泛型类
public class MyGeneric<T>{
//使用泛型T
//1 创建变量
T t;
//2 泛型作为方法的参数
public void show(T t){
sout(t);
}
//3 泛型作为方法的返回值
public T getT(){
return t;
}
}
public static void main(String[] args) {
Integer[] intArray = { 1, 2, 3, 4, 5 };
Double[] doubleArray = { 1.1, 2.2, 3.3, 4.4 };
String[] stringArray = { "apple", "banana", "orange" };
printArray(intArray);
printArray(doubleArray);
printArray(stringArray);
}
public static <T> void printArray(T[] array) {
for (T element : array) {
System.out.println(element);
}
}
// 使用泛型类
public class TestGeneric{
public static void main(String[] args){
//使用泛型类创建对象
// 注意: 1. 泛型只能使用引用类型
// 2. 不用泛型类型对象之间不能相互赋值
MyGeneric<String> myGeneric = new MyGeneric<String>();
myGeneric.t = "hello";
myGeneric.show("hello world!");
String string = myGeneric.getT();
MyGeneric<Integer> myGeneric2 = new MyGeneric<Integer>();
myGeneric2.t = 100;
myGeneric2.show(200);
Integer integer = myGeneric2.getT();
}
}
泛型接口
语法:接口名
注意:不能泛型静态常量
语法: 返回值类型
public class MyGenericMethod{
//泛型方法
public <T> T show(T t){
sout("泛型方法" + t);
return t;
}
}
//调用
MyGenericMethod myGenericMethod = new MyGenericMethod();
myGenericMethod.show("字符串");// 自动类型为字符串
myGenericMethod.show(200);// integer类型
myGenericMethod.show(3.14);// double类型
泛型集合
概念:参数化类型、类型安全的集合,强制集合元素的类型必须一致
特点:编译时即可检查,而非运行时抛出异常
访问时,不必类型转换(拆箱)
不同泛型之间应用不能相互赋值,泛型不存在多态
1.4set集合
特点:无序、无下标、元素不可重复
方法:全部继承自Collection中的方法
增、删、遍历、判断与collection一致
1.4.1HashSet(重点)
存储结构:哈希表(数组+链表+红黑树)
存储过程(重复依据)
- 根据hashCode计算保存的位置,如果位置为空,直接保存,若不为空,进行第二步
- 再执行equals方法,如果equals为true,则认为是重复,否则形成链表
特点
- 基于HashCode计算元素存放位置
- 利用31这个质数,减少散列冲突
- 31提高执行效率
31 * i = (i << 5) - i转为移位操作 - 当存入元素的哈希码相同时,会调用equals进行确认,如果结果为true,则拒绝后者存入
新建集合 HashSet<String> hashSet = new HashSet<String>();
添加元素 hashSet.add( );
删除元素 hashSet.remove( );
遍历操作
1. 增强for for( type type : hashSet)
2. 迭代器 Iterator<String> it = hashSet.iterator( );
判断 hashSet.contains( ); hashSet.isEmpty();
1.4.2TreeSet
特点
- 基于排列顺序实现元素不重复
- 实现SortedSet接口,对集合元素自动排序
- 元素对象的类型必须实现Comparable接口,指定排序规则
- 通过CompareTo方法确定是否为重复元素
存储结构:红黑树
创建集合 TreeSet<String> treeSet = new TreeSet<>()
添加元素 treeSet.add();
删除元素 treeSet.remove();
遍历 1. 增强for 2. 迭代器
判断 treeSet.contains();
补充:TreeSet集合的使用
Comparator 实现定制比较(比较器)
Comparable 可比较的
// 重写compare
@override
public int compare(Person o1, Person o2){
int n1 = o1.getAge()-o2.getAge();
int n2 = o1.getName().comareTo(o2.getName());
return n1 == 0 ? n2 : n1;
}
1.5Map
Map接口的特点
方法:
1.5.1Map接口的使用
//创建Map集合 Map<String, String> map = new HashMap<>(); // 1. 添加元素 map.put("cn", "中国"); map.put("uk", "英国"); map.put("cn", "zhongguo"); // 会替换第一个 // 2. 删除 map.remove("uk"); // 3. 遍历 // 3.1 使用KeySet() //Set<String> keyset = map.keySet(); // 所有Key的set集合 for(String key : map.keyset){ sout(key + "---" + map.get(key)); } // 3.2 使用entrySet() //Set<Map.Entry<String, String>> entries = map.entrySet(); for(Map.Entry<String, String> entry : map.entries){ sout(entry.getKey() + "---" + entry.getValue(); }
1.5.2HashMap 【重点】
存储结构:哈希表(数组+链表+红黑树)
使用key可使hashcode和equals作为重复
增、删、遍历、判断与上述一致
原码分析总结:
- HashMap刚创建时,table是null,节省空间,当添加第一个元素时,table容量调整为16
- 当元素个数大于阈值(16*0.75 = 12)时,会进行扩容,扩容后的大小为原来的两倍,目的是减少调整元素的个数
- jdk1.8 当每个链表长度 >8 ,并且数组元素个数 ≥64时,会调整成红黑树,目的是提高效率
- jdk1.8 当链表长度 <6 时 调整成链表
- jdk1.8 以前,链表时头插入,之后为尾插入
1.5.3Hashtable
线程安全,运行效率慢;不允许null作为key或是value
Properties
hashtable的子类,要求key和value都是string,通常用于配置文件的读取
1.5.4TreeMap
实现了SortedMap接口(是map的子接口),可以对key自动排序
1.7Collection工具类
概念:集合工具类,定义了除了存取以外的集合常用方法
直接二分查找int i = Collections.binarySearch(list, x); 成功返回索引
其他方法 : copy复制、reverse反转、shuffle打乱
补充:
// list转成数组
Integer[] arr = list.toArray(new Integer[10]);
sout(arr.length);
sout(Array.toString(arr));
// 数组转成集合
// 此时为受限集合,不能 添加和删除!
String[] name = {"张三","李四","王五"};
List<String> list2 = Arrays.asList(names);
// 把基本类型数组转为集合时,需要修改为包装类
Integer[] nums = {100, 200, 300, 400, 500};
List<Integer> list3 = Arrays.asList(nums);
2.Iterator
迭代器专门用来遍历集合的一种方式,虽然有些东西循环也可以实现,但是迭代器可以更方便、快捷的删除某一个元素。
迭代的意思就是循环或者遍历,他也是接口来实现的,这是我个人的理解哈。
迭代器有三个方法
hasNext(); 有没有下一个元素
next(); 获取下一个元素
remove(); 删除集合里上一次next返回的元素
实现代码如下:
Iterator it = collection.iterator(); while (it.hasNext()) {
String nowData = (String)it.next();
//删除当前元素,也就是说遍历查询后的数据为空时就会删除上一次next返回的元素;遍历后查询的集合size()为0是就会删除这个集合上一级的key
it.remove();
}
逻辑层实现如下:
Iterator<Attention> it = list.iterator(); while (it.hasNext()) { Attention nowData = it.next(); //表一数据
Users u=service.list(nowData.getId());
nowData.setUsers(u);
//表二数据 Member m=service2.list(nowData.getMemberId());
nowData.setMember(m); }
最后直接返回list就好了,因为迭代器都把下面的数据迭代添加了哈。
有错误的地方请指出哈!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号