
Linux内核中namespace之PID namespace
前面看了LInux PCI设备初始化,看得有点晕,就转手整理下之前写的笔记,同时休息一下!!~(@^_^@)~
这片文章是之前写的,其中参考了某些大牛们的博客!!
PID框架的设计
一个框架的设计会考虑很多因素,相信分析过Linux内核的读者来说会发现,内核的大量数据结构被哈希表和链表链接起来,最最主要的目的就是在于查找。可想而知一个好的框架,应该要考虑到检索速度,还有考虑功能的划分。那么在PID框架中,需要考虑以下几个因素.
-
如何通过task_struct快速找到对应的pid
-
如何通过pid快速找到对应的task_struct
-
如何快速的分配一个唯一的pid
这些都是PID框架设计的时候需要考虑的一些基本的因素。也正是这些因素将PID框架设计的愈加复杂。
原始的PID框架
先考虑的简单一点,一个进程对应一个pid
struct task_struct {
.....
pid_t pid;
.....
}
引入hlist和pid位图
struct task_struct *pidhash[PIDHASH_SZ];
这样就很方便了,再看看PID框架设计的一些因素是否都满足了,如何分配一个唯一的pid呢,连续递增?,那么前面分配的进程如果结束了,那么分配的pid就需要回收掉,直到分配到PID的最大值,然后从头再继续。好吧,这或许是个办法,但是是不是需要标记一下那些pid可用呢?到此为此这看起来似乎是个解决方案,但是考虑到这个方案是要放进内核,开发linux的那帮家伙肯定会想近一切办法进行优化的,的确如此,他们使用了pid位图,但是基本思想没有变,同样需要标记pid是否可用,只不过使用pid位图的方式更加节约内存.想象一下,通过将每一位设置为0或者是1,可以用来表示是否可用,第1位的0和1用来表示pid为1是否可用,以此类推.到此为此一个看似还不错的pid框架设计完成了,下图是目前整个框架的整体效果.

用上面大牛的引言来引入今天的主题:
其实PID namespace带来的好处远不止于此,其中最重要的就是对轻量级虚拟化的支持。当前炙手可热的docker就是基于Linux 内核中命名空间的原理。有了PID命名空间,我们就可以保证进程的隔离性,至少在进程的角度,可以按照namespace的方式去组织,不同namespace的进程互不干扰。这也是笔者要分析下底层虚拟化支持的初衷之一!
言归正传:
引入进程PID命名空间后的PID框架
随着内核不断的添加新的内核特性,尤其是PID Namespace机制的引入,这导致PID存在命名空间的概念,并且命名空间还有层级的概念存在,高级别的可以被低级别的看到,这就导致高级别的进程有多个PID,比如说在默认命名空间下,创建了一个新的命名空间,占且叫做level1,默认命名空间这里称之为level0,在level1中运行了一个进程在level1中这个进程的pid为1,因为高级别的pid namespace需要被低级别的pid namespace所看见,所以这个进程在level0中会有另外一个pid,为xxx.套用上面说到的pid位图的概念,可想而知,对于每一个pid namespace来说都应该有一个pidmap,上文中提到的level1进程有两个pid一个是1,另一个是xxx,其中pid为1是在level1中的pidmap进行分配的,pid为xxx则是在level0的pidmap中分配的. 下面这幅图是整个pidnamespace的一个框架
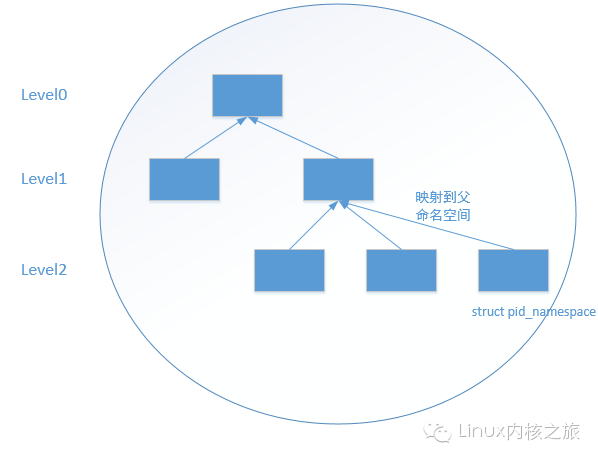
可以看到这里出现了一个层次结构,即一个命名空间可以有其子命名空间,子命名空间中的进程同样会出现在父命名空间中,只是进程ID是不同的。看PID的结构:
1 struct pid 2 { 3 atomic_t count; 4 unsigned int level; 5 /* lists of tasks that use this pid */ 6 struct hlist_head tasks[PIDTYPE_MAX]; 7 struct rcu_head rcu; 8 struct upid numbers[1]; 9 };
count表示这个PID的引用计数,同一个PID结构可以为多个进程所共享;
level表示该PID所在的层级;
tasks是一个HASH数组,每一项都是一个链表头。分别是PID链表头,进程组ID表头,会话ID表头;
rcu用于保护指针引用;
numbers是一个UPID数组,记录对应层级的命名空间中的UPID,所以可以想到,该PID处于第几层,那么这个数组应该有几项(当然都是从0开始)。
看下UPID结构:
1 struct upid { 2 /* Try to keep pid_chain in the same cacheline as nr for find_vpid */ 3 int nr; 4 struct pid_namespace *ns; 5 struct hlist_node pid_chain; 6 };
UPID相比之下就简单的多,或者说这才是真正的PID。
nr表示ID号;
namespace指向该UPID所在命名空间的namespace结构;
pid_chain是一个链表,系统会把UPID 的nr和namespace的ns经过某种hash,得到在一个全局的Hash数组中的下标,此UPID便会加入到对应下标的链表中。
看下进程中对于PID是如何应用的:
1 struct task_struct{ 2 ... 3 struct pid_link pids[PIDTYPE_MAX]; 4 ... 5 }
进程中包含一个pid_link结构的数组,我们还是先看一个pid_link结构:
1 struct pid_link 2 { 3 struct hlist_node node; 4 struct pid *pid; 5 };
node作为一个节点加入到所有引用同一PID结构的进程链表中;
pid指向该进程引用的PID结构。
也许到这里还是显得关系有点紊乱,那么看一下下面的图:
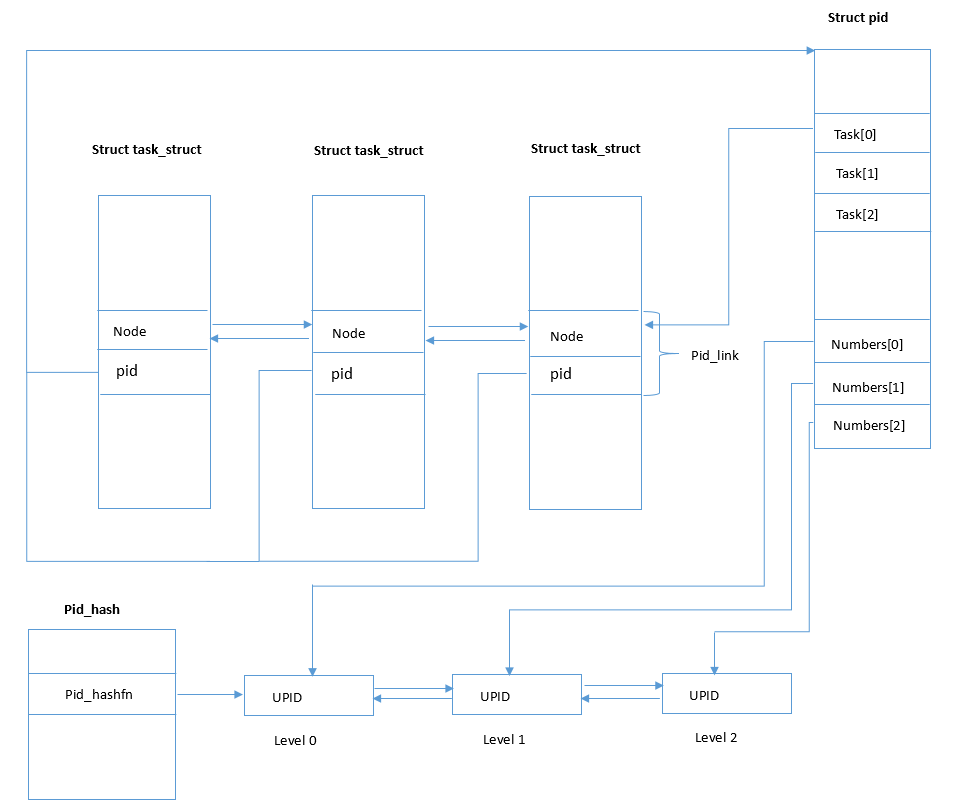
没错,这个图是我画的!!哈哈,可花了我不少时间了,希望对大家理解进程结构和PID以及UPID之间的关系有所帮助。贴出这个图突然发现没有什么好解释的了,各种关系图中已经表明。不过需要注意的是最下面的UPID我仅仅用一个框框代表了,其实是Numbers指向UPID结构,而让UPID加入到链表中的是结构中的pid_chain;还有一个问题就是UPID那一组链表并不是表示同一PID下的所有UPID,根据内核源代码,这里只是处理冲突的一种方式,而这里画成链表仅仅是为了表示这里是以链表存在的。
下面说下PID位图:
每一个namespace都对应一个map,用于分配pid号。这里包含两个成员,nr_free表示可用的ID号数量,第二个是一个指向一个页面的指针。这么设计有其自身的合理性。默认情况下page指向一个页面,而一个页面是4kb的大小,即4096个字节,也就是4096*8bit,每一位表示一个pid号,一个页面就可以表示32768个进程ID,普通情况下绝对是够了,即使特殊情况不够,那么还可以动态扩展,这就是其合理性所在。
1 struct pidmap { 2 atomic_t nr_free; 3 void *page; 4 };
这里是pid_namespace结构:
1 struct pid_namespace { 2 struct kref kref; 3 struct pidmap pidmap[PIDMAP_ENTRIES];//命名空间对应的PID位图 4 int last_pid;//上次分配的PID,便于下次分配 5 unsigned int nr_hashed; 6 struct task_struct *child_reaper; 7 struct kmem_cache *pid_cachep; 8 unsigned int level;//命名空间所在层级 9 struct pid_namespace *parent;//指向父命名空间的指针 10 #ifdef CONFIG_PROC_FS 11 struct vfsmount *proc_mnt; 12 struct dentry *proc_self; 13 #endif 14 #ifdef CONFIG_BSD_PROCESS_ACCT 15 struct bsd_acct_struct *bacct; 16 #endif 17 struct user_namespace *user_ns; 18 struct work_struct proc_work; 19 kgid_t pid_gid; 20 int hide_pid; 21 int reboot; /* group exit code if this pidns was rebooted */ 22 unsigned int proc_inum; 23 };
下一节会结合LInux内核源代码分析下PID的具体分配情况

 浙公网安备 33010602011771号
浙公网安备 33010602011771号