
Hadoop完全分布式部署
Hadoop下载地址:https://archive.apache.org/dist/hadoop/common/
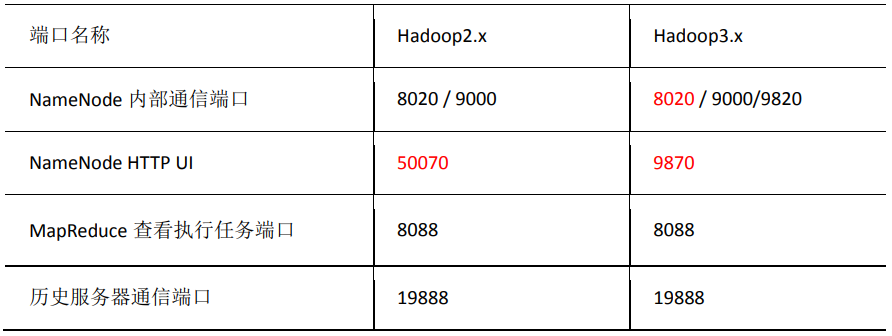
Hadoop各组件常用端口说明
服务规划
注:NameNode和SecondaryNameNode和ResourceManager尽量不要安装在同一台服务器,很耗内存

该部署以Red Hat 7为例
安装前提
需先配置好1.8的JAVA环境,可参考JDK的安装配置(Windows、Linux),Hadoop和Java版本对应关系可参考https://blog.csdn.net/m0_67393619/article/details/123933614
关闭防火墙和SELinux(所有设备)
systemctl stop firewalld.service
systemctl disable firewalld.service
setenforce 0
vi /etc/selinux/config
1 | SELINUX=enforcing改为SELINUX=disabled |
配置IP地址和主机名之间的映射(所有设备)
vi /etc/hosts
1 2 3 | 192.168.111.129 node1192.168.111.130 node2192.168.111.131 node3 |
需重启设备生效
创建用户(所有设备)
useradd hadoop
passwd hadoop
SSH免密登录配置(所有设备互相进行配置)
su - hadoop
ssh-keygen -t rsa
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
Hadoop完全分布式部署
Hadoop完全分布式的数据是存储在hadoop上的,并且是多台服务器进行的工作
先在192.168.111.129上的操作
1.解压安装包
tar -zxvf hadoop-3.0.3.tar.gz -C /usr/local/
2.修改环境变量
vim /etc/profile
1 2 | export HADOOP_HOME=/usr/local/hadoop-3.0.3export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin |
source /etc/profile
3.修改hadoop配置文件
cd /usr/local/hadoop-3.0.3/etc/hadoop
vim hadoop-env.sh
1 | export JAVA_HOME=/usr/local/java/jdk1.8.0_60 |
核心配置文件
vim core-site.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | <configuration> <!-- 指定 NameNode 的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://node1:8020</value> </property> <!-- 指定 hadoop 数据的存储目录,凡是上传到Hadoop上的文件都会存储至该路径 --> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop-3.0.3/data</value> </property> <!-- 配置 HDFS 网页登录使用的静态用户为 hadoop --> <property> <name>hadoop.http.staticuser.user</name> <value>hadoop</value> </property> </configuration> |
HDFS配置文件
vim hdfs-site.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | <configuration> <!-- NameNode web 端访问地址--> <property> <name>dfs.namenode.http-address</name> <value>node1:9870</value> </property> <!-- SecondaryNameNode web 端访问地址--> <property> <name>dfs.namenode.secondary.http-address</name> <value>node3:9868</value> </property> <!-- 数据文件的副本数量, 默认就是3--> <property> <name>dfs.replication</name> <value>3</value> </property></configuration> |
YARN配置文件
vim yarn-site.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | <configuration> <!-- 指定 MapReduce 走 shuffle --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定 ResourceManager 的地址--> <property> <name>yarn.resourcemanager.hostname</name> <value>node2</value> </property> <!-- 环境变量的继承,好像是个BUG,不配置会报错 --> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property></configuration> |
MapReduce配置文件
vim mapred-site.xml
1 2 3 4 5 6 7 | <configuration> <!-- 指定 MapReduce 程序运行在 Yarn 上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> |
workers节点文件(hadoop3.0以下版本为slave文件)
vim workers
1 2 3 | node1node2node3 |
4.创建相关目录
mkdir -p /usr/local/hadoop-3.0.3/data
5.给Hadoop目录授权
chown -R hadoop:hadoop /usr/local/hadoop-3.0.3
6.复制Hadoop目录至其他节点
scp -r /usr/local/hadoop-3.0.3 node2:/usr/local
scp -r /usr/local/hadoop-3.0.3 node3:/usr/local
复制完成后记得去其他设备上给hadoop目录授权(chown -R hadoop:hadoop /usr/local/hadoop-3.0.3)
7.初始化HDFS
#第一次启动HDFS需要先进行格式化,需要在NameNode节点上执行
su - hadoop
cd /usr/local/hadoop-3.0.3/bin
./hdfs namenode -format
8.启动HDFS
#hadoop用户启动
cd /usr/local/hadoop-3.0.3/sbin
./start-dfs.sh
9.启动YARN
#来到配置了 ResourceManager 的节点启动,这里我的是node2
#hadoop用户启动
cd /usr/local/hadoop-3.0.3/sbin
./start-yarn.sh
10.查看启动情况
分别登陆三个节点使用jps命令查看
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | ####192.168.111.129(node1)jps39264 NodeManager38836 NameNode39367 Jps38954 DataNode####192.168.111.130(node2)jps3937 NodeManager4296 Jps3417 DataNode3820 ResourceManager####192.168.111.131(node3)jps5412 Jps5206 SecondaryNameNode5096 DataNode5309 NodeManager |
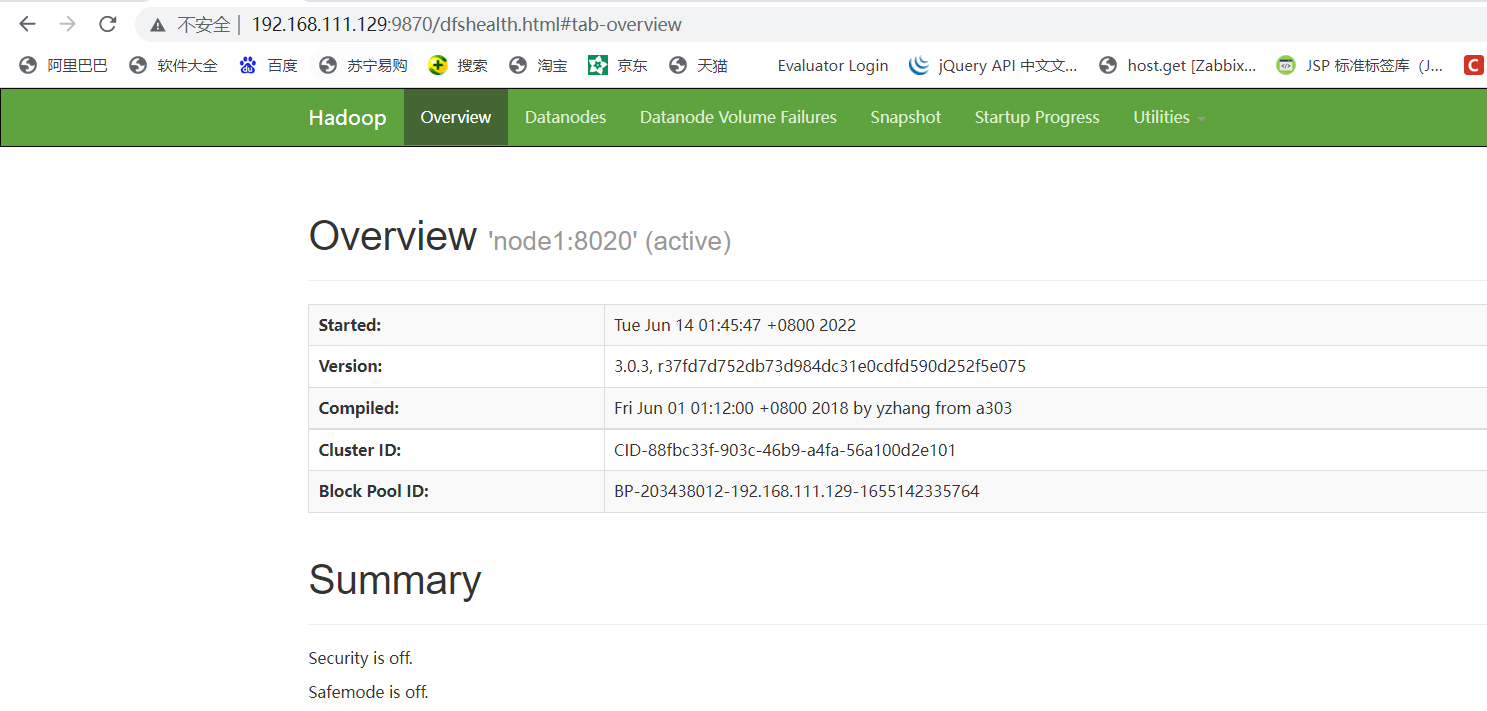
11.访问页面是否正常
访问HDFS的NameNode WEB:http://192.168.111.129:9870/
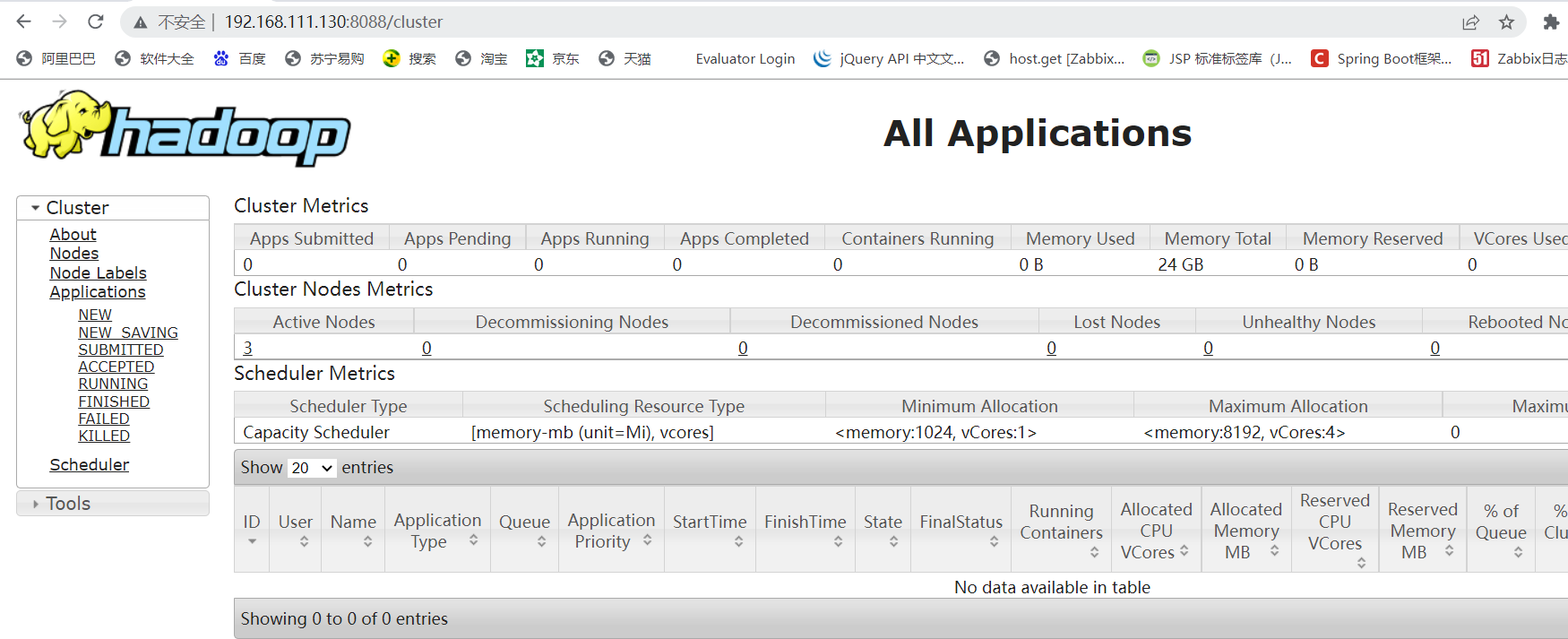
访问YARN的ResourceManager WEB:http://192.168.111.130:8088/
#当我们有MapReduce任务执行时,在该页面上即可查看到
12.Hadoop集群奔溃处理方式
#若练习的时候出现奔溃,可以使用以下方式,生产环境的话就算了
删除每个hadoop下的data和logs文件,然后重新格式化HDFS并启动即可
13.配置历史服务器(在此我们配置在node1上)
作用:可以查看到程序的历史运行情况
cd /usr/local/hadoop-3.0.3/etc/hadoop
MapReduce配置文件
vim mapred-site.xml
1 2 3 4 5 6 7 8 9 10 11 | <!-- 历史服务器端地址 --> <property> <name>mapreduce.jobhistory.address</name> <value>node1:10020</value> </property> <!-- 历史服务器 web 端地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>node1:19888</value> </property> |
启动历史服务器
cd /usr/local/hadoop-3.0.3/bin
./mapred --daemon start historyserver
1 2 3 4 5 6 | jps39264 NodeManager38836 NameNode40501 Jps38954 DataNode40444 JobHistoryServer |
访问JobHistoryServer WEB: http://192.168.111.129:19888/
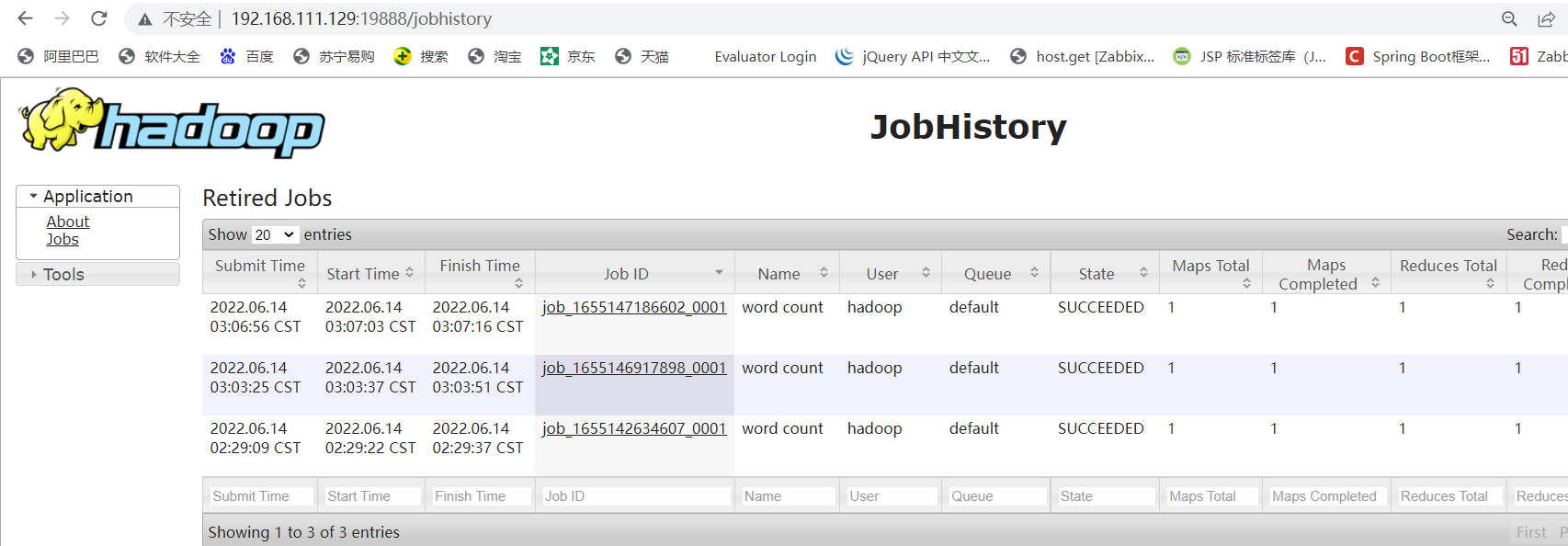
配置了历史服务器后,我们YARN的ResourceManager WEB页面里的历史任务才可以进行查看
#需重启YARN(在此我们是在node2上操作)
cd /usr/local/hadoop-3.0.3/sbin
./stop-yarn.sh
./start-yarn.sh
#不过对于我目前的这个环节单单重启YARN还不够,因为我hadoop配置的都是域名,所以需要在本机进行域名配置,修改C:\Windows\System32\drivers\etc下的hosts文件

然后通过ResourceManager WEB中的任务history选项即可进行跳转
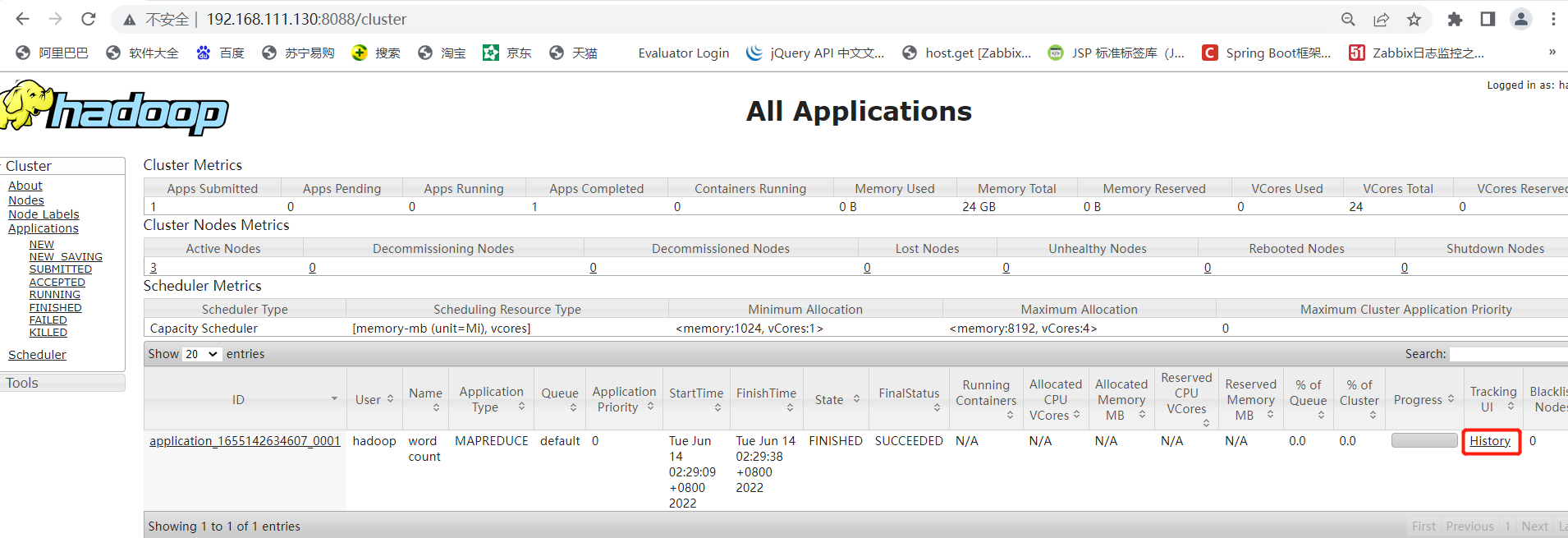
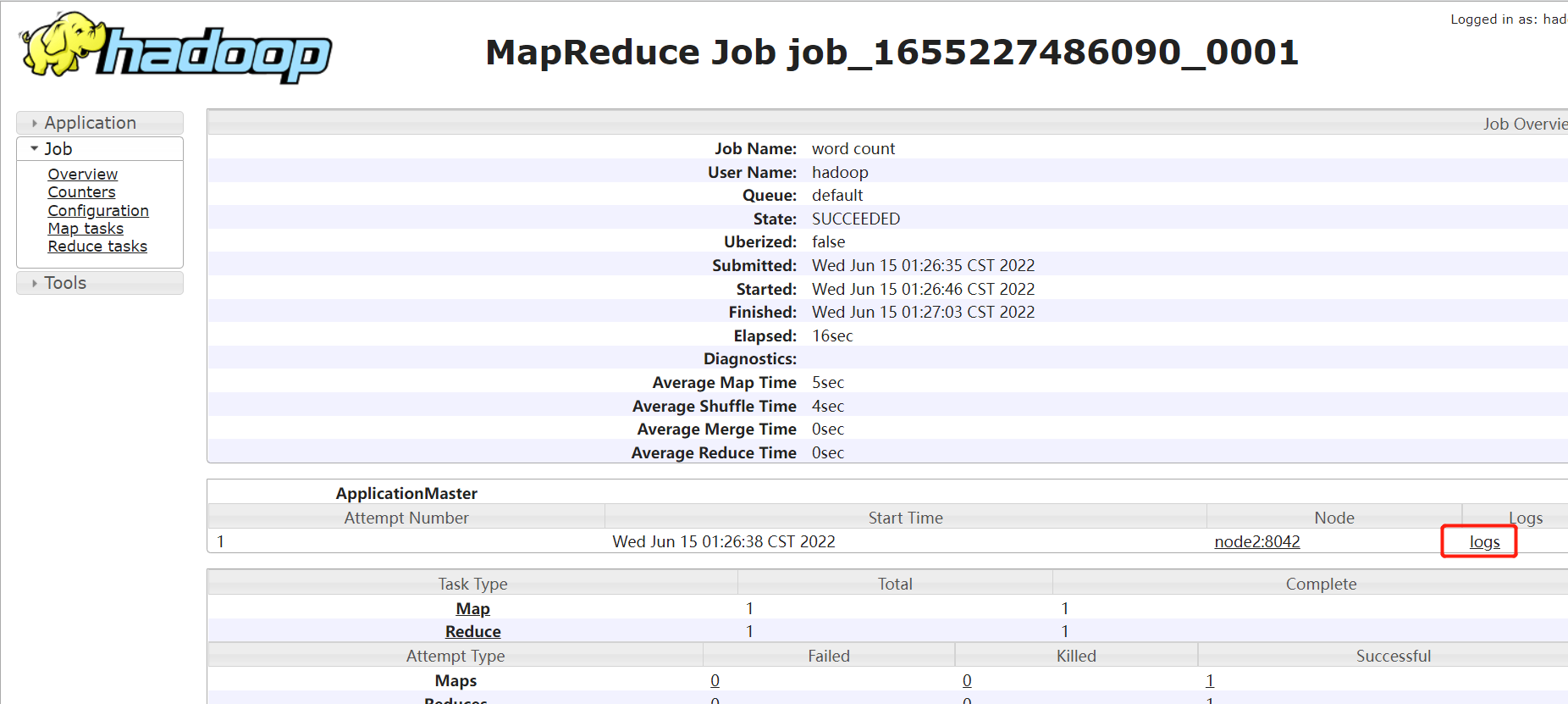
14.配置日志聚集功能(所有节点)
可以看到上方jobhistory有个logs选项,该选项是记录我们程序的运行日志,不过只有配置了日志聚集功能才可以查看,日志聚集功能会将所有服务器日志聚集到HDFS上
cd /usr/local/hadoop-3.0.3/etc/hadoop
vim yarn-site.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | <!-- 开启日志聚集功能 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 设置日志聚集服务器地址 --> <property> <name>yarn.log.server.url</name> <value>http://node1:19888/jobhistory/logs</value> </property> <!-- 设置日志保留时间为 7 天 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> |
注:开启日志聚集功能,需重新启动Yarn、HistoryServer
#重启HistoryServer(在此我们是在node1上操作)
cd /usr/local/hadoop-3.0.3/bin
./mapred --daemon stop historyserver
./mapred --daemon start historyserver
#重启YARN(在此我们是在node2上操作)
cd /usr/local/hadoop-3.0.3/sbin
./stop-yarn.sh
./start-yarn.sh
#然后新增的任务就可以通过ResourceManager WEB中的任务history选项进行跳转至History,再跳转至logs。不过这里必须是新增的,之前的任务还是不可以。logs跳转后的页面如下所示
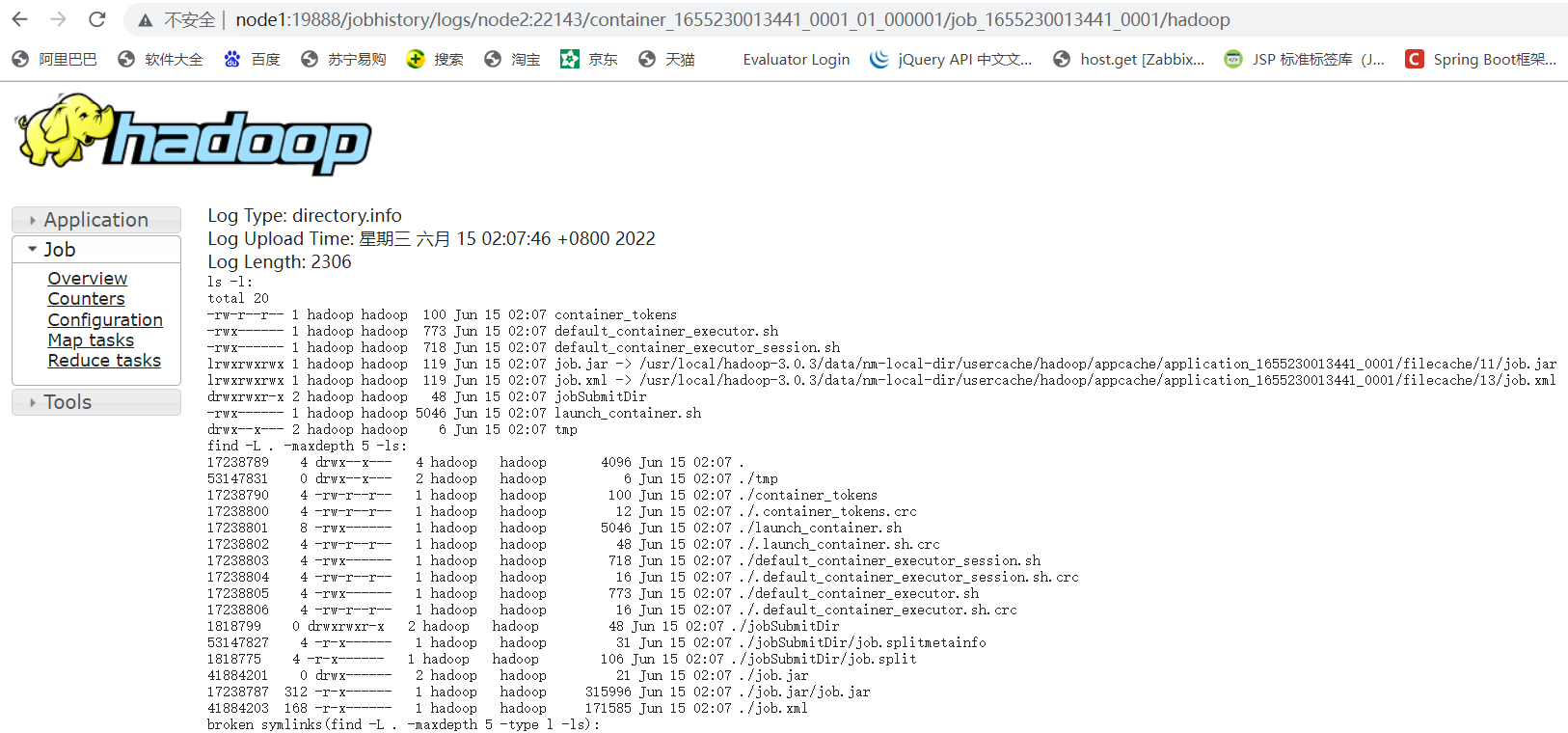
15.Hadoop集群启动/停止方式总结
整体启动/停止 HDFS
start-dfs.sh/stop-dfs.sh
整体启动/停止 YARN
start-yarn.sh/stop-yarn.sh
逐一启动/停止 HDFS 组件
hdfs --daemon start/stop namenode/datanode/secondarynamenode
逐一启动/停止 YARN 组件
yarn --daemon start/stop resourcemanager/nodemanager
逐一启动/停止 historyserver 组件
mapred --daemon stop historyserver


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律