

Kafka集群部署
Kafka介绍
Kafka是一个分布式、支持分区的(partition)、多副本的(replica),基于Zookeeper(Kafka2.8版本开始自带了Zookeeper)协调的分布式消息中间件系统,Kafka是由scala和java语言编写的,其中,Producer和Consumer是由Java编写,Broker是由Scala编写的。
最大的特性就是可以实时的处理大量数据以满足各种需求场景,比如基于 hadoop 的批处理系统、低延迟的实时系统、Spark/Flink 流式处理引擎,nginx 访问日志,消息服务等等,用 scala 语言编写
Kafka特性
- 高吞吐量、低延迟:Kafka 每秒可以处理几十万条消息,它的延迟最低只有几毫秒。每个 topic 可以分多个 Partition,Consumer Group 对 Partition 进行消费操作,提高负载均衡能力和消费能力
- 可扩展性:kafka 集群支持热扩展
- 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
- 容错性:允许集群中节点失败(多副本情况下,若副本数量为 n,则允许 n-1 个节点失败)
- 高并发:支持数千个客户端同时读写
Kafka使用场景
- ⽇志收集:⼀个公司可以⽤Kafka收集各种服务的log,通过kafka以统⼀接⼝服务的⽅式开放给各种consumer,例如hadoop、Hbase、Solr等。
- 消息系统:解耦和⽣产者和消费者、缓存消息等。
- ⽤户活动跟踪:Kafka经常被⽤来记录web⽤户或者app⽤户的各种活动,如浏览⽹⻚、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
- 运营指标:Kafka也经常⽤来记录运营监控数据。包括收集各种分布式应⽤的数据,⽣产各种操作的集中反馈,⽐如报警和报告。
kafka官网:http://kafka.apache.org/
kafka配置快速入门:http://kafka.apache.org/quickstart
kafka下载页面:http://kafka.apache.org/downloads
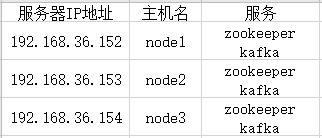
服务规划
Kafka集群部署
注意事项:
- 集群的数量不是越多越好,最好不要超过 7 个,因为节点越多,消息复制需要的时间就越长,整个群组的吞吐量就越低。
- 集群数量最好是单数,因为超过一半故障集群就不能用了,设置为单数容错率更高。
该部署以Red Hat 7为例
1.关闭防火墙和SELinux(所有设备)
systemctl stop firewalld.service
systemctl disable firewalld.service
setenforce 0
vi /etc/selinux/config
1 | SELINUX=enforcing改为SELINUX=disabled |
2.安装JDK(所有设备)
安装kafka前需要先安装jdk,可参考我之前编写的JDK的安装配置(Windows、Linux),不过kafka好像已经宣布了即将弃用对java8的支持,所以在未来版本,肯定也就不能安装java8版本了
3.配置IP地址和主机名之间的映射(所有设备)
vim /etc/hosts
1 2 3 | 192.168.36.152 node1192.168.36.153 node2192.168.36.154 node3 |
4.配置主机名(所有设备)
vim /etc/sysconfig/network
1 2 | NETWORKING=yeshostname=主机名 |
hostnamectl set-hostname 主机名
需重启设备使配置生效:init 6
5.安装Zookeeper(所有设备)
安装kafka前还需要依赖Zookeeper组件,这里可参考我之前编写的ZooKeeper部署
6.安装Kafka(192.168.36.152)
解压安装包
tar -zxvf kafka_2.13-3.1.1.tgz -C /usr/local/
配置Kafka配置文件
cd /usr/local/kafka_2.13-3.1.1/config/
vim server.properties
1 2 3 4 5 6 | #各节点不可重复,唯一标识broker.id=0#Kafka数据存储路径,会按照分区名进行存储log.dirs=/usr/local/kafka_2.13-3.1.1/data#Zookeeper节点zookeeper.connect=node1:2181,node2:2181,node3:2181/kafka-zk |
mkdir -p /usr/local/kafka_2.13-3.1.1/data
将Kafka文件进行分发给其他节点
scp -r /usr/local/kafka_2.13-3.1.1/ root@node2:/usr/local/
scp -r /usr/local/kafka_2.13-3.1.1/ root@node3:/usr/local/
7.配置环境变量(所有设备)
vim /etc/profile
1 2 3 | #KAFKA_HOMEexport KAFKA_HOME=/usr/local/kafka_2.13-3.1.1export PATH=$PATH:$KAFKA_HOME/bin |
source /etc/profile
8.启动Kafka(所有设备)
# 先启动Zookeeper
zkServer.sh start
# 然后启动Kafka
kafka-server-start.sh -daemon /usr/local/kafka_2.13-3.1.1/config/server.properties
# jps命令查看
11027 QuorumPeerMain
12263 Kafka
12347 Jps


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· AI 智能体引爆开源社区「GitHub 热点速览」
· 写一个简单的SQL生成工具