

1.1、Elasticsearch详解及部署
Elasticsearch介绍
Elasticsearch简称ES,是一个基于Lucene的搜索服务器。它提供了一个分布式、高扩展、高实时的搜索与数据分析引擎,基于RESTful web接口,它能很方便的使大量数据具有搜索、分析和探索的能力。
Elasticsearch的实现原理主要分为以下几个步骤,首先用户将数据提交到Elasticsearch 数据库中,再通过分词控制器去将对应的语句分词,将其权重和分词结果一并存入数据,当用户搜索数据时候,再根据权重将结果排名,打分,再将返回结果呈现给用户。
应用场景
- 全文搜索
Elasticsearch提供了全文搜索的功能,适用于电商商品搜索、App搜索、企业内部信息搜索、IT系统搜索等。
打个比方,在我们数据库做模糊查询时,如LIKE语句,它会遍历整张表,同时进行字符串匹配,这时候如果我们的表数据很多时,响应速度可想而知,所以这时候我们就可以引入ES。将数据库与我们ES数据同步,通过ES来完成我们的大数据检索,提高我们的查询效率。
- 日志分析
复杂的业务场景通常会产生繁杂多样的日志,如Apache Log、System Log、MySQL Log等,往往很难从繁杂的日志中获取价值,却要承担其存储的成本。Elasticsearch能够借助Beats、Logstash等快速对接各种常见的数据源,并通过集成的Kibana高效地完成日志的可视化分析,让日志产生价值。
接下来,我会对ES及ES的一些相关插件进行部署
ES与其他工具版本对应关系可参考https://www.elastic.co/cn/support/matrix#matrix_compatibility
Elasticsearch部署
该部署以Centos7为例
#这里我只使用了一台设备(192.168.111.129)来进行实验
安装前提:需先配置好1.8的JAVA环境,可参考JDK的安装配置(Windows、Linux)
ElasticSearch与JDK版本的版本对应关系可参考https://www.elastic.co/cn/support/matrix#matrix_jvm
ElasticSearch下载地址: https://mirrors.huaweicloud.com/elasticsearch/?C=N&O=D
1.关闭防火墙和SELinux
systemctl stop firewalld.service
systemctl disable firewalld.service
setenforce 0
vi /etc/selinux/config
1 | SELINUX=enforcing改为SELINUX=disabled |
2.解压安装包
tar -zxvf elasticsearch-7.6.1-linux-x86_64.tar.gz -C /usr/local/
3.配置ES配置文件
cd /usr/local/elasticsearch-7.6.1/config/
vi elasticsearch.yml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | #将以下注释去除并修改#配置es的集群名称cluster.name: my-es#节点名称node.name: node-1#设置索引数据的存储路径path.data: /usr/local/elasticsearch-7.6.1/data#设置日志的存储路径path.logs: /usr/local/elasticsearch-7.6.1/logs#设置当前的ip地址,通过指定相同网段的其他节点会加入该集群中network.host: 0.0.0.0#设置对外服务的端口http.port: 9200#首次启动全新的Elasticsearch集群时,会出现一个集群引导步骤,该步骤确定了在第一次选举中便对其票数进行计数的有资格成为集群中主节点的节点的集合(投票的目的是选出集群的主节点),单节点就配置一个即可cluster.initial_master_nodes: ["node-1"] |
4.创建ES相关配置文件
mkdir -p /usr/local/elasticsearch-7.6.1/data
mkdir -p /usr/local/elasticsearch-7.6.1/logs
5.创建ES用户并授权
因为安全问题elasticsearch 不让用root用户直接运行,所以要创建新用户
useradd es
echo "123" |passwd --stdin es
chown -R es:es /usr/local/elasticsearch-7.6.1/
6.配置资源使用
vi /etc/security/limits.conf
1 2 3 4 | * soft nofile 65536* hard nofile 131072* soft nproc 65535* hard nproc 65535 End of file |
7.配置虚拟内存大小
vi /etc/sysctl.conf
1 2 | #添加下面配置vm.max_map_count=655360 |
sysctl -p
8.启动ES
su - es
cd /usr/local/elasticsearch-7.6.1/bin/
nohup ./elasticsearch &
查看日志(因为是nohup启动的,bin下面也会有一个nohup.out记录日志)
cd /usr/local/elasticsearch-7.6.1/logs
tail -f my-es.log
9.访问ES web页面
访问IP:9200即可
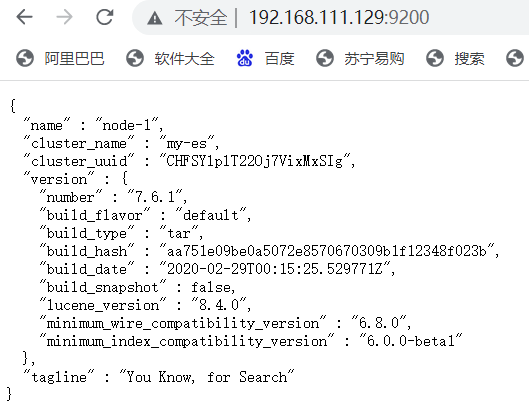
ES集群部署可参考Elasticsearch集群部署
Elasticsearch-head安装
elasticsearch-head将是一款专门针对于elasticsearch的客户端工具。elasticsearch-head是用于监控Elasticsearch状态的客户端插件,包括数据可视化、执行增删改查操作等。
由于head插件本质上还是一个nodejs的工程,因此需要安装node,使用npm来安装依赖的包。
nodejs下载地址:https://nodejs.org/en/download/
ElasticSearch-head下载地址:https://github.com/mobz/elasticsearch-head
1.解压nodejs安装包
tar -xf node-v14.18.0-linux-x64.tar.xz -C /usr/local/
2.配置nodejs的环境变量
vi /etc/profile
1 2 | export NODE_HOME=/usr/local/node-v14.18.0-linux-x64export PATH=$PATH:$NODE_HOME/bin |
source /etc/profile
node -v
1 | v14.18.0 |
npm -v
1 | 6.14.15 |
3.建立软连接
ln -s /usr/local/node-v14.18.0-linux-x64/bin/npm /usr/local/bin/
ln -s /usr/local/node-v14.18.0-linux-x64/bin/node /usr/local/bin/
4.安装cnpm命令
npm install -g cnpm --registry=https://registry.npm.taobao.org
5.解压ElasticSearch-head安装包并授权
unzip elasticsearch-head-master.zip -d /usr/local/
cd /usr/local/elasticsearch-head-master/
cnpm install
chown -R es:es /usr/local/elasticsearch-head-master/
6.修改ElasticSearch-head配置文件
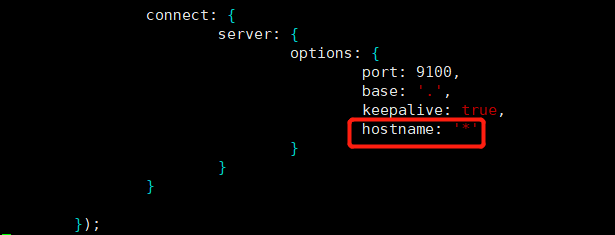
vim Gruntfile.js
1 | #找到connect,然后在true后面加逗号,然后换行添加hostname: '*' (注意,冒号后面有空格) |
vim _site/app.js
1 | #可以通过/app.App = ui进行查找,将localhost修改为ES的IP地址 |

7.修改ElasticSearch配置文件
cd /usr/local/elasticsearch-7.6.1/config/
vim elasticsearch.yml
1 2 3 | #添加如下参数,启用CORS,这里注意后面不允许出现空格http.cors.enabled: true http.cors.allow-origin: "*" |
8.重启ES并启动head
可以先通过Kill命令杀掉ES进程
su - es
cd /usr/local/elasticsearch-7.6.1/bin/
nohup ./elasticsearch &
cd /usr/local/elasticsearch-head-master/
nohup npm start &
查看日志
tail -f nohup.out
查看进程
1 2 | ps -ef|grep gruntes 4946 4934 0 4月05 pts/0 00:00:02 grunt |
9.访问ElasticSearch-head web页面
访问IP:9100即可
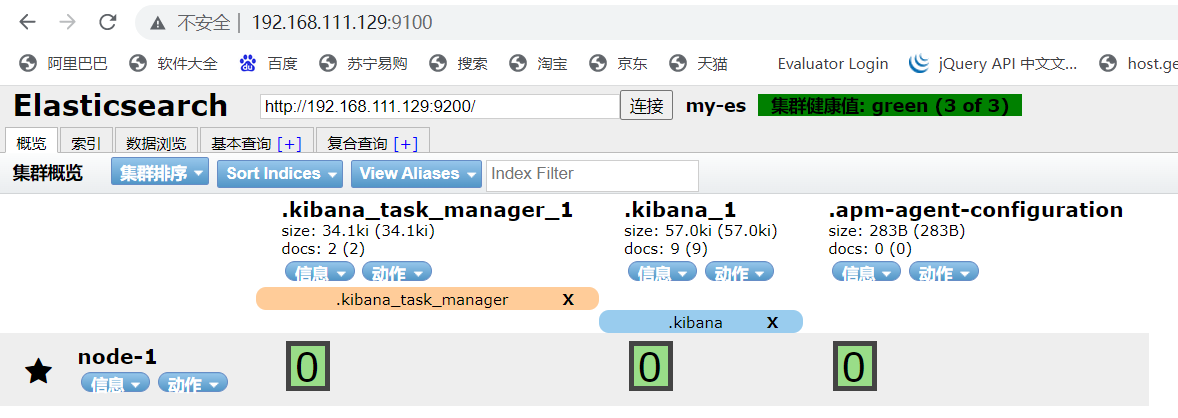
可参考elasticsearch-head页面说明及使用继续了解
Kibana安装
Kibana下载地址:https://mirrors.huaweicloud.com/kibana/?C=N&O=D
1.解压安装包
tar -zxvf kibana-7.6.1-linux-x86_64.tar.gz -C /usr/local/
2.配置Kibana配置文件
cd /usr/local/kibana-7.6.1-linux-x86_64/config/
vim kibana.yml
1 2 3 4 5 6 7 8 | #server.port: 5601#本机IP地址server.host: "192.168.111.129"#ES的端口及地址elasticsearch.hosts: ["http://192.168.111.129:9200"]elasticsearch.requestTimeout: 90000#中文化i18n.locale: "zh-CN" |
3.授权及启动Kibana
chown -R es:es /usr/local/kibana-7.6.1-linux-x86_64/
su - es
cd /usr/local/kibana-7.6.1-linux-x86_64/bin/
nohup ./kibana &
查看日志
tail -f nohup.out
4.查看进程
Kibana的进程通过ps -ef|grep kibana是无法查看到的,所以我们可以通过端口来进行查看
1 2 | netstat -tunlp|grep 5601tcp 0 0 192.168.111.129:5601 0.0.0.0:* LISTEN 3974/./../node/bin/ |
要想通过ps来查看的话可以通过ps -ef|grep node来进行查看,不过node查看的话,不一定会准确
1 2 3 | ps -ef|grep nodees 3974 3816 1 4月05 pts/0 00:01:54 ./../node/bin/node ./../src/cliroot 5029 4983 0 00:01 pts/0 00:00:00 grep --color=auto node |
5.访问Kibana web页面
访问IP:5601即可
6.测试连通性

接下来我们就可以了解一下Kibana的一些具体操作了,可参考Kibana使用说明
elasticsearch-analysis-ik分词器插件安装
作用:如果直接使用Elasticsearch的分词器在处理中文内容的搜索时,ES会将中文词语分成一个一个的汉字。当用Kibana作图,按照term来分组的时候,也会将一个汉字单独分成一组。这对于我们的使用是及其不方便的,因此我们引入es之中文的分词器插件es-ik就能解决这个问题。
elasticsearch-analysis-ik分词器下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
1.创建分词器目录
分词器安装在ES目录下即可,所有在ES目录下创建分词器目录
cd /usr/local/elasticsearch-7.6.1/plugins/
mkdir ik
2.解压安装包
unzip elasticsearch-analysis-ik-7.6.1.zip -d /usr/local/elasticsearch-7.6.1/plugins/ik/
3.重新对ES目录授权
chown -R es:es /usr/local/elasticsearch-7.6.1/
4.重启ES和Kibana
可以先通过Kill命令杀掉ES和Kibana进程
su - es
cd /usr/local/elasticsearch-7.6.1/bin/
nohup ./elasticsearch &
此时的ES日志是可以查看到是有加载分词器插件的

cd /usr/local/kibana-7.6.1-linux-x86_64/bin/
nohup ./kibana &
日志分析场景实现可参考ELK与EFK部署


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具