

RabbitMQ镜像集群部署及集群相关操作
RabbitMQ普通集群和镜像集群说明
普通集群
1、将 RabbitMQ 部署到多台服务器上,每个服务器启动一个 RabbitMQ 实例,多个实例之间进行消息通信。
2、此时我们创建的队列 Queue,它的元数据(主要就是 Queue 的一些配置信息)会在所有的 RabbitMQ 实例中进行同步,但是队列中的消息只会存在于一个 RabbitMQ 实例上,而不会同步到其他队列。
3.、当我们消费消息的时候,如果连接到了另外一个实例,那么那个实例会通过元数据定位到 Queue 所在的位置,然后访问 Queue 所在的实例,拉取数据过来发送给消费者。
这种集群可以提高 RabbitMQ 的消息吞吐能力,但是无法保证高可用,因为一旦Master实例挂了,消息就没法访问了。如果消息队列做了持久化,那么等Master实例恢复后,便可以继续访问;如果消息队列没做持久化,那么消息就丢了。
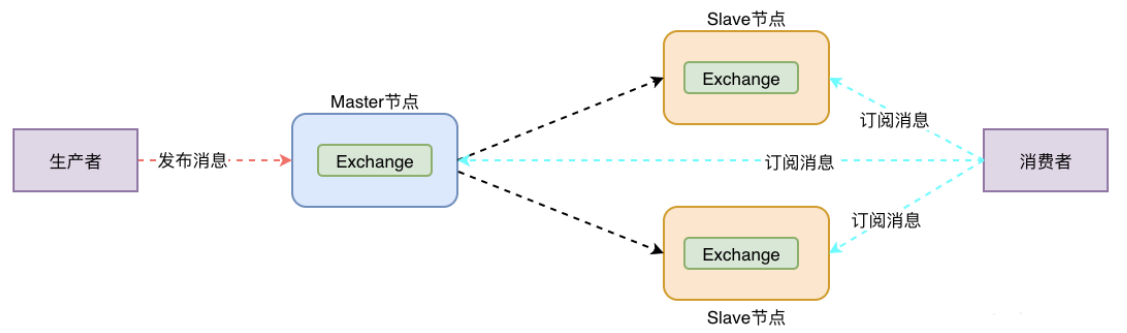
镜像集群
镜像集群的部署是依托在普通集群之上的
1、和普通集群最大的区别在于 Queue 数据和元数据不再是单独存储在一台机器上,而是同时存储在多台机器上
2、也就是说每个 RabbitMQ 实例都有一份镜像数据(副本数据)。每次写入消息的时候都会自动把数据同步到多台实例上去,这样一旦其中一台机器发生故障,其他机器还有一份副本数据可以继续提供服务,也就实现了高可用
3、镜像队列设置后,会分一个主节点和多个从节点,如果主节点宕机,从节点会有一个选为主节点,原先的主节点起来后会变为从节点。
镜像模式的优点:任何一个机器宕机,其他机器任然可以使用。
镜像模式的缺点:1、所有机器之间进行数据同步,增加性能开销,网络带宽压力大。2、可扩展性差,如果某个queue负载很重,你加机器,新增的机器也包含了这个queue的所有数据,并没有办法线性扩展你的queue。
RabbitMQ镜像集群部署服务规划:

该部署以Red Hat 7为例
安装RabbitMQ集群
1.安装RabbitMQ(所有设备)
可以参考我之前编写的RabbitMQ单机部署进行安装
2.关闭防火墙和SELinux(所有设备)
systemctl stop firewalld.service
systemctl disable firewalld.service
setenforce 0
vi /etc/selinux/config
1 | SELINUX=enforcing改为SELINUX=disabled |
3.配置IP地址和主机名之间的映射(所有设备)
vi /etc/hosts
1 2 | 192.168.36.150 rabbit-node1192.168.36.151 rabbit-node2 |
需重启设备生效
4.同步erlang cookies(150设备)
注:这里最好先将要同步的其他设备的RabbitMQ先停止,否则先同步再停止可能会报erlang.cookie不一致的错误,可以通过 rabbitmqctl stop_app 命令关闭
#RabbitMQ是通过erlang编写,erlang语言通过同步erlang集群各个节点的cookie实现分布式
scp /root/.erlang.cookie root@192.168.36.151:/root/.erlang.cookie
#查看两台设备是否一致
cat /root/.erlang.cookie
5.RabbitMQ集群添加节点(151设备)
在此登录其他节点加入集群,这里我的只有151一个设备
#关闭应用
rabbitmqctl stop_app
#重置节点
rabbitmqctl reset
#将node2加入集群并设置节点为内存节点(默认加入的为磁盘节点)
rabbitmqctl join_cluster --ram rabbit@rabbit-node1
- 也可以通过命令修改节点的类型rabbitmqctl changeclusternode_type disc | ram
- 磁盘节点和内存节点的具体说明,可参考RabbitMQ的内存节点和磁盘节点说明
#启动应用
rabbitmqctl start_app
#查看集群状态,任意节点都可以
rabbitmqctl cluster_status
完成后即可登录我们的RabbitMQ管理页面进行查看(ip:15672)
将某节点退出集群
1 2 3 4 | # 在退出的节点上执行rabbitmqctl stop_app# 在主节点上执行(如去除rabbit-node2),offline参数代表允许离线删除rabbitmqctl forget_cluster_node rabbit-node2 [--offline] |
6.配置镜像队列集群(任意节点)
以上配置完成的集群只是普通集群,该集群下不同节点数据不一定会一致,所以我们需要进行数据同步设置,两种方式任选其一即可
方式一:命令行配置
rabbitmqctl set_policy ha-all '^' '{"ha-mode":"all","ha-sync-mode":"automatic"}'
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | # 策略说明格式:rabbitmqctl set_policy [-p <vhost>] [--priority <priority>] [--apply-to <apply-to>] <name> <pattern> <definition>-p Vhost:可选参数,针对指定vhost下的queue进行设置--priority:可选参数,policy的优先级--apply-to:可选参数,策略适用对象类型,可选queues,exchanges,allname:policy策略的名称pattern:queue的匹配模式(正则表达式),^表示匹配所有队列definition:镜像定义,包括三个部分ha-mode, ha-params, ha-sync-mode 1、ha-mode:指明镜像队列的模式,有效值为 all/exactly/nodes all:表示在集群中所有的节点上进行镜像 exactly:表示在指定个数的节点上进行镜像,节点的个数由ha-params指定 nodes:表示在指定的节点上进行镜像,节点名称通过ha-params指定 2、ha-params:ha-mode模式需要用到的参数 3、ha-sync-mode:进行队列中消息的同步方式,有效值为automatic和manual,默认manual |
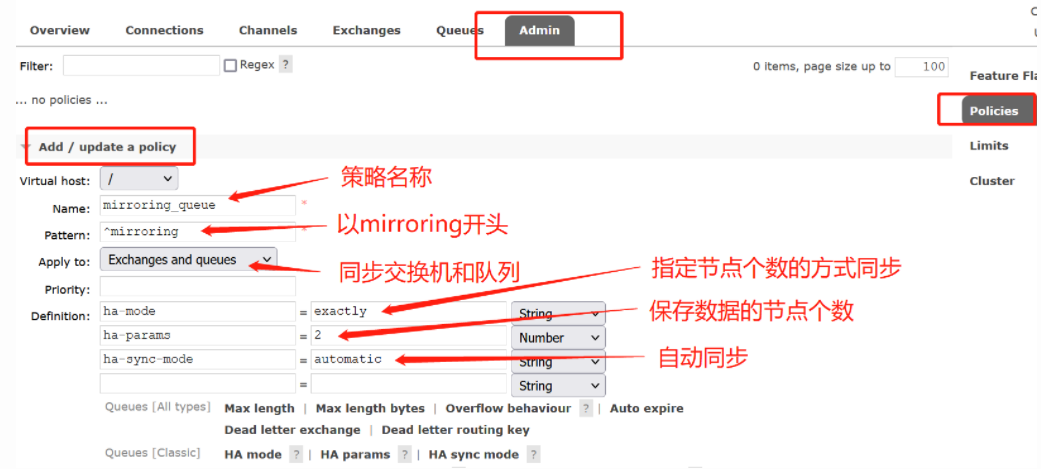
其它示例:新增一个名为myPolicy的策略,适用队列与交换机,优先级为1,同步 virtual host 为"/" 下名称前缀为"mirroring"的队列,并且自动保存到两个节点上,队列中消息的同步方式为automatic(自动的)
rabbitmqctl set_policy -p / --priority 1 --apply-to all myPolicy "^mirroring" '{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'
方式二:登录管理页面配置
安装HaProxy(所有设备)
HaProxy包下载地址:https://src.fedoraproject.org/repo/pkgs/haproxy/
1.部署HaProxy
tar -xf haproxy-2.5.5.tar.gz
cd haproxy-2.5.5/
make TARGET=linux-glibc ARCH=x86_64 PREFIX=/usr/local/haproxy
TARGET:内核版本
ARCH:系统CUP(64位为 x86_64)
make install PREFIX=/usr/local/haproxy
2.配置配置HaProxy环境变量
Vi /etc/profile
export HAPROXY_HOME=/usr/local/haproxy
export PATH=$PATH:$JAVA_HOME/bin:$ERLANG_HOME/bin:$RABBITMQ_HOME/sbin:/$HAPROXY_HOME/sbin #在path后加上该路径即可
source /etc/profile
3.创建HaProxy用户及用户组
groupadd haproxy
#创建nginx运行账户haproxy并加入到haproxy组,不允许haproxy用户直接登录系统
useradd -g haproxy haproxy -s /bin/false
4.创建相关文件目录
#创建haproxy错误日志目录
mkdir -p /usr/local/haproxy/errors
touch /usr/local/haproxy/errors/403.http
touch /usr/local/haproxy/errors/500.http
touch /usr/local/haproxy/errors/502.http
touch /usr/local/haproxy/errors/503.http
touch /usr/local/haproxy/errors/504.http
#创建日志文件
mkdir -p /usr/local/haproxy/logs
touch /usr/local/haproxy/logs/haproxy.log
#创建haproxy配置文件
mkdir -p /usr/local/haproxy/conf
touch /usr/local/haproxy/conf/haproxy.cfg
touch /usr/local/haproxy/stats
5.修改配置文件
vi /usr/local/haproxy/conf/haproxy.cfg
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 | global log 127.0.0.1 local1 chroot /usr/local/haproxy #haproxy的pid存放路径 pidfile /var/run/haproxy.pid maxconn 4000 user haproxy group haproxy daemon #需要创建该文件 stats socket /usr/local/haproxy/statsdefaults mode http #采用全局定义的日志 log global #日志类别http日志格式 option httplog #不记录健康检查的日志信息 option dontlognull #每次请求完毕后主动关闭http通道 option http-server-close option forwardfor except 127.0.0.0/8 #serverID对应的服务器挂掉后,强制定向到其他健康的服务器 option redispatch #3次连接失败就认为服务不可用,也可以通过后面设置 retries 3 timeout http-request 10s timeout queue 1m timeout connect 10s #客户端连接超时 timeout client 1m #服务器连接超时 timeout server 1m timeout http-keep-alive 10s timeout check 10s #最大连接数 maxconn 3000#开启haproxy监控服务listen rabbitmq_cluster #通过6672端口进行映射,映射的地址通过后面的server项进行配置 bind 0.0.0.0:6672 #记录tcp连接的状态和时间 option tcplog #四层协议代理,即对TCP协议转发 mode tcp #开启TCP的Keep Alive(长连接模式) option clitcpka #haproxy和rabbitmq建立连接的超时时间 timeout connect 1s #客户端与haproxy最大空闲时间 timeout client 10s #服务器与haproxy最大空闲时间 timeout server 10s #采用轮询转发消息 balance roundrobin #每5秒发送一次心跳包,如联系两次有响应则代表状态良好 #如连续三次没有反应,则视为服务故障,该节点将被剔除 server rabbit-node1 192.168.36.150:15672 check inter 5s rise 2 fall 3 server rabbit-node2 192.168.36.151:15672 check inter 5s rise 2 fall 3listen http_front #监听端口-页面访问的端口 bind 0.0.0.0:6001 #统计页面自动刷新时间 stats refresh 30s #统计页面url stats uri /haproxy_stats #指定haproxy访问用户名密码 stats auth haproxy_admin:haproxy_pwd #设置haproxy错误页面 errorfile 403 /usr/local/haproxy/errors/403.http errorfile 500 /usr/local/haproxy/errors/500.http errorfile 502 /usr/local/haproxy/errors/502.http errorfile 503 /usr/local/haproxy/errors/503.http errorfile 504 /usr/local/haproxy/errors/504.http |
6.开启日志记录
#Haproxy默认是没有开启日志记录的,需要根据rsyslog通过udp的方式获取Haproxy日志信息
vi /etc/rsyslog.conf
1 2 3 4 5 6 | # Provides UDP syslog reception#打开以下两行注解$ModLoad imudp$UDPServerRun 514#添加日志目录 (local1与haproxy.cfg中global log保持一致)local1.* /usr/local/haproxy/logs/haproxy.log |
vi /etc/sysconfig/rsyslog
1 2 3 4 5 6 | # Options for rsyslogd# Syslogd options are deprecated since rsyslog v3.# If you want to use them, switch to compatibility mode 2 by "-c 2"# See rsyslogd(8) for more details# 修改如下内容SYSLOGD_OPTIONS="-r -m 0 -c 1" |
#重启生效
systemctl start rsyslog
7.启动HaProxy
#检查配置文件语法
haproxy -c -f /usr/local/haproxy/conf/haproxy.cfg
#启动
haproxy -f /usr/local/haproxy/conf/haproxy.cfg
#重启命令
haproxy -f /usr/local/haproxy/conf/haproxy.cfg -st $(cat /var/run/haproxy.pid)
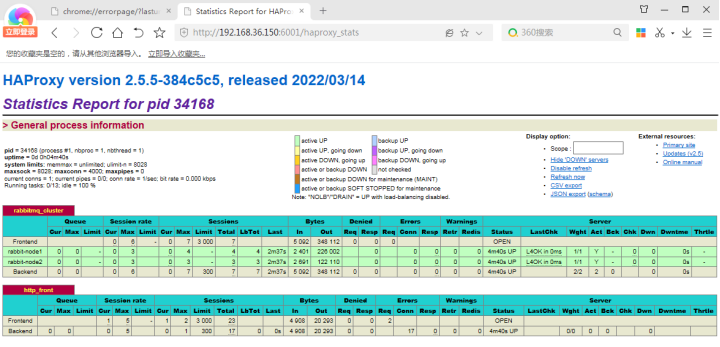
启动完成后即可通过浏览器登录ip:6001/haproxy_stats访问
账号密码为我们haproxy配置文件中所配置的haproxy_admin:haproxy_pwd
安装Keepalived(所有设备)
Keepalived包下载地址:https://www.keepalived.org/download.html
1.部署Keepalived
tar -zxvf keepalived-1.2.13.tar.gz
cd keepalived-1.2.13
./configure
make && make install
2.创建相关文件目录
mkdir /etc/keepalived
cp /usr/local/etc/rc.d/init.d/keepalived /etc/init.d/
cp /usr/local/etc/sysconfig/keepalived /etc/sysconfig/
cp /usr/local/etc/keepalived/keepalived.conf /etc/keepalived/
cp /usr/local/sbin/keepalived /usr/sbin/
cp /etc/keepalived/keepalived.conf keepalived.conf.bak
3.修改配置文件
vi /etc/keepalived/keepalived.conf
MASTER:(150设备)
#注意黄色字段即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | ! Configuration File for keepalivedglobal_defs { notification_email { acassen@firewall.loc failover@firewall.loc sysadmin@firewall.loc } notification_email_from Alexandre.Cassen@firewall.loc #smtp_server 192.168.200.1 #smtp_connect_timeout 30 router_id LVS_01}vrrp_instance VI_1 { state MASTER interface ens33 virtual_router_id 51 priority 150 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 192.168.36.199/24 }}#以下为LVS的配置,如果没有使用LVS,则可以全部删除掉 |
BACKUP:(151设备)
#注意黄色字段即可

! Configuration File for keepalived global_defs { notification_email { acassen@firewall.loc failover@firewall.loc sysadmin@firewall.loc } notification_email_from Alexandre.Cassen@firewall.loc #smtp_server 192.168.200.1 #smtp_connect_timeout 30 router_id LVS_02 } vrrp_instance VI_1 { state BACKUP interface ens33 virtual_router_id 51 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 192.168.36.199/24 } } #以下为LVS的配置,如果没有使用LVS,则可以全部删除掉
4.启动Keepalived
启动命令:/etc/init.d/keepalived start
关闭命令:/etc/init.d/keepalived stop
Keepalived启动完成后,在Master节点上查看IP即可看见我们的虚拟IP地址
ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 00:0c:29:fd:87:72 brd ff:ff:ff:ff:ff:ff inet 192.168.36.150/24 brd 192.168.36.255 scope global noprefixroute ens33 valid_lft forever preferred_lft forever inet 192.168.36.199/24 scope global secondary ens33 valid_lft forever preferred_lft forever inet6 fe80::ac5d:4c27:f607:e8aa/64 scope link noprefixroute valid_lft forever preferred_lft forever
然后可以尝试把Keeplived Master节点关闭看虚拟IP会不会漂移到另一个节点,成功漂移即可
5.Keepalived优化
至此,我们的Keepalived虽然部署成功了,但是此时只有当Master节点上的Keepalived down掉,我们的虚拟IP才会漂移,如果是Haproxy down掉,Keepalived进程是还会继续运行的,所以我们要做以下配置,让Haproxy down掉的时候,Keepalived也会自己down掉,这样我们才能将虚拟IP进行漂移,从而保证服务的访问正常(只需要在Master节点上做该配置即可,因为Master再次启动时,虚拟IP是会漂移回来的)
方式一:
#编写一个后台运行的脚本来监控Haproxy状态
cd /etc/keepalived/
vi check_hap.sh
#!/bin/bash while true do hap=$(ps -ef|grep haproxy|grep -v 'grep'|awk '{print $2}'|wc -l) if [[ $hap -eq 0 ]];then /etc/init.d/keepalived stop else continue fi sleep 5 done
chmod +x check_hap.sh
#后台运行该脚本
nohup ./check_hap.sh 2>&1 &
方式2:
#同样是需要编写一个监控Haproxy的脚本,但是是由Keepalived来调用该脚本
cd /etc/keepalived/
vi check_hap.sh
#!/bin/bash hap=$(ps -ef|grep haproxy|grep -v 'grep'|awk '{print $2}'|wc -l) if [[ $hap -eq 0 ]];then /etc/init.d/keepalived stop else continue fi
chmod +x check_hap.sh
#修改keepalived配置文件
vi keepalived.conf
#参考红色部分即可
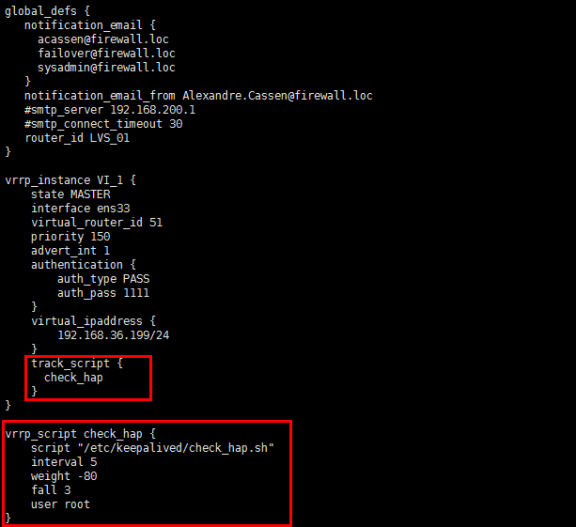
#配置完成后重启Keepalived
/etc/init.d/keepalived restart
扩展:keepalived日志默认是在系统日志下的/var/log/messages,若想要做日志分离,可参考Keepalived日志分离配置
至此,我们RabbitMQ集群高可用就部署完成了


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 上周热点回顾(3.3-3.9)
· AI 智能体引爆开源社区「GitHub 热点速览」