数据对齐
本文是针对2005年的一篇关于数据对齐的技术文章《Data alignment: Straighten up and fly right》的学习笔记。以下内容中理论部分来自对文章的翻译,实验部分是在魅族16x(高通骁龙sdm710)上跑的测试结果。
理论
内存访问粒度
我们通常简单地认为内存就像是一个字节数组,CPU逐字节逐字节地访问内存:

然而事实上,CPU通常以2字节,4字节,8字节或16字节为块,逐块逐块地访问内存:

这个块的大小(也就是一次读取内存的大小)被叫做内存访问粒度(Memory access granularity)。
数据对齐
我们所说的数据按2 byte对齐,4 byte对齐,8 byte 对齐,指的是数据的内存地址能被2,4,8整除。我们通过一个例子来看不同内存访问粒度下,地址对齐与否在内存访问上的差异。这个例子是:从地址0(对齐地址)开始读取4字节,然后再从地址1(非对齐地址)开始读取4字节。
- 1 byte 内存粒度
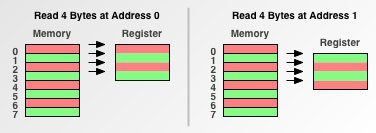
因为一次就读取1字节,所以不管从哪个地址开始读取,都需要4次内存访问。
- 2 byte 内存粒度

从地址0开始读取,需要2次内存访问。而地址1是个非对齐的地址,因为它不是内存粒度的倍数,地址不在内存访问的边界,所以从地址1开始读取需要:
首先读取(0-1)两个地址,将(0)移除;
其次读取(2-3)两个地址;
再次读取(4-5)两个地址,将(5)移除;
最后合并(1),(2-3)和(4),放入寄存器中。
可见从地址1开始读取,需要3次内存访问和移除之类的附加操作。
- 4 byte 内存粒度
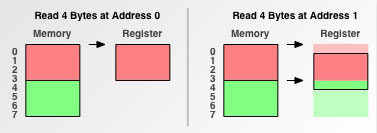
从地址0开始读取,需要1次内存访问。而从地址1开始读取需要:
首先读取(0-3)四个地址,将(0)移除;
其次读取(4-7)四个地址,将(5-7)移除;
最后合并(1-3)和(4),放入寄存器中。
可见从地址1开始读取,需要2次内存访问和移除之类的附加操作。
鉴于内存访问的开销是一个常量,读取同样大小的字节时,内存粒度越大,内存访问的开销越小,读取的速度就越快。地址不对齐时,需要更多内存访问的开销以及附加操作,从而降低了读取速度。
结构体成员对齐
默认情况下:
- 结构体中各成员按自身类型大小对齐,即各成员变量的地址必须是自身类型的倍数。
- 结构体的总大小必须是成员中最大类型的整数倍,整个结构体的地址也必须是成员中最大类型的整数倍。
为了达到上述要求,各成员变量之间会补充相应的padding。如下例,结构体S1的成员m1和m2之间有7 byte的填充,整个结构体的大小是16 byte。通过打印查看,s1 的地址是0xffda3d68, s1.m2的地址是0xffda3d70。要注意s1 的地址也必须是sizeof(double)的倍数,否则m1和m2之间填充的就不是7 byte了。
struct S1
{
char m1; // 1-byte
// padding 7-byte space here
double m2; // 8-byte
};
struct S1 s1;
printf("size of s1 %u", sizeof(s1));
printf("s1 address 0x%x, s1.m2 address 0x%x\n", &s1, &(s1.m2));
- 结构体作为成员,类型大小按其成员所含最大类型计算。
如下例,结构体S1作为结构体S2的一个成员。因为S1中最大类型成员是m2,所以S2的成员s1按8 byte(sizeof(double))对齐而不是按16 byte(sizeof(struct S1))对齐,整个结构体S2的大小为24 byte。通过打印查看,s2的地址是0xffaf3b20, s2.s1的地址是0xffaf3b28。
struct S2
{
char m1; // 1-byte
// padding 7-byte space here
struct S1 s1; // 16-byte
};
struct S2 s2;
printf("size of s2 %u\n", sizeof(s2));
printf("s2 address 0x%x, s2.s1 address 0x%x\n", &s2, &(s2.s1));
在某些场景下,我们想要控制结构体中各成员的字节对齐,那么可以通过#pragma pack宏来控制。如下例,#pragma pack(push, 1)表明结构体中各成员按1 byte对齐,结构体S1的大小为9,结构体S2的大小为10。通过打印,s2.s1的地址是0xffd1ccd1,显然已经不能被2,4,8整除了。
#pragma pack(push, 1)
struct S1
{
char m1;
double m2;
};
#pragma pack(pop)
struct S2
{
char m1;
struct S1 s1;
};
实验
速度
基于上面的理论,从一个非对齐的地址开始访问内存会需要更多的开销,原文《Data alignment: Straighten up and fly right》中也通过实验对比了非对齐地址和对齐地址访问内存的速度,实验的结果是对齐地址访问内存的速度要快过非对齐地址。考虑原文发表于2005年,其实验结果是否仍然适用于如今不得而知,因此本文在魅族16x(高通骁龙sdm710)上进行相同的实验,看看最近的CPU是否已经支持非对齐地址访问。测试代码如下:
void Munge8(void* data, size_t size)
{
uint8_t* data8 = reinterpret_cast<uint8_t*>(data);
uint8_t* data8end = data8 + size;
while (data8 != data8end)
{
*data8 = -(*data8);
++data8;
}
}
void Munge16(void* data, size_t size)
{
uint16_t* data16 = reinterpret_cast<uint16_t*>(data);
uint16_t* data16end = data16 + (size >> 1);
uint8_t* data8 = reinterpret_cast<uint8_t*>(data16end);
uint8_t* data8end = data8 + (size & 0x0001);
while (data16 != data16end)
{
*data16 = -(*data16);
++data16;
}
while (data8 != data8end)
{
*data8 = -(*data8);
++data8;
}
}
void Munge32(void* data, size_t size)
{
uint32_t* data32 = reinterpret_cast<uint32_t*>(data);
uint32_t* data32end = data32 + (size >> 2);
uint8_t* data8 = reinterpret_cast<uint8_t*>(data32end);
uint8_t* data8end = data8 + (size & 0x0003);
while (data32 != data32end)
{
*data32 = -(*data32);
++data32;
}
while (data8 != data8end)
{
*data8 = -(*data8);
++data8;
}
}
void Munge64(void* data, size_t size)
{
uint64_t* data64 = reinterpret_cast<uint64_t*>(data);
uint64_t* data64end = data64 + (size >> 3);
uint8_t* data8 = reinterpret_cast<uint8_t*>(data64end);
uint8_t* data8end = data8 + (size & 0x0007);
while (data64 != data64end)
{
*data64 = -(*data64);
++data64;
}
while (data8 != data8end)
{
*data8 = -(*data8);
++data8;
}
}
void run_memory_alignment_test()
{
char* data = new char[1024 * 1024 * 200]();
if (NULL != data)
{
const size_t munge_size = 1024 * 1024 * 160;
long long tic = 0;
long long toc = 0;
for (uint i = 0; i < 16; ++i)
{
void* pData = reinterpret_cast<void*>(reinterpret_cast<uint8_t*>(&data[0]) + i);
printf("read data from address 0x%x\n", pData);
// test for Munge8
tic = Utils::GetCurrentTime();
for (uint j = 0; j < 10; ++j)
{
Munge8(pData, munge_size);
}
toc = Utils::GetCurrentTime();
printf("run Munge8 for align %u use %llums\n", i, (toc - tic) / 10);
// test for Munge16
tic = Utils::GetCurrentTime();
for (uint j = 0; j < 10; ++j)
{
Munge16(pData, munge_size);
}
toc = Utils::GetCurrentTime();
printf("run Munge16 for align %u use %llums\n", i, (toc - tic) / 10);
// test for Munge32
tic = Utils::GetCurrentTime();
for (uint j = 0; j < 10; ++j)
{
Munge32(pData, munge_size);
}
toc = Utils::GetCurrentTime();
printf("run Munge32 for align %u use %llums\n", i, (toc - tic) / 10);
// test for Munge64
tic = Utils::GetCurrentTime();
for (uint j = 0; j < 10; ++j)
{
Munge64(pData, munge_size);
}
toc = Utils::GetCurrentTime();
printf("run Munge64 for align %u use %llums\n", i, (toc - tic) / 10);
}
delete[] data;
data = NULL;
}
else
{
printf("error : out of memory.");
}
}
测试代码以NDK分别基于armeabi,armeabi-v7a和arm64-v8a三种指令集编译可执行文件。在高通骁龙sdm710上执行可执行文件,从实际的结果来看,运行时间已经和原文给出的结论不一样,测试结果如下:
- 基于armeabi指令集
从测试结果看,armeabi指令集上不管起始地址是否对齐,其耗时基本一致。同时还看出单次访问的字节数越多,循环次数越少,整体的运行时间就越少,Time(Munge8) > Time(Munge16) > Time(Munge32) > Time(Munge64)。

另外当地址不是4的倍数时,运行Munge64会抛出总线错误的异常:
11-08 10:39:55.763 7325 7325 F libc : Fatal signal 7 (SIGBUS), code 1, fault addr 0xe0300001 in tid 7325 (alignment_test), pid 7325 (alignment_test)
11-08 10:39:55.837 7328 7328 I crash_dump32: obtaining output fd from tombstoned, type: kDebuggerdTombstone
11-08 10:39:55.838 1005 1005 I /system/bin/tombstoned: received crash request for pid 7325
11-08 10:39:55.839 7328 7328 I crash_dump32: performing dump of process 7325 (target tid = 7325)
11-08 10:39:55.839 7328 7328 I crash_dump32: call setprop_coredump_comm_pid, 7325 (target tid = 7325)
11-08 10:39:55.841 7328 7328 F DEBUG : *** *** *** *** *** *** *** *** *** *** *** *** *** *** *** ***
11-08 10:39:55.841 7328 7328 F DEBUG : Build fingerprint: 'Meizu/meizu_16X_CN/16X:8.1.0/OPM1.171019.026/1539636360:userdebug/test-keys'
11-08 10:39:55.841 7328 7328 F DEBUG : Revision: '0'
11-08 10:39:55.841 7328 7328 F DEBUG : ABI: 'arm'
11-08 10:39:55.841 7328 7328 F DEBUG : pid: 7325, tid: 7325, name: alignment_test >>> ./alignment_test <<<
11-08 10:39:55.841 7328 7328 F DEBUG : signal 7 (SIGBUS), code 1 (BUS_ADRALN), fault addr 0xe0300001
11-08 10:39:55.841 7328 7328 F DEBUG : r0 e0300001 r1 00000000 r2 f2c80001 r3 fffffff8
11-08 10:39:55.841 7328 7328 F DEBUG : r4 0a000000 r5 f2c80001 r6 0a000000 r7 ff99f9d0
11-08 10:39:55.841 7328 7328 F DEBUG : r8 00000000 r9 00000000 sl 00000000 fp ff99fa0c
11-08 10:39:55.841 7328 7328 F DEBUG : ip 000ba572 sp ff99f988 lr b948fa97 pc b948f8ac cpsr 20000030
11-08 10:39:55.843 7328 7328 F DEBUG :
11-08 10:39:55.843 7328 7328 F DEBUG : backtrace:
11-08 10:39:55.843 7328 7328 F DEBUG : #00 pc 000008ac /system/bin/alignment_test/armeabi/alignment_test
11-08 10:39:55.843 7328 7328 F DEBUG : #01 pc 00000a93 /system/bin/alignment_test/armeabi/alignment_test
11-08 10:39:55.843 7328 7328 F DEBUG : #02 pc 00000811 /system/bin/alignment_test/armeabi/alignment_test
11-08 10:39:55.843 7328 7328 F DEBUG : #03 pc 00080ba5 /system/lib/libc.so (__libc_init+48)
11-08 10:39:55.843 7328 7328 F DEBUG : #04 pc 000007c8 /system/bin/alignment_test/armeabi/alignment_test
11-08 10:39:55.891 7328 7328 I crash_dump32: performing dump name is ./alignment_test
从抛出的错误代码BUS_ADRALN来看是因为地址不对齐引起的,但是不清楚为何地址不对齐时,Munge32等其他函数运行不会有总线错误出现,还希望有了解的大神指导指导!
- 基于armeabi-v7a指令集
和armeabi指令集一样,armeabi-v7a指令集上不管起始地址是否对齐,其耗时基本一致。虽然得益于armeabi-v7a指令集的优化,函数运行时间得到了提升,但依然遵循:Time(Munge8) > Time(Munge16) > Time(Munge32) > Time(Munge64)。同样地,当地址不是4的倍数时,运行Munge64会抛出同样的总线错误。

- 基于arm64-v8a指令集
从测试结果看,arm64-v8a指令集上不管起始地址是否对齐,其耗时基本一致。且做了更进一步的优化,不管单次访问的字节数是多少,整体的运行时间基本一致,Time(Munge8) == Time(Munge16) == Time(Munge32) == Time(Munge64)。

总结
本文的实验仅能说明在魅族16x(高通骁龙sdm710平台)上:
- 三种指令集上非对齐内存访问所需开销和对齐内存访问的开销基本一致。
- armeabi和armeabi-v7a指令集上,当地址不对齐时,运行Munge64(非对齐地址单次访问8 byte)会出现
BUS_ADRALN的总线错误。 - arm64-v8a在内存访问上做了更进一步的优化,不管单次访问的字节数是多少,整体的运行时间基本一致。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号