linux笔记
Linux
磁盘分区相关
磁盘分区的作用
1.让数据更加安全,对一个分区的数据进行重整时不会影响到另外分区的数据
2.提高性能,分区后数据集中在磁盘的柱面上,搜索时数据更加集中,提高读取速度
磁盘可以分成主分区、拓展分区、逻辑分区(在拓展分区上划分)
(一块磁盘最多四个主分区,或者三个主分区加一个拓展分区)
命名:
/dev/sda(SCSI接口类型磁盘第一块)
/dev/sdb (SCSI接口类型磁盘第二块)
/dev/hda(IDE接口类型磁盘第一块)
/dev/hdb(IDE接口类型磁盘第二块)
每块分区的序号1-4是留给主分区和拓展分区的,故逻辑分区的编号一定是从5开始的
cat:获取展示文件的所有内容 (tac 从后往前显示 cat命令倒置)
nl:显示非空行文件内容同时显示行号 (cat -n 显示文件所有行的行号)
more/less:一行一行显示文件内容 不同的是less可以上下翻页
head/tail:只查看文件头/尾几行
od:以某种编码形式查看文件 (-h 以十六进制查看 -c以字符形式查看)
wc:显示文件信息(显示形式:行数、单词数、字符数)

diff:查看两个文件的差异
用法:diff 1.txt 2.txt
显示表达式如下:
0a1 --在1.txt 文件的第0行加了一行
3c3 --两个文件在第三个有所不同
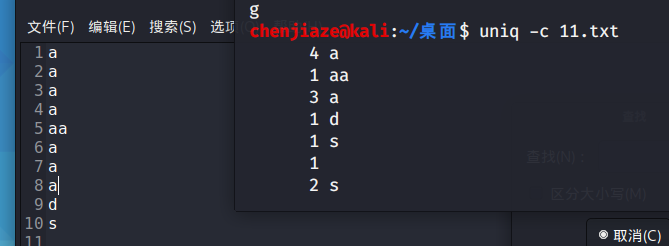
uniq:显示出删除文件重复行的结果 -c显示出重复行的数量
Chmod命令
ls-l命令 列出查看一个目录下的文件和子目录的详悉信息
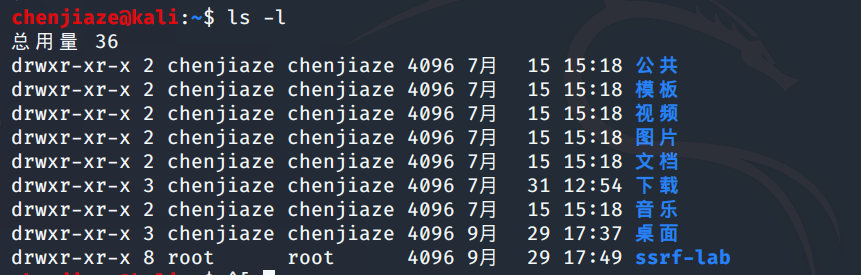
ls -ld 显示当前目录的详细信息
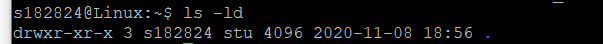
第一个字符
p表示命名管道文件
d表示目录文件
l表示符号连接文件
-表示普通文件
s表示socket文件
c表示字符设备文件
b表示块设备文件
Linux/Unix 的文件调用权限分为三级 : 文件所有者(Owner)、用户组(Group)、其它用户(Other Users)。
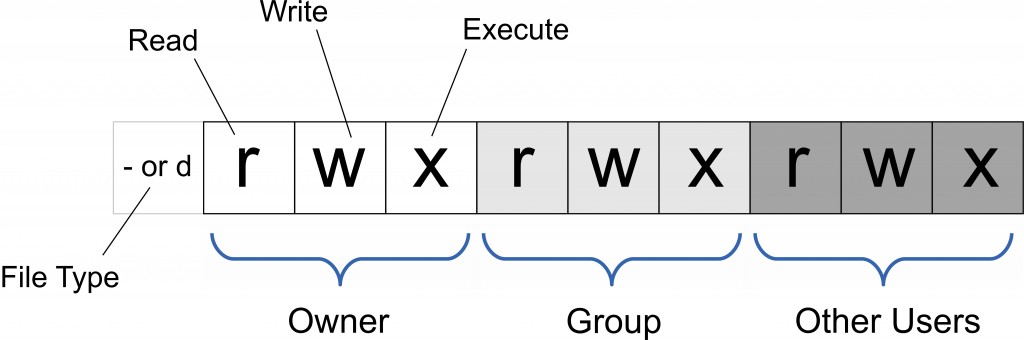
chmod命令用于改变指定文件的权限(读写执行)
相关参数
u表示文件拥有者,g表示与文件拥有者同组用户,o表示其他用户,a表示所有用户
+表示增加权限,-表示取消权限,=指定权限
r读,w写,x可执行
八进制表示
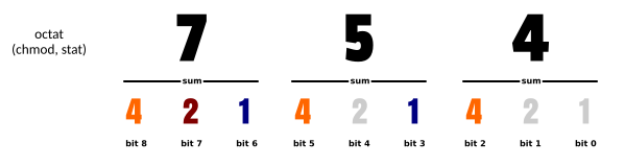
案例

特殊权限位
SUID(Set UID)
有时在文件的执行位x处会出现's'字段 ,说明设定了suid

这个权限位的功能是:只要用户对某个文件有执行权限,那么当他去执行文件的时候,系统会默认他会以这个文件的所有者去执行,一旦文件执行结束,身份切换也随即消失。
例如,当一个普通用户执行passwd命令改密码,虽说/etc/passwd对于普通用户来说是没有任何权限的,但是因为passwd命令设定了suid,所以普通用户在执行的时候,相当于以root(/etc/shadow文件所有者)的身份去修改密码,但是这个命令结束,普通用户还是普通用户。
SGID(Set GID)
与SUID类似,设定后,当一个用户执行一个文件,他会认为是与这个文件所者同组的用户的身份来执行文件
SBIT(Sticky Bit)
是很多个用户在同一个目录下都能写文件和删除文件,但是大家都只能操作自己的文件,不能操作其他人的文件,只有root和该目录的所有者才能操作目录下的文件。
chgrp
Linux chgrp(英文全拼:change group)命令用于变更文件或目录的所属群组。
chown
Linux chown(英文全拼:change ownerp)命令用于设置文件所有者和文件关联组的命令。
Linux的LVM管理
绝大多数都是使用MBR(Master Boot Recorder)都是通过先对一个硬盘进行分区,然后再将该分区进行文件系统的格式化,在Linux系统中如果要使用该分区就将其挂载上去即可,windows的话其实底层也就是自动将所有的分区挂载好,然后我们就可以对该分区进行使用了。
参考:
https://www.cnblogs.com/shoufeng/p/10615452.html 概念
https://zhuanlan.zhihu.com/p/62597195 逻辑卷过程
LVM指Logical Volume Manager,逻辑卷管理,是一种对磁盘空间的动态管理(对比与标准分区)
实现方法
一种将一至多个硬盘的分区在逻辑上进行组合, 当成一个大硬盘来使用。当硬盘空间不足时, 可以动态地添加其它硬盘的分区到已有的卷组中(提高磁盘分区管理的灵活性)
未用LVM的坏处
(1) 不同的分区相互独立, 单独的文件不能跨分区存储, 容易出现硬盘的利用率不均衡;
(2)如果一个文件系统/分区满了,按传统的基于分区式的文件系统,就必须重新分区/建立文件
(3)如果要把硬盘上的多个分区合并在一起使用, 只能采用重新分区的方式, —— 需要做好数据的备份与恢复.
具体实现
四个逻辑卷基本概念
①PE (Physical Extend) 物理块
②PV (Physical Volume) 物理卷:可以是整个物理硬盘,可以是raid设备
③VG (Volume Group) 卷组:一个卷组包含至少一个物理卷
④LV (Logical Volume) 逻辑卷
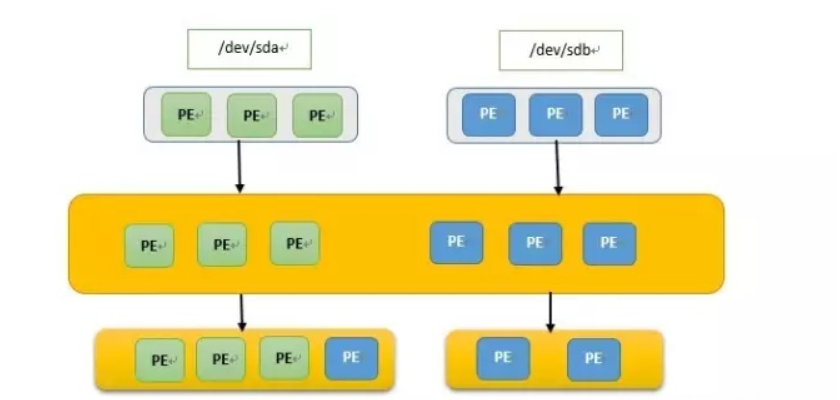
1.将物理硬盘格式化成PV(Physical Volume 物理卷
将硬盘sda sdb 格式化成PV, 这个过程是将LVM是将底层的硬盘划分为了一个一个的PE(Physical Extend)。
LVM磁盘管理中PE默认大小为4M,PE就是我们逻辑卷管理的最基本单位.
2.创建一个VG(Volume Group)
在将硬盘格式化成PV以后,我们第二步操作就是创建一个卷组,也就是VG(Volume Group),卷组在这里我们可以将其抽象化成一个空间池,VG的作用就是用来装PE的,我们可以把一个或者多个PV加到VG当中,因为在第一步操作时就已经将该硬盘划分成了多个PE,所以将多个PV加到VG里面后,VG里面就存放了许许多多来自不同PV中的PE
我们通过上面的图片就可以看到,我们格式化了两块硬盘,每个硬盘分别格式化成了3个PE,然后将两块硬盘的PE都加到了我们的VG当中,那么我们的VG当中就包含了6个PE,这6个PE就是两个硬盘的PE之和。通常创建一个卷组的时候我们会为其取一个名字,也就是该VG的名字。
3.基于VG创建我们最后要使用的LV(Logical Volume)
当我们创建好我们的VG以后,这个时候我们创建LV其实就是从VG中拿出我们指定数量的PE
创建逻辑卷其实就是我们从VG中拿出我们指定数量的PE,VG中的PE可以来自不同的PV,我们可以创建的逻辑卷的大小取决于VG当中PE存在的数量,并且我们创建的逻辑卷其大小一定是PE的整数倍(即逻辑卷的大小一定要是4M的整数倍)。
4.将我们创建好的LV进行文件系统的格式化,然后挂载使用
在创建好LV以后,这个时候我们就能够对其进行文件系统的格式化了,
我们最终使用的就是我们刚创建好的LV,其就相当于传统的文件管理的分区
我们首先要对其进行文件系统的格式化操作,然后通过mount命令对其进行挂载,
这个时候我们就能够像使用平常的分区一样来使用我们的逻辑卷了。
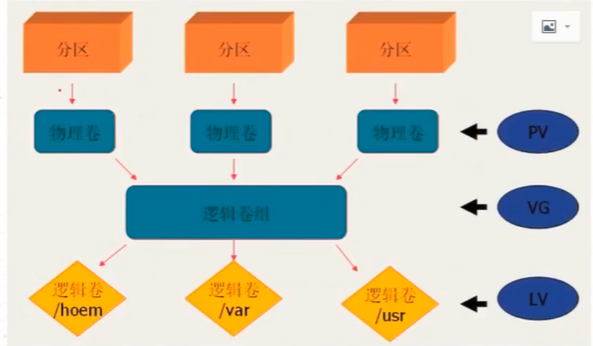
LVM总结:
(1)物理磁盘被格式化为PV,空间被划分为一个个的PE
(2)不同的PV加入到同一个VG中,不同PV的PE全部进入到了VG的PE池内
(3)LV基于PE创建,大小为PE的整数倍,组成LV的PE可能来自不同的物理磁盘
(4)LV现在就直接可以格式化后挂载使用了
(5)LV的扩充缩减实际上就是增加或减少组成该LV的PE数量,其过程不会丢失原始数据
Linux权限掩码umask
linux中umask函数主要用于,在创建新文件或者新目录的时候,指定用户创建的新文件新目录的权限默认值


umask默认为0022
0:特殊权限位
022:用户权限位 权限掩码值,实际权限为777-022=755 (rwx r-x r-x)
如果用户创建的是目录,则默认所有权限都开放,为777,默认为:drwxrwxrwx
新建文件:666-022=644; 新建目录:777-022=755.
可以更改权限掩码

Linux用户有关
创建新用户 adduser + 用户名
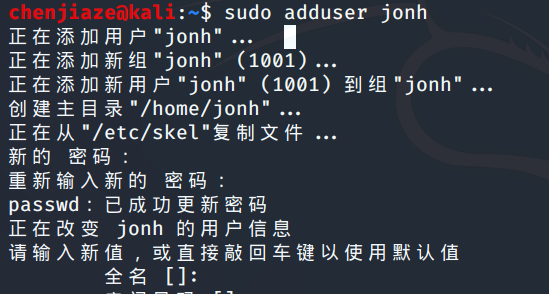
切换用户 su+用户名
linux /etc/passwd 文件
是系统用户配置文件,存储额系统中所有用户的基本信息,并且所有用户都可以对此文件执行读操作。
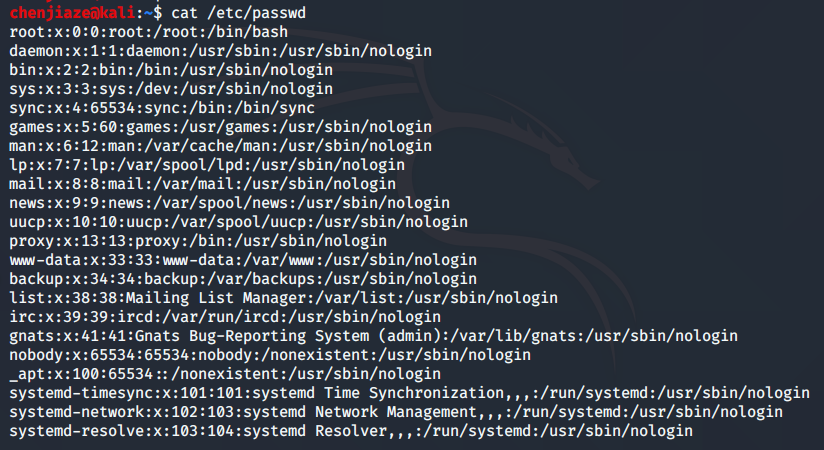
读者可能会问,Linux 系统中默认怎么会有这么多的用户?这些用户中的绝大多数是系统或服务正常运行所必需的用户,这种用户通常称为系统用户或伪用户。系统用户无法用来登录系统,但也不能删除,因为一旦删除,依赖这些用户运行的服务或程序就不能正常执行,会导致系统问题。
/etc/passwd展示了七个字段,分别以冒号隔开
七个字段详细信息如下:
用户名 (magesh): 已创建用户的用户名,字符长度 1 个到 12 个字符。
密码(x):代表加密密码保存在 /etc/shadow 文件中。、
用户 ID(506):代表用户的 ID 号,每个用户都要有一个唯一的 ID 。**UID 号为 0 的是为 root 用户保留的**,UID 号 1 到 99 是为系统用户保留的,UID 号 100-999 是为系统账户和群组保留的。
**群组 ID (**507):代表群组的 ID 号,每个群组都要有一个唯一的 GID ,保存在 /etc/group文件中。
**用户信息**:代表描述字段,可以用来描述用户的信息
**家目录**(/home/mageshm):代表用户的家目录。
**Shell**(/bin/bash):代表用户使用的 shell 类型。
Linux /etc/shadow(影子文件)
/etc/passwd 文件,由于该文件允许所有用户读取,易导致用户密码泄露,因此 Linux 系统将用户的密码信息从 /etc/passwd 文件中分离出来,并单独放到了此文件中。
/etc/shadow 文件只有 root 用户拥有读权限,其他用户没有任何权限,这样就保证了用户密码的安全性。
内容
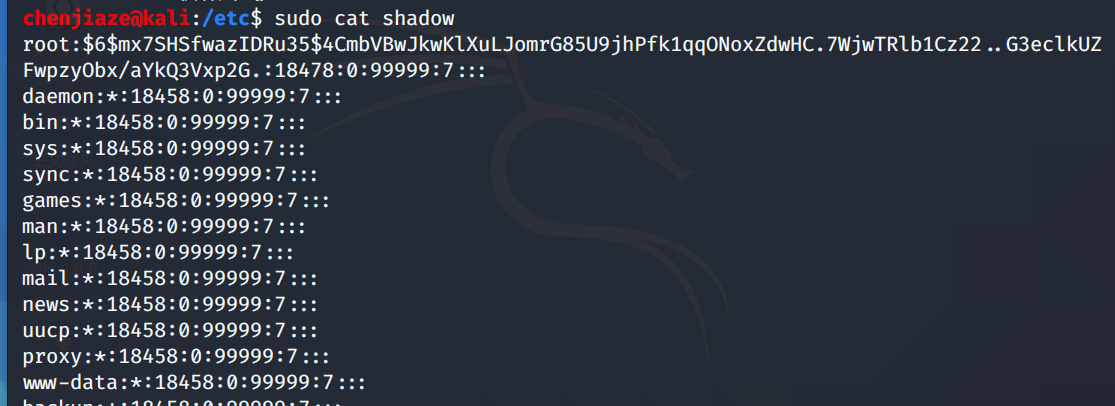
用户名:加密密码:最后一次修改时间:最小修改时间间隔:密码有效期:密码需要变更前的警告天数:密码过期后的宽限时间:账号失效时间:保留字段
Find 命令
find -name '*.c' --找出所有.c结尾的文件(默认指当前目录下的文件)
find /tmp -name '*.c' --找出/tmp中所有.c结尾的文件
find . -type f --将当前目录下的所有一般文件列出来
-type 参数意义
d: 目录
c: 字型装置文件
b: 区块装置文件
p: 具名贮列
f: 一般文件
l: 符号连结
s: socket
find -size 0 --找出当前目录下的空文件
-size +1M (大于1M)
-size -1K (小于1K)
find -size 0 -exec ls -l {} ; --找出所有大小为零的文件并展示详细信息
注意 :;前有空格
-exec 将直接执行语句
find -size 0 -ok rm {} ; --找出所有大小为零的文件并删除他们
-ok 会让你是否确定执行
find . -ctime -20 --找出所有最近20天内更新过的文件
-20 最近20天内
+20 距现在20天前
find . -type f -perm 644 -exec ls -l {} ;
--查找前目录中文件属主具有读、写权限,并且文件所属组的用户和其他用户具有读权限的文件:

which命令
显示在环境变量下符合条件的文件

几种“找文件“命令对比
which:根据PATH环境变量去找存在的可执行文件
whereis:在一些特定目录里面找,可以用whereis -l 展示这些特定目录
locate:在/var/lib/mlocate中找文件,
find:在硬盘中找文件,是速度最慢但最全的搜索方法
sort命令
sort用来对获取到的信息进行特定方式的排序
sort 1.txt --默认排序方式是以第一个字段以ASCII 码次序排序
sort -u 1.txt --排序忽略重复行
sort -r 1.txt --以默认排序的倒序排序显示
sort -r 1.txt o 2.txt --将1.txt的逆序重定向到2.txt
sort -n 1.txt --特别指用number即数值的形式排序
sort -k3 1.txt --以第三个字段排序
sort -t: -k3 1.txt --以冒号作为分隔符,以第三个字段排序
cut命令
cut命令用来显示行中的指定部分,删除文件中指定字段。cut经常用来显示文件的内容。
试验文档
[root@localhost text]# cat test.txt
No Name Mark Percent
01 tom 69 91
02 jack 71 87
03 alex 68 98
cut -f 1 test.txt --显示test里面第一个字段结果
cut -f 2,3 test.txt --显示text第二、三字段
cut -f2 -complement test.txt --显示除了第二个字段以外内容
cut -d: -f1,2 text.txt --以冒号作为分隔符分隔字段 ,显示第一、二字段
cut -d' ' -f 1,2 1.txt --以空格作为分隔符分隔字段,显示第一、二字段
paste命令
按列合并两个文本的内容

同样地,可以用重定位符 :paste ts1 ts2 > ts3.txt
paste -d: ts1 ts2 --d参数指定连接分隔符
grep命令
grep全程global search regular expression(RE) and print out the line。
全局正则搜索然后打印出来,是一个强大的搜索命令
grep 123 1.txt(grep 123 1.txt) --在1.txt里面搜索’123'
grep -n 123 1.txt --打印结果显示行号

grep -v 123 1.txt --打印没有包含123的结果
grep -i abc 1.txt --查询过程忽略大小写
grep -c abc 1.txt --显示含有abc的行的数量
grep -E --使用延伸型正则表达式 (存在 + ? | () 等符号时使用)建议直接用egrep
sed命令
sed命令用来处理文本
sed -e 4a 123 1.txt --在1.txt 第四行后面添加'123'
nl /etc/passwd | sed '2d' --显示passwd内容 并且将第二行删除
nl /etc/passwd | sed '3,$d' --显示passwd内容 并且将第三行到之后的行删除
nl /etc/passwd | sed '2i drink tea' --在第二行前一行插入'drink tea'
nl /etc/passwd | sed '2,5c No 2-5 number' --将第2-5行替代成'No 2-5 number'
sed '/[1]*$/d' /tmp/hello.c --删除空行
sed -i '/[2]*$/d' /tmp/hello.c --删除空行 并且写入文件
sed -n '5,10p' /tmp/databook --打印5-10 行的内容
awk命令
和sed差不多也是处理文本的工具
awk -F: '\ <s18\ ' {print $1,$3} ' /etc/passwd --以冒号作为分隔符 打印s18开头的项目的第一第三个字段
awk -F '[ ,]' --设置多个分隔符
awk '$2~/[3]/' /tmp/passwd --打印/tmp/passwd第二列中以kK开头的行
awk '$4<2.5 ' /tmp/student_record --数学表达式
awk '$3=="CS" && $<3.5' /tmp/student_record --逻辑表达式匹配
正则表达式各种符号:https://tool.oschina.net/uploads/apidocs/jquery/regexp.html
重定位与管道符
重定向
重定向分输入重定向和输出重定向,即改变输入输出方向
正常来说,标准输入设备是键盘,标准输出设备是显示器
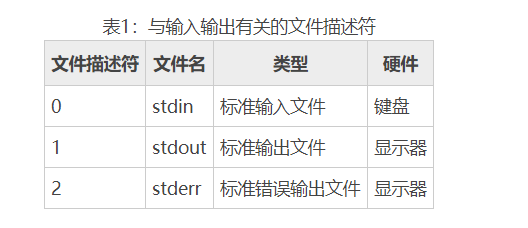
用法
输出重定向中'>'表示覆盖 ; ‘ >>’表示追加

也可以使用复合命令
command>file1 2>file2 :以覆盖的方式,命令的正确输出结果写入file1 把错误结果写入file2
(会首先创建两个文件file1 file2)
command >file 2>&1 :以覆盖的方式,命令的正确和错误输出结果都写入file
输入重定向
wc -l < /etc/passwd :将/etc/passwd作为输入执行wc -l(统计行数)
wc -l<<END :将使用特定的分界符‘END’作为命令输入的结束标志.
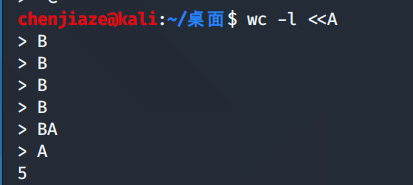
command< input_file>output_file : 将input_file作为输入文件执行command命令 输出到output_file
cate 2>/dev/null : 将输入的错误指令返回结果 丢入dev/null(类似垃圾桶)
管道命令(|)
管道命令可以将一条指令的执行结果做第二条指令的输入
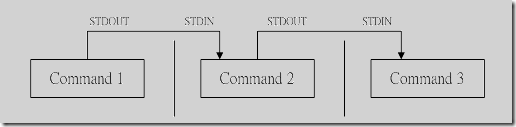
管道命令只处理前一个命令的正确输出,不处理错误输出

如图只有正确的命令执行结果会作为第二条指令的输入
错误的指令直接通过标准输出打印到屏幕
cat /etc/passddd /etc/passwd 2>/dev/null | grep -n 'root'
将输入错误结果丢入/dev/null 正确指令作为grep的输入执行
区别
管道触发两个子进程执行"|"两边的程序;而重定向是在一个进程内执行
linux进程管理
ps命令process status,常用ps -ef 、ps aux查看进程
两者区别:是Unix系统的两种风格,System V 和BSD风格,绝大多数linux都可以同时使用这两种方式的
ps命令
ps -ef
-e显示所有进程
-f full显示详细信息
| UID | PID | PPID | C | STIME | TTY | TIME | CMD |
|---|---|---|---|---|---|---|---|
| 用户 | 进程id | 父进程id | cpu百分比 | 启动时间 | 所在终端 | 进程占用cpu | 命令参数 |
| root | 1 | 0 | 0 | 06:50 | ? | 00:00:10 | /sbin/init |
| root | 40 | 1 | 0 | 12:33 | pts/0 | 00:00:03 | /java/ |
| ?b表示与终端无关 |
ps aux
a显示所有进程
u使用基于用户的信息输出格式,增加用户名、cpu内存占用率等信息
x同时显示没有控制终端的进程(TTY ?)
| USER | PID | %CPU | %MEM | VSZ | RSS | TTY | STAT | START | TIME | COMMAND |
|---|---|---|---|---|---|---|---|---|---|---|
| root | 1 | 0.0 | 1.2 | 19221 | 2989 | ? | S | 12:20 | 00:09 | /sbin/ini |
| 该进程使用的虚拟內存量(KB) | 该进程占用的固定內存量(KB) | 进程的状态 | 该进程实际使用CPU运行的时间 |
D //无法中断的休眠状态(通常 IO 的进程);
R //正在运行可中在队列中可过行的;
S //处于休眠状态;
T //停止或被追踪;
W //进入内存交换 (从内核2.6开始无效);
X //死掉的进程 (基本很少见);
Z //僵尸进程;
< //优先级高的进程
N //优先级较低的进程
L //有些页被锁进内存;
s //进程的领导者(在它之下有子进程);
l //多线程,克隆线程(使用 CLONE_THREAD, 类似 NPTL pthreads);
+ //位于后台的进程组;
ps -lax
| UID | PID | PPID | PRI | NI | WCHAN |
|---|---|---|---|---|---|
| 用户id | 进程id | 父进程id | 优先级 | nice值 | 进程正在等待的资源类型 |
| 越小越优先 | |||||
ps o
o参数可以指定ps输出的字段,并且利用某个字段排序
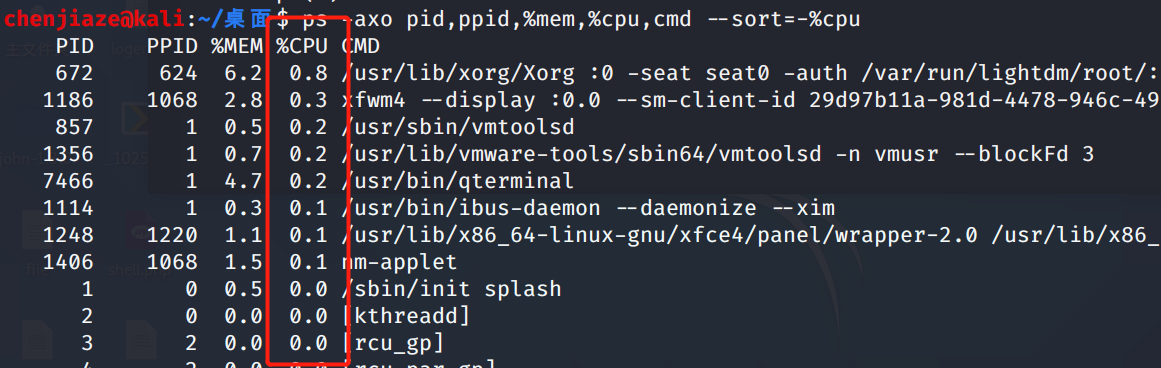
ps -axo pid,ppid,%mem,%cpu,cmd --sort=-%cpu
显示指定字段,用%cpu降序排序
nice命令
进程的nice值 在-20~19之间,nice越小优先级越大,默认nice为0
nice 可以给要启动的进程赋予 NI 值,但是不能修改已运行进程的 NI 值。
例如
nice -n -5 sudo service apache2 start
type命令
type命令用来显示指定命令的类型


linux前后台切换管理

“后台任务”的特点
继承当前session的标准输出和标准错误输出,因此,后台任务的所有输出依旧会在命令行下显示出来
不继承当前session的标准输入,因此,你将无法对该任务输入命令。如果它试图读取标准输入,就会暂停执行(halt)。
command &
将command指令放在后台执行
bg
将任务转为后台执行
bg%1 将进程号为1的进程转入后台执行
fg 将任务转为前台执行
bg%2 将进程号为2的进程转入前台执行
ctrl Z 停止当前进程,并放入后台
jobs 显示当前后台的进程
linux命令执行操作符
分号(;)可以用作串行执行多条语句 ,如:pwd;who|wc -l
单个与符号(&)cmd1&cmd2 用作两条指令并行执行
与符号(&&) cmd1&&cmd2 :当cmd1执行成功了,执行cmd2;若cmd1没有执行,则也不执行cmd2
或符号(||)cmd1&&cmd2 :当cmd1执行成功了,不执行cmd2;若cmd1没有执行,则执行cmd2
kill命令与信号量
用来中断一个进程,无论它是前台后台进程
kill -l 查看所有信号量
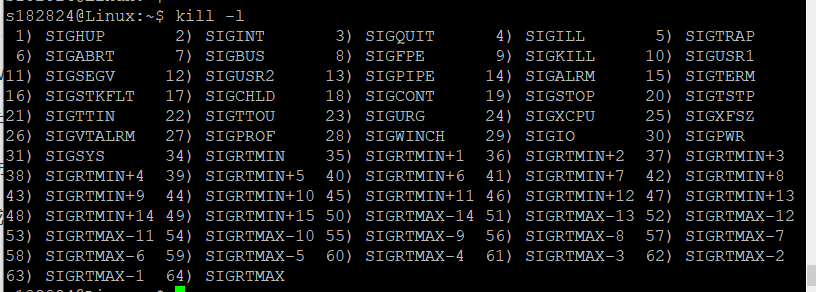
常用:1(HUP)重新加载进程、9(KILL)强制杀死进程、15(TERM)正常停止一个进程
kill -9 pid --强制终止进程
linux计划任务
Crontab命令
cron服务:指定时间周期性执行某个任务,依赖于系统后台crond进程
crontab -e 编辑crontab
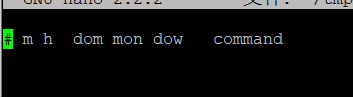
(分钟|小时|日|月|周|指令)
crontab -l 查看计划
at命令
at服务用于指定某个时间一次性执行某个任务,依赖于系统后台atd进程
‘at + 时间’进入at指令交互模式

输入指令ctrl D 退出
at -l / atq --查看设置的一次性计划任务
at -c +jobname --查看一次性计划任务具体内容(包含一些环境变量)
at -d --删除计划任务
命令格式
at 3:30pm
at 15:30
at 10:10 today
at now+2min ——2分钟后执行
at 4pm + 3 days ——3天以后的下午4点运行此job
at 10am Jul 31 ——在7月31日上午10点运行此job
at 1am tomorrow ——明天上午1点运行此job
at 4:00 2020-12-12 ——在2020-12-12日的凌晨4点执行
at -t 09201430 ——9月20日的下午2:30运行此job
at -t 202009201430 ——2020年的9月20日的下午2:30运行此job
# man at
at now + 5 minutes 任务在5分钟后运行
at now + 1 hour 任务在1小时后运行
at now + 3 days 任务在3天后运行
at now + 2 weeks 任务在两周后运行
shell编程
shell启动时,会用到三个文件?
登录模式(login_shell):先读/etc/profile 在(/.bash_profile、/.bash_login、~/profile)找到存在的第一个
在读取/etc/profile时也会调用一些别的配置文件
非登录模式(non-login_shell):仅读取.bashrc里的内容
通常shell脚本用.sh 结尾表示,在文件的开头写"#!/bin/bash"
.bash_history:记录前一次登录以前所执行的命令,这一次登录的命令记录缓存在内存中,当注销后写入.bash_history
内置命令和非内置命令
内置命令如cd、echo、exit等,这些命令由shell程序识别,通常在linux系统加载运行时shell就被加载并驻留在系统内存中。
其执行速度比外部命令快,因为内部命令shell不需要创建子进程。
非内置命令如ls,在系统加载时并不随系统一起被加载到内存中,而是在需要的时候才将其调入内存。
对于非内置命令,执行命令过程,会先fork一个子shell,由这个子shell去执行bash的代码
而执行内置命令相当于调用shell进程的一个函数,不创建新的进程
type命令
用于区别内置命令和非内置命令
type -t name :显示类型 如file 、alias、builtin

type -p name :当后面跟非内置命令时,显示完整文件名

type -a name : 显示出在PATH中 所有包含name的命令
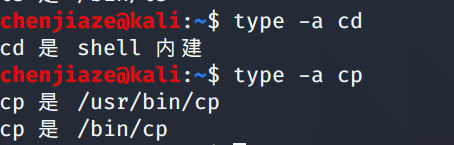
环境变量
foo="hello world" 设置一个局部变量 (只有当前shell有效)
// foo = ls -l 反单引号内写命令 可以将命令结果赋给环境变量
echo $foo 输出环境变量内容
set | grep foo 显示在用户的局部变量和用户环境变量表中的‘foo’行
env | grep foo显示在用户的用户环境变量表中的‘foo’行
export foo 把用户局部变量foo写入环境变量
set、env和export区别
env是环境变量的缩写,指列出所有环境变量
export也是列出环境变量 ,但相比起env,更详细;但它主要作用还是将自订变量转化为环境变量(环境变量可以在子Shell中沿用)
set 用来查看所有变量 包含环境变量和自定义变量
为什么环境变量的数据可以被子程序所引用呢?
- 当启动一个 shell,操作系统会分配一记忆区块给 shell 使用,此内存内之变量可让子程序取用
- 若在父程序利用 export 功能,可以让自订变量的内容写到上述的记忆区块当中(环境变量);
- 当载入另一个 shell 时 (亦即启动子程序,而离开原本的父程序了),子 shell 可以将父 shell 的环境变量所在的记忆区块导入自己的环境变量区块当中。
设置环境变量的方法
- /etc/profile中添加,所有用户有效
- /etc/.bash_profile 中添加,单一用户有效
- export 变量名 当前shell有效
- declear -x 变量名
source命令
source命令用来在当前bash环境下读取并执行文件 ,和. 的用法一样

