
Hadoop综合大作业
本次作业的要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339
前言:本次作业爬取猫眼电影 一出好戏的评论,整合成csv文件
作业要求
1.对CSV文件进行预处理生成无标题文本文件,将爬虫大作业产生的csv文件上传到HDFS
2.把hdfs中的文本文件最终导入到数据仓库Hive中,在Hive中查看并分析数据
3.用Hive对爬虫大作业产生的进行数据分析(10条以上的查询分析)
大数据分析
1.对CSV文件进行预处理生成无标题文本文件,将爬虫大作业产生的csv文件上传到HDFS
首先,我们需要在本地中创建一个/usr/local/bigdatacase/dataset文件夹,具体的步骤为:
① cd /usr/local
② sudo mkdir bigdatacase
③ cd bigdatacase/
④ sudo mkdir dataset
⑤ cd dataset/
如下图所示:
其次,我们把lagoupy.csv文件放到下载这个文件夹中,并使用命令把lagoupy.csv文件拷贝到我们刚刚所创建的文件夹中,具体步骤如下:
① sudo cp /home/chen/下载/lagoupy.csv /usr/local/bigdatacase/dataset/ #把lagoupy.csv文件拷到刚刚所创建的文件夹中
② head -5 lagoupy.csv #查看这个文件的前五行
如下图所示:

接着,启动hadoop,步骤如下:
① start-all.sh #启动hadoop
② jps #查看hadoop是否启动成功
如下图所示:
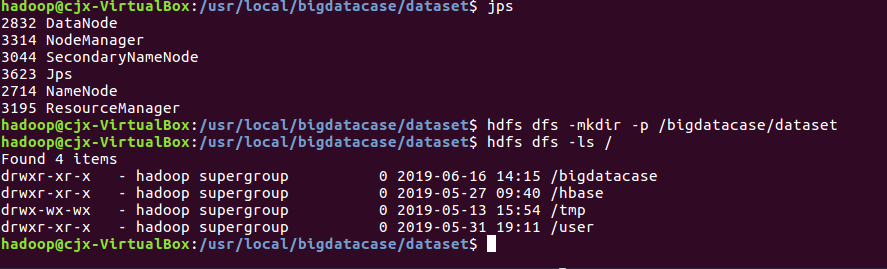
将爬虫大作业产生的csv文件上传到HDFS,再一次对csv文件进行处理,生成无标题文本文件
① hdfs dfs -mkdir -p /bigdatacase/dataset #在hdfs上新建/bigdatacase/dataset
② hdfs dfs -ls /
③ hdfs dfs -put ./lagoupy.csv /bigdatacase/dataset #把本地文件lagoupy.csv上传至hdfs中
④ hdfs dfs -ls /bigdatacase/dataset #查看
⑤ hdfs dfs -cat /bigdatacase/dataset/lagoupy.csv | head -5 #查看hdfs中lagoupy.csv的前五行
如下图所示:
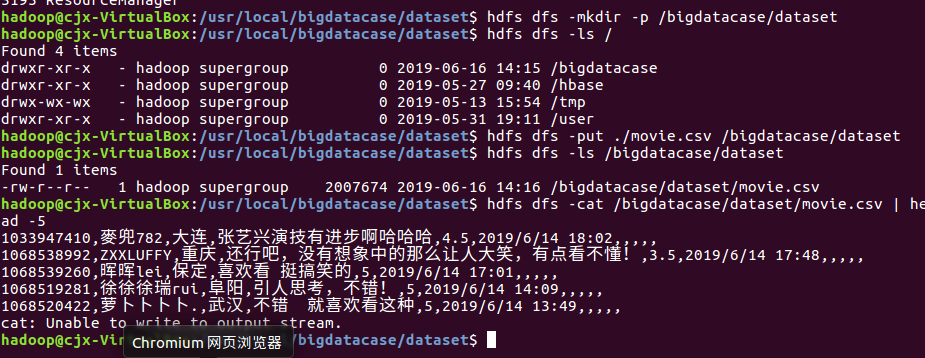
最后,我们把本地的文件上传至HDFS中,步骤如下:
① hdfs dfs -mkdir -p /bigdatacase/dataset #在hdfs上新建/bigdatacase/dataset
② hdfs dfs -ls /
③ hdfs dfs -put ./lagoupy.csv /bigdatacase/dataset #把本地文件lagoupy.csv上传至hdfs中
④ hdfs dfs -ls /bigdatacase/dataset #查看
⑤ hdfs dfs -cat /bigdatacase/dataset/lagoupy.csv | head -5 #查看hdfs中lagoupy.csv的前五行
如下图所示:
把hdfs中的文本文件最终导入到数据仓库Hive中
① service mysql start #启动mysql数据库
并且检测端口3306是否有给占用
② cd /usr/local/hive
③ ./bin/hive #启动hive
如下图所示

其次,把hdfs中的文本文件最终导入到数据仓库Hive中,并在Hive中查看并分析数据,具体步骤如下:
① create database dblab; -- 创建数据库dblab
② use dblab;
③ create external table cucn(aa string,number int,click int,title string,riqi string,text string) row format delimited fields terminated by '\t' stored as textfile location '/bigdatacase/dataset/'; -- 创建表cucn并把hdfs中/bigdatacase/dataset/目录下的数据加载到表中
④ select * from cucn limit 10; -- 查看cucn中前10行的数据
如下图所示:



用Hive对爬虫大作业产生的进行数据分析(10条以上的查询分析)
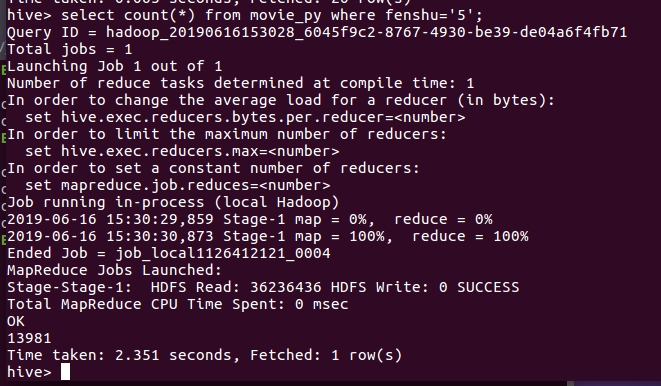
.查找评分为5
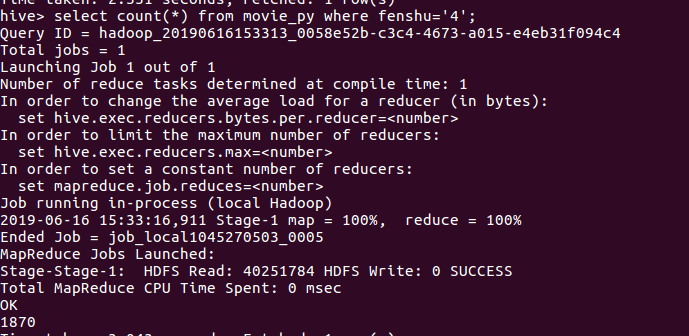
查找评分为4的的数量
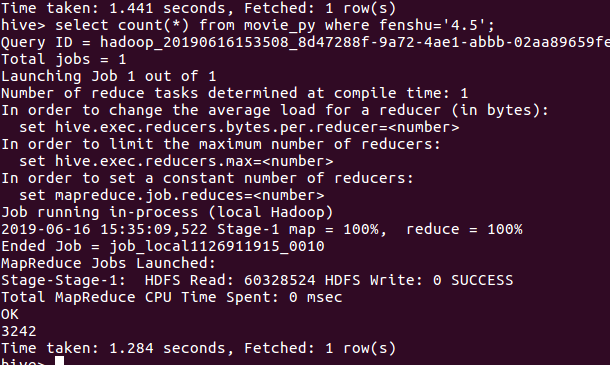
评分为4.5
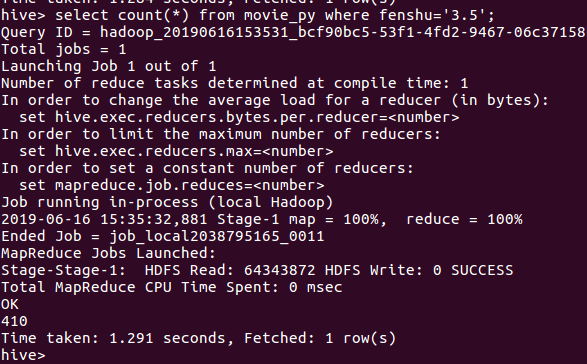
评分为3.5
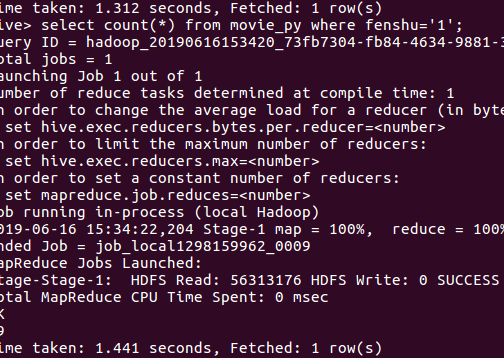
评分为3
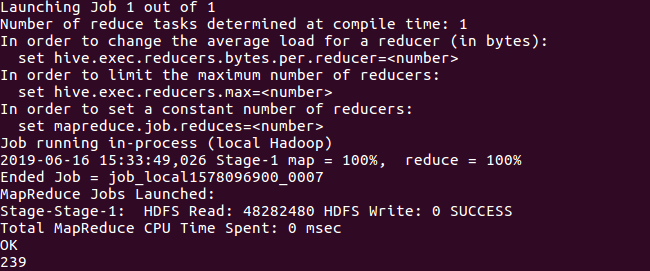
评分为2
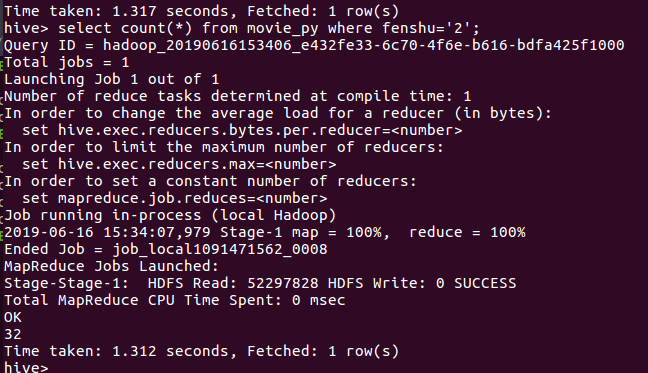
评分为1
结论:评分为5的数量(在爬取的20000+条数据中给出五分满分的有13000接近14000的数量,接近70%)可见观众评论对此非常之高 我们可以看到,在评分4.5以下不足20/1 符合大多数人们的审美口味和观影习惯,一个受众面宽广的电影。
查看平均评分
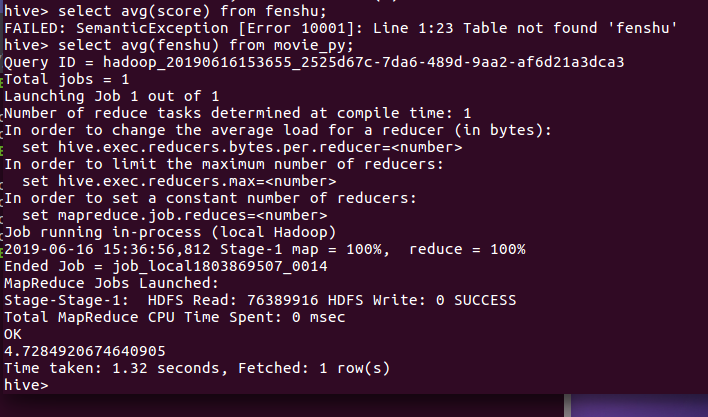
结论:平均评分高达4.7+ ,高出2018年暑期档平均分4.0(数据出自猫眼电影有)0.7之多,而一般来说,高于4.5,就代表不是能看,而是会给观众带来深度思考,引发现象的现象级电影。
寻找多少城市参加了评论


结论:总共有897个城市参加了,中国2800个县级市中,参评人数不足1/2,可见其实还是相当多人数没有把电影当作日常消遣行为,中国经济地区发展不平衡还比较严重。
查看评分大于4的城市排行

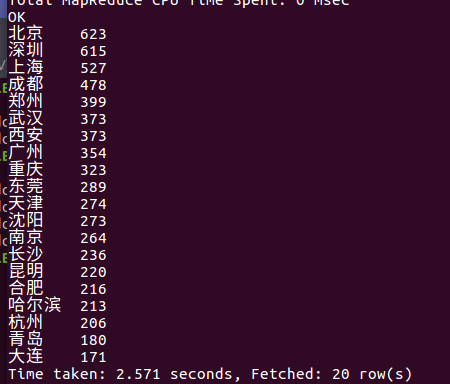
结论:结果显示,在排名中,还是北上广深等一线城市打分人数更多,人口基数更多。经济发展水平更高/
查看在上映之前就评论的人数
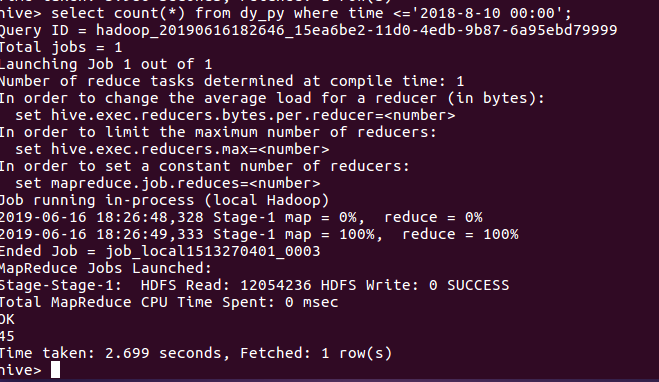
结论:电影播出之前,黄渤第一次做导演,演员卡司中,张艺兴被誉为流量明星代表。更多观众是抱着所谓的“极限挑战大电影去期待的”所以并没有多少人关心。而推出之后,口碑水涨船高,观众纷纷自来水
存在问题:1.电脑硬件原因,当数据量过大的时候,hive会出现以杀死现象。因此没有爬取全部的电影评论,而是截取了其中的两万条数据。和实际情况可能存在误差。
2.create表中,把分数设置为了,double型,导致会出现null,后来通过更改数据类型为string解决了这个问题。
3. 尽管可能座过数据清洗,但可能还会存在脏数据的情况。电脑允许的情况下可以通过增大数据量来减少这种误差。
心得体会:在本学期老师的细心指导下,完成了本次大作业的完成。学会了基本的python爬虫语法和相关的反爬虫策略。对于网络请求有了新的认识。了解了hadoop大数据平台的结构和基本操作方式。能够在实际过程中解决一些简单的问题。学会大数据分析的理论和相关操作。获得了相关经验和能力。感谢老师一个学期的辛勤付出

 浙公网安备 33010602011771号
浙公网安备 33010602011771号