对神经网络的初步理解
神经网络就是,比如说,我们输入一张图片,这张图片的话比如说是100X100像素值,比如有一层神经网络与之对应,其中里面的每个神经元都是一个数值(激活值)为(0,1)的个体,颜色越亮越接近1,颜色越暗越接近0,然后那层神经网络的每个神经元的不同的激活值就可以大概地组成一张图像,然后比如输出层要输出一个9的图像,那么它的上一层就可能会是一个圆圈和一竖,进而9便是它们的组合,再上一层便是好几个破碎的圆弧。
有输入层,输出层和隐藏层,那么怎么运作呢,比如说输入层像素756,第二层只有16个神经元,那么第二次那每个神经元都要和和第一层的756个神经元连接并得到所有激活值加权和,便有了756X16个权重和16个偏置值,为什么有偏置值,因为比如说,你希望加权和达到10,才能参与计算,不然,默认为0,那么这个偏置值就是一个门槛
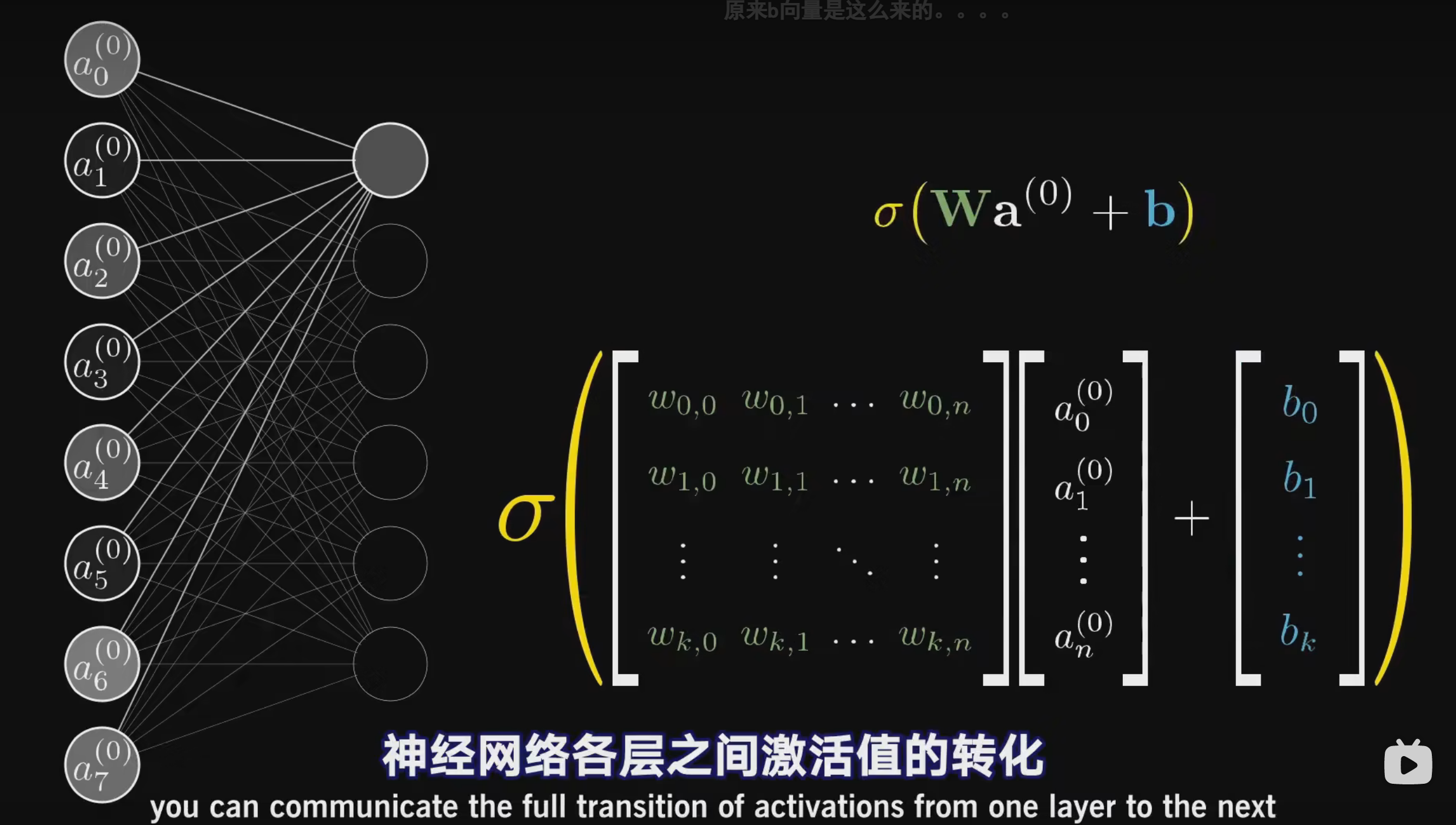
然后想要得到一个最优的输出,肯定是要调整好参数,就是偏置值和权重,然后代价函数是不是真实输出值和理想输出值的一个差距呢,然后输出值的参数是偏置值和权重
当我们训练神经网络时,我们需要计算每个权重参数(例如神经元之间连接的权重)对损失函数的贡献。反向传播算法就是一种有效的方法,可以计算每个权重参数对损失函数的贡献。
通俗来说,假设你是一个烘焙师傅,你要根据客人的口味调整蛋糕的甜度。你不知道要怎样调整才能达到最好的效果,所以你决定采用试错的方法。
你首先尝试制作一个偏甜的蛋糕,然后让客人品尝。如果客人认为蛋糕太甜了,你就需要对甜度进行调整,使得下一次制作的蛋糕更接近客人的口味。
现在,假设你已经找到了一个比较接近客人口味的蛋糕,你需要确定每个原材料对蛋糕口感的影响程度,这样你才能对蛋糕进行微调,最终得到完美的味道。
反向传播算法就是类似于上述的过程。首先,我们通过前向传播算法计算出当前神经网络的输出结果。然后,我们将输出结果与期望结果进行比较,并计算出损失函数的值。接着,我们使用反向传播算法来计算每个权重参数对损失函数的贡献。最后,我们将这些贡献加起来,就可以得到每个权重参数应该如何调整,以使得神经网络的输出更接近期望结果。什么叫把贡献加起来
是不是比如说,我觉得2更加重要,所以我调整权重,重点关注那些更亮的神经元的权重,然后再往前,希望前一层某神经元的激活值更大,我再去通过调整权重的方式
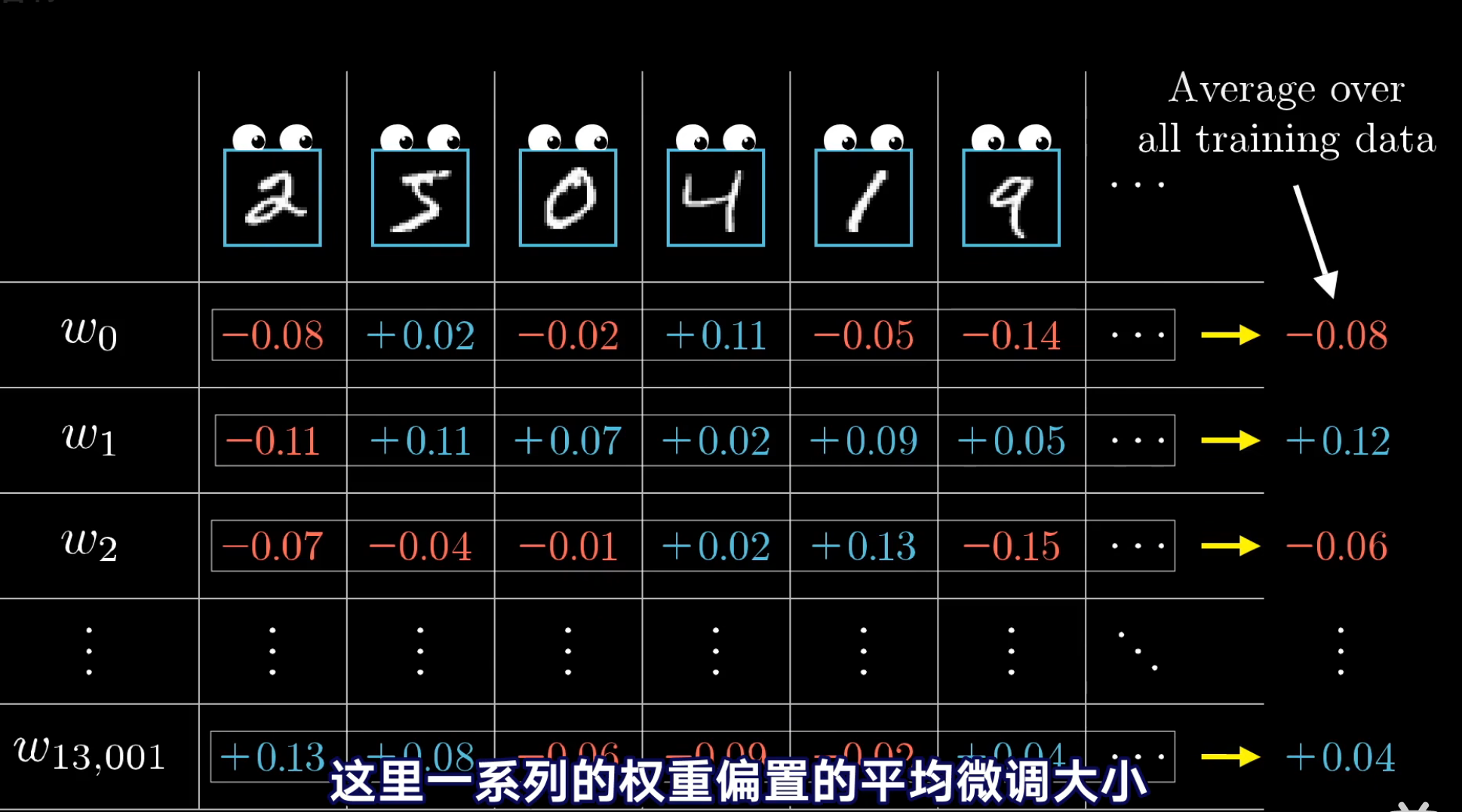

为什么要去求平均数,为什么这些平均数还可以成为梯度

 浙公网安备 33010602011771号
浙公网安备 33010602011771号