值迭代与策略迭代(有模型)

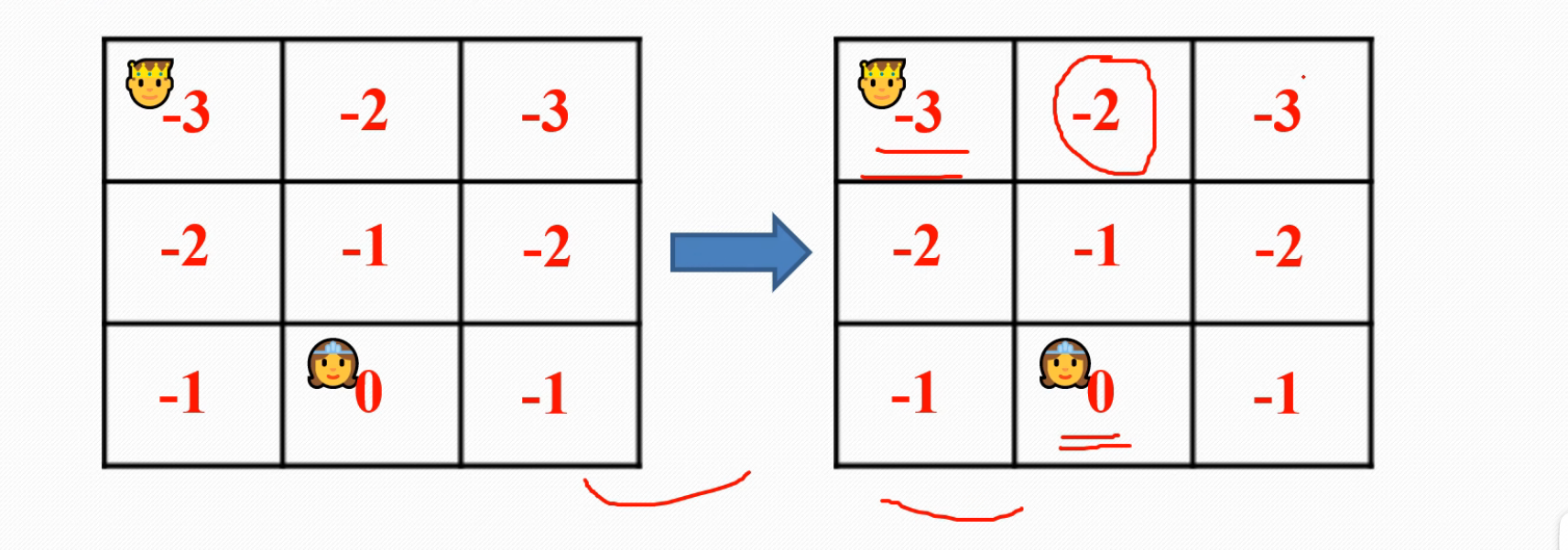
先说一下我初始理解,就是图片上面有三部曲,然后他是一个有模型的算法,然后假如说我让他训练100次就是,用python来表达就是 for episode in (100),这个就是最外面的那一层循环,然后每次episode,就是上面三部曲,但是第一步初始化环境是会根据上一个episode来变化的,从第一个episode开始讲,就是比如你vs全部都给你设成0,然后你王子每走一步,就会得到一个-1的reward,然后你得找到一个V'最大的点走过去,那个点的V‘其实是0,所以你目前的本状态的vs就得到了就是-1,然后你就写下孙悟空到此一游,把-1标上去,就类似于到此一游吧,然后你给本状态的v写好了之后,再跑去下一个状态,按照上面的方法一直走下去,可以理解成,你 for episode in (100)里面套着一个while循环,最终到达终点,然后此时此刻,你这个while循环走完之后捏,然后你会进入下一个episode,你会得到一张写满了“到此一游”(就是各个格子V值)的一张地图(来自上一个episode的while循环),让模型把它吃下去,重新初始化一个环境,与之前的全部都是零相对,这就是学习,如下图
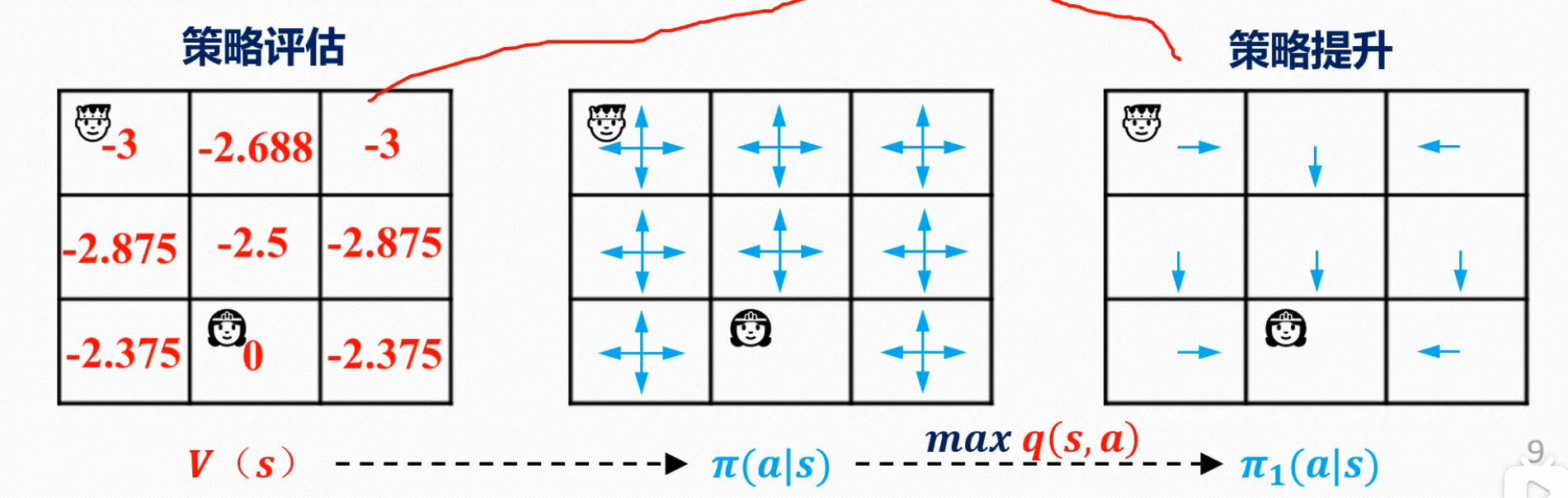
接下来是策略迭代然后策略迭代分为两部,分别是策略评估和策略更新
先是策略评估
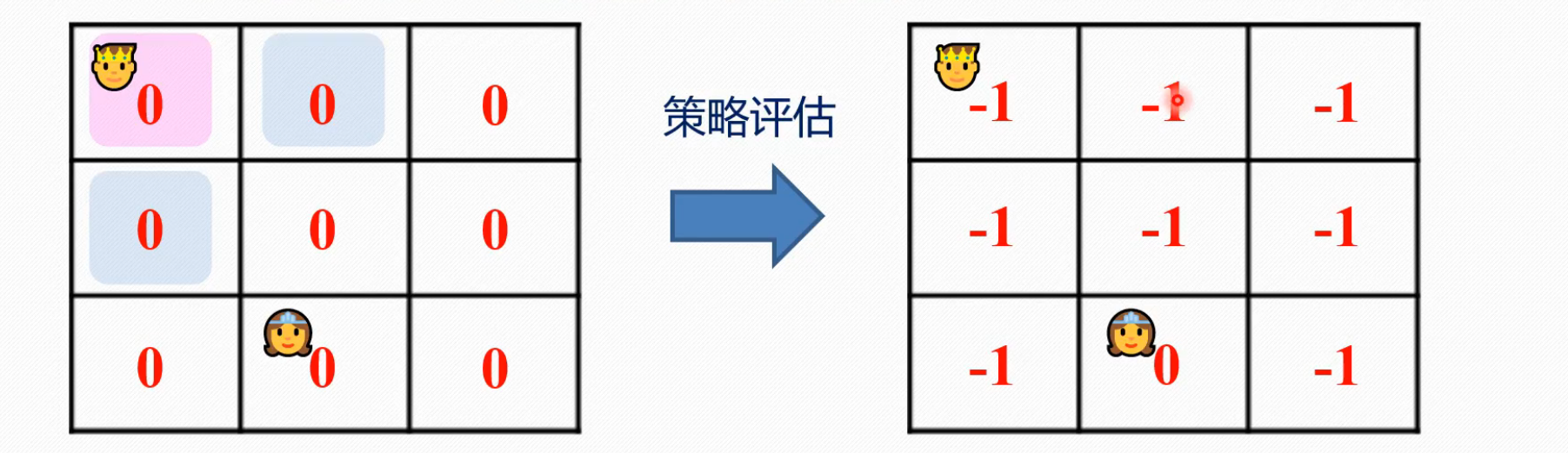

可以看到,在这一步里面,它的一个学习方式和值迭代是有些类似的,但是也有差别,差别在哪呢,第一个差别,就是我们设置了for episode in (100),每个episode里面有一个while循环,然后环境更新初始化放在了每个episode里面,while外面,但是,策略评估把环境初始化更新的方法放在了while的里面。第二个差别,值迭代,是会直接走向V'最大的一方,并依据其更新V,而策略评估,则会随缘走,加权走,并未开始贪婪,如图所示
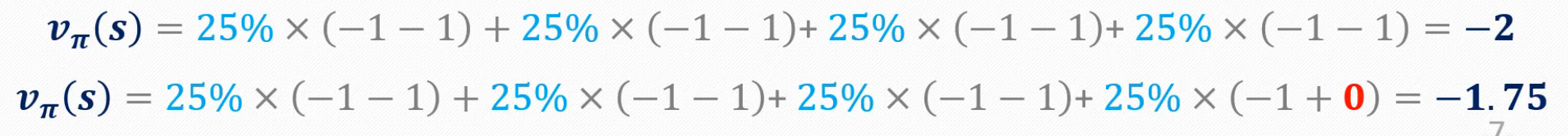
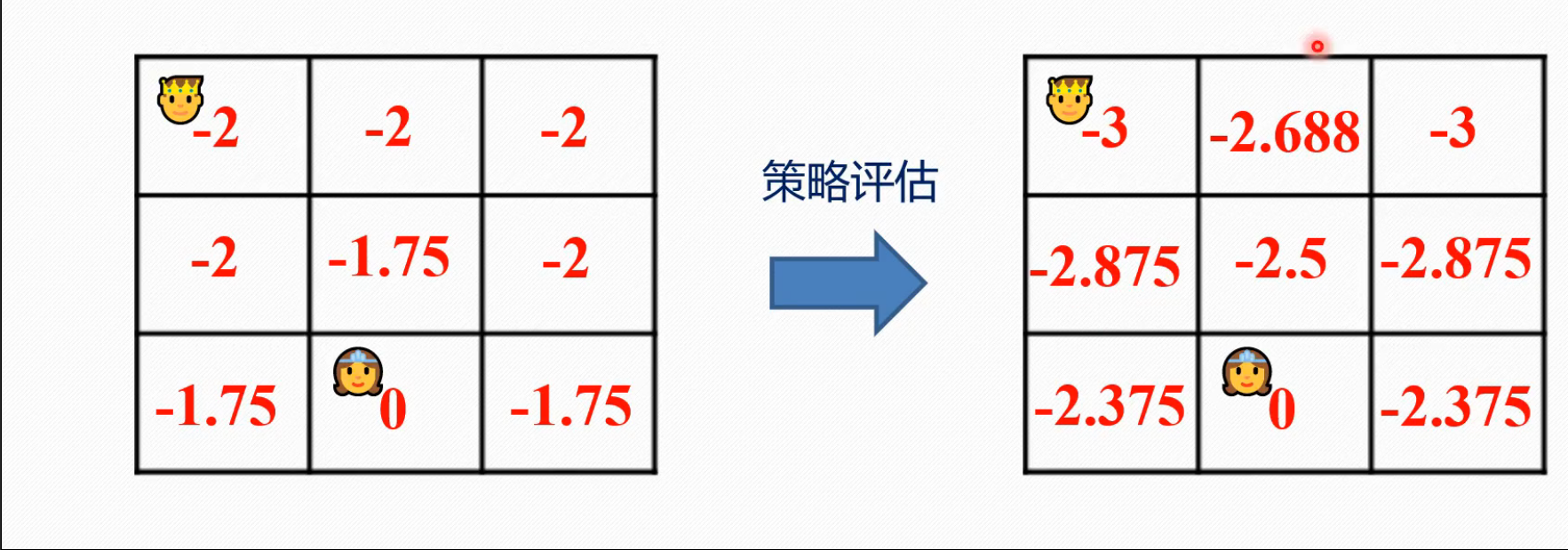
第二行,就是有一个括号里面的数值和仅为-1,并非-1,但也只得到了25%的加权,然后就按照此过程,在while里面一直更下去,直到收敛。。。。。。
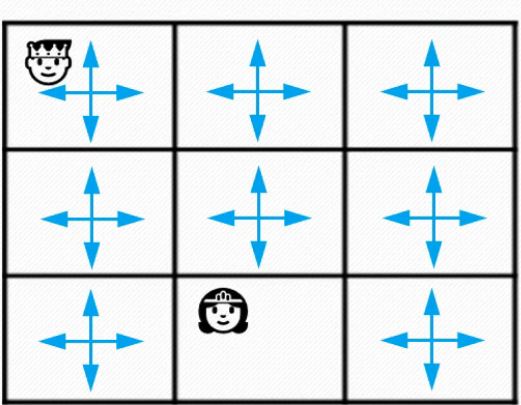
策略评估结束,最开始的均匀随机策略如图所示,就是要拷打他,锤炼他,改善他

 浙公网安备 33010602011771号
浙公网安备 33010602011771号