Storm容错和高可用
Daemon Fault Tolerance
Storm有一些不同的守护进程
- Nimbus负责调度workers
- supervisors负责运行和杀死workers
- log views负责访问日志
- UI负责显示集群的状态
What happens when a worker dies?
当一个worker死了以后,supervisor将会重启它。如果在启动过程中不断的失败,并且不能发送心跳给Nimbus,那么Nimbus将重新调度这个worker。
What happens when a node dies?
分配到这台机器上的任务会超时,然后Nimbus将这些任务分给其它机器来做。
What happens when Nimbus or Supervisor daemons die?
Nimbus和Supervisor守护进程被设计成快速失败的(当遇到不期望发生的情况时进程会自杀)并且是无状态的(所有状态都保持在zookeeper或者磁盘上)。
Nimbus和Supervisor必须运行在被监督的状态下(PS:必须对它们进行监控)。因此,如果Nimbus或者Supervisor守护进程死了以后,它们会被立即重启,就好像什么事都发生一样。
尤其是,Nimbus或者Supervisors的死亡对于worker进程没有任何影响(PS:如果它们死了,没有worker会受到影响)。这跟Hadoop不一样,Hadoop中如果JobTracker死了,所有job都会丢失。
Is Nimbus a single point of failure?
如果你失去了Nimbus节点,worker仍然会正常工作。另外,如果worker死了,supervisor会重启它。然而,如果没有Nimbus,在某些情况下wokers不能被重新分配到其它机器上(比如:运行worker的机器挂了)。
自从1.0.0版本以后,Storm的Nimbus是高可用的。
Highly Available Nimbus Design
Problem Statement:
目前Storm master又叫做nimbus,nimbus是一个运行在单个机器上的受监督的进程。大多数情况下,nimbus失败是短暂的,并且它会被supervisor重启。然而,有时候当磁盘或者网络失败发生的时候,nimbus就死了。在这种情况下topologies会正常运行,但是不能提交新的topologies了。为了解决这些问题,我们采用主备模式运行nimbus以此保证即使一个nimbus失败了备用的那个可以接替它。
Leader Election(选举):
nimbus服务器用下面的接口:
public interface ILeaderElector { /** * queue up for leadership lock. The call returns immediately and the caller * must check isLeader() to perform any leadership action. */ void addToLeaderLockQueue(); /** * Removes the caller from the leader lock queue. If the caller is leader * also releases the lock. */ void removeFromLeaderLockQueue(); /** * * @return true if the caller currently has the leader lock. */ boolean isLeader(); /** * * @return the current leader's address , throws exception if noone has has lock. */ InetSocketAddress getLeaderAddress(); /** * * @return list of current nimbus addresses, includes leader. */ List<InetSocketAddress> getAllNimbusAddresses(); }
在启动的时候,nimbus检查它本地是否有所有激活的topologies的code。一旦它得到这个检查的状态之后,它将调用addToLeaderLockQueue()方法。当一个nimbus被通知成为一个leader的时候,它会在假设自己是leadership角色之前再检查它是不是有所有的code。如果它缺少任何一个激活的topology的code,那么这个节点无法成为leadership角色,于是它将释放这个lock,在它为了获取leader lock之前它必须等待直到它获得了所有的code。
第一个实现是基于zookeeper的。如果zookeeper连接丢失或者被重置,造成的结果就是失去lock,这种实现关心的是isLeader()的状态变化。如果一个不是leader的nimbus收到一个请求,将抛异常。
下面的步骤描述了一个nimbus故障转移方案:假设,有4个topologies正在运行,3个nimbus结点,code-replication-factor = 2。我们假设“The leader nimbus has code for all topologies locally”在开始之前一直是true。非leader结点“nonleader-1”和“nonleader-2”各有2个topologies的code。假设Leader nimbus死了,硬盘坏了以至于没有恢复的可能。这个时候nonleader-1收到了zookeeper的通知表示它现在是新的leader,于是在接受成为leadership角色之前它检查它手上是不是有4个topologies(这些topologies在/storm/storms/目录下)的code。它意识到它只有2个topologies的code以至于它必须放弃lock,并且查看/storm/code-distributor/topologyId目录以找到从哪儿可以下载到它缺失的topologies。它发现从leader nimbus和nonleader-2那儿都可以。它尝试从这两个地方下载。nonleader-2也意识到它还缺2个topologies,并且按照之前相同的方法下载它所缺失的topologies。最终,它们当中至少有一个会获得所有的code,于是那个nimber将接收leadership成为新的leader。
下面的时序图描述的是leader选举和故障转移是如何进行的:
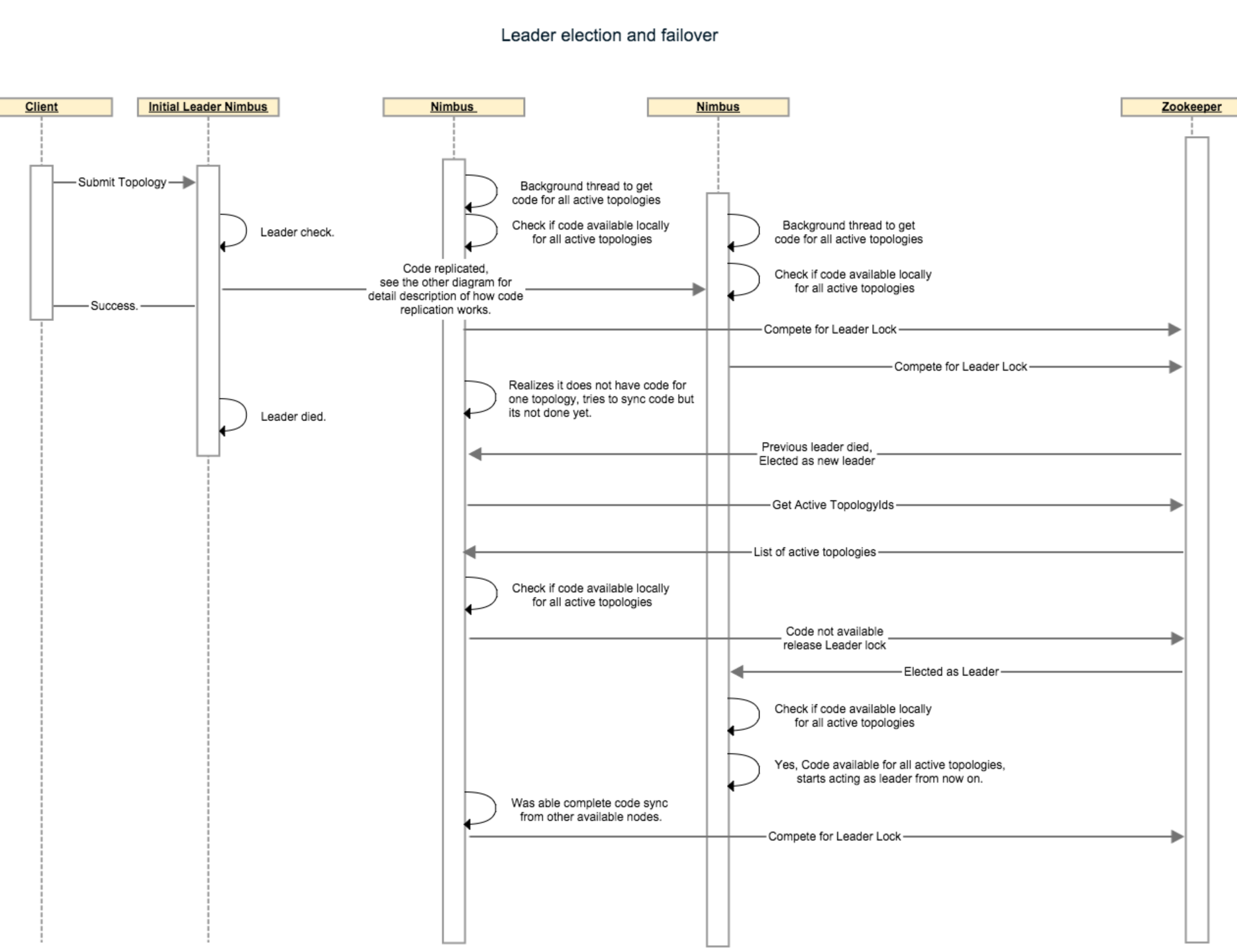
Nimbus state store:
目前,nimbus存储2种数据,一种是元数据(比如supervisor info、assignment info)被存储在zookeeper上,另一种是实际的topology配置和jars存储在nimbus所在的主机的本地磁盘上。
为了能够成功的故障转移从主切换到备,nimbus state/data需要被复制到所有的nimbus主机上或者需要被存储到一个分布式的存储设备上。正确的复制数据包含状态管理、一致性检查,并且即使不正确也很难测试出来。然而,许多storm用户不想额外的依赖像HDFS那种副本存储系统而且还想高可用。最终,我们想到用比特流协议来移动给定大小的代码分布,而且也是为了当supervisors数量很高的时候能获得更好的伸缩性。为了支持比特流和所有基于副本存储的文件系统,我们建议用下面的接口:
/** * Interface responsible to distribute code in the cluster. */ public interface ICodeDistributor { /** * Prepare this code distributor. * @param conf */ void prepare(Map conf); /** * This API will perform the actual upload of the code to the distributed implementation. * The API should return a Meta file which should have enough information for downloader * so it can download the code e.g. for bittorrent it will be a torrent file, in case of something * like HDFS or s3 it might have the actual directory or paths for files to be downloaded. * @param dirPath local directory where all the code to be distributed exists. * @param topologyId the topologyId for which the meta file needs to be created. * @return metaFile */ File upload(Path dirPath, String topologyId); /** * Given the topologyId and metafile, download the actual code and return the downloaded file's list. * @param topologyid * @param metafile * @param destDirPath the folder where all the files will be downloaded. * @return */ List<File> download(Path destDirPath, String topologyid, File metafile); /** * Given the topologyId, returns number of hosts where the code has been replicated. */ int getReplicationCount(String topologyId); /** * Performs the cleanup. * @param topologyid */ void cleanup(String topologyid); /** * Close this distributor. * @param conf */ void close(Map conf); }
为了支持复制,我们允许用户指定一个代码复制因子,这个复制因子表示在开始topologies之前代码必须被复制到多少个nimbus主机上。我们把zookeeper上维护的激活的topologies的列表作为我们的权力,表示这些topologies代码必须存在于nimbus主机上。任何一个没有在zookeeper上标记为active的所有的topologies代码的nimbus必须放弃它的lock,以至于其它的nimbus能够成为leader。在所有的nimbus主机上都有一个后台线程不断的尝试从其它的主机那里同步代码,所以只要还有一个种子主机上存在所有的active的topologies,那么最终至少有一个nimbus会变成leadership。
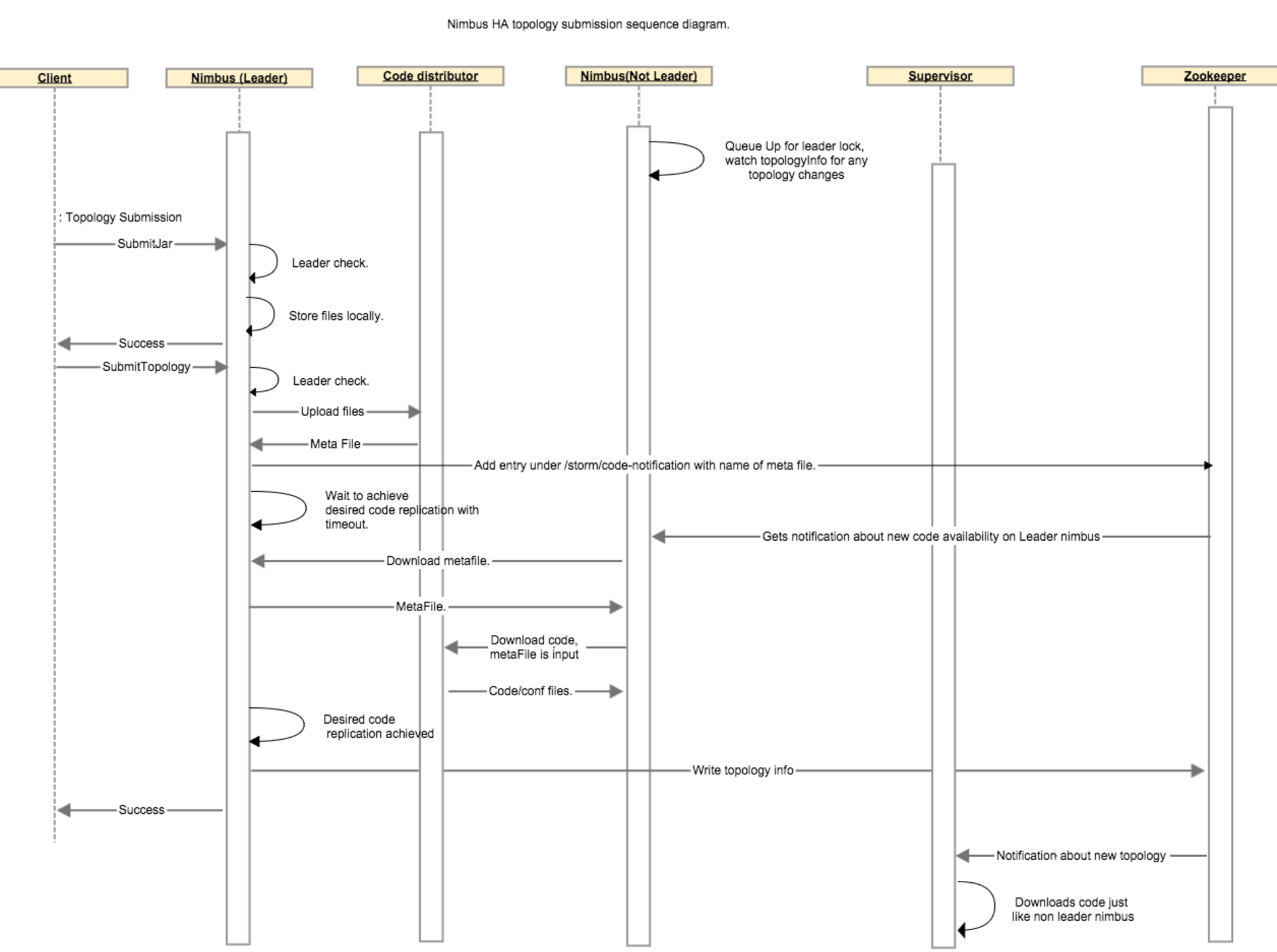
下面的步骤描述了对于一个topology在nimbus之间的代码复制过程:当客户端上传了一个jar文件,传就传了,什么也不会发生。而当客户端提交了一个topology的时候,leader nimbus调用code distributor(代码分发器)的upload函数,这将会在leader nimbus本地创建一个metafile文件。leader nimbus将在zookeeper上的/storm/code-distributor/topologyId目录下写一个新的入口,以此通知所有的非leader的nimbus它们应该下载这个新代码。在用户配置的超时时间内,客户端必须等待leader nimbus确保至少有N个非leader nimbus已经完成了代码复制。当一个非leader nimbus接收到关于这个新代码的通知的时候,它从leader nimbus那里下载这个meta file,并且通过调用代码分发器的download函数下载这个metafile所代表的真实的代码。一旦非leader nimbus完成了代码下载,这个非leader nimubs会向zk的 /storm/code-distributor/topologyId目录下写一个新的入口以此表明这是一个可以下载代码的metafile的位置,这样做是为了以防万一leader nimbus死了。然后leader nimbus继续做它该做的事情。
下面这个时序图描述了在代码分发过程中各个组件之间的通信:
本节重点
守护进程容错
1、如果worker死了,那么supervisor会重启它,如果还是失败,则由nimbus重新指定机器运行它
2、如果worker所在的机器挂了,那么这台机器上的所有未完成的任务将分配给其它机器去执行
3、如果nimbus或者supervisor死了,它们会被快速重启,就好像什么都没发生一样
4、nimbus和supervisor必须有监控,它们必须运行在监督之下
5、nimbus或者supervisor死了对worker进程没有影响
高可用的Nimbus设计
1、Nimbus HA采用的是主备模式,主节点挂掉以后从节点会接替主节点
2、Nimbus存储两种类型的数据
- 元数据,包括supervisor info, assignment info(任务分配的信息)。这些信息保存在zookeeper中。
- 实际的topology配置和jars存储在nimbus主机的本地磁盘上
3、为了能够更好的故障转移,这些状态以及数据必须被复制到所有的nimbus上或者存到一个分布式的存储上。Storm内部使用的比特流协议来复制的。
4、用户自定义副本因子来决定代码必须被复制到多少个nimbus上
5、每个nimbus都有一个后台线程不断的尝试从其它主机那里同步代码
6、复制的流程如下:
(1)当leader nimbus收到一个客户端提交的topology时,它调用代码分发器的upload方法,这将在本地创建一个metafile来保存topology的元数据,紧接着zookeeper的/storm/code-distributor/topologyId目录下写一个新的数据,以此通知所有的nonleader nimbus它们应该下载这个新代码;
(2)客户端在提交这个topology以后一直处于等待状态,直到leader nimbus确保至少有N个non leader nimbus已经完成了代码复制,或者超时返回;
(3)当一个non leader nimbus收到这样一个通知以后,首先从leader nimbus那里下载metafile,然后下载真实的代码,这些都完成以后它会往/storm/code-distributor/topologyId再写一个入口以表明从它那里可以下载代码的metafile
7、leader选举是基于zookeeper实现的
8、选举的过程如下:
(1)nimbus在启动的时候检查自己本地是不是有所有的在zookeeper上标记为active状态的topologies的代码,如果没有则不能入队,有的话就调用addToLeaderLockQueue()函数以求获得leadership lock;
(2)当一个non leader nimbus被通知它可以成为新的leader的时候,这个nimbus会再次检查它本地是不是有所有的topologies的代码,如果是不是,那么它必须放弃lock,为了再次入队获得leadership lock它必须等待直到它收集到所有的代码;如果是的话,那么它将成为leader;
参考
http://storm.apache.org/releases/1.1.1/Daemon-Fault-Tolerance.html
http://storm.apache.org/releases/1.1.1/nimbus-ha-design.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号