Storm WordCount

特别注意,在本地运行的时候应该去掉<scope>provided</scope>,否则会报java.lang.ClassNotFoundException: org.apache.storm.topology.IRichSpout
集群环境中运行的时候应该加上
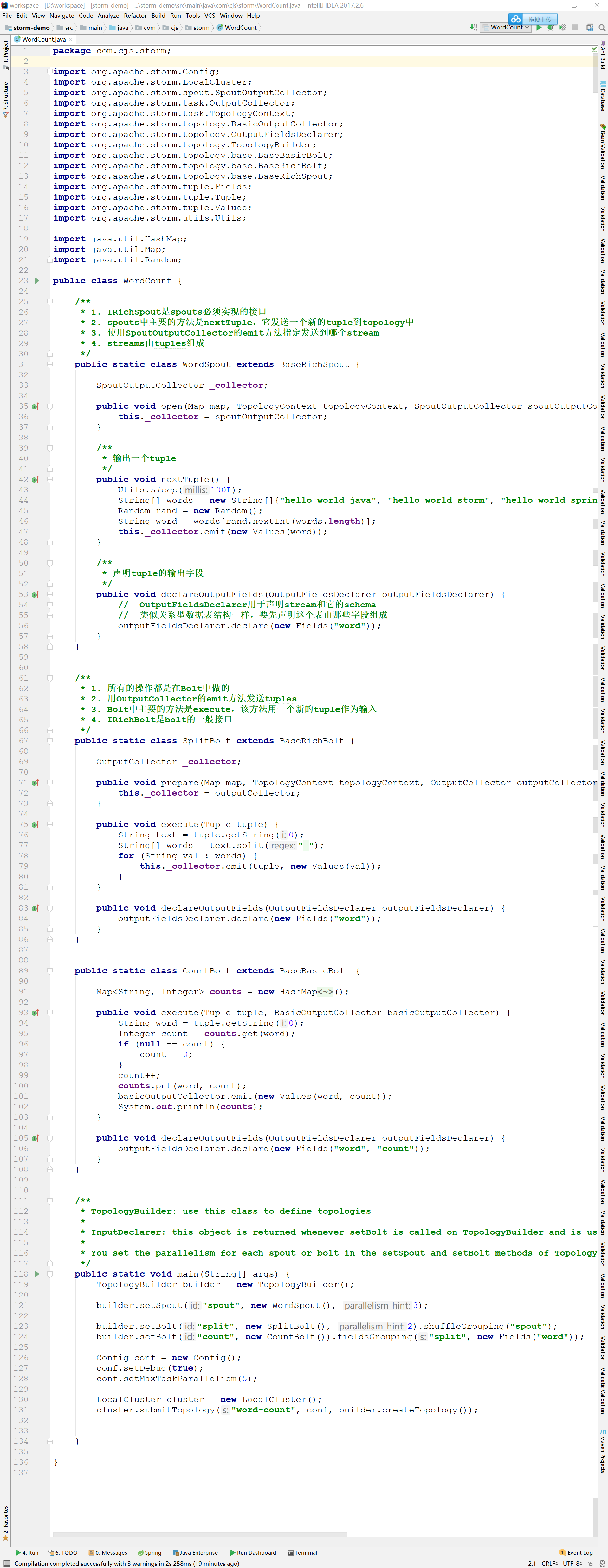
在这个例子中,有一个spout,两个bolt,也就是说这个任务分为两步。spout随机发送一句话到stream,而SplitBolt负责将其分隔成一个一个单词,CountBolt负责计数。运行的时候,spout的并行数是3,SplitBolt的并行数是2,也就是说相当于有3个spout,2个SplitBolt,1个CountBolt。
运行的时候,直接右键运行main方法即可,输出结果大概是这样的:
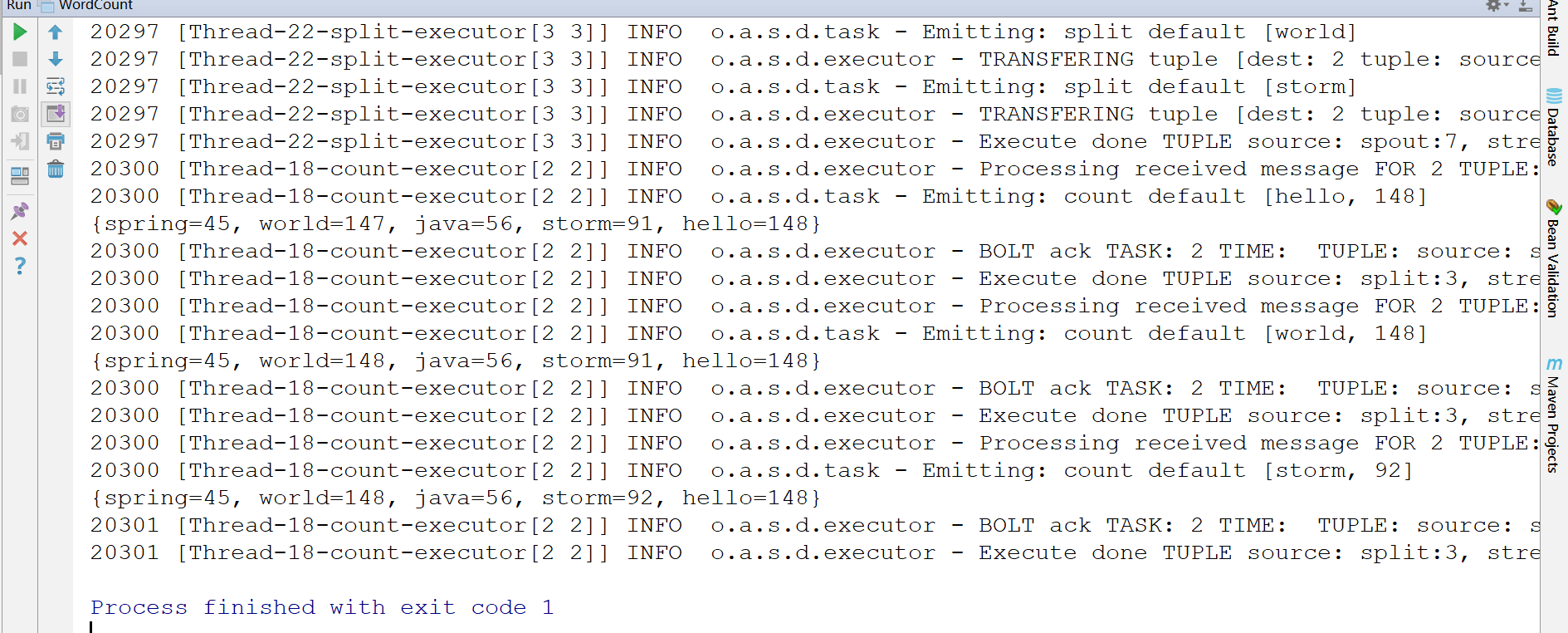
简单的对比hadoop,可以这样理解storm:
Storm中的Topology相当于Hadoop中的Job
Storm中的Spout相当于Hadoop中的输入文件,而Bolt相当于MapReduce任务
Storm中的每一个处理是一个Bolt再到下一个Bolt,而Hadoop中是一个MapReduce任务再下一个MapReduce
如果一个任务需要分多步完成的话,那么在Storm中每一步就相当于一个Bolt,而在Hadoop中每一步相当于一个MapReduce任务

 浙公网安备 33010602011771号
浙公网安备 33010602011771号