HBase简介
参考 http://hbase.apache.org/book.html#_architecture
Architecture
65. Overview
65.1. NoSQL?
HBase是一种"NoSQL"数据库。“NoSQL”一般指的是非关系型数据库,我们知道,关系型数据库支持SQL,也就是说HBase不支持SQL。非关系型数据库有许多种,BerkeleyDB是一种本地非关系型数据库,然而,HBase是分布式数据库。从技术上来讲,HBase更像是“Data Store”,而不是“Data Base”,因为它缺少许多关系型数据库的特性,比如:列类型、辅助索引、触发器、查询语言等等。(PS:意思是,从技术的角度讲,HBase更像一个数据存储,而不像数据库)
HBase集群扩展通过增加RegionServer来实现。如果一个集群从10扩展到20个RegionServer,那么,不仅仅是存储容量增加一倍,连处理能力也会增加一倍。对于关系型数据库而言,也可以用scale做到这样,但是需要指出的是,这需要特别的硬件和存储设备。HBase特性如下:
- 强一致性读写:HBase不是一个“最终一致性”的数据存储。这使得它更适合高速度的聚集任务。
- 自动分区:HBase的表通过region被分布在集群中,而region是自动拆分并重新分布数据行的。
- 自动RegionServer容灾
- Hadoop/HDFS集成:HBase支持HDFS作为它的分布式文件系统
- MapReduce:HBase支持通过MapReduce基于HBase作为数据源的大量的并行处理
- Java Client API:HBase支持通过Java API编程的方式来访问
- Thrift/REST API:HBase也支持Thrift和REST这样的非Java的客户端
- Block Cache and Bloom Filters
- Operational Management:HBase提供web界面
65.2. When Should I Use HBase?
并不是所有的问题都适合用HBase
第一、确保你有足够的数据。如果你有数以亿计的数据行,那么HBase是一个不错的选择。如果你只有数千或者百万的数据,那么使用传统的关系型数据库可能更好,因为事实上你的这些数据可能只需要一个或者两个节点就能处理得完,这样的话集群中的其它的节点就处于空闲状态。
第二、确保你不需要用到关系型数据库的特性(比如:固定类型的列、辅助索引、事务、查询语言等等)。基于关系型数据库构建的应用不能通过简单的改变JDBC驱动来传输到HBase中。从RDBMS到HBase是完全相反的两套设计。
第三、确保你有足够的硬件。因为当DataNode数量小于5的时候HDFS将不能正常工作了。
65.3. What Is The Difference Between HBase and Hadoop/HDFS?
HDFS是一个分布式的文件系统,适合存储大文件,但它不能提供快速的个性化的在文件中查找。HBase是构建于HDFS基础之上的,并且它支持对大表的中的记录进行快速查找和更新。HBase内部将数据存放在HDFS中被索引的“StoreFiles”上以供快速查找。
69. Master
HMaster是Master Server的一个实现。Master Server负责监视集群中所有的RegionServer实例,并且它也是所有元数据改变的一个对外接口。在分布式集群中,典型的Master运行在NameNode那台机器上。
69.3. Interface
HMasterInterface接口是操作元数据的主要接口,提供以下操作:
- Table (createTable, modifyTable, removeTable, enable, disable)
- ColumnFamily (addColumn, modifyColumn, removeColumn)
- Region (move, assign, unassign)
70. RegionServer
HRegionServer是RegionServer的实现,它负责服务并管理regions。在分布式集群中,一个RegionServer通常运行在一个DataNode上。
70.1. Interface
HRegionRegionInterface既包含数据的操作也包含region维护的操作
- Data (get, put, delete, next, etc.)
- Region (splitRegion, compactRegion, etc.)
70.5. RegionServer Splitting Implementation
region server处理写请求,它们被累积在内存中一个叫memstore的地方。一旦memstore文件满了,内容将被写到磁盘上作为store file。这个事件叫做memstore flush。随着store file的不断累积,RegionServer将合并它们成大文件,以减少store file的数量。在每次刷新或者合并以后,region中数据的数量会发生改变。RegionServer根据切分策略来查看是否region太大了或者应该被切分。
逻辑上,region切分的操作很简单。找一个合适的位置,将region中的数据切分成两个新的region。然而,这个处理的过程并不简单。当切分发生的时候,数据并不是立刻被重写到这个心创建的女儿region上。
71. Regions

73. HDFS

Data Model
在HBase中,数据被存储在表中,有行和列。这些术语和关系型数据有一些重叠,当然这不是一个很好的类比,但是它对我们思考HBase的表示一个多维的map很有帮助。
Table
由多行组成
Row
HBase中的行由一个row key和一个或多个列组成。Rows在存储的时候按照row key的字典序存储。正因为如此,row key的设计就显得非常重要。基于这一点,相关连的行相互之间存在附近。通常,row key是一个网站的域名。如果你的row key是域名,你应该以倒置的方式存储它们(比如:org.apache.www,org.apache.mail,org.apache.jira等等)。这样的话,所有的apache域名在表中是相近的位置,而不是被子域名的第一部分分开。
Column
HBase中的列由一个列簇和一个列修饰符组成,它们之间用冒号分隔(:)
Column Family
列簇由一系列的列和它们的值组成,这是基于性能考虑的。每一个列簇都有一系列的存储属性,比如:是否它们的值应该被缓存到内存中,它们的数据怎样被压缩,它们的row key怎样被编码,等等。表中的每一行都有相同的列簇,即使一个给定的行在给定的列簇上没有存储任何数据。
Column Qualifier
一个列修饰符被添加到列簇中为了给指定的数据片段提供索引。假设,给定的列簇是content,那么,一个列修饰符可能是content:html,其它的还有可能是content:pdf。虽然,列簇在表创建的时候就固定了,但是列修饰符是不确定的,而且不同的行可能有不通的列修饰符。
Cell

Timestamp
一个timestamp被写在每个value的旁边,它是一个value的版本修饰符。默认的,timestamp代表数据被RegionServer写入的时间,你也可以在写数据的时候指定一个不同的timestamp值
20. Conceptual View

在这个例子中,有一个表叫“webtable”,它包含两行数据(com.cnn.www和com.example.www)和三个列簇(contents,anchor,people)。对于第一行(com.cnn.www),anchor包含两列(anchor:cssnsi.com,anchor:my.look.ca),contents包含一列(contents:html)。row key为“com.cnn.www”的行有5个版本,而row key为“com.example.www”的行有1个版本。contents:html列包含整个网站的HTML。
在这个表格中的空的单元格并不占用空间
下图是一个模拟,目的在于解释说明上面我们所说的,便于我们理解:

21. Physical View
虽然,在概念上,表看起来像是一行一行的,但物理上,它们是按照列簇被存储的。一个新的列修饰符可以在任意时刻被添加到列簇中。
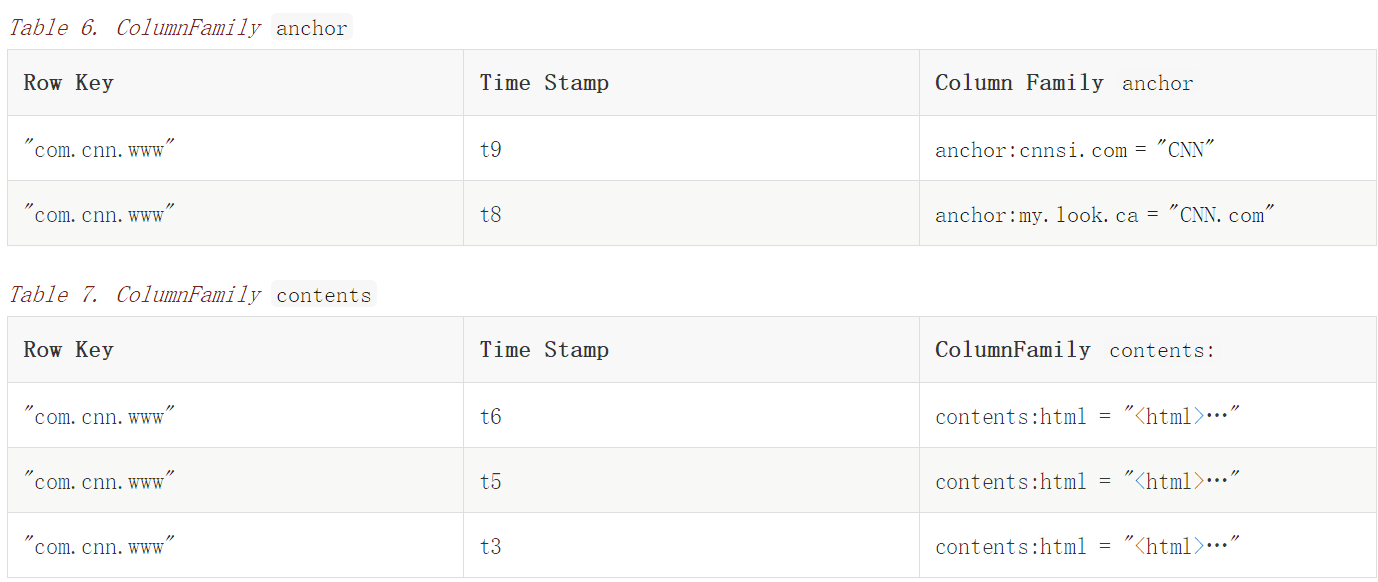
在前面的概念视图中的空的单元格是不被存储的。因此,请求contents:html列并且timestamp为t8将返回没有值。然而,如果不指定timestamp,那么某个列的大部分值都会被返回。如果指定多个版本,只有找到的第一个会被返回,因为数据是按照timestamp降序存储的。
22. Namespace
一个命名空间是表的一个逻辑分组
23. Table
24. Row
行按照row key字典升序存储
25. Column Family
Columns in Apache HBase are grouped into column families.
列簇中所有的列成员都有相同的前缀。例如,列courses:history和courses:math都是courses这个列簇的成员。用冒号分隔列簇和列修饰符。列簇前缀必须由可以打印输出的字符组成。列修饰符可以由任意字节组成。列簇必须在表被定义的时候就声明好,因此列就不需要在表创建的时候定义了,并且可以随时新增。
物理上,所有的列簇成员被存储在一起。
26. Cells
A {row, column, version} tuple exactly specifies a cell in HBase.
27. Data Model Operations
数据模型有4个主要操作,分别是Get、Put、Scan和Delete。这些操作是应用在表上的。
27.1. Get
返回指定行的属性
27.2. Put
添加新的行到表中,或者更新已经存在的行
27.3. Scans
扫描特定属性的多行
27.4. Delete
从表中删除一行
28. Versions
在HBase中,{row,column,version}可以确定一个单元格。当行和列被压缩成字节的时候,版本用long类型指定。在HBase中,版本以降序存储,所以,最近的值总是最先被发现。
29. Sort Order
对于所有的数据模型操作,HBase以数据被存储时的顺序返回。首先按行排序,其次按列簇,再其次按列修饰符,最后是timestamp。(PS:前是三个是字典升序,最后一个timestamp是降序)
30. Column Metadata
不存储列的元数据,因此,HBase可以支持每一行有许多列,行与行之间可以有多种不同的列。
31. Joins
HBase不直接join操作,至少不支持关系型数据库那种join。在HBase中,读取数据通过Get和Scan。
33. Schema Creation
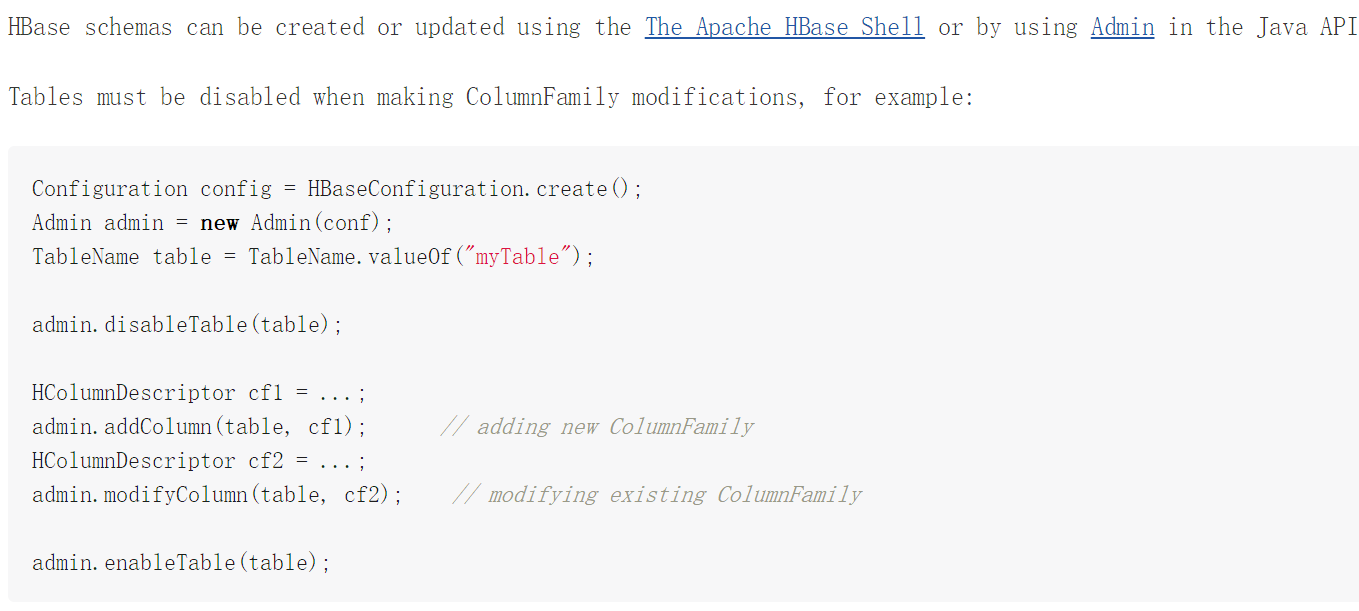
34. Table Schema Rules Of Thumb
- regions的大小在10~50GB之间
- cells的大小不超过10MB
- 典型的,每个表的列簇在1~3个之间。HBase的表不应该被设计成模仿关系型数据库的表
- 一个有1~2个列簇的表所拥有的regions大约在50~100个左右
- 保持你的列簇名字尽可能的短
50. HBase as a MapReduce Job Data Source and Data Sink
HBase可以作为MapReduce作业的数据源。对于读写HBase的MapReduce作业,建议使用TableMapper和TableReducer。
如果你运行HBase作为数据源的MapReduce作业,你需要在配置文件中指定表和列名。
当你从HBase读取数据的时候,TableInputFormat请求regions的列表并且作为一个map。
54. HBase MapReduce Examples

 浙公网安备 33010602011771号
浙公网安备 33010602011771号