MySQL 窗口函数
1. 窗口函数概念和语法
窗口函数对一组查询行执行类似聚合的操作。然而,聚合操作将查询行分组到单个结果行,而窗口函数为每个查询行产生一个结果:
- 函数求值发生的行称为当前行
- 与发生函数求值的当前行相关的查询行组成了当前行的窗口
相比之下,窗口操作不会将一组查询行折叠到单个输出行。相反,它们为每一行生成一个结果。
SELECT
manufacturer, product, profit,
SUM(profit) OVER() AS total_profit,
SUM(profit) OVER(PARTITION BY manufacturer) AS manufacturer_profit
FROM sales;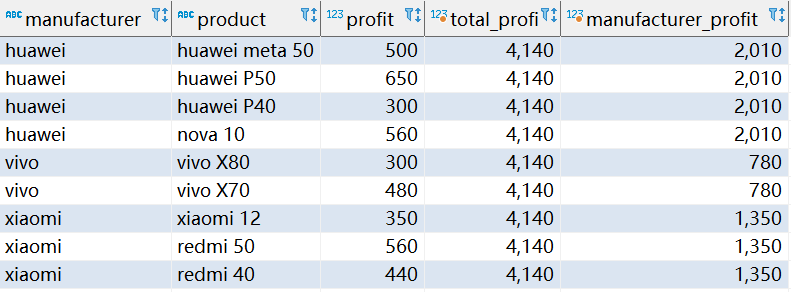
查询中的每个窗口操作都通过包含一个 OVER 子句来表示,该子句指定如何将查询行划分为组以供窗口函数处理:
- 第一个 OVER 子句是空的,它将整个查询行集视为一个分区。窗口函数因此产生一个全局和,但对每一行都这样做。
- 第二个 OVER 子句按 manufacturer 划分行,产生每个分区(每个manufacturer)的总和。该函数为每个分区行生成此总和。
窗口函数只允许在查询列表和 ORDER BY 子句中使用。
查询结果行由 FROM 子句确定,在 WHERE、GROUP BY 和 HAVING 处理之后,窗口执行发生在 ORDER BY、LIMIT 和 SELECT DISTINCT 之前。
OVER子句被允许用于许多聚合函数,因此,这些聚合函数可以用作窗口函数或非窗口函数,具体取决于是否存在 OVER 子句:
AVG()
BIT_AND()
BIT_OR()
BIT_XOR()
COUNT()
JSON_ARRAYAGG()
JSON_OBJECTAGG()
MAX()
MIN()
STDDEV_POP(), STDDEV(), STD()
STDDEV_SAMP()
SUM()
VAR_POP(), VARIANCE()
VAR_SAMP()MySQL还支持只能作为窗口函数使用的非聚合函数。对于这些,OVER子句是必须的
CUME_DIST()
DENSE_RANK()
FIRST_VALUE()
LAG()
LAST_VALUE()
LEAD()
NTH_VALUE()
NTILE()
PERCENT_RANK()
RANK()
ROW_NUMBER()ROW_NUMBER() 它生成其分区内每一行的行号。默认情况下,分区行是无序的,行编号是不确定的。若要对分区行进行排序,请在窗口定义中包含一个ORDER BY子句。下面的示例中,查询使用无序分区和有序分区(row_num1和row_num2列)来说明省略和包含ORDER BY之间的区别:
SELECT
manufacturer, product, profit,
ROW_NUMBER() OVER(PARTITION BY manufacturer) AS row_num1,
ROW_NUMBER() OVER(PARTITION BY manufacturer ORDER BY profit) AS row_num2
FROM sales;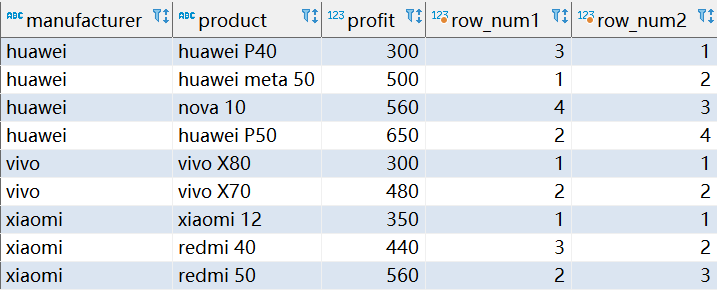
如前所述,要使用窗口函数(或将聚合函数视为窗口函数),需要在函数调用后包含OVER子句。OVER子句有两种形式:
over_clause:
{OVER (window_spec) | OVER window_name}这两种形式都定义了窗口函数应该如何处理查询行。它们的区别在于窗口是直接在OVER子句中定义的,还是通过对查询中其他地方定义的命名窗口的引用提供的:
- 在第一种情况下,窗口规范直接出现在 OVER 子句中的括号之间。
- 在第二种情况下,window_name 是由查询中其他地方的 WINDOW 子句定义的窗口规范的名称。
对于 OVER (window_spec) 语法,窗口规范有几个部分,都是可选的:
window_spec:
[window_name] [partition_clause] [order_clause] [frame_clause]如果 OVER() 为空,则窗口由所有查询行组成,窗口函数使用所有行计算结果。否则,括号中的子句决定了使用哪些查询行来计算函数结果,以及它们是如何分区和排序的:
- window_name: 由查询中其他地方的window子句定义的窗口的名称。如果window_name单独出现在OVER子句中,则它完全定义了窗口。如果分区、排序或分帧子句也给出了,它们会修改被命名窗口的解释。
- partition_clause: PARTITION BY 子句指示如何将查询行分组。给定行的窗口函数结果基于包含该行的分区的行。如果省略 PARTITION BY,则有一个由所有查询行组成的分区。
partition_clause: PARTITION BY expr [, expr] ... - order_clause: ORDER BY 子句指示如何对每个分区中的行进行排序。根据 ORDER BY 子句相等的分区行被视为对等。如果省略 ORDER BY,则分区行是无序的,没有隐含的处理顺序,并且所有分区行都是对等的。
order_clause: ORDER BY expr [ASC|DESC] [, expr [ASC|DESC]] ...
每个ORDER BY表达式后面可以有选择地跟着ASC或DESC来表示排序方向。NULL 值首先进行升序排序,最后进行降序排序。
窗口定义中的 ORDER BY 适用于各个分区。要将结果集作为一个整体进行排序,请在查询顶层包含 ORDER BY。
- frame_clause: frame是当前分区的子集,frame子句指定如何定义该子集。
小结:
窗口,就是数据范围,也可以理解为记录集合,窗口函数就是在满足某种条件的记录集合上执行的特殊函数。即,应用在窗口内的函数。
- 静态窗口:窗口大小是固定的,窗口内的每条记录都要执行此函数
- 动态窗口:也叫滑动窗口,窗口大小是变化的
窗口函数有以下功能:
- 同时具有分组和排序的功能
- 不减少原表的行数
2. 窗口函数frame规范
一个frame是当前分区的一个子集,frame子句指定如何定义这个子集。
frame是根据当前行确定的,这使得frame可以根据当前行在分区中的位置在分区中移动。
- 通过将一个frame定义为从分区开始到当前行的所有行,我们可以计算每一行的运行总数。
- 通过将一个frame定义为在当前行的每一边扩展N行,我们可以计算滚动平均。
下面的查询演示了如何使用移动帧来计算每组按时间顺序排列的值的总和,以及从当前行和紧随其后的行计算的滚动平均值:
SELECT
manufacturer, `month`, profit,
SUM(profit) OVER(
PARTITION BY manufacturer
ORDER BY `month`
ROWS unbounded PRECEDING
) AS running_total,
AVG(profit) OVER(
PARTITION BY manufacturer
ORDER BY `month`
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING
) AS running_average
FROM
sales;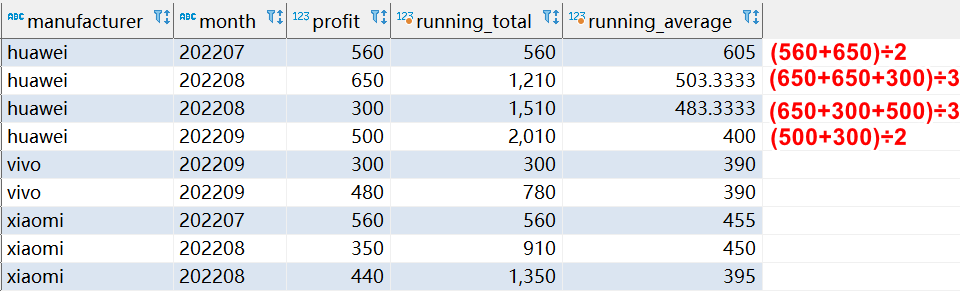
frame 子句语法:
frame_clause:
frame_units frame_extent
frame_units:
{ROWS | RANGE}在没有frame子句的情况下,默认frame取决于是否存在ORDER BY子句。
frame_units值表示当前行和帧行之间的关系类型:
ROWS: frame由开始行和结束行位置定义。偏移量是行号与当前行号之间的差异。RANGE: frame由值范围内的行定义。偏移量是行值与当前行值之间的差异。
frame_extend 表示frame的起始点和结束点。可以只指定frame的开始(在这种情况下,当前行隐式地是结束)或使用BETWEEN指定frame的两个端点:
frame_extent:
{frame_start | frame_between}
frame_between:
BETWEEN frame_start AND frame_end
frame_start, frame_end: {
CURRENT ROW
| UNBOUNDED PRECEDING
| UNBOUNDED FOLLOWING
| expr PRECEDING
| expr FOLLOWING
}使用BETWEEN语法,frame_start不能发生在frame_end之后。
允许的frame_start和frame_end值含义如下:
CURRENT ROW: 对于ROWS,边界是当前行。对于RANGE,边界是当前行的对等点。UNBOUNDED PRECEDING: 边界是第一个分区行。UNBOUNDED FOLLOWING: 边界是最后一个分区行。exprPRECEDINGexprFOLLOWING
下面是一些有效expr PRECEDINGexpr FOLLOWING
10 PRECEDING
INTERVAL 5 DAY PRECEDING
5 FOLLOWING
INTERVAL '2:30' MINUTE_SECOND FOLLOWING在没有frame子句的情况下,默认的frame取决于是否存在ORDER BY子句:
- 有
ORDER BY:默认frame包括从分区开始到当前行的行,包括当前行的所有对等点。与之等效的frame如下:RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW - 没有
ORDER BY:默认frame包括所有的分区行(因为,如果没有ORDER BY,所有的分区行都是对等的)。与之等效的frame如下:RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
因为默认frame会根据是否存在ORDER BY而有所不同,所以向查询添加ORDER BY以获得确定性结果可能会更改结果。要获得相同的结果,但按ORDER BY排序,无论ORDER BY是否存在,都要提供要使用的显式frame规范。
3. 窗口函数应用
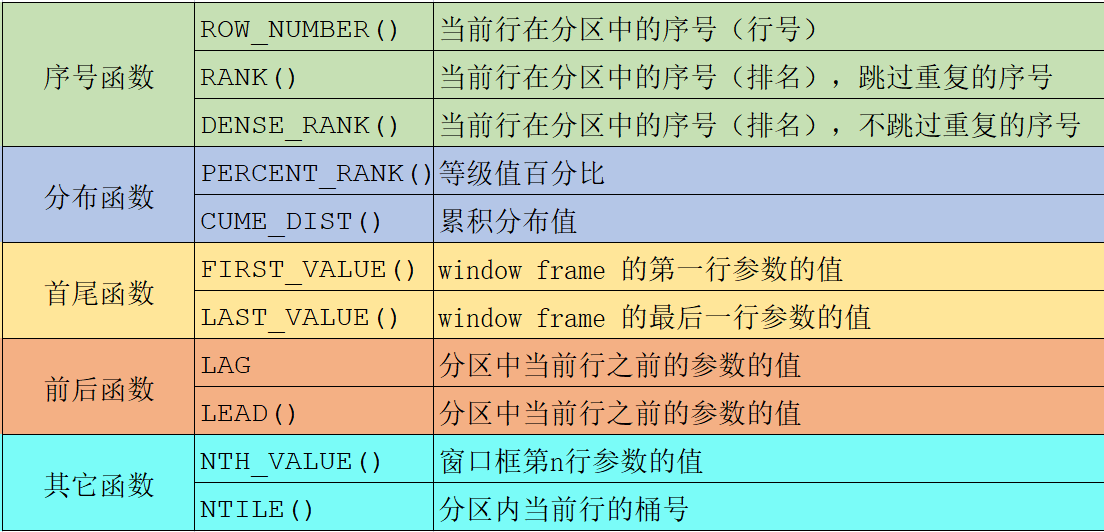
示例数据
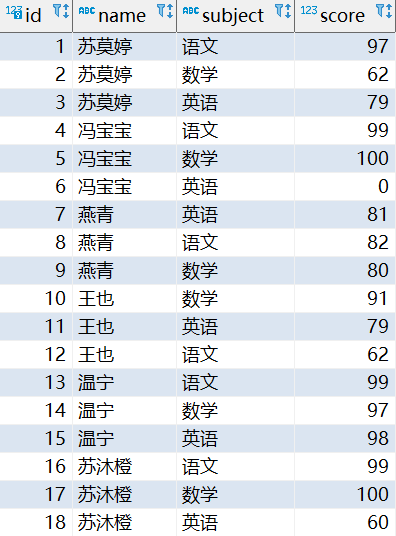
序号函数
select
name, subject, score,
rank() over w as 'rank',
dense_rank() over w as 'dense_rank',
row_number() over w as 'row_number'
from
student
window w as (partition by subject order by score desc);
可以看到,row_number就是个序号,rank在处理并列情况的时候会占用后面的序号,而dense_rank不会
同时,这个SQL中使用了命名窗口写法
Top-N问题:每个类别中取前N条
这类问题可以套用这个模板
SELECT * FROM (SELECT *,row_number() over (PARTITION BY 姓名 ORDER BY 成绩 DESC) AS ranking FROM test) AS tmp WHERE tmp.ranking <= N;查询每科第一名
select * from (
select
name, subject, score,
dense_rank() over(partition by subject order by score desc) as 'rn'
from
student
) tmp where tmp.rn = 1;每科前三名
select * from (
select
name,
subject,
score,
row_number() over(partition by subject order by score desc) as 'rn'
from
student
) tmp where tmp.rn <= 3;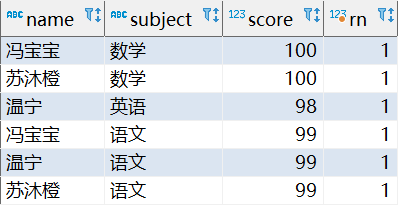
每科高于平均分数(写法一)
select * from (
select
name, subject, score,
avg(score) over(partition by subject) as 'avg_score'
from
student
) tmp where tmp.score > tmp.avg_score;高于每科平均分数(写法二)
select
name, subject, score
from
student s
where
s.score > (select avg(score) from student s2 where s2.subject = s.subject)
order by s.subject asc;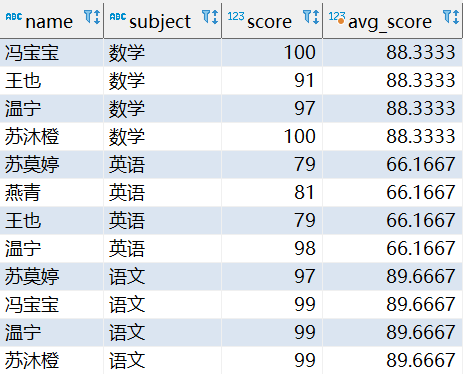
聚集函数作窗口函数
select
name, subject, score,
first_value(score) over(partition by subject order by score desc) as '单科最高分',
max(score) over(partition by subject) as '科目最高分',
min(score) over(partition by subject) as '科目最低分',
avg(score) over(partition by subject) as '科目平均分',
sum(score) over(partition by subject order by score desc rows between unbounded preceding and current row) as '总分',
sum(score) over(partition by name) as '学生总分',
count(subject) over (partition by name) as '参加的学科数'
from
student order by subject;
假设90分算及格,求每个学生的及格率
select
t1.name,
t1.pass_num as '通过的科目数',
t2.total_num as '参加的科目数',
concat(round((t1.pass_num / t2.total_num) * 100, 2), '%') as '及格率'
from
(select name, count(*) pass_num from student where score > 90 group by name) t1
left join (select name, count(*) total_num from student group by name) t2
on t1.name = t2.name;
最后,窗口函数只能在查询或子查询中使用,不能在UPDATE或DELETE语句中使用它们来更新行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号