MongoDB Security
1. Security
MongoDB提供了一系列的保护措施,以保护它自身安全:
- 启用访问控制并实行身份验证
- MongoDB支持多种身份认证机制,默认的认证机制是SCRAM
- 配置基于角色的访问控制
- 首先创建一个管理员账号(administrator),然后创建其他账号。为每个访问系统的人和应用程序创建一个唯一的MongoDB账号
- 遵循最小特权原则。创建定义一组用户所需访问权限的角色。然后创建用户,并仅为他们分配执行操作所需的角色。用户可以是人,也可以是客户端应用程序
- 一个用户可以拥有跨不同数据库的权限。如果一个用户需要在多个数据库上的权限,请创建一个具有授予适用数据库权限的角色的用户,而不是在不同的数据库中多次创建该用户
- 加密通信(TLS/SSL)加密和保护数据
- 将 MongoDB 配置为对所有输入和输出连接使用 TLS/SSL
- 限制网络暴露
- 确保MongoDB运行在受信任的网络环境中,并配置防火墙或安全组来控制MongoDB实例的入站和出站流量
- 禁用直接SSH root访问
- 仅允许受信任的客户端访问 MongoDB 实例可用的网络接口和端口
- 审计系统活动
- 跟踪对数据库配置和数据的访问和更改
- 使用专用用户运行MongoDB使用安全配置选项运行MongoDB
- 使用专用操作系统用户帐户运行 MongoDB 进程。确保该帐户具有访问数据的权限,但没有不必要的权限
1.1. Authentication(认证)
Authentication 是验证用户的身份
Authorization 授予用户对资源和操作的访问权限
简而言之,认证是告诉我“你是谁”,授权是“你可以做什么”
访问控制很简单,只有三步:
- 启用访问控制
- 创建用户
- 认证用户
Salted Challenge Response Authentication Mechanism (SCRAM) 是 MongoDB 的默认身份验证机制。
当用户进行身份验证时,MongoDB使用SCRAM根据用户名、密码和身份验证数据库 验证提供的用户凭据。
MongoDB支持两种SCRAM机制:SCRAM-SHA-1 和 SCRAM-SHA-256
以下是单机版mongod实例进行SCRAM认证的步骤:
1、不带访问控制启动MongoDB
mongod --port 27017 --dbpath /var/lib/mongodb
2、连接到mongodb实例
mongosh --port 27017
3、创建 administrator 用户
注意:可以在启用访问控制之前或之后创建用户管理员。如果在创建任意用户之前启用了访问控制,那么MongoDB会返回一个localhost异常,这个异常告诉我们允许在admin数据库中创建管理员用户。创建之后,必须作为用户管理员进行身份验证后,才可以再创建其他用户。
(PS:上面这句话的意思是,在启用访问控制之前或者之后创建用户管理员都可以,但是如果先启用了访问控制,而后再创建用户的时候就会报错。这个错会告诉我们,应该首先在admin数据库中创建用户管理员,然后用用户管理员登录(或者叫身份验证)成功以后才可以再创建其它用户。)
具体操作步骤如下:
(1)切换到admin数据库
(2)添加一个myUserAdmin用户,并赋予其“userAdminAnyDatabase”和“readWriteAnyDatabase”这两个角色
use admin
db.createUser(
{
user: "myUserAdmin",
pwd: passwordPrompt(), // or cleartext password
roles: [
{ role: "userAdminAnyDatabase", db: "admin" },
{ role: "readWriteAnyDatabase", db: "admin" }
]
}
)注意:passwordPrompt()方法提示你输入密码。你也可以直接将密码指定为字符串。建议使用passwordPrompt()方法,以避免在屏幕上看到密码,并可能将密码泄露到shell历史记录中。
userAdminAnyDatabase 角色运行用户:
- 创建用户
- 授予或撤销用户角色
- 创建或修改自定义角色
4、带访问控制,重启MongoDB实例
用 mongosh 关闭 mongod 实例
db.adminCommand( { shutdown: 1 } )启动mongod,这次带上访问控制
- 如果从命令行启动mongod,则只需带上 --auth 参数即可
mongod --auth --port 27017 --dbpath /var/lib/mongodb - 如果从配置文件启动mongod,则只需将配置文件中security.authorization设置为enabled即可,然后 systemctl start mongod
security:
authorization: enabled

5、以用户管理员身份连接和认证
方式一:连接的时候进行认证
用 mongosh 连接,带上 -u <username>, -p 和 --authenticationDatabase <database> 命令行参数
mongosh --port 27017 --authenticationDatabase "admin" -u "myUserAdmin" -p随后,输入正确的密码即可连接成功
方式二:连接之后再进行认证
先连接,然后切换到认证数据库(本例中是admin),然后使用db.auth(<username>, <pwd>) 方法进行认证
mongosh --port 27017
use admin
db.auth("myUserAdmin", passwordPrompt()) // or cleartext password
1.2. 基于角色的访问控制
MongoDB默认情况下没有启用访问控制。可以通过 --auth 命令行参数 或者 将配置文件中security.authorization设置为enabled 来启用访问控制。
一个角色可以从它所属数据库中的其他角色那里继承权限。 在 admin 数据库上创建的角色可以从任何数据库中的角色继承权限。
分配了角色的用户将获得该角色的所有权限。一个用户可以有多个角色。通过分配给不同数据库中的用户角色,在一个数据库中创建的用户可以具有操作其他数据库的权限。
注意:在数据库中创建的第一个用户应该是具有管理其他用户权限的用户管理员。

1.2.1. 内置角色
每个MongoDB的内置角色都定义了角色数据库中所有非系统集合的数据库级别的访问权限以及所有系统集合的集合级别的访问权限。
MongoDB为每个数据库提供内置的数据库用户和数据库管理角色。MongoDB仅在admin数据库上提供所有其他内置角色。
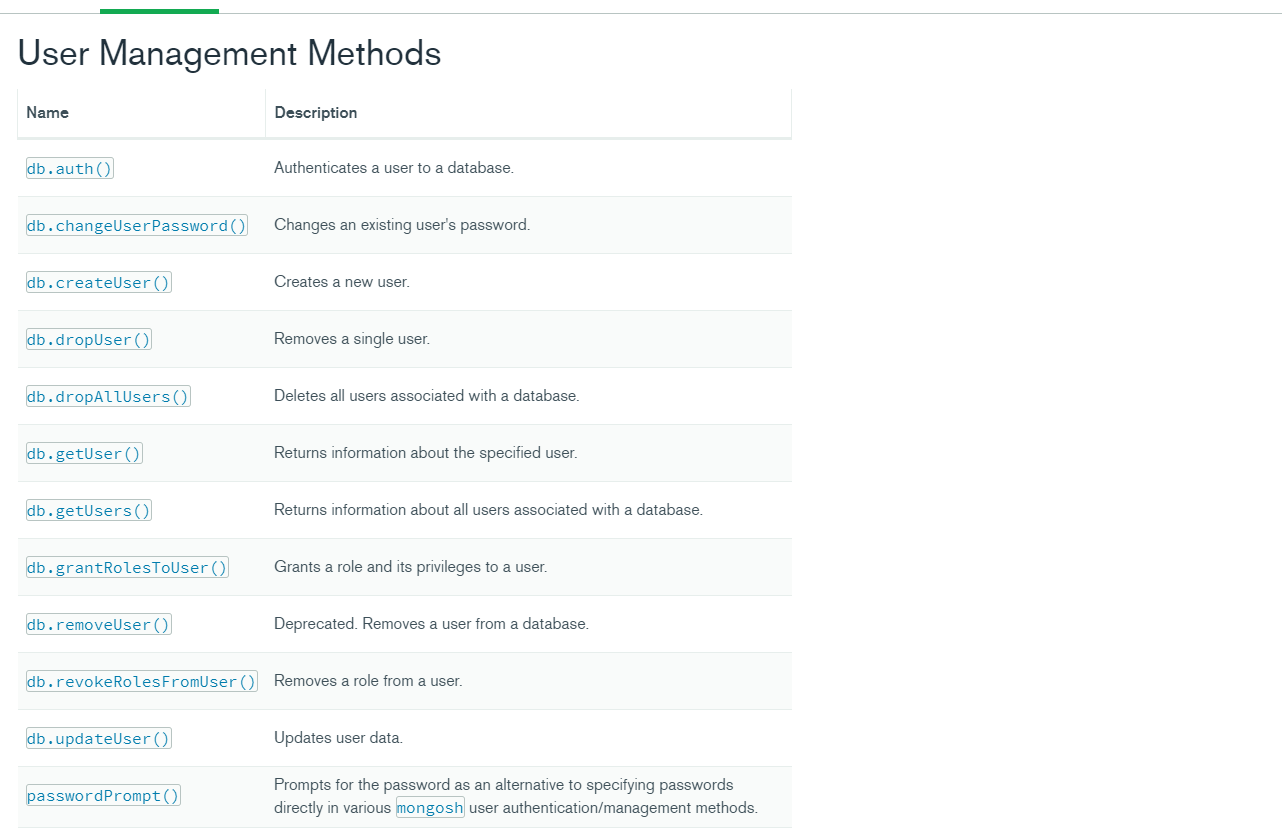
| 角色类型 | 角色名称 | 角色描述 |
|---|---|---|
| Database User Roles | read | 提供在所有非系统集合和system.js集合中读取数据的能力。 |
| readWrite | 提供“read”角色的所有权限,外加在所有非系统集合和system.js集合中修改数据的能力。 | |
| Database Administration Roles | dbAdmin | 提供执行管理任务的能力,例如与数据库相关的任务、索引和收集统计信息。该角色不授予用户和角色管理权限。 |
| dbOwner | 数据库所有者可以对数据库执行任何管理操作。该角色结合了readWrite、dbAdmin和userAdmin三个角色的权限。 | |
| userAdmin | 提供在当前数据库上创建和修改角色和用户的能力。 | |
| Cluster Administration Roles | clusterAdmin | 提供最大的集群管理访问。此角色结合了 clusterManager、clusterMonitor 和 hostManager 角色授予的权限。此外,该角色还提供 dropDatabase 操作的权限。 |
| clusterManager | 提供对集群的管理和监控操作的权限 | |
| clusterMonitor | 提供对监控工具的只读访问权限 | |
| hostManager | 提供监控和管理服务器的能力 | |
| Backup and Restoration Roles | backup | 提供备份数据所需的最低权限 |
| restore | 提供从备份中恢复数据所需的权限 | |
| All-Database Roles | readAnyDatabase | 提供和“read”角色相似的在所有数据库上的只读权限,local和config数据库除外 |
| readWriteAnyDatabase | 提供和“readWrite”角色相似的在所有数据库上的读写权限,local和config数据库除外 | |
| userAdminAnyDatabase | 提供和“userAdmin”角色相似的在所有数据库上访问用户管理操作的权限,local和config数据库除外 | |
| dbAdminAnyDatabase | 提供和“dbAdmin”角色相似的在所有数据库上管理操作的权限,local和config数据库除外 | |
| Superuser Roles | root |
超级用户,提供以下角色的所有权限:
|
| Internal Role | __system | MongoDB 将此角色分配给代表集群成员的用户对象,例如副本集成员和 mongos 实例。 |
1.2.2. 自定义角色

1.2.3. 管理用户和角色
连接
mongosh --port 27017 -u myUserAdmin -p 'abc123' --authenticationDatabase 'admin'
创建角色
use admin
db.createRole(
{
role: "mongostatRole",
privileges: [
{ resource: { cluster: true }, actions: [ "serverStatus" ] }
],
roles: []
}
)查看用户角色
db.getUser("zhangsan")查看角色权限
db.getRole( "readWrite", { showPrivileges: true } )回收(撤销)角色
use reporting
db.revokeRolesFromUser(
"reportsUser",
[
{ role: "readWrite", db: "accounts" }
]
)授予角色
db.grantRolesToUser(
"reportsUser",
[
{ role: "read", db: "accounts" }
]
)创建用户
use test
db.createUser(
{
user:"user123",
pwd: passwordPrompt(), // or cleartext password
roles:[ "readWrite", { role:"changeOwnPasswordCustomDataRole", db:"admin" } ]
}
)
修改密码
db.changeUserPassword("reporting", "SOh3TbYhxuLiW8ypJPxmt1oOfL")或者
use test
db.updateUser(
"user123",
{
pwd: passwordPrompt(), // or cleartext password
customData: { title: "Senior Manager" }
}
)认证
db.auth( <username> )
db.auth( <username>, passwordPrompt() )
db.auth( <username>, <password> )
2. MongoDB Shell
2.1. 安装 mongosh
下载安装包,然后解压,并设置环境变量
# 解压
tar -zxvf mongosh-1.1.7-linux-x64.tgz
# 授予执行权限
chmod +x bin/mongosh
chmod +x bin/mongocryptd-mongosh
# 添加到PATH环境变量中
sudo cp mongosh /usr/local/bin/
sudo cp mongocryptd-mongosh /usr/local/bin/
# 或者
sudo ln -s $(pwd)/bin/* /usr/local/bin/
2.2. 连接到MongoDB服务器
1、本地实例,默认端口
mongosh等同于
mongosh "mongodb://localhost:27017"以上两种写法是一样的
2、本地实例,非默认端口
mongosh --port 28015等价于
mongosh "mongodb://localhost:28015"这两种写法是一样的
3、远程实例
mongosh --host mongodb0.example.com --port 28015或者
mongosh "mongodb://mongodb0.example.com:28015"
2.2.1. 选项参数
1、如果要连接到的MongoDB实例需要身份验证,那么可以使用 --username 和 --authenticationDatabase 命令行选项。mongosh 会提示你输入密码,它会在你键入时屏蔽该密码。
例如:
mongosh "mongodb://mongodb0.example.com:28015" --username alice --authenticationDatabase admin也可以加上 --password 选项,这样的话就是以明文方式带上密码
2、连接到副本集
# 连接到副本集
mongosh "mongodb://mongodb0.example.com.local:27017,mongodb1.example.com.local:27017,mongodb2.example.com.local:27017/?replicaSet=replA"3、连接到指定的数据库
下面的连接字符串URI将连接到数据库db1
mongosh "mongodb://localhost:27017/db1"
2.3. mongosh 用法
# 显示当前数据库
db
# 切换数据库
use <database>
# 创建一个新的数据库和集合
# 如果集合不存在,MongoDB 会在首次存储该集合的数据时创建该集合
use myNewDatabase
db.myCollection.insertOne( { x: 1 } );1、向集合中插入数据
db.myCollection.insertOne()
其中:
- db 代表当前数据库
- myCollection 是集合的名称
2、查看数据库中的集合
db.getCollection()
3、终止命令行
Ctrl + C
4、清屏
cls或者
Ctrl + L
5、文档的增删查改
# 插入单条文档
db.collection.insertOne()
# 插入多条文档
db.collection.insertMany()
# 查询所有文档
db.collection.find()
# 带查询条件
db.collection.find({<field>:<value>, <field>:<value>, ...})
# 更新单条文档
db.collection.updateOne()
# 更新多条文档
db.collection.updateMany()
# 替换
db.collection.replaceOne()
# 删除单条文档
db.collection.deleteOne()
# 删除多条文档
db.collection.deleteMany()示例
use example
db.movies.insertOne(
{
title: "The Favourite",
genres: [ "Drama", "History" ],
runtime: 121,
rated: "R",
year: 2018,
directors: [ "Yorgos Lanthimos" ],
type: "movie"
}
)
db.movies.find( { title: "The Favourite" } )
db.movies.find( {
year: 2010,
$or: [ { "awards.wins": { $gte: 5 } }, { genres: "Drama" } ]
} )
db.listingsAndReviews.updateMany(
{ security_deposit: { $lt: 100 } },
{
$set: { security_deposit: 100, minimum_nights: 1 }
}
)
db.movies.find( { rated: { $in: [ "PG", "PG-13" ] } } )
db.movies.deleteMany({})
db.movies.deleteMany( { title: "Titanic" } )
2.4. mongosh Help
1、命令行帮助
mongosh --help
2、mongosh Shell 帮助
help
3、数据库帮助
show dbs
db.help()
4、集合帮助
(1)查看当前数据库下的集合
show collections
(2)查看集合对象帮助
db.collection.help()
(3)查看特定方法的帮助,用 db.<collection>.<method>.help()
db.collection.getIndexes.help()
(4)光标帮助
db.collection.find().help()更多参见
https://docs.mongodb.com/mongodb-shell/reference/methods/
https://docs.mongodb.com/mongodb-shell/reference/options/
3. 数据库、集合、文档
在 MongoDB 中,数据库保存一个或多个文档集合。
通过 use <db> 来选择某一个数据使用
如果数据库不存在,MongoDB 会在首次存储该数据库的数据时创建该数据库。
use myNewDB
db.myNewCollection1.insertOne( { x: 1 } )
MongoDB 将文档存储在集合中。 集合类似于关系型数据库中的表。

如果集合不存在,MongoDB 会在首次存储该集合的数据时创建该集合。
db.myNewCollection2.insertOne( { x: 1 } )
db.myNewCollection3.createIndex( { y: 1 } )MongoDB 将数据记录存储为 BSON 文档。BSON 是 JSON 文档的二进制表示,尽管它包含比 JSON 更多的数据类型。

文档结构
{
field1: value1,
field2: value2,
field3: value3,
...
fieldN: valueN
}
字段的值可以是任何 BSON 数据类型,包括其他文档、数组和文档数组。例如,以下文档包含不同类型的值:
var mydoc = {
_id: ObjectId("5099803df3f4948bd2f98391"),
name: { first: "Alan", last: "Turing" },
birth: new Date('Jun 23, 1912'),
death: new Date('Jun 07, 1954'),
contribs: [ "Turing machine", "Turing test", "Turingery" ],
views : NumberLong(1250000)
}字段名称是字符串,但是有以下限制
- 字段名“_id”被保留用作主键,它的值在集合中必须是唯一的,是不可变的,并且可以是数组以外的任何类型。 如果 _id 包含子字段,则子字段名称不能以 ($) 符号开头。
- 字段名称不能包含null字符
- 服务器允许存储包含点 (.) 和美元符号 ($) 的字段名称。
点符号
MongoDB 使用点(.)符号来访问数组的元素和访问嵌入文档的字段。
数组
"<array>.<index>"例如:
{
...
contribs: [ "Turing machine", "Turing test", "Turingery" ],
...
}
要指定 contribs 数组中的第三个元素,请使用点表示法“contribs.2”
内嵌文档
"<embedded document>.<field>"例如:
{
...
name: { first: "Alan", last: "Turing" },
contact: { phone: { type: "cell", number: "111-222-3333" } },
...
}- 要指定“first”字段,可以使用“name.last”
- 要指定“number”字段,可以使用“contact.phone.number”
字段顺序
与 JavaScript 对象不同,BSON 文档中的字段是有序的。
对于查询操作,在比较文档时,字段排序非常重要。
例如,在文档查询中比较a和b两个字段时,{a: 1, b: 1} 与 {b: 1, a: 1} 是不同的。
对于写入操作,MongoDB 保留文档字段的顺序,但以下情况除外:
- _id 字段始终是文档中的第一个字段
- 包含重命名字段名称的更新操作可能会导致文档中的字段重新排序
BJSON类型
https://docs.mongodb.com/manual/reference/bson-types/
ObjectId
ObjectId 很小,可能是唯一的,生成速度快,并且是有序的。 ObjectId 值的长度为 12 个字节,包括:
- 一个4字节的时间戳,表示ObjectId的创建时间
- 一个5字节的随机值,每个进程生成一次
- 一个3字节的递增计数器,初始化为一个随机值
在MongoDB中,存储在集合中的每个文档都需要一个唯一的_id字段作为主键。如果插入的文档省略了_id字段,MongoDB会自动为_id字段生成一个ObjectId。
MongoDB客户端应添加具有唯一 ObjectId 的 _id 字段。 将 ObjectIds 用于 _id 字段可提供以下额外好处:
- 在mongosh中,可以使用ObjectId.getTimestamp()方法来访问ObjectId的创建时间
- 对存储ObjectId值的_id字段进行排序大致相当于按创建时间进行排序
4. 配置文件选项
https://docs.mongodb.com/manual/reference/configuration-options/
Linux中,默认配置文件是 /etc/mongod.conf
启动时指定配置文件,可以使用 --config 或者 -f 选项
例如:
mongod --config /etc/mongod.conf或者
mongod -f /etc/mongod.conf主要的一些配置参见 https://docs.mongodb.com/manual/reference/configuration-options/#core-options
5. MongoDB 包组件
5.1. mongod
mongod 是 MongoDB 系统的主要守护进程。 它处理数据请求,管理数据访问,并执行后台管理操作。
https://docs.mongodb.com/manual/reference/program/mongod/
6. CRUD
https://docs.mongodb.com/manual/crud/
https://docs.mongodb.com/manual/reference/command/
https://docs.mongodb.com/manual/reference/method/
7. 存储
存储引擎是数据库的组件,负责管理数据在内存和磁盘中的存储方式。MongoDB 支持多个存储引擎,因为不同的引擎对于特定的工作负载表现更好。选择合适的存储引擎会显着影响应用程序的性能。
7.1. WiredTiger Storage Engine (Default)
WiredTiger 是从 MongoDB 3.2 开始的默认存储引擎。 它非常适合大多数工作负载,建议用于新部署。 WiredTiger 提供文档级并发模型、检查点和压缩等功能。
从 MongoDB 3.2 开始,WiredTiger 存储引擎是默认存储引擎。对于现有部署,如果不指定 --storageEngine 或 storage.engine 设置,则 3.2+ 版本的 mongod 实例可以自动确定 --dbpath 或 storage.dbPath 中用于创建数据文件的存储引擎。
7.1.1. 文档级别的并发
WiredTiger 使用文档级并发控制进行写入操作。 因此,多个客户端可以同时修改一个集合的不同文档。
对于大多数读写操作,WiredTiger 使用乐观并发控制。 WiredTiger 仅在全局、数据库和集合级别使用意图锁。 当存储引擎检测到两个操作之间的冲突时,会引发写入冲突,导致 MongoDB 透明地重试该操作。
7.1.2. 快照和检查点
WiredTiger 使用多版本并发控制 (MVCC)。在操作开始时,WiredTiger 会为操作提供数据的时间点快照。快照呈现内存中数据的一致视图。
写入磁盘时,WiredTiger 将快照中的所有数据以一致的方式跨所有数据文件写入磁盘。现在持久的数据充当数据文件中的检查点。检查点确保数据文件在最后一个检查点之前是一致的,包括最后一个检查点;即检查点可以充当恢复点。
从 3.6 版开始,MongoDB 配置 WiredTiger 以每隔 60 秒创建检查点(即将快照数据写入磁盘)。在早期版本中,MongoDB 将检查点设置为在 WiredTiger 中以 60 秒的间隔或在写入 2 GB 的日志数据时发生在用户数据上,以先发生者为准。
在写入新的检查点期间,之前的检查点仍然有效。因此,即使 MongoDB 在写入新检查点时终止或遇到错误,在重新启动时,MongoDB 也可以从最后一个有效检查点恢复。
当 WiredTiger 的元数据表被原子更新以引用新的检查点时,新的检查点变得可访问和永久。一旦可以访问新的检查点,WiredTiger 就会从旧的检查点中释放页面。
7.1.3. 日志
WiredTiger 使用预写日志(即日志)结合检查点来确保数据的持久性。
WiredTiger 日志保留检查点之间的所有数据修改。 如果 MongoDB 在检查点之间退出,它会使用日志重放自上一个检查点以来修改的所有数据。
7.1.4. 压缩
使用 WiredTiger,MongoDB 支持所有集合和索引的压缩。压缩以增加 CPU 为代价最大限度地减少了存储使用。
默认情况下,WiredTiger 使用 snappy 压缩库对所有集合使用块压缩,对所有索引使用前缀压缩。
7.1.5. 内存使用
使用 WiredTiger,MongoDB 同时利用 WiredTiger 内部缓存和文件系统缓存。
从 MongoDB 3.4 开始,默认的 WiredTiger 内部缓存大小是以下两者中的较大者:
- 50% of (RAM - 1 GB)
- 256 MB
例如,在一个总共有 4GB RAM 的系统上,WiredTiger 缓存将使用 1.5GB 的 RAM (0.5 * (4 GB - 1 GB) = 1.5 GB)。 相反,总共有 1.25 GB RAM 的系统将分配 256 MB 给 WiredTiger 缓存,因为这是总 RAM 减去 1 GB 的一半以上 (0.5 * (1.25 GB - 1 GB) = 128 MB < 256 MB) 。
7.2. 内存存储引擎
内存存储引擎在 MongoDB Enterprise 中可用。它不是将文档存储在磁盘上,而是将它们保留在内存中,以获得更可预测的数据延迟。
从MongoDB Enterprise版本3.2.6开始,内存存储引擎是64位版本中通用可用性(GA)的一部分。除了一些元数据和诊断数据,内存存储引擎不维护任何磁盘上的数据,包括配置数据、索引、用户凭据等。
通过避免磁盘I/O,内存存储引擎允许更多可预测的数据库操作延迟。
7.2.1. 指定内存存储引擎
为了选择使用内存存储引擎,可以这样操作:
- 命令行中使用 --storageEngine 选项指定 inMemory ,或者 在配置文件中通过设置 storage.engine 的值
- --dbpath 或 storage.dbPath(如果使用配置文件)。尽管内存存储引擎不会将数据写入文件系统,但它会在 --dbpath 中维护小型元数据文件和诊断数据以及用于构建大型索引的临时文件。
例如:
mongod --storageEngine inMemory --dbpath <path>或者
storage:
engine: inMemory
dbPath: <path>
7.2.2. 并发
内存存储引擎对写入操作使用文档级并发控制。因此,多个客户端可以同时修改一个集合的不同文档。
7.2.3. 内存使用
内存存储引擎要求它的所有数据(包括索引,如果mongod实例是副本集的一部分,则包括oplog,等等)必须符合命令行选项 --inMemorySizeGB 或配置文件中 storage.inMemory.engineConfig.inMemorySizeGB 设置的内存大小。
默认情况下,内存存储引擎使用 50% 的物理 RAM 减去 1 GB。
例如,内存8G,那么使用内存存储引擎的话,默认使用的内存大小最多是 8 × 0.5 - 1 = 3 GB
如果写入操作会导致数据超过指定的内存大小,MongoDB 会返回错误:
"WT_CACHE_FULL: operation would overflow cache"为了指定新的内存大小,在配置文件中设置 storage.inMemory.engineConfig.inMemorySizeGB
storage:
engine: inMemory
dbPath: <path>
inMemory:
engineConfig:
inMemorySizeGB: <newSize>
或者使用命令行参数 --inMemorySizeGB
mongod --storageEngine inMemory --dbpath <path> --inMemorySizeGB <newSize>
7.2.4. 持久化
内存存储引擎是非持久化的,不向持久化存储写入数据。非持久数据包括应用程序数据和系统数据,如用户、权限、索引、副本集配置、分片集群配置等。
因此,日志或等待数据变得持久的概念不适用于内存存储引擎。
7.2.5. 事务
从MongoDB 4.2开始,副本集和分片集群上都支持事务: 主节点使用 WiredTiger 存储引擎,并且次要成员使用 WiredTiger 存储引擎或内存存储引擎。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号