Spark Streaming 编程入门指南
Spark Streaming 是核心Spark API的扩展,可实现实时数据流的可伸缩,高吞吐量,容错流处理。可以从许多数据源(例如Kafka,Flume,Kinesis或TCP sockets)中提取数据,并且可以使用复杂的算法处理数据,这些算法用高级函数表示,如map、reduce、join和window。最后,可以将处理后的数据推送到文件系统,数据库和实时仪表板。实际上,可以在数据流上应用Spark的机器学习和图形处理算法。

在内部,它的工作方式如下。 Spark Streaming接收实时输入数据流,并将数据分成批次,然后由Spark引擎进行处理,以生成批次的最终结果流。
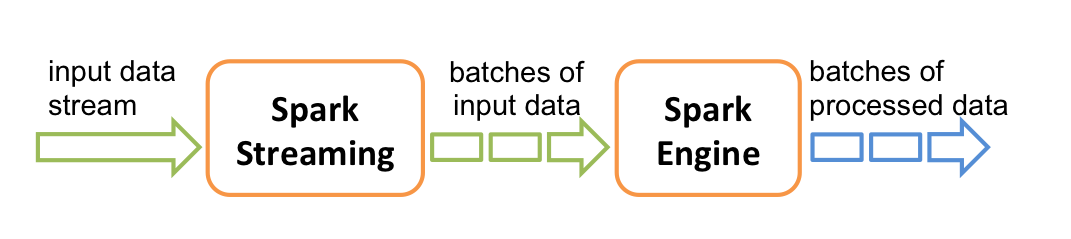
Spark Streaming提供了一种高级抽象,称为离散流或DStream,它表示连续的数据流。DStreams可以从Kafka、Flume和Kinesis等源的输入数据流创建,也可以通过在其他DStreams上应用高级操作创建。在内部,DStream表示为RDDs序列。
1. 了解Spark
Apache Spark 是一个用于大规模数据处理的统一分析引擎

特性:
快
将工作负载运行速度提高100倍
Apache Spark使用最新的DAG调度程序,查询优化器和物理执行引擎,为批处理数据和流数据提供了高性能。
易用
可以使用Java,Scala,Python,R和SQL快速编写应用程序。
通用
结合SQL、流和复杂的分析
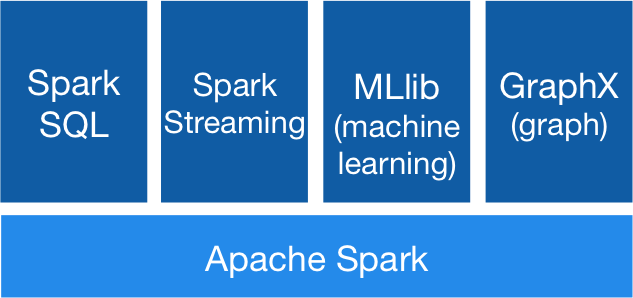
Spark为包括SQL和DataFrames,用于机器学习的MLlib,GraphX和Spark Streaming在内的一堆库提供支持。您可以在同一应用程序中无缝组合这些库。
到处运行
Spark可在Hadoop,Apache Mesos,Kubernetes,独立或云中运行。它可以访问各种数据源。
可以在EC2,Hadoop YARN,Mesos或Kubernetes上使用其独立集群模式运行Spark。访问HDFS,Alluxio,Apache Cassandra,Apache HBase,Apache Hive和数百种其他数据源中的数据。
2. 入门案例
统计单词出现的次数,这个例子在Hadoop中用MapReduce也写过。
JavaStreamingContext是java版的StreamingContext。它是Spark Streaming功能的主要入口点。它提供了从输入源创建JavaDStream和JavaPairDStream的方法。可以使用context.sparkContext访问内部的org.apache.spark.api.java.JavaSparkContext。在创建和转换DStream之后,可以分别使用context.start()和context.stop()启动和停止流计算。
1 public static void main(String[] args) throws InterruptedException {
2 // Create a local StreamingContext with two working thread and batch interval of 1 second
3 SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount");
4 JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(1));
5
6 // Create a DStream that will connect to hostname:port, like localhost:9999
7 JavaReceiverInputDStream<String> lines = jssc.socketTextStream("localhost", 9999);
8
9 // Split each line into words
10 JavaDStream<String> words = lines.flatMap(x -> Arrays.asList(x.split(" ")).iterator());
11
12 // Count each word in each batch
13 JavaPairDStream<String, Integer> pairs = words.mapToPair(s -> new Tuple2<>(s, 1));
14 JavaPairDStream<String, Integer> wordCounts = pairs.reduceByKey((i1, i2) -> i1 + i2);
15
16 // Print the first ten elements of each RDD generated in this DStream to the console
17 wordCounts.print();
18
19 // Start the computation
20 jssc.start();
21 // Wait for the computation to terminate
22 jssc.awaitTermination();
23 }
3. 基本概念
3.1. Maven依赖
1 <groupId>org.apache.spark</groupId>
2 <artifactId>spark-streaming_2.12</artifactId>
3 <version>2.4.5</version>
4 <scope>provided</scope>
5 </dependency>
为了从其它数据源获取数据,需要添加相应的依赖项spark-streaming-xyz_2.12。例如:
1 <dependency>
2 <groupId>org.apache.spark</groupId>
3 <artifactId>spark-streaming-kafka-0-10_2.12</artifactId>
4 <version>2.4.5</version>
5 </dependency>
3.2. 初始化StreamingContext
为了初始化一个Spark Streaming程序,必须创建一个StreamingContext对象,该对象是所有Spark Streaming功能的主要入口点。
我们可以从SparkConf对象中创建一个JavaStreamingContext对象
1 import org.apache.spark.SparkConf;
2 import org.apache.spark.streaming.Duration;
3 import org.apache.spark.streaming.api.java.JavaStreamingContext;
4
5 SparkConf conf = new SparkConf().setAppName(appName).setMaster(master);
6 JavaStreamingContext ssc = new JavaStreamingContext(conf, new Duration(1000));
appName 参数是显示在集群UI上的你的应用的名字
master 参数是一个Spark、 Mesos 或 YARN 集群URL,或者也可以是一个特定的字符串“local[*]”表示以本地模式运行。实际上,当在集群上运行时,肯定不希望对在程序中对master进行硬编码,而希望通过spark-submit启动应用程序并在其中接收它。然而,对于本地测试,你可以传“local[*]”来运行Spark Streaming。
还可以从一个已存在的JavaSparkContext中创建一个JavaStreamingContext对象
1 import org.apache.spark.streaming.api.java.*;
2
3 JavaSparkContext sc = ... //existing JavaSparkContext
4 JavaStreamingContext ssc = new JavaStreamingContext(sc, Durations.seconds(1));
在定义完context之后,必须做以下事情:
- 通过创建input DStreams来定义input sources
- 通过对DStreams应用transformation(转换)和output(输出)操作来定义流计算
- 用streamingContext.start()来开始接收数据并处理它
- 用streamingContext.awaitTermination()等待处理停止(手动停止或由于任何错误)
- 用streamingContext.stop()可以手动停止
需要记住的点:
- 一旦启动上下文,就无法设置新的流计算或将其添加到该流计算中
- 上下文一旦停止,就无法重新启动
- 一个JVM中只能同时激活一个StreamingContext
- StreamingContext中的stop()也会停止SparkContext。但如果要仅停止StreamingContext的话,设置stop(false)
- 只要在创建下一个StreamingContext之前停止了上一个StreamingContext(不停止SparkContext),就可以将SparkContext重用于创建多个StreamingContext
3.3. DStreams(离散流)
Discretized Stream 或 DStream 是Spark Streaming提供的基本抽象。它表示一个连续的数据流,可以是从源接收的输入数据流,也可以是通过转换输入流生成的已处理数据流。在内部,DStream由一系列连续的RDD表示,这是Spark对不变的分布式数据集的抽象。DStream中的每个RDD都包含来自特定间隔的数据,如下图所示。
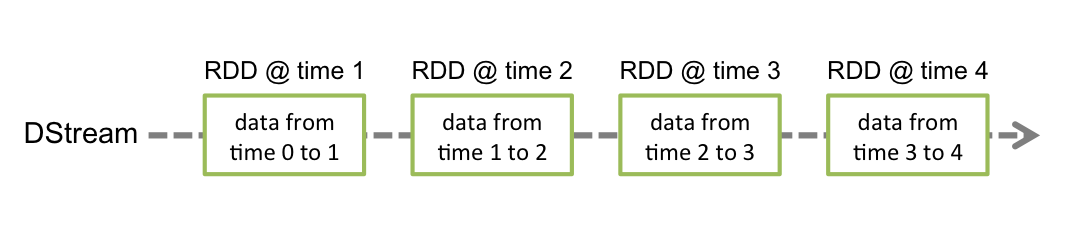
在DStream上执行的任何操作都转换为对基础RDD的操作。例如,最简单的将一行句子转换为单词的例子中,flatMap操作应用于行DStream中的每个RDD,以生成单词DStream的RDD。如下图所示:
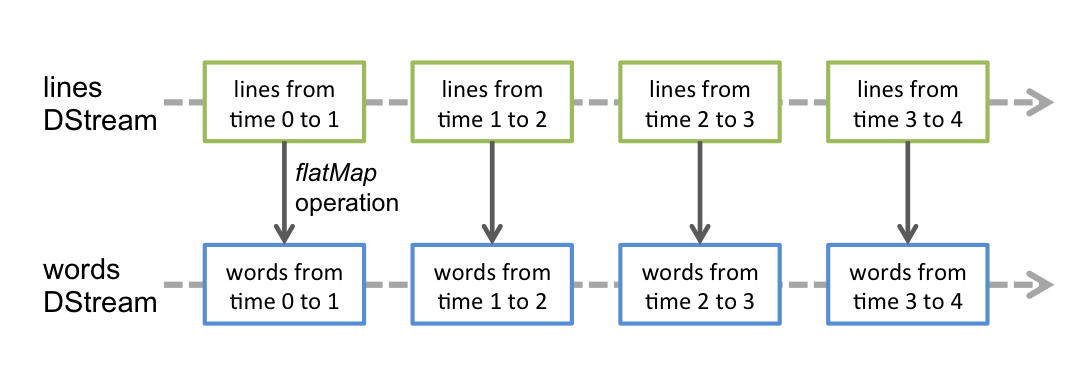
3.4. Input DStreams 和 Receivers
Input DStream是表示从源接收的输入数据流。在上图中,lines是输入DStream,因为它表示从netcat服务器接收的数据流。每一个输入DStream都关联着一个Receiver对象,该对象从源接收数据并将其存储在Spark的内存中以进行处理。
Spark Streaming提供了两类内置的streaming源:
- Basic sources :直接在StreamingContext API中可用的源。例如,文件系统和socket连接
- Advanced sources :像Kafka,Flume,Kinesis等这样的源,可通过额外的程序类获得
如果要在流应用程序中并行接收多个数据流,则可以创建多个输入DStream。这将创建多个Receiver(接收器),这些接收器将同时接收多个数据流。重要的是要记住,必须为Spark Streaming应用程序分配足够的内核(或线程,如果在本地运行),以处理接收到的数据以及运行接收器。
需要记住的点:
- 在本地运行Spark Streaming程序时,请勿使用“ local”或“ local [1]”作为master URL。这两种方式均意味着仅一个线程将用于本地运行任务。如果使用的是基于接收器的输入DStream(例如套接字,Kafka,Flume等),则将使用单个线程来运行接收器,而不会留下任何线程来处理接收到的数据。 因此,在本地运行时,请始终使用“ local [n]”作为主URL,其中n>要运行的接收器数
- 为了将逻辑扩展到在集群上运行,分配给Spark Streaming应用程序的内核数必须大于接收器数。 否则,系统将接收数据,但无法处理它。
Basic Sources
为了从文件中读取数据,可以通过StreamingContext.fileStream[KeyClass, ValueClass, InputFormatClass]来创建一个DStream
例如:streamingContext.textFileStream(dataDirectory);
Spark Streaming将监视目录dataDirectory并处理在该目录中创建的所有文件
- 可以监视一个简单的目录,例如:"hdfs://namenode:8040/logs/2017/*"。在这里,DStream将由目录中与模式匹配的所有文件组成。也就是说:它是目录的模式,而不是目录中的文件。
- 所有文件必须使用相同的数据格式
- 根据文件的修改时间而不是创建时间,将其视为时间段的一部分
- 一旦已经被处理后,在当前窗口中对文件的更改不会导致重新读取该文件。即:更新被忽略。
3.5. Transformations on DStreams
对DStreams做转换,与RDD相似,转换允许修改输入DStream中的数据。DStream支持普通Spark RDD上可用的许多转换。一些常见的方法如下:
| map(func) | 通过将源DStream的每个元素传递给函数func来处理并返回新的DStream | ||
| flatMap(func) | 与map类似,但是每个输入项可以映射到0个或多个输出项 | ||
| filter(func) | 过滤 | ||
| repartition(numPartitions) | 通过创建更多或更少的分区来更改此DStream中的并行度 | ||
| union(otherStream) | 将源DStream和另一个DStream中的元素合并在一起,返回一个新的DStream。相当于SQL中的union | ||
| count() | 返回元素的个数 | ||
| reduce(func) | 通过使用函数func(接受两个参数并返回一个)来聚合源DStream的每个RDD中的元素,从而返回一个单元素RDD的新DStream。 | ||
| countByValue() |
|
||
| reduceByKey(func, [numTasks]) | 在一个(K,V)形式的DStream上调用时,返回一个新的(K,V)DStream,其中使用给定的reduce函数汇总每个键的值 | ||
| join(otherStream, [numTasks]) | 在(K,V)和(K,W)两个DStream上调用时,返回一个新的(K,(V,W))DStream | ||
| cogroup(otherStream, [numTasks]) | 在(K,V)和(K,W)DStream上调用时,返回一个新的(K,Seq [V],Seq [W])元组的DStream | ||
| transform(func) | 通过对源DStream的每个RDD应用RDD-to-RDD函数来返回新的DStream。这可用于在DStream上执行任意RDD操作。 |
||
| updateStateByKey(func) | 返回一个新的“state” DStream | ||
其实,这次操作跟Java Stream很像
Window Operations(窗口操作)
Spark Streaming还提供了窗口计算,可以在数据的滑动窗口上应用转换。下图说明了此滑动窗口:
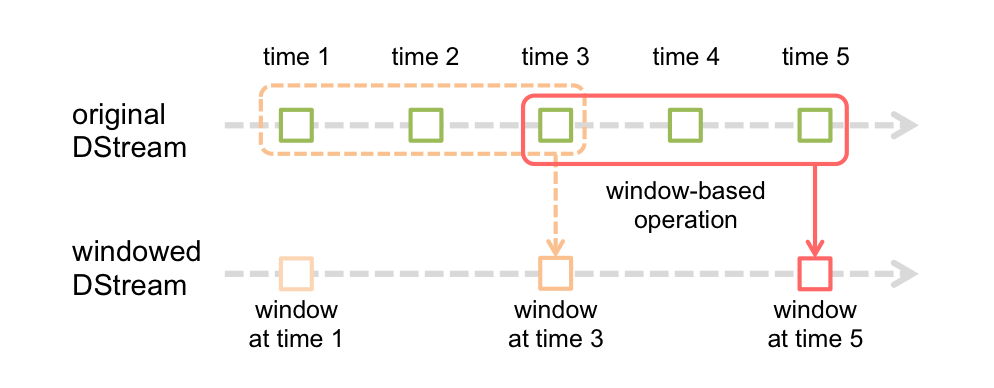
如图所示,每当窗口在源DStream上滑动时,就会对落入窗口内的源RDD进行操作,以生成窗口DStream的RDD。
任何窗口函数所必须的两个参数:
- 窗口的长度
- 滑到的频率(或者说时间间隔)
举个例子,我们来扩展前面的示例,假设我们想要每10秒在数据的最后30秒生成一次单词次数统计。为此,必须在数据的最后30秒内对(word,1)对的DStream对应用reduceByKey操作。
1 import org.apache.spark.streaming.Durations;
2 import org.apache.spark.streaming.api.java.JavaDStream;
3 import org.apache.spark.streaming.api.java.JavaPairDStream;
4 import scala.Tuple2;
5
6
7 JavaDStream<String> words = lines.flatMap(x -> Arrays.asList(x.split(" ")).iterator());
8 JavaPairDStream<String, Integer> pairs = words.mapToPair(s -> new Tuple2<>(s, 1));
9
10 // Reduce last 30 seconds of data, every 10 seconds
11 JavaPairDStream<String, Integer> windowedWordCounts = pairs.reduceByKeyAndWindow((i1, i2) -> i1 + i2, Durations.seconds(30), Durations.seconds(10));
一些常见的窗口操作如下。所有这些操作均采用上述两个参数:windowLength和slideInterval
| window(windowLength, slideInterval) | 返回基于源DStream的窗口批处理计算的新DStream |
| countByWindow(windowLength, slideInterval) | 返回流中元素的滑动窗口数 |
| reduceByWindow(func, windowLength, slideInterval) | 对窗口内的数据进行聚合操作 |
| reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]) | 在(K,V)DStream上调用时,返回新的(K,V)DStream,其中使用给定的reduce函数func在滑动窗口中的批处理上汇总每个键的值 |
| reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]) | |
| countByValueAndWindow(windowLength, slideInterval, [numTasks]) |
3.6. Output Operations on DStreams
输出操作允许将DStream的数据输出到外部系统,例如数据库或文件系统。

流式应用程序必须24/7全天候运行,因此必须能够抵抗与应用程序逻辑无关的故障(例如,系统故障,JVM崩溃等)。为此,Spark Streaming需要将足够的信息检查点指向容错存储系统,以便可以从故障中恢复。检查点有两种类型的数据。
- 元数据检查点-将定义流计算的信息保存到HDFS等容错存储中。这用于从运行流应用程序的驱动程序的节点的故障中恢复。
- 数据检查点-将生成的RDD保存到可靠的存储中
完整代码:
1 package com.example.demo;
2
3 import org.apache.spark.SparkConf;
4 import org.apache.spark.streaming.Durations;
5 import org.apache.spark.streaming.api.java.JavaDStream;
6 import org.apache.spark.streaming.api.java.JavaPairDStream;
7 import org.apache.spark.streaming.api.java.JavaStreamingContext;
8 import scala.Tuple2;
9
10 import java.util.Arrays;
11 import java.util.regex.Pattern;
12
13 /**
14 * @author ChengJianSheng
15 */
16 public class JavaWordCount {
17
18 private static final Pattern SPACE = Pattern.compile(" ");
19
20 public static void main(String[] args) {
21 if (args.length < 1) {
22 System.err.println("Usage: JavaWordCount <file>");
23 System.exit(1);
24 }
25
26 SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("JavaWordCount");
27 JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(1));
28
29 JavaDStream<String> lines = jssc.textFileStream(args[0]);
30 JavaDStream<String> words = lines.flatMap(line -> Arrays.asList(SPACE.split(line)).iterator());
31 JavaPairDStream<String, Integer> ones = words.mapToPair(word -> new Tuple2<>(word, 1));
32 JavaPairDStream<String, Integer> counts = ones.reduceByKey((i1, i2) -> i1 + i2);
33 counts.print();
34
35 /*
36 JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(1));
37 JavaDStream<String> textFileStream = jsc.textFileStream("/data");
38 textFileStream.flatMap(line->Arrays.asList(line.split(" ")).iterator())
39 .mapToPair(word->new Tuple2<>(word, 1))
40 .reduceByKey((a,b)->a+b)
41 .print();
42 jsc.start();
43 */
44 }
45 }
4. Docs
https://spark.apache.org/docs/latest/streaming-programming-guide.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号