Elasticsearch Index模块
1. Index Setting(索引设置)
每个索引都可以设置索引级别。可选值有:
- static :只能在索引创建的时候,或者在一个关闭的索引上设置
- dynamic:可以动态设置
1.1. Static index settings(静态索引设置)
- index.number_of_shards :一个索引应该有的主分片(primary shards)数。默认是5。而且,只能在索引创建的时候设置。(注意,每个索引的主分片数不能超过1024。当然,这个设置也是可以改的,通过在集群的每个节点机器上设置系统属性来更改,例如:export ES_JAVA_OPTS="-Des.index.max_number_of_shards=128")
- index.shard.check_on_startup :分片在打开前是否要检查是否有坏损。默认是false。
- index.routing_partition_size :自定义的路由值可以路由到的分片数。默认是1。
1.2. Dynamic index settings(动态索引设置)
- index.number_of_replicas :每个主分片所拥有的副本数,默认是1。
- index.auto_expand_replicas :根据集群中数据节点的数量自动扩展副本的数量。默认false。
- index.refresh_interval :多久执行一次刷新操作,使得最近的索引更改对搜索可见。默认是1秒。设置为-1表示禁止刷新。
- index.max_result_window :在这个索引下检索的 from + size 的最大值。默认是10000。(PS:也就是说最多可以一次返回10000条)
2. Analysis
索引分析模块是一个可配置的分析器注册表,可用于将字符串字段转换为以下各个场景中的Term:
- 添加到反向索引( inverted index)以使文档可搜索
- 用于高级查询,如match查询
(PS:简而言之,
第一、分析器用于将一个字符串转成一个一个的Term;
第二、这些Term可以被添加到反向索引中,以使得该文档可以通过这个Term被检索到;
第三、这些Term还可以高级查询,比如match查询)
3. Merge(合并)
在Elasticsearch中,一个分片就是一个Lucene索引,而且一个Lucene索引被分解成多个段(segments)。段是索引中存储索引数据的内部存储元素,并且是不可变的。较小的段定期合并到较大的段中,以控制索引大小。
合并调度程序(ConcurrentMergeScheduler)在需要时控制合并操作的执行。合并在单独的线程中运行,当达到最大线程数时,将等待进一步的合并,直到合并线程可用为止。
支持下列参数:
- index.merge.scheduler.max_thread_count :在单个碎片上,一次合并的最大线程数。默认是 Math.max(1, Math.min(4, Runtime.getRuntime().availableProcessors() / 2))
4. Slow log(慢日志)
4.1. Search Slow Log(查询慢日志)
分片级慢查询日志,允许将慢查询记录到专用的日志文件中
可以在执行query阶段和fetch阶段设置阈值,例如:

上面所有的设置项都是动态设置的,而且是按索引设置的。(PS:也就是说,是针对某一个索引设置的)
默认情况下,是禁用状态(设置为-1)
级别(warn, info, debug, trace)可以控制哪些日志级别的日志将会被记录
注意,日志记录是在分片级别范围内完成的,这意味着只有在特定的分片中执行搜索请求的慢日志才会被记录。
日志文件配置默认在log4j2.properties
4.2. Index Slow Log(索引慢日志)
和前面的慢查询日志类似,索引慢日志文件名后缀为_index_indexing_slowlog.log
日志和阈值配置与慢查询类似,而且默认日志文件配置也是在log4j2.properties
下面是一个例子:

5. Store(存储)
5.1. 文件存储类型
不同的文件系统有不同的存储类型。默认情况下,Elasticsearch将根据操作环境选择最佳实现。
可选的存储类型有:
- fs :默认实现,取决于操作系统
- simplefs :对应Lucene SimpleFsDirectory
- niofs :对应Lucene NIOFSDirectory
- mmapfs :对应Lucene MMapDirectory
可以改变这种设置,通过在config/elasticsearch.yml中添加如下配置,例如:
index.store.type: niofs
上面的设置对所有的索引都生效。你也可以在索引创建的时候针对某一个特定的索引进行设置,例如:
curl -X PUT "localhost:9200/my_index" -H 'Content-Type: application/json' -d' { "settings": { "index.store.type": "niofs" } } '
5.2. 预加载数据到文件系统缓存
默认情况下,Elasticsearch完全依赖于操作系统的文件系统缓存来缓存I/O操作。可以设置index.store.preload来告诉操作系统在打开时将热点索引文件的内容加载到内存中。这个选项接受一个逗号分隔的文件扩展列表:扩展名在列表中的所有文件将在打开时预加载。这对于提高索引的搜索性能非常有用,特别是在主机操作系统重启时,因为这会导致文件系统缓存被丢弃。但是请注意,这可能会减慢索引的打开速度,因为只有在将数据加载到物理内存之后,索引才会可用。
静态设置的话可以这样设置:
index.store.preload: ["nvd", "dvd"]
或者在索引创建的时候设置:
curl -X PUT "localhost:9200/my_index" -H 'Content-Type: application/json' -d' { "settings": { "index.store.preload": ["nvd", "dvd"] } } '
默认值是一个空数组,意味着文件系统不会预加载任何数据。对于可搜索的索引,你可能想要把它们设置为["nvd", "dvd"],这将会使得norms和doc数据被预先加载到物理内存。不推荐把所有的文件都预加载到内存,通常可能更好的选择是设置为["nvd", "dvd", "tim", "doc", "dim"],这样的话将会预加载norms,doc values,terms dictionaries, postings lists 和 points
6. Translog(事物日志)
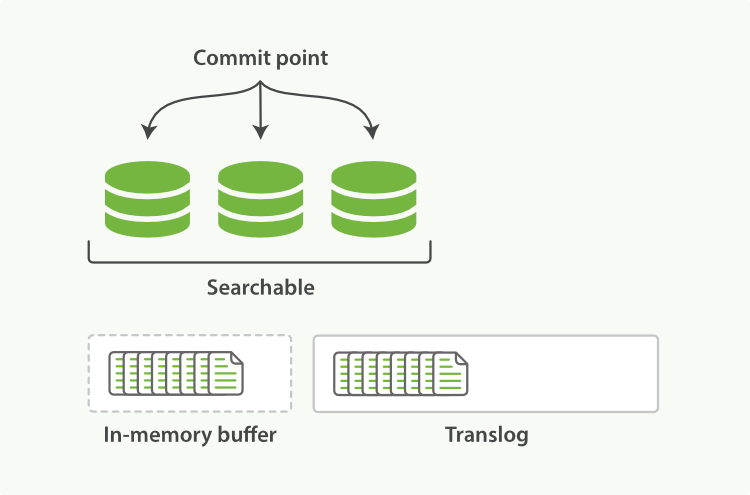
对Lucene的更改只有在Lucene提交的时候才会持久化到磁盘,这是一个相对昂贵的操作,因此不能再每次索引创建或者删除以后就执行。如果进程退出或者硬件故障的话,那么在两次提交之间所做的更改将会被Lucece从索引中删除。(PS:上一次提交以后到下一次提交之前这之间的更新会丢失)
如果每次更改以后立即执行Lucene提交,那么这个开销实在太大,因此每个分片副本也都有一个事物日志,它被叫做与之关联的translog。所有的索引和删除操作都是在内部Lucene索引处理之后,确认之前,被写入到translog的。在崩溃的情况下,当分片恢复时,可以从translog中恢复最近的事务,这些事务已经被确认,但是还没有包含在上一次Lucene提交中。
Elasticsearch flush是执行Lucene提交并启动新translog的过程。flush是在后台自动执行的,以确保translog不会变得太大。(PS:因为如果translog很大,那么恢复所需要的时间越长)。当然,我们也可以通过API手动执行刷新,尽管很少需要这样做。
6.1. Translog设置
translog中的数据只有在fsync和提交时才会被持久化到磁盘。在硬件失败的情况下,在translog提交之前的数据都会丢失。
默认情况下,如果index.translog.durability被设置为async的话,Elasticsearch每5秒钟同步并提交一次translog。或者如果被设置为request(默认)的话,每次index,delete,update,bulk请求时就同步一次translog。更准确地说,如果设置为request, Elasticsearch只会在成功地在主分片和每个已分配的副本分片上fsync并提交translog之后,才会向客户端报告index、delete、update、bulk成功。
可以动态控制每个索引的translog行为:
- index.translog.sync_interval :translog多久被同步到磁盘并提交一次。默认5秒。这个值不能小于100ms
- index.translog.durability :是否在每次index,delete,update,bulk请求之后立即同步并提交translog。接受下列参数:
- request :(默认)fsync and commit after every request。这就意味着,如果发生崩溃,那么所有只要是已经确认的写操作都已经被提交到磁盘。
- async :在后台每sync_interval时间进行一次fsync和commit。意味着如果发生崩溃,那么所有在上一次自动提交以后的已确认的写操作将会丢失。
- index.translog.flush_threshold_size :当操作达到多大时执行刷新,默认512mb。也就是说,操作在translog中不断累积,当达到这个阈值时,将会触发刷新操作。
- index.translog.retention.size :translog文件达到多大时执行执行刷新。默认512mb。
- index.translog.retention.age :translog最长多久提交一次。默认12h。
6.2. 小结
1、只有在Lucene提交的时候,对Lucene所做的更改才会持久化到磁盘,而这一操作开销很大,因而不可能每次改变后就立即提交,而如果不是每次更改后立即提交的话,那么在本次提交以后到下一次提前以前这之间的更改就有丢失的可能。为了解决这种问题,每个索引分片都有一个叫做“translog”的事物日志,每次Lucene处理完以后,就向translog中写日志,最后确认本次更改。也就是说,translog是在Lucene内部处理完以后,确认请求之前写的。
2、translog是为了避免频繁Lucene提交所造成的大额开销,同时又要尽量减少数据丢失而采取的一种方案
3、Elasticsearch flush的时候会提交Lucene更改,同时开启新的translog。flush是后台自动进行的。默认30分钟一次。
4、translog本身作为文件也是需要fsync(同步)到磁盘的。通过translog选项设置,我们可以控制多久同步一次,或者当文件达到多大的时候同步,或者文件最长多久就必须同步。默认每次请求以后就立即同步。如果在同步之前发生崩溃,那么上一次同步之后的写操作也是会丢失的。
5、Lucene提交跟translog提交是两回事,Lucene提交的时候translog肯定会被提交
7. Segment(段)
向索引中插入文档时,文档首先被保存在内存缓存(in-memory buffer)中,同时将操作写入到translog中,此时这条刚插入的文档还不能被搜索到。默认1秒钟refresh一次,refresh操作会将文件写到操作系统的文件系统缓存中,并形成一个segment,refresh后文档可以被检索到。
当flush的时候,所有segment被同步到磁盘,同时清空translog,然后生成一个新的translog
Lucene把每次生成的倒排索引叫做一个segment,也就是说一个segment就是一个倒排索引。(PS:可以类比Oracle中段区块的概念)
8. 参考
https://www.elastic.co/guide/en/elasticsearch/reference/current/index-modules.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/index-modules-translog.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号