
结对第二次作业——部门与学生的智能匹配
Github地址
小组成员
031502107 陈家权
031502147 庄加鑫
数据模型
-
对于学生,我们建立了student结构体,其中包含学生编号(int sid),学生绩点(double gpa),学生的兴趣标签(string interest[12]),兴趣标签个数(int interest_cnt),学生的空闲时间(将每一个时间段映射成int数据,用两个二维数组表示,start_freetime[10][2]表示开始时间,end_freetime[10][2]表示结束时间,其中[10][0]表示第几天,[10][1]表示时间段,一天共划分成48个时间段,即每半个小时为一个时间段,例如:start_freetime[10][0]=1,start_freetime[10][1]=38,表示开始时间是星期一七点。)加入的部门编号(采用vector容器,vector admission_dep),标记某个空闲时间段是否已有部门活动(bool mark_freetime[10])。
-
对于部门,我们建立了department结构体,其中包含部门标号(int did),纳新人数(int num),部门的特点标签(string feature[12]),剩余席位(int numrest) ,部门的活动时间(用两个二维数组表示,start_hdtime[10][2]表示开始时间,end_hdtime[10][2]表示结束时间,具体情况同学生的空闲时间一样。),匹配成功的学生信息(vector res)
struct student
{
int sid; // 学生编号
double gpa; // 学生绩点
string interest[12];//兴趣标签
int interest_cnt;//兴趣标签个数
int voluntary[5]; //学生志愿部门
int start_freetime[10][2];//学生空闲开始时间
int end_freetime[10][2];//学生空闲结束时间
int freetime_cnt;//学生空闲时间个数
vector<int>admission_dep;//加入的部门编号
bool mark_freetime[10];//标记某个空闲时间段是否已有部门活动
} stu[301];
struct department
{
int did; //部门编号
int num; //纳新人数
int numrest; //剩余席位
string feature[12];//特点标签
int feature_cnt; //特点标签个数
int start_hdtime[2][2];//部门活动开始时间
int end_hdtime[2][2];//部门活动结束时间
int hdtime_cnt;//部门活动时间个数
vector<struct student> res; //接纳集合
} dep[21];
- 数据生成程序主要用的就是随机函数。
对于学生,随机生成绩点范围(1,5),兴趣标签(5-7个),空闲时间段(5-6个,晚上大多有时间),先随机生成开始时间,再随机生成结束时间(18:00~24:00 映射成int数据范围为36~48)。
对于部门,随机生成纳新人数(12,15],特点标签,部门的活动时间(1-2个),先随机生成开始时间,再随机生成结束时间(19:00~21:00 映射成int数据范围为38~42)。 - 考虑的因素
把部门的活动时间和学生空闲时间规定在晚上,比较切合实际
部门的最低纳新人数控制(纳新的人数是限制匹配率的重要条件,因此每个部门纳新人数设置较高)
以下是import文件生成代码:
int main() {
srand(time(NULL));
FILE *fp1;
fp1=fopen("import.txt","w");
int i,j,cnt,test[21];
for(i=1; i<=20; i++) {
fprintf(fp1,"%d ",i);
fprintf(fp1,"%d ",rand()%4+12);
cnt=rand()%3+5;
fprintf(fp1,"%d ",cnt);
int l=rand()%12;
for(j=0; j<cnt; j++) {
l=(l+1)%12;
fprintf(fp1,"%d ",l);
}
//fprintf(fp1,"\n");
cnt=rand()%2+1;
fprintf(fp1,"%d ",cnt);
memset(test,0,sizeof(test));
for(j=0; j<cnt;) {
int day=rand()%7+1;
if(test[day]==0) {
int hour=rand() % 2 + 38;
test[day]=1;
j++;
fprintf(fp1,"%d %d %d\n",day,hour,hour+3);
}
}
fprintf(fp1,"\n");
}
for(i=1; i<=300; i++) {
fprintf(fp1,"%d\n",i);
fprintf(fp1,"%.2lf\n",(1 + rand() % 4 + double(rand() % 10) / 10));
cnt=rand()%3+5;
fprintf(fp1,"%d\n",cnt);
int l=rand()%10;
for(j=0; j<cnt; j++) {
l=(l+1)%10;
fprintf(fp1,"%d ",l);
}
fprintf(fp1,"\n");
cnt=5;
fprintf(fp1,"%d\n",cnt);
memset(test,0,sizeof(test));
for(j=0; j<cnt;) {
int l=rand()%20+1;
if(test[l]==0) {
fprintf(fp1,"%d ",l);
test[l]=1;
j++;
}
}
fprintf(fp1,"\n");
cnt=rand()%2+5;
fprintf(fp1,"%d\n",cnt);
memset(test,0,sizeof(test));
for(j=0; j<cnt;) {
int day=rand()%7+1;
if(test[day]==0) {
int hour=rand() % 3 + 36;
test[day]=1;
j++;
fprintf(fp1,"%d %d %d\n",day,hour,rand()%3+hour+4);
}
}
fprintf(fp1,"\n");
}
fclose(fp1);
return 0;
}
输入数据import.txt
-
关于import.txt里数据的说明
-
前20项为部门的信息:
数据顺序依次为部门编号,部门纳新人数,部门标签个数n,n个部门标签下标,部门活动时间段个数m,
m个具体的时间段(每个时间由3个数据构成,活动为星期几,活动开始时间,活动结束时间) -
后300项为学生信息:
数据顺序依次为学生编号,学生绩点,学生兴趣个数n,n个兴趣标签下标,学生志愿部门个数m,m个志愿部门编号,空闲时间段个数k,
k个具体的时间段(每个时间由3个数据构成,空闲时间为星期几,空闲时间段开始时间,空闲时间段束时间)
结合数据模型的算法
写在前面:
1.每个优先算法都是按照志愿优先的原则,即5个志愿部门优先级不同,第一志愿的优先级高于第二志愿优先级,以此类推,算法匹配的过程从学生的第一志愿到第五志愿依次匹配,决定学生是否可加入志愿部门。因此学生需选择最心仪部门填在靠前的位置。
2.争取最大机会填满所有志愿,因此我们的程序默认每个学生都填满了5个志愿部门,毕竟学生如果少填一个部门志愿,可能就失去了一次匹配机会。
学生与部门的匹配,都要先考虑空闲时间和活动时间是否冲突,若时间冲突,则该学生不可加入该部门,以下是判断时间是否冲突的代码:
int initialization::time_is_ok(int sid, int did)
{
for (int i = 0; i <stu[sid].freetime_cnt; i++)
{
for (int j = 0; j < dep[did].hdtime_cnt; j++)
{
if (!stu[i].mark_freetime[i] && stu[sid].start_freetime[i][0] == dep[did].start_hdtime[j][0] && stu[sid].start_freetime[i][1] <= dep[did].start_hdtime[j][1] && stu[sid].end_freetime[i][1] >= dep[did].end_hdtime[j][1])
return i;
}
}
return -1; //表示时间冲突
}
这里不用bool数据类型而用int类型的原因是:返回值说明该学生的第i个空闲时间段已有部门活动,在之后的部门匹配中,该学生已不可再加入在这个时间段有活动的部门。
接下来说说绩点优先算法(GraFirst):
绩点优先算法按照“学生绩点优先、遵循志愿顺序”的原则进行匹配。
绩点优先算法:
1.先将学生按照绩点从高到低排序。然后300个学生按照志愿依次匹配。
2.对于学生的每一个志愿,算法每次判定该部门是否已招满,若该部门已招满新部员,则此次匹配不成功。继续判定下一个学生的同一顺序的志愿。若该部门未招满部员,则继续判定学生的空闲时间和部门活动时间是否冲突,时间不冲突,则标记该空闲时间段,说明该空闲时间段已有部门活动,在之后的部门匹配中,该学生已不可再加入在这个时间段有活动的部门。时间冲突,则该次匹配不成功。在满足部门未招满和时间不冲突的情况下,则该学生匹配成功,将学生信息加入该部门结构体的数据类型vector
3.重复上述步骤,直至每个学生的部门志愿都被判定过。
以下是绩点优先算法代码:
void initialization::GraFirst()
{
sort(stu, stu+301, cmp_max_gpa);
for (int j = 0; j <= 4; j++)
{
for (int i = 1; i <= 300; i++)
{
int temp = stu[i].voluntary[j];
if (dep[temp].numrest <= 0) continue;
int mark = time_is_ok(i, temp);
if (mark == -1) continue;
else
{
stu[i].mark_freetime[mark] = true;
dep[temp].res.push_back(stu[i]);
stu[i].admission_dep.push_back(temp);
if (dep[temp].numrest > 0)
dep[temp].numrest--; //剩余席位-1
}
}
}
}
接下来说说兴趣优先算法:
绩点优先算法按照“学生兴趣优先、遵循志愿顺序”的原则进行匹配。
兴趣优先算法:
1.学生按照绩点默认排序,即按照编号从小到大排序。然后300个学生按照志愿依次匹配。
2.对于学生的每一个志愿,算法每次判定该部门是否已招满,若该部门已招满新部员,则此次匹配不成功。继续判定下一个学生的同一顺序的志愿。若该部门未招满部员,则继续判定学生的空闲时间和部门活动时间是否冲突,时间不冲突,则标记该空闲时间段,说明该空闲时间段已有部门活动,在之后的部门匹配中,该学生已不可再加入在这个时间段有活动的部门。时间冲突,则该次匹配不成功。在满足部门未招满和时间不冲突的情况下,若学生兴趣和部门标签匹配则该学生匹配成功,否则匹配失败。匹配成功后,将学生信息加入该部门结构体的数据类型vector
3.重复上述步骤,直至每个学生的部门志愿都被判定过。
void initialization::InterestFirst()
{
for (int j = 0; j <= 4; j++)
{
for (int i = 1; i <= 300; i++)
{
int temp = stu[i].voluntary[j];
if (dep[temp].numrest <= 0) continue;
int mark = time_is_ok(i, temp);
if (mark == -1) continue;
else if(InterestMatching(i,temp))
{
stu[i].mark_freetime[mark] = true;
dep[temp].res.push_back(stu[i]);
stu[i].admission_dep.push_back(temp);
if (dep[temp].numrest > 0)
dep[temp].numrest--; //剩余席位-1
}
}
}
}
输入输出的格式
采用了文本文件输入
代码遵循的规范
- 变量名定义做到见其名知其意,有实际含义
- 代码标有注释,便于阅读和理解
- 代码格式化对齐,阅读方便。
例如:student 结构体中的数据定义
struct student
{
int sid; // 学生编号
double gpa; // 学生绩点
string interest[12];//兴趣标签
int interest_cnt;//兴趣标签个数
int voluntary[5]; //学生志愿部门
int start_freetime[10][2];//学生空闲开始时间
int end_freetime[10][2];//学生空闲结束时间
int freetime_cnt;//学生空闲时间个数
vector<int>admission_dep;//加入的部门编号
bool mark_freetime[10];//标记某个空闲时间段是否已有部门活动
} stu[301];
结果分析评价
程序通过命令行进行测试,不同的输入参数代表程序将采用不同的优先算法。
| 参数名称 | 参数意义 | 用法实例 |
|---|---|---|
| -GF | GraFirst,采用绩点优先算法 | SecondPairWork.exe -GF |
| -IF | InterestFirst,采用兴趣优先算法 | SecondPairWork.exe -IF |
| 优先条件 | 匹配学生个数 | 未匹配学生个数 | 实际耗时(s) | 文件输出路径 |
|---|---|---|---|---|
| 绩点优先 | 238 | 62 | 2.868 | output_GF.txt |
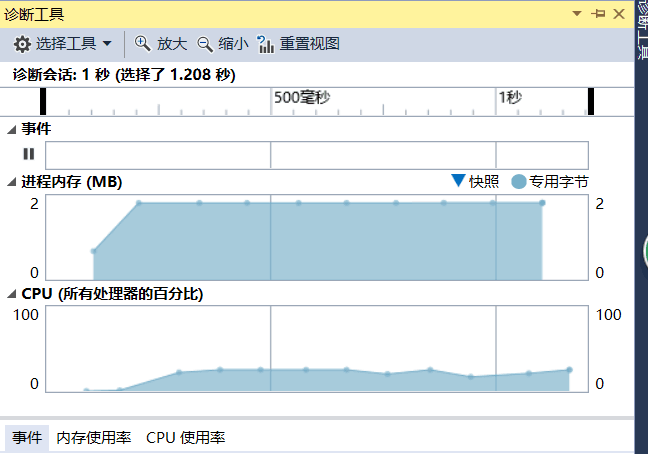
| 兴趣优先 | 214 | 86 | 1.208 | output_IF.txt |

结对感受
第一次尝试结对编码,体验还是不错的。感受到团队的力量之强大。问题在谈论交流中变得豁然开朗。有了明确的分工,两个人先各司其职,最后进行整合。
分工:队友主要负责输入import的生成,我主要负责优先算法的实现。代码测试则是共同完成。
队友闪光点:在学生的空闲时间应该用什么数据类型表示时,自己感觉用字符型或日期型在时间冲突判定时会很麻烦,想法思路陷入死胡同,和队友讨论交流后,队友给力的提出一个新想法,将每一个时间段映射成int数据,这在时间冲突判定时就会变得简单,在这里给队友一个大大的赞!

