
完整代码
点击查看代码
import torch
import numpy as np
import torch.nn as nn
import math
import torch.nn.functional as F
# multi-head attention
class selfAttention(nn.Module):
def __init__(self, num_attention_heads, input_size, d_model, Q=None, K=None, V=None):
super(selfAttention, self).__init__()
if d_model % num_attention_heads != 0:
raise ValueError(
"the hidden size %d is not a multiple of the number of attention heads"
"%d" % (d_model, num_attention_heads)
)
self.num_attention_heads = num_attention_heads
self.d_k = int(d_model / num_attention_heads) # dk = dv (Q, K, V 的最后一个维度)
self.all_head_size = d_model # 所有头加起来的总维度大小
self.key_layer = nn.Linear(input_size, d_model,
bias=False) # input_size:输入向量的最后一个的维度,d_model:输出的维度,它会被分割成多个注意力头
self.query_layer = nn.Linear(input_size, d_model, bias=False)
self.value_layer = nn.Linear(input_size, d_model, bias=False)
self.Q = Q
self.K = K
self.V = V
def trans_to_multiple_heads(self, x):
new_size = x.size()[: -1] + (self.num_attention_heads, self.d_k)
x = x.view(new_size)
return x.permute(0, 2, 1, 3)
def forward(self, x):
if self.Q is None or self.K is None or self.V is None:
key = self.key_layer(x) # [batch_size, seq_len, d_model]
query = self.query_layer(x) # [batch_size, seq_len, d_model]
value = self.value_layer(x) # [batch_size, seq_len, d_model]
else:
key = self.K
query = self.Q
value = self.V
key_heads = self.trans_to_multiple_heads(
key) # [batch_size, num_attention_heads, seq_len, d_k]
query_heads = self.trans_to_multiple_heads(
query) # [batch_size, num_attention_heads, seq_len, d_k]
value_heads = self.trans_to_multiple_heads(
value) # [batch_size, num_attention_heads, seq_len, d_k]
attention_scores_before_normalize = torch.matmul(
query_heads, key_heads.permute(0, 1, 3, 2)) # [batch_size, num_attention_heads, seq_len, seq_len]
attention_scores = attention_scores_before_normalize / math.sqrt(self.d_k)
attention_probs = F.softmax(attention_scores, dim=-1)
result = torch.matmul(attention_probs,
value_heads) # [batch_size, num_attention_heads, seq_len, d_k] 与 QKV 等大小
result = result.permute(0, 2, 1, 3).contiguous() # [batch_size, seq_len, num_attention_heads, d_k]
new_size = result.size()[: -2] + (self.all_head_size,) # [batch_size, seq_len, d_model]
result = result.view(*new_size)
print("attention_scores(before normalize) shape: ", attention_scores_before_normalize.shape)
print("dk", self.d_k)
print("attention_scores(after normalize) shape: ", attention_scores.shape)
print("attention_probs shape(after softmax): ", attention_probs.shape)
print("result shape: ", result.shape)
return result
if __name__ == "__main__":
# batch_size = 1
# seq_len = 4
# x_size = 16
# input_size = 16
# d_model = 16
#
# num_attention_heads = 1
#
# X = torch.Tensor(
# [[0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0], # X1
# [0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 1, 1, 0], # X2
# [0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0], # X3
# [0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 1, 1, 0]] # X4
# ) # [batch_size, seq_len, x_size]
# x = X.view(batch_size, seq_len, x_size)
# print("x: ", x)
#
# # embedding
# i = torch.eye(d_model) # 单位阵
# w = torch.Tensor(
# [[1, 0, 0, 0],
# [0, 1, 0, 0],
# [0, 0, 1, 0],
# [0, 0, 0, 1], ]
# ) # [x_size, input_size]
# w = i
# w = w.view(x_size, input_size)
#
# X = torch.matmul(X, w) # [batch_size, seq_len, input_size]
# print("a: ", X)
#
# # QKV
# wq = torch.Tensor(
# [[1, 0, 1],
# [1, 0, 0],
# [0, 0, 1],
# [0, 1, 1],
# ]
# )
# wk = torch.Tensor(
# [[0, 0, 1],
# [1, 1, 0],
# [0, 1, 0],
# [1, 1, 0],
# ]
# )
# wv = torch.Tensor(
# [[0, 2, 0],
# [0, 3, 0],
# [1, 0, 3],
# [1, 1, 0],
# ]
# ) # [input_size, d_model]
# wq = i
# wk = i
# wv = i
# wq = wq.view(input_size, d_model)
# wk = wk.view(input_size, d_model)
# wv = wv.view(input_size, d_model)
#
# Q = torch.matmul(X, wq) # [batch_size, seq_len, d_model]
# K = torch.matmul(X, wk) # [batch_size, seq_len, d_model]
# V = torch.matmul(X, wv) # [batch_size, seq_len, d_model]
# Q = Q.view(batch_size, seq_len, d_model)
# K = K.view(batch_size, seq_len, d_model)
# V = V.view(batch_size, seq_len, d_model)
# print("Q: ", Q, "\nK: ", K, "\nV: ", V)
#
# # self attention
# attention = selfAttention(num_attention_heads=num_attention_heads, # num_attention_heads:注意力头的数量
# input_size=input_size, # input_size:输入向量的最后一个的维度
# d_model=d_model, # d_model:输出的维度,它会被分割成多个注意力头
# Q=Q, K=K, V=V
# )
# result = attention.forward(X)
# print("result: ", result)
# print("result shape: ", result.shape) # [batch_size, seq_len, d_model]
features = torch.rand((32, 20, 10))
attention = selfAttention(2, 10, 16)
result = attention.forward(features)
print(result.shape)
原理简介
Self-Attention Layer 基本结构如下:



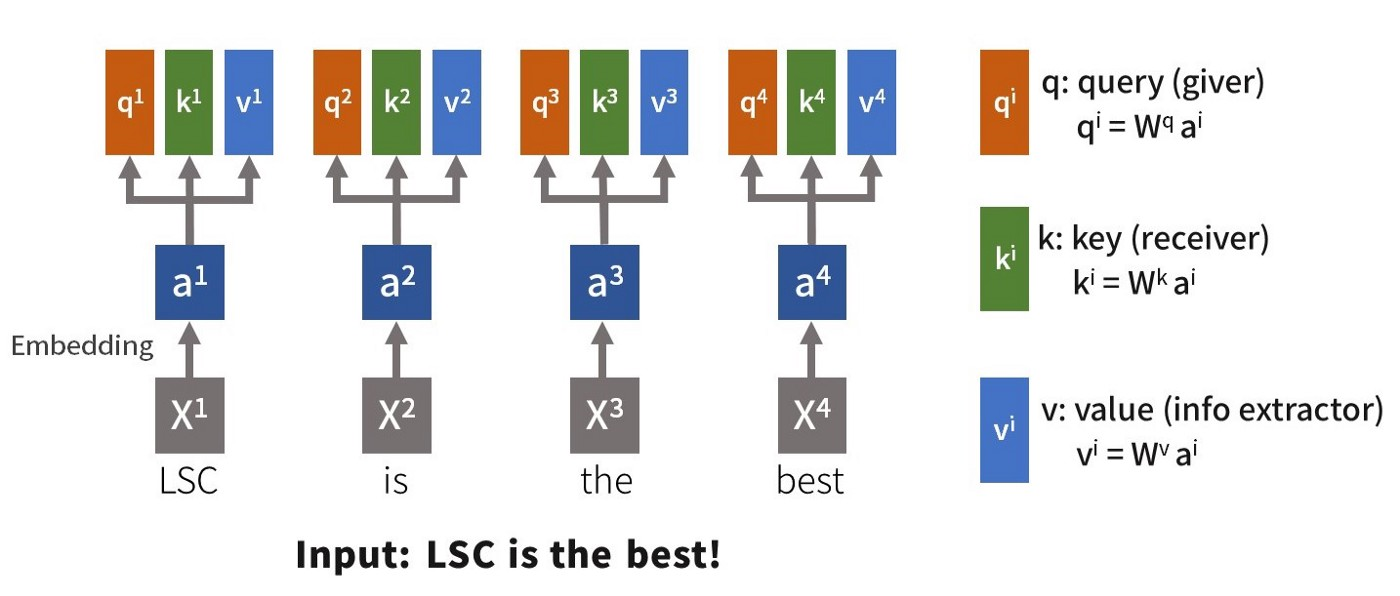
1. 首先对于每个输入 \(\boldsymbol{x}\),经过 Embedding 层对每个输入进行编码得到 \(\boldsymbol{a_1,a_2,a_3,a_4}\)
batch_size = 1
seq_len = 3
x_size = 4
input_size = 4 # embedding size
hidden_size = 3 # (q,k,v) size
num_attention_heads = 1
X = torch.Tensor(
[[1,0,1,0], # X1
[0,2,0,2], # X2
[1,1,1,1]] # X3
) # [batch_size, seq_len, x_size]
x = X.view(batch_size, seq_len, x_size)
print("x: ", x)
w = torch.Tensor(
[[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1], ]
) # [x_size, input_size]
w = w.view(x_size, input_size)
X = torch.matmul(X, w) # [batch_size, seq_len, input_size]
print("a: ", X)
x: tensor([[[1., 0., 1., 0.],
[0., 2., 0., 2.],
[1., 1., 1., 1.]]])
a: tensor([[1., 0., 1., 0.],
[0., 2., 0., 2.],
[1., 1., 1., 1.]])
2. 然后将输入特征经过三个全连接层分别得到 Query,Key,Value:
\(\boldsymbol{q^i(Query) = W^q a^i}\)
\(\boldsymbol{k^i(Key) = W^k a^i}\)
\(\boldsymbol{v^i(Value) = W^v a^i}\)
\(W^q\),\(W^v\),\(W^v\) 先随机初始化,由网络迭代训练而来。
wq = torch.Tensor(
[[1, 0, 1],
[1, 0, 0],
[0, 0, 1],
[0, 1, 1],
]
)
wk = torch.Tensor(
[[0, 0, 1],
[1, 1, 0],
[0, 1, 0],
[1, 1, 0],
]
)
wv = torch.Tensor(
[[0, 2, 0],
[0, 3, 0],
[1, 0, 3],
[1, 1, 0],
]
) # [input_size, hidden_size]
wq = wq.view(input_size, hidden_size)
wk = wk.view(input_size, hidden_size)
wv = wv.view(input_size, hidden_size)
Q = torch.matmul(X, wq) # [batch_size, seq_len, hidden_size]
K = torch.matmul(X, wk) # [batch_size, seq_len, hidden_size]
V = torch.matmul(X, wv) # [batch_size, seq_len, hidden_size]
Q = Q.view(batch_size, seq_len, hidden_size)
K = K.view(batch_size, seq_len, hidden_size)
V = V.view(batch_size, seq_len, hidden_size)
print("Q: ", Q, "\nK: ", K, "\nV: ", V)
Q: tensor([[[1., 0., 2.],
[2., 2., 2.],
[2., 1., 3.]]])
K: tensor([[[0., 1., 1.],
[4., 4., 0.],
[2., 3., 1.]]])
V: tensor([[[1., 2., 3.],
[2., 8., 0.],
[2., 6., 3.]]])
3. 计算注意力。注意力矩阵是由 Query 和 Key 计算得到,方式由许多种,如点积、缩放点积等。Value 可以看作是信息提取器,将根据单词的注意力提取一个唯一的值,也即某个特征有多少成分被提取出来。
\[Attention(Q,K,V)=softmax(QK^T/\sqrt{d_k})V
\]
# attention
# Q k^T / sqrt(dk)
scores = torch.matmul(Q, K.transpose(-1, -2)) / math.sqrt(hidden_size) # [batch_size, seq_len, seq_len]
print("scores: \n", scores)
# softmax
attn_weights = F.softmax(scores, dim=-1) # [batch_size, seq_len, seq_len]
print("attn_weights: \n", attn_weights)
# weighted sum
attn_output = torch.matmul(attn_weights, V) # [batch_size, seq_len, hidden_size]
print("attn_output: \n", attn_output)
scores:
tensor([[[1.1547, 2.3094, 2.3094],
[2.3094, 9.2376, 6.9282],
[2.3094, 6.9282, 5.7735]]])
attn_weights:
tensor([[[1.3613e-01, 4.3194e-01, 4.3194e-01],
[8.9045e-04, 9.0884e-01, 9.0267e-02],
[7.4449e-03, 7.5471e-01, 2.3785e-01]]])
attn_output:
tensor([[[1.8639, 6.3194, 1.7042],
[1.9991, 7.8141, 0.2735],
[1.9926, 7.4796, 0.7359]]])
4. 多头注意力
在上述的 self-attention 中,我们最终只得到一个注意力矩阵,也就是说这个注意力矩阵所关注的信息只偏句子之间的一种关系,但是在时序序列中,往往特征之间不止一种关系,所以我们要提取多个注意力矩阵,这样可以捕获更多的信息,这种注意力机制也就是 多头注意力机制(Multi-Heads)。
\[MultiHead(Q,K,V)=Concat(head_1,...,head_h)W^O
\]
\[head_i=Attention(QW^Q_i,KW^K_i,VW^V_i)
\]
其中,\(W^Q_i\in\mathbb{R}^{d_{model}\times{d_k}}\) , \(W^K_i\in\mathbb{R}^{d_{model}\times{d_k}}\) , \(W^V_i\in\mathbb{R}^{d_{model}\times{d_v}}\) , \(W^O\in\mathbb{R}^{h{d_v}\times{d_{model}}}\)
# multi-head attention
class selfAttention(nn.Module):
def __init__(self, num_attention_heads, input_size, d_model, Q=None, K=None, V=None):
super(selfAttention, self).__init__()
if d_model % num_attention_heads != 0:
raise ValueError(
"the hidden size %d is not a multiple of the number of attention heads"
"%d" % (d_model, num_attention_heads)
)
self.num_attention_heads = num_attention_heads
self.d_k = int(d_model / num_attention_heads) # dk = dv (Q, K, V 的最后一个维度)
self.all_head_size = d_model # 所有头加起来的总维度大小
self.key_layer = nn.Linear(input_size, d_model, bias=False) # input_size:输入向量的最后一个的维度,d_model:输出的维度,它会被分割成多个注意力头
self.query_layer = nn.Linear(input_size, d_model, bias=False)
self.value_layer = nn.Linear(input_size, d_model, bias=False)
self.Q = Q
self.K = K
self.V = V
def trans_to_multiple_heads(self, x):
new_size = x.size()[: -1] + (self.num_attention_heads, self.d_k)
x = x.view(new_size)
return x.permute(0, 2, 1, 3)
def forward(self, x):
if self.Q is None or self.K is None or self.V is None:
key = self.key_layer(x) # [batch_size, seq_len, d_model]
query = self.query_layer(x) # [batch_size, seq_len, d_model]
value = self.value_layer(x) # [batch_size, seq_len, d_model]
else:
key = self.K
query = self.Q
value = self.V
key_heads = self.trans_to_multiple_heads(
key) # [batch_size, num_attention_heads, seq_len, d_k]
query_heads = self.trans_to_multiple_heads(
query) # [batch_size, num_attention_heads, seq_len, d_k]
value_heads = self.trans_to_multiple_heads(
value) # [batch_size, num_attention_heads, seq_len, d_k]
attention_scores_before_normalize = torch.matmul(
query_heads, key_heads.permute(0, 1, 3, 2)) # [batch_size, num_attention_heads, seq_len, seq_len]
attention_scores = attention_scores_before_normalize / math.sqrt(self.d_k)
attention_probs = F.softmax(attention_scores, dim=-1)
result = torch.matmul(attention_probs,
value_heads) # [batch_size, num_attention_heads, seq_len, d_k] 与 QKV 等大小
result = result.permute(0, 2, 1, 3).contiguous() # [batch_size, seq_len, num_attention_heads, d_k]
new_size = result.size()[: -2] + (self.all_head_size,) # [batch_size, seq_len, d_model]
result = result.view(*new_size)
print("attention_scores(before normalize) shape: ", attention_scores_before_normalize.shape)
print("dk", self.d_k)
print("attention_scores(after normalize) shape: ", attention_scores.shape)
print("attention_probs shape(after softmax): ", attention_probs.shape)
print("result shape: ", result.shape)
return result
# 随机输入一个 [batch, seq_len, input] 的向量测试一下
# 结果应该是 [batch_size, seq_len, d_model] 的tensor
x = torch.rand((32, 20, 10))
attention = selfAttention(2, 10, 16)
result = attention.forward(x)
print(result.shape) # [32, 20, 16]: [batch_size, seq_len, d_model]
attention_scores(before normalize) shape: torch.Size([32, 2, 20, 20])
dk 8
attention_scores(after normalize) shape: torch.Size([32, 2, 20, 20])
attention_probs shape(after softmax): torch.Size([32, 2, 20, 20])
result shape: torch.Size([32, 20, 16])
torch.Size([32, 20, 16])
可视化
# 对一幅 8*8*1 的图片进行 self-attention
# 切成 4*4 的小块,每个小块 16 个像素点,共 4 个小块
# 0, 0, 0, 0 | 0, 0, 0, 0 |
# 0, 1, 1, 0 | 1, 1, 1, 1 X1 | X2
# 0, 0, 0, 0 | 0, 0, 0, 0 |
# 0, 1, 1, 0 | 0, 1, 1, 0 |
# --------------------------- ------------------
# 0, 0, 0, 0 | 0, 0, 0, 0 |
# 0, 1, 1, 0 | 1, 1, 1, 1 X3 | X4
# 0, 0, 0, 0 | 0, 0, 0, 0 |
# 0, 1, 1, 0 | 0, 1, 1, 0 |
X = torch.Tensor(
[[0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0], # X1
[0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 1, 1, 0], # X2
[0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0], # X3
[0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 1, 1, 0]] # X4
) # [batch_size, seq_len, x_size]
batch_size = 1
seq_len = 4
x_size = 16
input_size = 16
d_model = 16
num_attention_heads = 1
x = X.view(batch_size, seq_len, x_size)
print("x: ", x)
# embedding
i = torch.eye(x_size) # 单位阵
w = i
w = w.view(x_size, input_size)
X = torch.matmul(X, w) # [batch_size, seq_len, input_size]
print("a: ", X)
# QKV
i = torch.eye(d_model) # 单位阵
wq = i
wk = i
wv = i
wq = wq.view(input_size, d_model)
wk = wk.view(input_size, d_model)
wv = wv.view(input_size, d_model)
Q = torch.matmul(X, wq) # [batch_size, seq_len, d_model]
K = torch.matmul(X, wk) # [batch_size, seq_len, d_model]
V = torch.matmul(X, wv) # [batch_size, seq_len, d_model]
Q = Q.view(batch_size, seq_len, d_model)
K = K.view(batch_size, seq_len, d_model)
V = V.view(batch_size, seq_len, d_model)
print("Q: ", Q, "\nK: ", K, "\nV: ", V)
# self attention
attention = selfAttention(num_attention_heads=num_attention_heads, # num_attention_heads:注意力头的数量
input_size=input_size, # input_size:输入向量的最后一个的维度
d_model=d_model, # d_model:输出的维度,它会被分割成多个注意力头
Q=Q, K=K, V=V
)
result = attention.forward(X)
print("result: ", result)
print("result shape: ", result.shape) # [batch_size, seq_len, d_model]

参考
https://blog.csdn.net/weixin_53598445/article/details/125009686
https://blog.csdn.net/baidu_33000721/article/details/137880166
https://www.bilibili.com/video/BV1Rz4y1g7J7
https://zhuanlan.zhihu.com/p/420820453

 浙公网安备 33010602011771号
浙公网安备 33010602011771号