

CoType: Joint Extraction of Typed Entities and Relations with Knowledge Bases
CoType: 基于知识库的类型化实体和关系联合抽取
Author(s): Xiang Ren† Zeqiu Wu† Wenqi He† Meng Qu† Clare R. Voss‡ Heng Ji♯ Tarek F. Abdelzaher† Jiawei Han†
Ren X, Wu Z, He W, et al. Cotype: Joint extraction of typed entities and relations with knowledge bases[C]//Proceedings of the 26th international conference on world wide web. 2017: 1015-1024.
| 内容 | 描述 | |
|---|---|---|
| 论文信息 | - 论文标题:CoType: 基于知识库的类型化实体和关系联合抽取 CoType: Joint Extraction of Typed Entities and Relations with Knowledge Bases |
- 作者:Ren X, Wu Z, He W, et al. - 发表日期:2017 - 期刊或会议名称:WWW |
| 摘要概要 | 本文研究了 从知识库中 获得标记数据的类型化实体和关系的联合提取 (即远程监督)。提出了一个新领域的独立框架,称为 COTYPE,它运行一个数据驱动的文本分割算法来提取实体,并将实体、关系、文本特征和类型标签联合嵌入到两个低维空间(分别用于实体和关系),其中,在每个空间中,类型相近的对象有相似的表示。然后使用这些学习过的嵌入,估计测试提及的类型(不可链接)。 提出了一个联合优化问题,从文本语料库和知识库中学习嵌入,对带噪声标注的数据采用了一种新的部分标签损失函数,并引入了一个对象“翻译”函数来捕获实体之间的交叉约束和相互关系。 |
实验:在三个公共数据集上进行的实验证明了COTYPE在不同领域(如新闻、生物医学)的有效性,与第二好的方法相比,其F1得分平均提高了25% 主要研究问题: 独立领域的文本 类型化实体和关系的联合提取与远程监督: domain-independent, joint extraction of typed entities and relations in text with distant supervision. |
| 主要贡献 | 1. 提出了一个远程监督模型COTYPE 2. 提出了一个领域无关的文本分割算法用于抽取实体 3. 提出了一个联合嵌入的代价函数融合mention-type association, mention-feature co-occurrence, entity-relation cross-constraints 4. 实验提升了state-of-the-art的效果 |
|
| 方法 | 利用局部标签学习 使用从提及的本地上下文提取的文本特征 来 建模提及类型关联。它使用 基于翻译嵌入的目标 来 建模关系提及及其实体(提及)参数之间的相互类型依赖关系。 整个模型分为四个部分: 在训练语料上运行基于POS的文本切割算法,得到候选entity mention 生成relation mention,构造其元组表示 将两个mention以及文本特征、实体类别标签全部嵌入两个空间之中(实体和关系分别构建一个空间) 利用嵌入的空间 预测 正确的关系对应 三个假设: 假设一 (MENTION-FEATURE CO-OCCURRENCE): 对于两个entity mention,如果它们共享很多的文本特征,那么它们更可能具有相似的类别(在低维空间更接近),反之亦然 假设二 (PARTIAL-LABEL ASSOCIATION): 一个relation mention在低维空间应该同他最可能的候选类别更近, 根据这一假设,我们假定r为一个d维向量,代表关系类别在低维空间的表示,那么z和r的相似程度通过点积的方式呈现,我们拓展最大边界损失用来对每一个relation mention定义一个类别损失,通过最小化损失来得到最优 假设三 (ENTITY-RELATION INTERACTION):对于一个relation mention z={m1,m2,s},m1的嵌入向量应该近似于m2的嵌入向量加上z的词嵌入向量,这一假设类似于表示学习的思想。 |
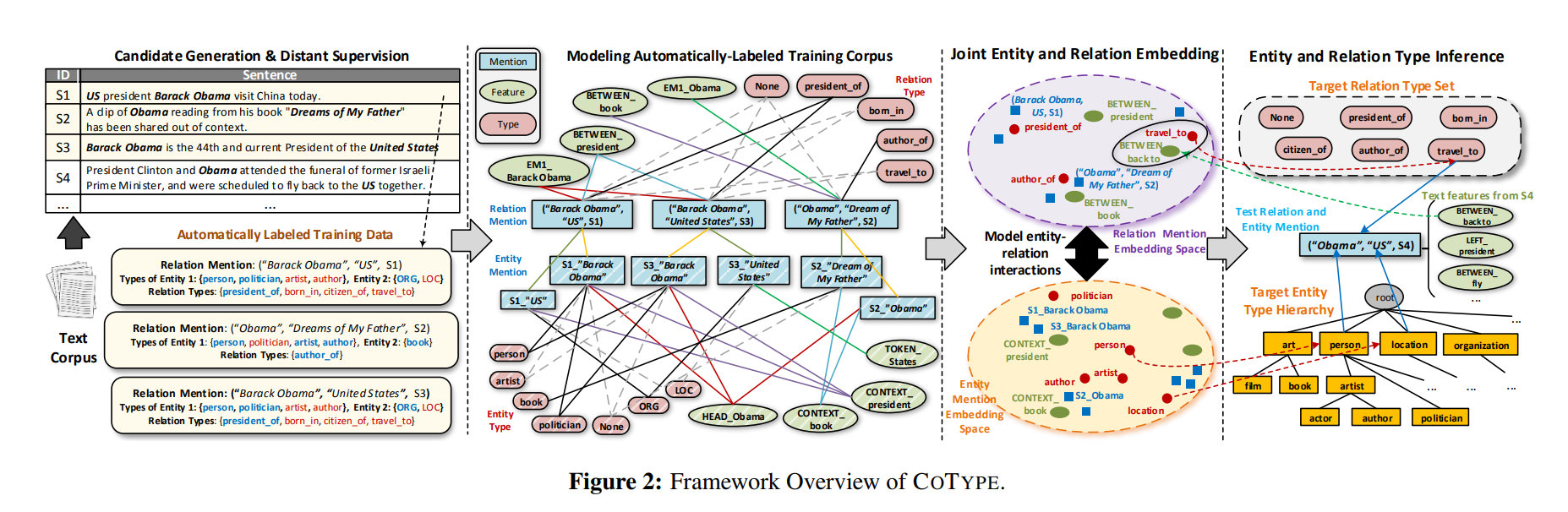 1. Candidate Generation:Entity Mention Detection、Relation Mention Generation、Text Feature Extraction 2. Joint Entity and Relation Embedding: 将可链接关系、可链接实体、实体和关系类型标签、文本特征嵌入到d维关系向量空间和d维实体向量空间 联合优化 3. Model Learning and Type Inference: 在进行推断的过程中,对于关系类别,采用最近邻的方式查找,对于实体的类别,采用自顶向下的方式查找 |
| 实验设计 | - 数据:(1)NYT;(2)Wiki-KBP;(3)BioInfer; - 论文中的主要结果和发现: Relation Extraction: 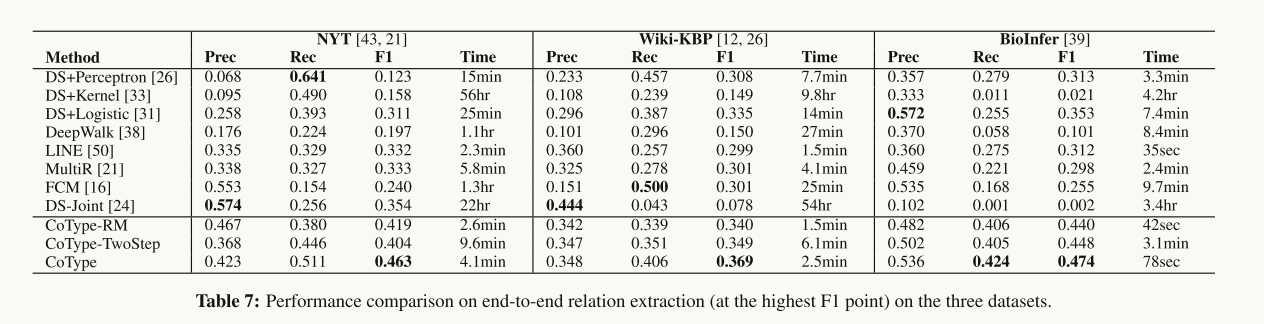 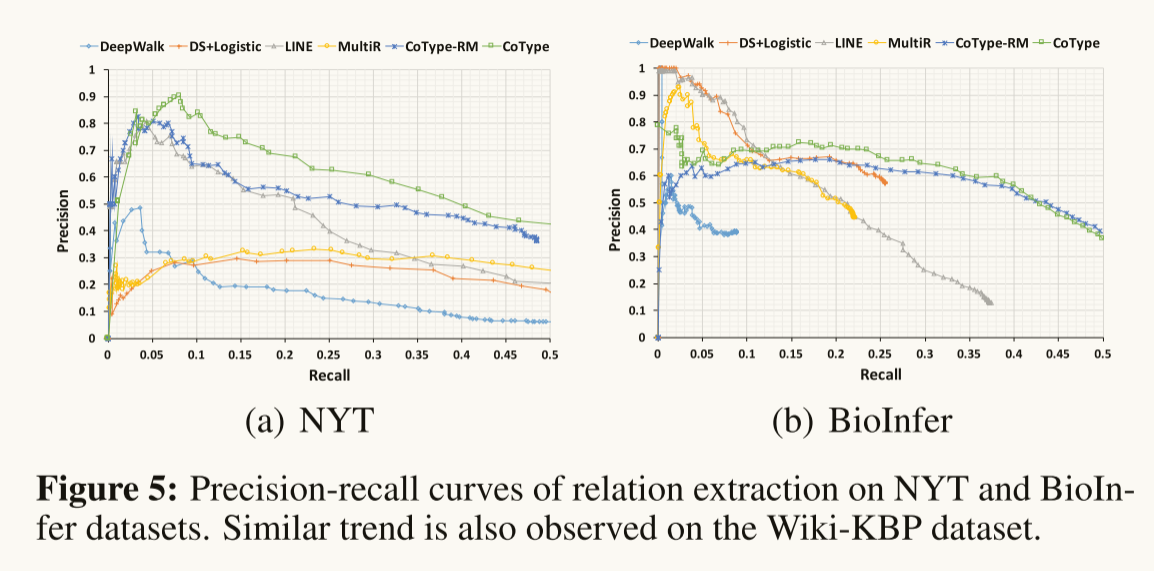 |
Entity Recognition and Typing: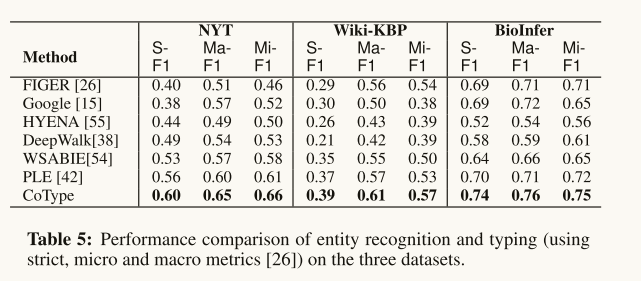 Relation Classification: Relation Classification: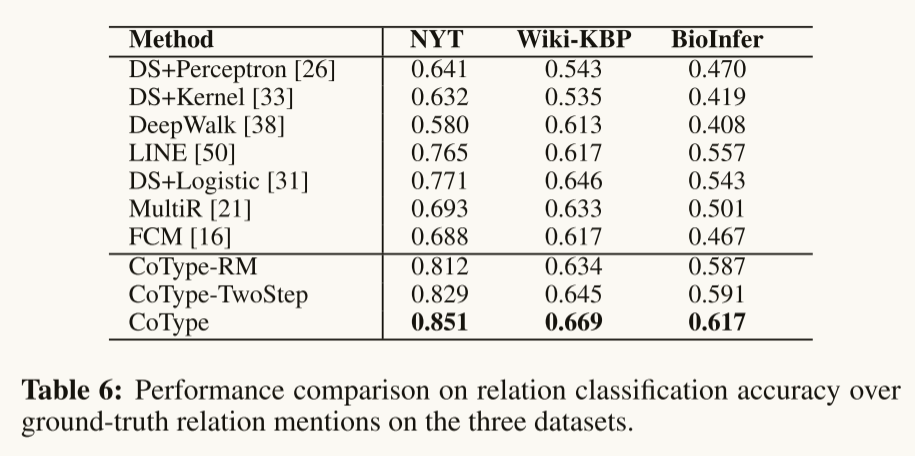 |
| 结论 | 本文研究了领域无关、类型化实体的联合提取以及文本中远程监控的关系。提出的CoType框架用领域无关的分割算法来挖掘实体提及,并将联合实体和关联提及的问题作为全局嵌入问题。我们设计了一个噪声鲁棒目标来建模带噪声的类型标签,并捕获实体与关系之间的相互依赖关系。 | |
| 个人评价 | CoType要解决的任务是实现实体和关系的联合抽取,传统的方法会将这两个任务独立处理,先进行实体识别,然后进行关系提取。而这样的处理方法会导致误差传播,所以就开始有很多学者开始研究将这两个任务联合处理。这篇论文也是出于这样的考虑进行联合抽取,同时结合远程监督的思想。 在生成Entity Mention时用到与领域无关的分词算法(domain-agnostic text segmentation)可以缓解目前的领域依赖问题。本文提出了一个联合优化问题,采用了三个假设 设计损失函数,在实验部分证明了采用这些假设可以有效改进实体和关系抽取的精度。 |
文中对于如何利用知识库的信息解释得比较简略,看完不太能理解是怎么利用知识库信息的。 自动标注训练语料库的步骤是否对结果有较大的影响,如何证明自动标注的语料库能对模型训练起到作用呢 本文的模型非常复杂,实验中对各个模块的功能分析不够详细,体现不出各个模块的作用。 本文算法实现了同时输出实体类型的embedding和关系类型的embedding,这两个产物互相影响,但是在实验部分,仅仅和其他单独进行NER任务的模型进行比较,似乎有失偏颇。 |
ABSTRACT
从文本中提取实体和关系对于理解海量文本语料库具有重要意义。传统的实体关系抽取系统主要依赖人工标注语料库进行训练,采用增量式pipeline。然而这样的系统需要额外的专业知识才能移植到一个新的领域,并且容易出现错误。
在本文中,我们研究了 从知识库中 启发式地获得标记数据的类型化实体和关系的联合提取 (即远程监督)。由于我们通过远程监督进行类型标记的算法是上下文无关的,因此带噪声训练数据给任务带来了的挑战。我们提出了一个新领域的独立框架,称为 COTYPE,它运行一个数据驱动的文本分割算法来提取实体,并将实体、关系、文本特征和类型标签联合嵌入到两个低维空间(分别用于实体和关系),其中,在每个空间中,类型相近的对象有相似的表示。然后,COTYPE使用这些学习过的嵌入,估计测试提及的类型(不可链接)。
我们提出了一个联合优化问题,从文本语料库和知识库中学习嵌入,对带噪声标注的数据采用了一种新的部分标签损失函数,并引入了一个对象“翻译”函数来捕获实体之间的交叉约束和相互关系。在三个公共数据集上进行的实验证明了COTYPE在不同领域(如新闻、生物医学)的有效性,与第二好的方法相比,其F1得分平均提高了25%。
INTRODUCTION
实体及其关系的提取是理解海量文本语料库的关键。识别构成实体的文本中的片段范围,并为这些文本范围分配类型(例如,person, company),以及实体之间的关系(例如,employed_by),这些都是构建文本语料库以及进一步分析的关键。
例如,当系统发现“公司”和“产品”实体之间的“产品”关系时,它就能够回答诸如“X公司生产什么产品?”这样的问题。这些结构化的信息一旦被提取出来,就会以多种方式被使用,如信息提取中的原语、知识库填充和问答系统。传统的关系提取系统将流程划分为几个子任务,并以增量的方式解决它们(即,从文本中检测实体,标记它们的类型,然后提取它们的关系)。此类系统独立地处理子任务,因此可能会将错误传播到流程中的各个子任务。最近的研究集中在通过 联合提取方法 来捕获关系和实体参数之间的内在语言依赖来解决错误传播(例如,实体的类型有助于确定它们的关系类型,反之亦然)。
联合提取类型化实体和关系的一个主要挑战是设计一个领域无关的系统,该系统可以应用于 没有标注的 不同领域的 文本语料库。人工标注具有大量实体和关系类型的训练集代价过高,且容易出错。大规模、特定领域的文本语料库(例如,新闻、科学出版物、社交媒体内容)的迅速出现,需要的是能够联合提取目标类型的实体和关系的方法,而无需人工监督。
为了实现这一目标,大致有两种方法: 弱监督和远距离监督。弱监督依赖于一小组手工指定的种子实例(或模式),这些实例在引导学习中被应用,以识别每种类型的更多实例。远程监督通过对齐文本和知识库(KB)自动生成训练数据,典型的工作流程为:(1)检测文本中提到的实体;(2)将检测到的实体提及映射到以KB为单位的实体;(3)将其KB映射实体的所有KB类型赋给所提及的每个实体的候选类型集;(4)在每个实体提及对的候选类型集合中,分配其KB映射实体之间的所有KB关系类型。然后使用自动标注的训练语料库来推断剩余的候选实体和关系的类型。
本文研究了远程监督的类型化实体和关系的联合抽取问题。给定一个领域特定的语料库和一组来自知识库的目标实体和关系类型,我们的目标是检测文本中的关系提及(以及它们的实体参数),并在远程监督下,按照目标类型或非目标类型(None)对上下文中的每个关系进行分类*。
主要解决在远程监督的过程中面临的三大挑战:
Domain Restriction: 需要事先训练的命名实体抽取器限制了领域的扩展
Error Propagation: 实体抽取和关系抽取分开导致错误的传递累计
Label Noise: 在远程监督当中面临的标签噪声问题(远程监督假设失效问题)。
本文的联合提取任务如下:(1)设计一种与领域无关的文本分割算法来检测候选的实体,同时采用远程监控和最小的语言假设(即,假设标注词性的语料库)。(2)对关系类型与实体参数类型之间的相互约束进行建模,实现两个子任务之间的反馈。(3)模型的真实类型标签候选人类型设置为潜变量和只要“最好”的类型(逐步估计我们学习模型)少提到这个是限制相关要求与现有多标记分类器相比,认为“每一个”类型是提到相关候选人。
为了整合这些元素,我们提出了一个新的框架,COTYPE。它首先运行POS约束文本分割使用积极的例子从知识库中挖掘质量实体,并形成候选关系。然后,执行实体链接,将候选关系(实体)映射到知识库关系(实体),并获取知识库类型。我们制定了一个全局目标来联合建模(1)可链接关系(实体)和从其本地上下文提取的文本特征之间的语料库级的共现;(2)提及物与其kb映射类型标签之间的关联;(3)关系提及与实体参数之间的交互。特别地,我们设计了一个新的部分标记损失,以一种鲁棒的方式来模拟嘈杂的标记关联,并采用基于翻译的目标来捕获实体-关系的相互作用。将目标最小化会产生两个低维空间(分别表示实体和关系),其中,在每个空间中,其类型在语义上相近的对象也具有类似的表示。通过学习嵌入,我们可以有效地估计其余不可链接的关系提及及其实体参数的类型。
本文的贡献主要有以下四部分:
提出了一个远程监督模型COTYPE
提出了一个领域无关的文本分割算法用于抽取实体
提出了一个联合嵌入的代价函数融合mention-type association, mention-feature co-occurrence, entity-relation cross-constraints
实验提升了state-of-the-art的效果
BACKGROUND AND PROBLEM
输入:词性标注语料、知识库、一个层级实体类别集合、关系类别集合
Entity Mention : 在文本中表示一个实体的范围(m)
Relation Mention : 表示句子s中提及与实体提及m1和m2的关系(m1,m2,s)
Knowledge Bases: 带有一组实体的KB包含有关关系实例和实体类型的人工策划事实
Target Types:目标实体类型层次结构是一个树,其中的节点表示感兴趣的实体类型。一个实体可能有多个类型,它们共同构成给定类型层次结构中的一个类型路径(不需要以叶子结束)。
自动标注:选择在语料中可以映射到知识库当中的entity mention,为每一个关系实例(在同一个句子当中出现的两个entity mention)构造一个元组表示
Problem Description:将D中每个句子中的实体提及(来自集合M)进行配对,生成一个候选关系提及集合Z。
Non-goals:这项工作依赖于实体链接系统[29]来提供消歧功能,但我们在这里不解决它们的限制(例如,错误映射的KB实体引入的标签噪声)。我们还假设给出了人工策划的目标类型层次结构(生成类型层次结构超出了本研究的范围)。
THE COTYPE FRAMEWORK
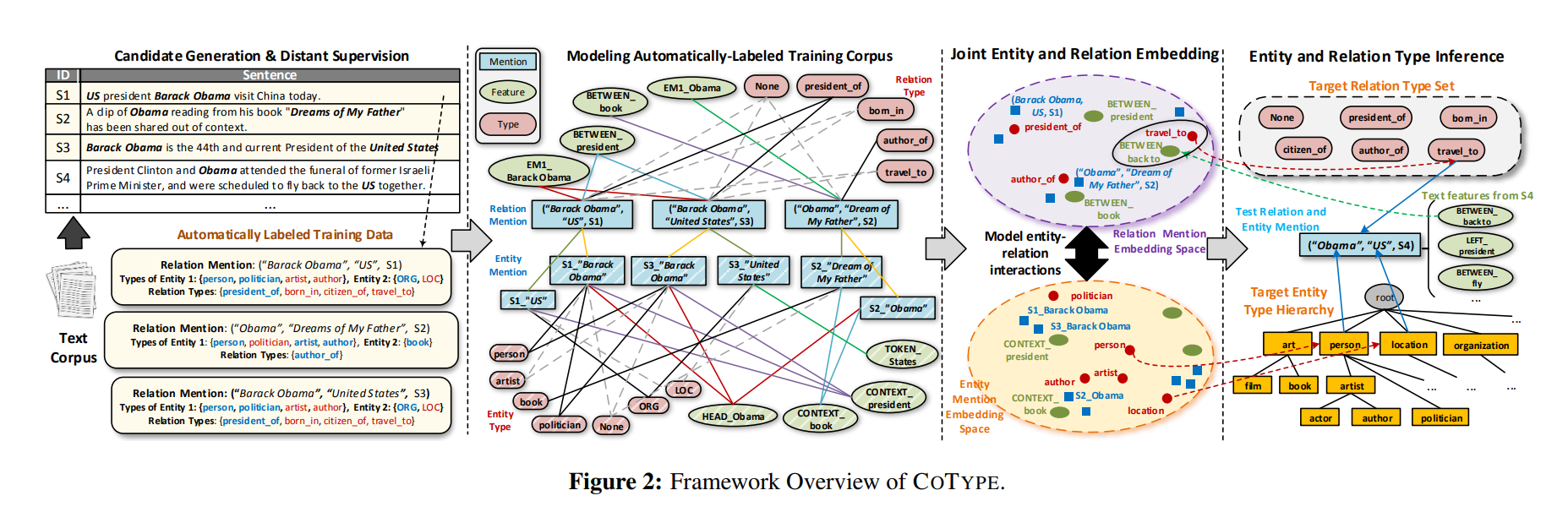
联合提取任务提出了两个独特的挑战。
首先,可链接的实体(关系)提及和它们的kb映射实体(关系)之间的远程监控中的类型关联是上下文无关的——候选类型集包含“假”类型。监督学习可能会产生偏向于错误类型标签的模型。
其次,关系提及和它们的实体参数之间存在依赖关系(例如,类型相关)。现有的系统将任务描述为级联监督学习问题,可能会出现错误传播。
我们的解决方案将类型预测任务转换为弱监督学习(在上下文中对提及和其候选类型之间的关联进行建模),并基于大型语料库中的冗余文本信号,使用关系学习联合捕获提及及其实体提及参数之间的交互。
具体来说,COTYPE利用局部标签学习 使用从提及的本地上下文提取的文本特征 来 建模提及类型关联。它使用 基于翻译嵌入的目标 来 建模关系提及及其实体(提及)参数之间的相互类型依赖关系。
整个模型分为四个部分:
- 在训练语料上运行基于POS的文本切割算法,得到候选entity mention
- 生成relation mention,构造其元组表示
- 将两个mention以及文本特征、实体类别标签全部嵌入两个空间之中(实体和关系分别构建一个空间)
- 利用嵌入的空间预测正确的关系对应
Candidate Generation:
本部分共分为三个部分:Entity Mention Detection、Relation Mention Generation、Text Feature Extraction
Entity Mention Detection:这一部分主要是文献 Mining quality phrases from massive text corpora(SIGMOD 2015)的扩展 通过计算切片质量函数来衡量这个片段是否有多大可能是一个entity mention,这个质量函数由短语质量和POS质量组合而成,利用 自动标记的语料库DL 当中的数据来估计这个函数的参数。 工作流程如下:
(1)对于DL中的样例,挖掘他们的频繁共同模板,包括词性模版和词性模版
(2)从语料级别的一致性和句子级别的词性特征抽取特征训练两个随机森林分类器,用于评估候选的短语模板和词性模板
(3)找到切片质量函数得分最高的片段
(4)计算修正特征,不断迭代2-4步直到收敛
切片评估函数的形式为
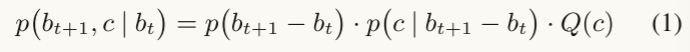
第一项为切片长度的先验概率,第二项为给定切片长度是一个好的切片的概率(需要估计),第三项为质量函数,在本文中,质量函数为短语质量和POS质量的平均相加
Relation Mention Generation: 对于在同一句话的两个entity mention,构建两个关系实例(m1,m2,s)和(m2,m1,s),如果远程监督可以使用,那么直接构造,再抽取30%的无法连接到知识库的mention作为负例
Text Feature Extraction:为了捕获关系(或实体)提及的浅层语法和分布语义,我们在pos标记的语料库中从提及本身(例如head token)和其上下文(例如bigram)提取各种词汇特征。

Joint Entity and Relation Embedding
本节给出了将 可链接关系、可链接实体、实体和关系类型标签、文本特征 嵌入到d维关系向量空间和d维实体向量空间的联合优化问题。在每个空间中,类型接近的对象应该具有相似的表示(例如,参见图2中的第3个col)。
提出了一个新的全局目标,将基于边际的秩损失用于建模 noisy mention-type
associations,并利用second-order proximity idea来建模corpus-level mention-feature co-occurrences。为了捕捉实体-关系的交互,我们采用了一种translation-based embedding loss来桥接实体提及和关系提及的向量空间。
Modeling Types of Relation Mentions: 在此阶段建模中,考虑mention-feature co-occurrences and mention-type associations这两部分监督信息
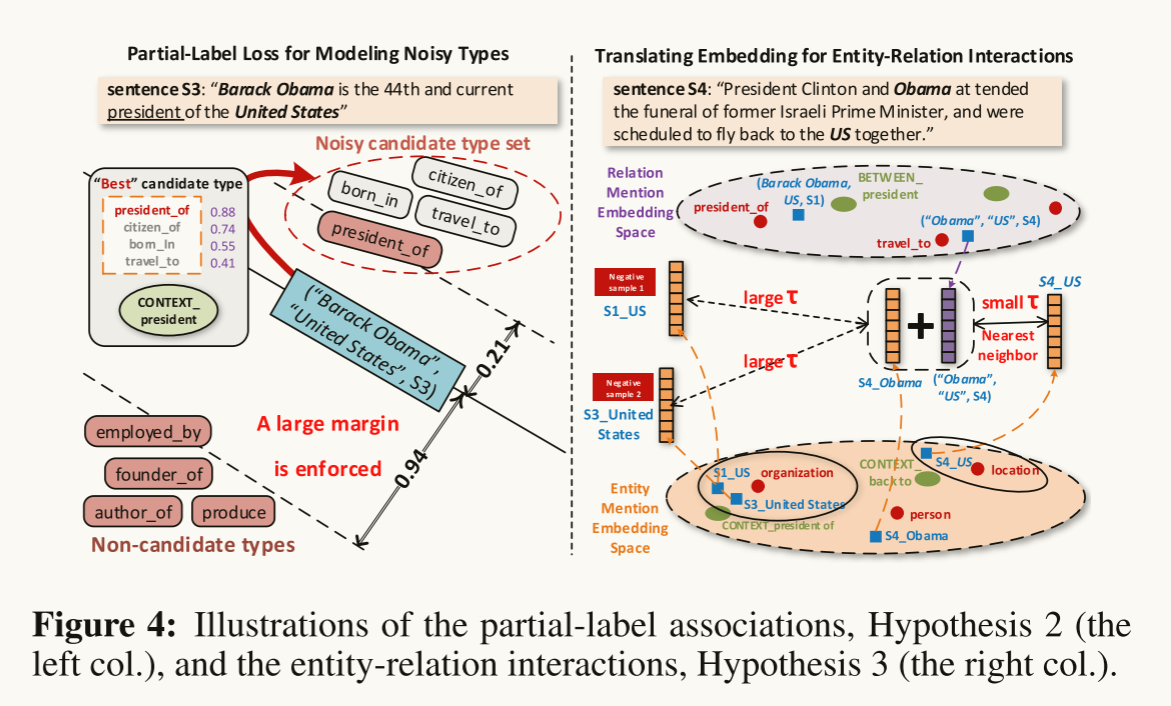
假设一 (MENTION-FEATURE CO-OCCURRENCE): 对于两个entity mention,如果它们共享很多的文本特征,那么它们更可能具有相似的类别(在低维空间更接近),反之亦然
假设二 (PARTIAL-LABEL ASSOCIATION): 一个relation mention在低维空间应该同他最可能的候选类别更近, 根据这一假设,我们假定r为一个d维向量,代表关系类别在低维空间的表示,那么z和r的相似程度通过点积的方式呈现,我们拓展最大边界损失用来对每一个relation mention定义一个类别损失,通过最小化损失来得到最优
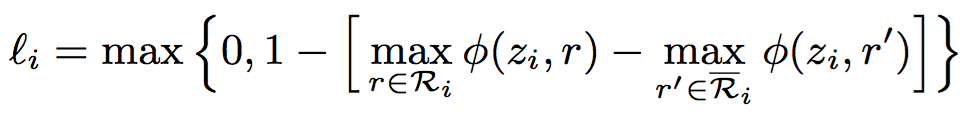
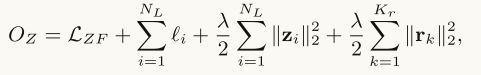
Modeling Types of Entity Mentions: 类似于对关系提及的类型进行建模,我们按照假设1和2对实体提及的类型进行建模。
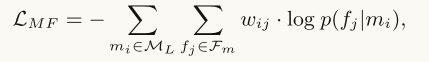
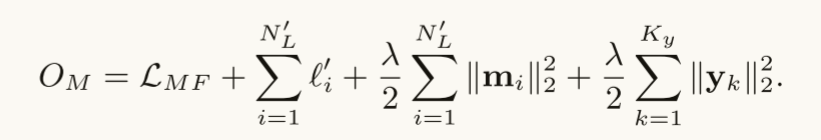
Modeling Entity-Relation Interactions: 在现实中,一个关系提到z = (m1,m2, s)和它的实体提到论证m1和m2之间存在着不同的相互作用。一种主要的交互是这些对象的关系和实体类型之间的相关性——提到的两个实体的实体类型为确定提到的关系的关系类型提供了很好的提示,反之亦然。例如,在图4(右列)中,知道实体提到“S4_US”是位置类型(而不是组织类型)有助于确定关系提到(“Obama”、“US”、S4)更可能是关系类型travel_to,而不是关系类型president_of或citizen_of。
假设三 (ENTITY-RELATION INTERACTION):对于一个relation mention z={m1,m2,s},m1的嵌入向量应该近似于m2的嵌入向量加上z的词嵌入向量,这一假设类似于表示学习的思想。
具体来说,我们使用ℓ-2范数为关系提及的三元组和它的两个实体提及参数(z,m1,m2)定义误差函数: τ(z) =∥m1 + z−m2∥2
当τ(z)的值很小时,表示(z,m1,m2)的嵌入向量确实捕获了类型约束。为了加强可链接关系提及(在集合ZL中)与其实体提及参数之间的小误差,我们使用基于margin-based loss来构建一个目标函数,如下所示。
A Joint Optimization Problem: 将上述三个损失函数相加,求它们的最小值
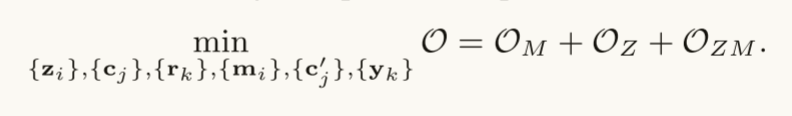
Model Learning and Type Inference
在进行推断的过程中,对于关系类别,采用最近邻的方式查找,对于实体的类别,采用自顶向下的方式查找。在查找的过程中,利用特征来表示mention,计算mention的嵌入向量同实体类别和关系类别的相似度
EXPERIMENTS
Data Preparation and Experiment Setting:
三个公开数据集(1)NYT;(2)Wiki-KBP;(3)BioInfer;
自动标注训练语料库:使用远程监督启发式地标记了NYT训练语料库,对于Wiki-KBP和BioInfer训练语料库,我们使用了DBpedia Spotlight2,将检测到的实体提到M映射到Freebase实体。然后,获得候选实体和关系类型,并构造训练数据DL。对于目标类型,我们丢弃了不能从测试数据映射到Freebase的关系/实体类型,同时在训练数据中保留Freebase实体/关系类型(在测试数据中没有找到)
Evaluation Metrics:对于实体识别,我们使用strict, micro, and macro F1 scores,来评估检测到的实体提及边界和预测的实体类型。在关系抽取评价中,我们考虑了两个设置:对于关系分类,给出了GT关系提及,不排除任何标签,我们专注于测试类型分类的准确性;在关系提取方面,我们采用了标准的Precision (P)、Recall (R)和F1 score。请注意,我们所有的评估都是句子级的(即上下文相关的)。
Performance on Entity Recognition and Typing:总的来说,COTYPE在所有三个数据集上的所有指标上都优于其他方法(例如,它在Micro-F1上比NYT数据集上的下一个最佳方法提高了8%)。这样的性能收益主要来自(1)一种更稳健的方法来建模有噪声的候选类型(与忽略标签噪声问题的监督方法和远程监督方法相比);(2)实体与关系提及以相互增强的方式联合嵌入(vs.噪声鲁棒方法PLE)。
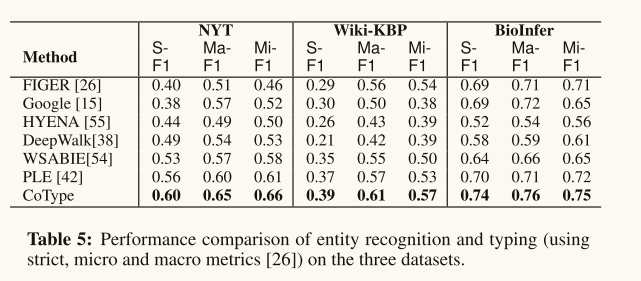
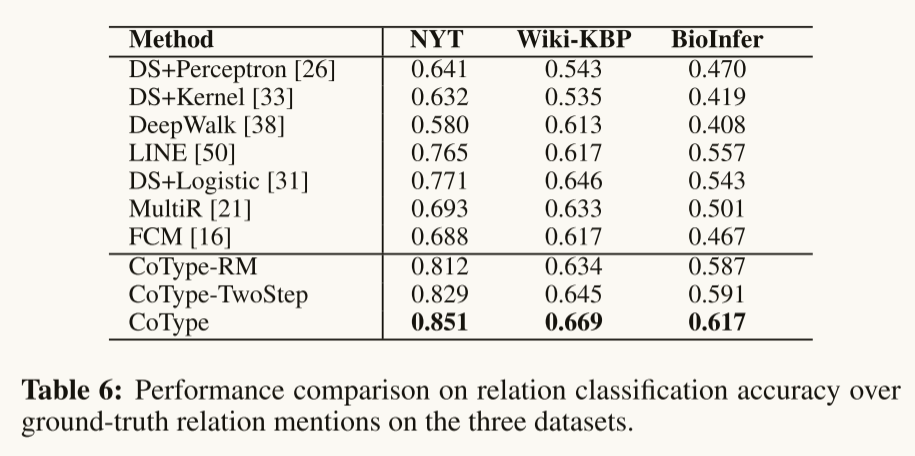
**Performance on Relation Classification: **与所有其他方法和变体相比,COTYPE获得了更高的准确性。所有比较方法(除了MultiR)在训练模型时都将DL简单地视为“完全标记”。COTYP-RM的改进验证了仔细建模标签噪声的重要性(即假设2)。将COTYPE-RM与MultiR进行比较,COTYPE-RM的优越性能证明了部分标签丢失在多实例学习中的有效性。最后,COTYPE优于COTYPE- rm和COTYPE- twostep,验证了所提出的基于翻译的嵌入目标能够有效地捕获实体-关系交叉约束。
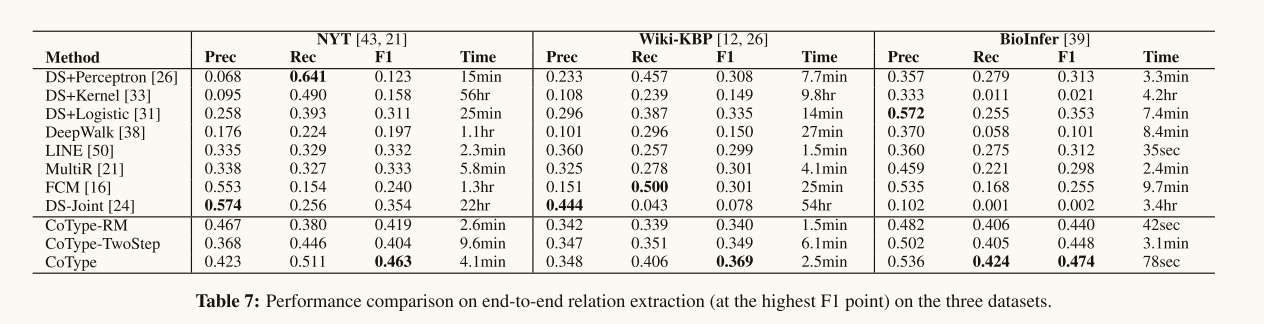
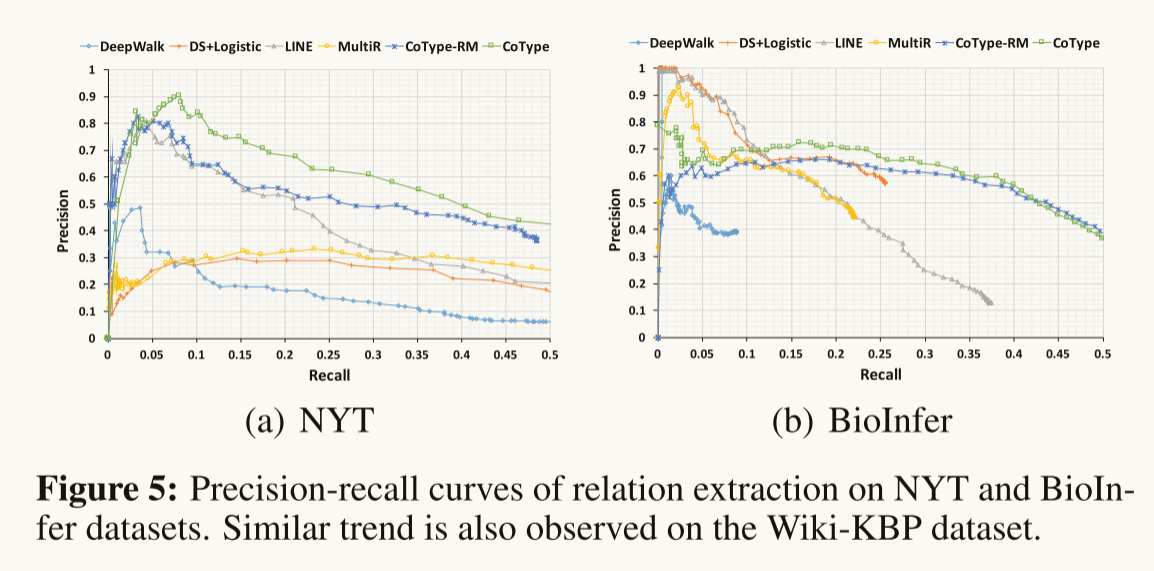
Performance on Relation Extraction: Table 7 表示了COTYPE在所有三个数据集的F1得分上都优于其他所有方法。我们发现DS-Joint和MultiR的召回率很低,因为它们的实体检测模块在DL上不能很好地工作(很多 token 都有假的负标签)。这证明了本文提出的领域无关文本分割算法的有效性。我们发现,学习嵌入的增量图(即COTYPE-TwoStep)只带来了微小的改进。而COTYPE采用假设3之后的“联合建模”图,得到了显著的改进。在图5中,NYT和BioInfer数据集的精确回忆曲线进一步表明,COTYPE在保持良好的回忆的情况下仍然可以达到下降精度。
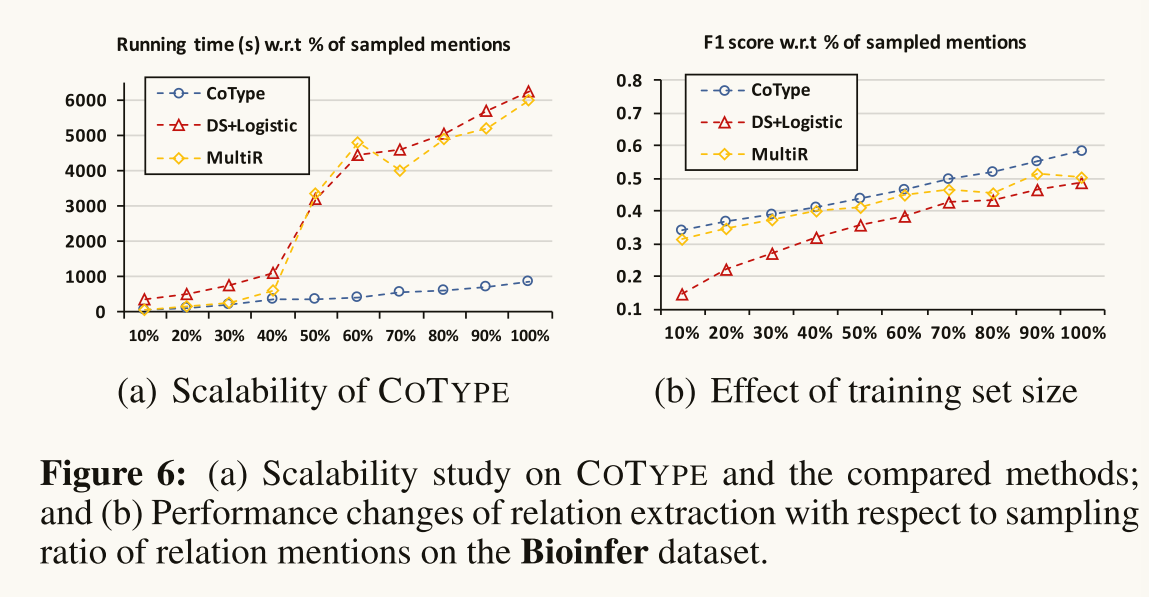
Scalability: 图6(a)测试了COTYPE与其他方法相比的Scalability,方法是在以不同比例采样的BioInfer语料库上运行。CoType展示了一个线性运行时趋势,并且是唯一能够处理完整数据集而不需要花费大量时间的方法。
Example output on news articles: Table 8

Testing the effect of training corpus size: 图6(b)显示了改变采样率时Bioinfer数据集的性能趋势。
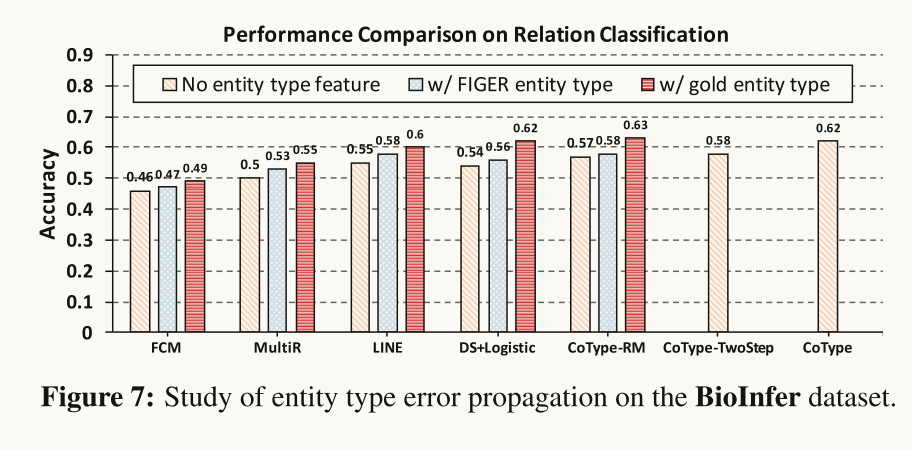
Study the effect of entity type error in relation classification: Figure 7
RELATED WORK
(1)Entity and Relation Extraction
(2)Learning Embeddings and Noisy Labels
CONCLUSION
本文研究了领域无关、类型化实体的联合提取以及文本中远程监控的关系。提出的CoType框架用领域无关的分割算法来挖掘实体提及,并将联合实体和关联提及的问题作为全局嵌入问题。我们设计了一个噪声鲁棒目标来建模带噪声的类型标签,并捕获实体与关系之间的相互依赖关系。实验结果证明了CoType在不同领域文本语料上的有效性和鲁棒性。未来的工作包括:在训练数据中加入伪反馈思想来减少false negative类型标签,在给定的类型层次结构中建模类型相关性,以及对测试实体提及和关系提及联合执行类型推断。
个人评价
CoType要解决的任务是实现实体和关系的联合抽取,传统的方法会将这两个任务独立处理,先进行实体识别,然后进行关系提取。而这样的处理方法会导致误差传播,所以就开始有很多学者开始研究将这两个任务联合处理。这篇论文也是出于这样的考虑进行联合抽取,同时结合远程监督的思想。
在生成Entity Mention时用到与领域无关的分词算法(domain-agnostic text segmentation)可以缓解目前的领域依赖问题。本文提出了一个联合优化问题,采用了三个假设 设计损失函数,在实验部分证明了采用这些假设可以有效改进实体和关系抽取的精度。 文中对于如何利用知识库的信息解释得比较简略,看完不太能理解是怎么利用知识库信息的。
自动标注训练语料库的步骤是否对结果有较大的影响,如何证明自动标注的语料库能对模型训练起到作用呢
本文的模型非常复杂,实验中对各个模块的功能分析不够详细,体现不出各个模块的作用。
本文算法实现了同时输出实体类型的embedding和关系类型的embedding,这两个产物互相影响,但是在实验部分,仅仅和其他单独进行NER任务的模型进行比较,似乎有失偏颇。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号