
迈向大规模小目标检测:综述与数据集
程塨,袁翔,姚西文,延可冰,曾庆华,谢星星,韩军伟*
TPAMI 2023
西北工业大学 自动化学院
原文地址:https://ieeexplore.ieee.org/document/10168277
原文代码:https://shaunyuan22.github.io/SODA/
| 项目 | 内容 | |
|---|---|---|
| 文献信息 | 标题:Towards Large-Scale Small Object Detection: Survey and Benchmarks 迈向大规模小目标检测:综述与数据集 | 出版日期:2023 |
| 作者:程塨,袁翔,姚西文,延可冰,曾庆华,谢星星,韩军伟* | 期刊或出版物名称:TPAMI | |
| 摘要 | 小目标固有结构导致的视觉外观较差和噪声表示,使得小目标检测成为一项极具挑战性的任务。此外,用于评估小目标检测方法的大规模数据集仍然是一个瓶颈。 本文对小目标检测进行了全面的回顾。为了推动 SOD 领域的发展,论文构建了两个大规模的小目标检测数据集(Small Object Detection dAtasets,SODA),即 SODA-D 和 SODA-A,分别专注于驾驶场景(Driving)和遥感场景(Aerial)。 | |
| 研究问题 | 本综述聚焦于 基于深度学习的小目标检测方法。 | object detection 是对实例进行分类和定位。Small object detection or tiny object detection,仅仅关注于检测那些有限大小的目标。在这个任务中,术语tiny和small通常由 面积阈值 或 长度阈值 定义。 |
| 主要贡献 | 1. 综述了 深度学习时代小目标检测的发展,系统地介绍了该领域的最新进展,将该领域的方法划分为六大类,对这些方法的优缺点进行了深入分析,并回顾了跨越多个领域的小目标检测数据集。 2. 发布了两个用于小目标检测的 large-scale benchmarks。 3.研究了几种有代表性的目标检测方法在本文的数据集上的性能。 | |
| 难点 | 小目标检测的 typical issues: (1)Information loss: 对feature map进行下样会失去对小物体的表示能力。 (2)Noisy feature representation: 卷积操作后,小目标特征易被背景和其他 instance “污染”。 (3)Low tolerance for bounding box perturbation: 对于一个小目标,预测边界框的轻微偏差会导致IoU显著降低。这意味着与较大目标相比,小目标对于边界框的扰动容忍度较低,这使得回归分支的学习变得更加困难。 (4)Inadequate samples for training:小目标占据的区域相对较小,并且与先验框(锚点或点)的重叠有限。这对于传统的标签分配策略造成了巨大挑战,这些策略通常基于边界框或中心区域的overlaps来收集正负样本,在训练过程中导致小目标的正样本分配不足。 | generic object detection(通用目标检测)的问题主要包括:intra-class variations, inaccurate localization, occluded object detection等。 |
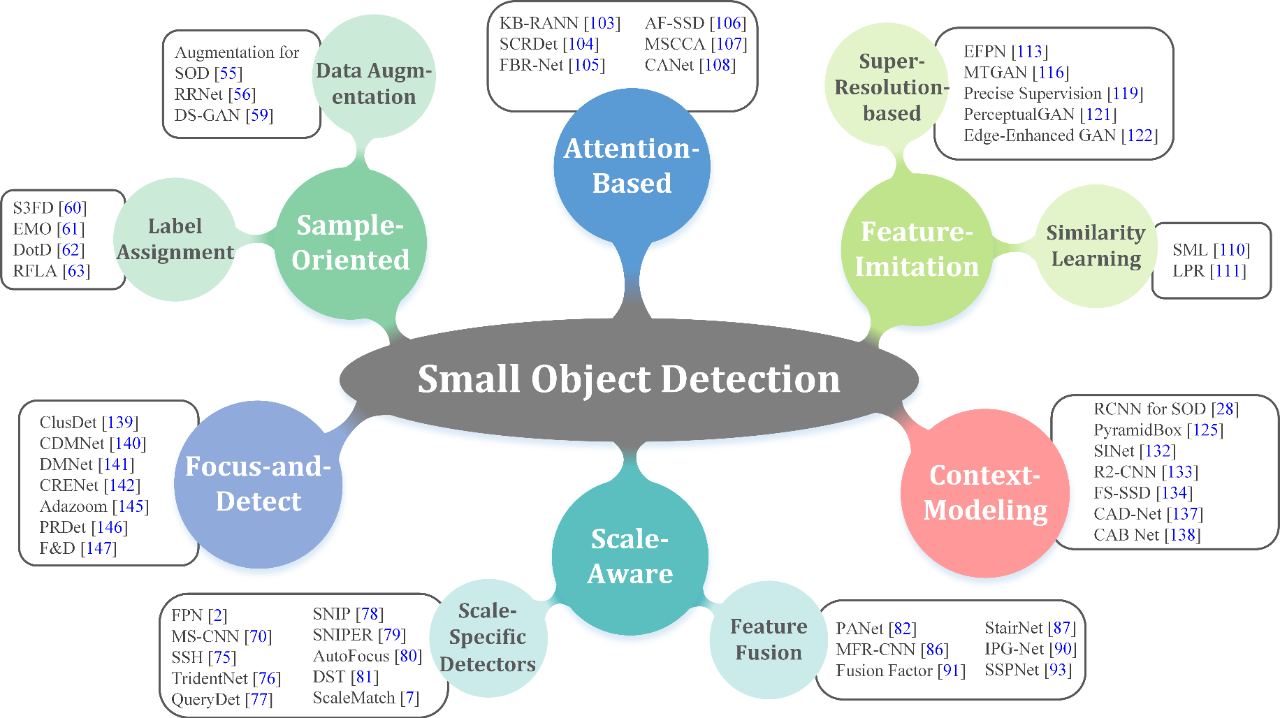
| 深度学习时代小目标检测的发展 | 小目标检测可分为六类: sample-oriented methods, scale-aware methods, attention-based methods, feature-imitation methods, context-modeling methods, and focus-and-detect methods. | |
| sample-oriented methods & scale-aware methods | 面向样本的方法(sample-oriented methods) 可以分为两派:通过数据增强增加小目标数量 或 设计最优的分配策略来使网络学习获得足够的样本。基于数据扩充的方法简单有效,但其性能提升依赖于数据集,即针对不同的数据集需要设计不同的增广策略。 | 尺度感知方法( scale-aware methods) 工作主要沿着两个方向进行。一种是通过设计多分支架构或量身定制的训练策略来构建特定尺度的检测器,另一种是通过融合hierarchical features来获得强大的小目标representations。 |
| attention-based methods & feature-imitation methods | 基于注意力的方法(attention-based methods) 通过为特征图的不同部分分配不同的权重,注意模型可以强调有价值的区域,同时抑制了那些不必要的区域。自然地,人们可以使用这种方案来突出显示容易被背景和噪声模式主导的小目标。基于注意力的方法因其灵活的嵌入设计而备受推崇,并且可以插入几乎所有的小目标检测架构中。然而,性能改进是以大量计算开销为代价的,因为涉及到相关操作,并且当前的注意力范式缺乏监督信号和显式优化。 | 特征模仿的方法(feature-imitation methods) 小目标包含的信息有限,导致模型在分类和回归时能够利用的信息很少;与此同时,大目标往往具有清晰的视觉结构和更好的区分度。因此,这类方法希望通过模仿较大目标的区域特征来丰富小目标的特征表示。可分为两类:基于相似性学习的特征模仿和基于超分辨率框架的方法。然而,无论是相似性学习方法还是超分辨率方法都必须避免塌陷问题并保持特征的多样性。此外,基于GAN的方法倾向于产生虚假的纹理和伪影,对检测产生负面影响。更糟糕的是,超分辨率架构使得端到端的优化变得复杂。 |
| context-modeling methods & focus-and-detect methods | 背景建模方法(context-modeling methods) 捕捉语义或空间关联的先验知识被称为上下文信息,它传递了超越对象区域的证据或线索。信息丰富的上下文有时可以提供比对象本身更多的决策支持,特别是在识别视觉质量较差的对象时。从信息论的角度来看,考虑的特征类型越多,越有可能获得更高的检测准确率。然而,当前的背景建模机制以启发式和经验方式确定上下文区域,不能保证所构建的目标表示具有足够的解释性和鲁棒性。 | 由粗到精的方法(focus-and-detect methods) 通过过滤掉那些没有目标的区域,从而减少无用的操作来提升检测效率。由粗到精的方法首先抽象出包含目标的区域,然后对其进行检测。这种范式保证了小对象可以以更高的分辨率进行处理,从而减轻了信息丢失,提高了表示质量。where to focus? 目前的方法要么依靠手工添加标注,要么依靠分割网络、高斯混合模型等辅助体系结构,但前者需要费力的标注,后者则使端到端优化复杂化。 |
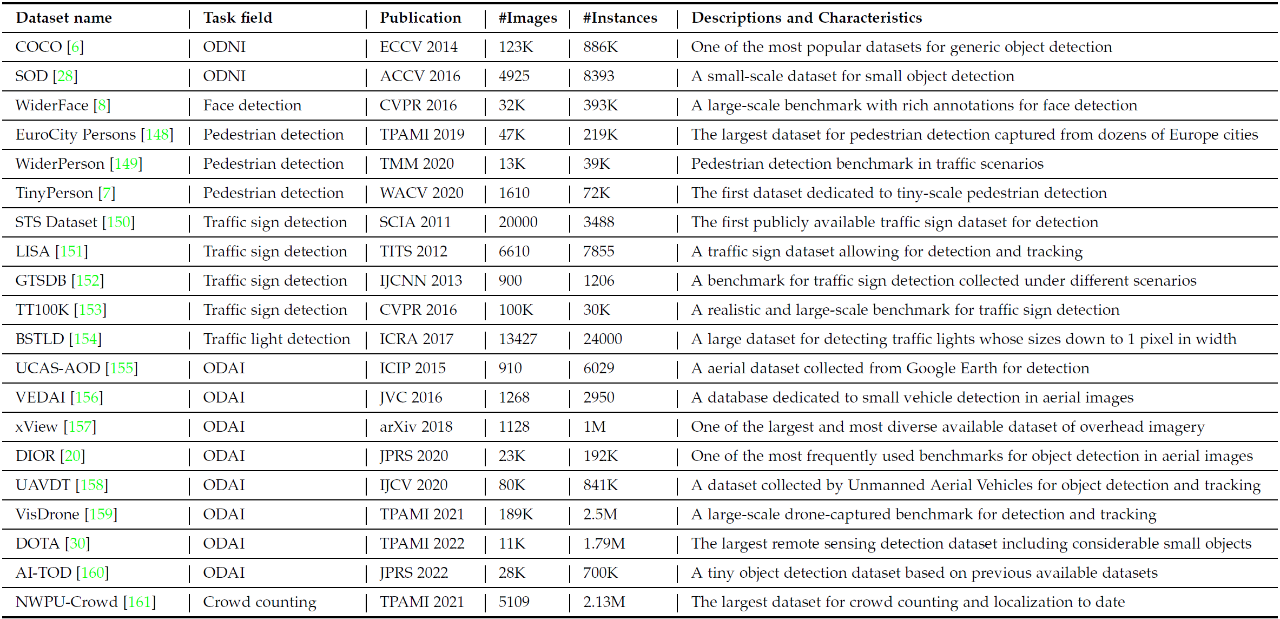
| 数据集 | 数据集对于基于深度学习的目标检测而言十分重要,小目标检测相关的数十个数据集相关的数据统计如下表。各个不同任务常用的数据集包括COCO、WiderFace、TinyPerson、TT100K、VisDrone、DOTA等。 | |
| SODA-D 和 SODA-A | SODA-D 的数据特性: 1.丰富的数据多样性:SODA-D中部分图像来源于MVD数据集[7],因而继承了MVD的一个重要特性:丰富的数据多样性。具体而言,SODA-D在位置、天气、时段、拍摄角度和场景等方面变化多样。2. 较高的空间分辨率:SODA-D数据集中的图像具有非常高的分辨率及成像质量,这有利于小目标或微小目标的检测。3. 忽略区域标注:数据集标注了大量的忽略(ignore)区域 ,尤其是SODA-D共有153976个忽略区域标注。两种情况时一个区域会被标记为忽略:第一,当目标符合预设类别,但其面积大于2000像素;第二,目标间高度重叠或者严重遮挡等难以区分其类别的情况。合理的忽略区域标注可以使得模型关注到真正具有挑战的小目标区域。 | SODA-A 的数据特性: 1. 较大的实例密度差异:SODA-A中每张图像的目标实例数量在1到11134之间变化,这意味着本文的基准数据集不仅包含稀疏情况,还包括许多目标密集排列的图像。此外,SODA-A中每张图像的平均实例数为347.02,是DOTA数据集(159.18)的两倍以上。2. 角度分布多样:SODA-A中的实例角度分布广泛,这种角度分布的多样性对于获得性能优异的有向目标检测器而言非常重要。3. 位置多样性:SODA-A中的图像来自世界各地数百个城市,这实际上极大增加了数据的多样性(例如,SODA-A中不同区域的airplane类别目标的外观变化很大)。此外,由此带来的类内变化和复杂的背景造成了更多实际挑战。 |
| 实验 | 评价指标:使用平均精度(AP)来评估探测器的性能。具体地说,作为最重要的度量,总的AP是通过对Small对象上的10个IoU阈值(0.5到0.95)的AP取平均值来获得的。AP50和AP75分别按照0.5和0.75的单一IoU阈值计算。此外,为了突出我们对尺寸限制对象的关注,还演示了四个区域子集的AP,即APes、APrs、APgs和APn。 | es:extremely Small,rs:relatively Small,gs: generally Small,n:norma。  |
| 结果讨论和解释 | (1)SODA-D数据集的实验结果 SODA-D数据集的实验结果选取不同检测范式下的代表性算法进行评估:即使是通用目标检测领域表现优异的算法,在面对小目标时,其性能仍然不理想。 基线检测器不同类别的检测结果:对于rider和bicycle类别精度较低,除了目标面积小这一挑战以外,实例数目相对较少也是一个重要原因。 测试了不同主干网络对于小目标检测性能的影响:当网络层数加深时,检测性能并不会得到显著提升甚至会下降。这也从侧面证明了不同于通用目标检测任务,对于小目标检测任务而言,更深的网络并不意味着更好的性能! | (2)SODA-A数据集的实验结果 选取了有向目标检测领域的数个代表性算法,在SODA-A测试集上的性能表现:双阶段算法的精度显著高于单阶段检测器。 基线检测器对于各类别的检测结果:由于SODA-A数据集包含很多长宽比较大的目标类别,如large-vehicle,不同算法所采用的不同目标表示形式对最终的检测结果有很大影响。 不同主干网络对于最终检测性能的影响:在通用目标检测领域表现出色的Swin-T和ConvNext-T 在面对遥感影像的小目标时,能够为双阶段算法带来一致的性能提升,但却会降低单阶段检测器的性能。 |
| 结论 | 高效特征提取网络: 现有的骨干网络可能不利于提取小目标的高质量特征表示。因而设计一个针对小目标的的高效骨干网络——既具有强大的特征提取能力,又能避免高计算成本和信息损失——是一个需要深入研究的关键问题。 | 高质量的层级化特征表示:特征金字塔(FPN)是小目标检测模型中不可或缺的一部分。然而,当前的FPN对于小目标检测而言并不是最优的,这是因为在启发式的金字塔层级分配策略下,只有极少的样本被分配到更高的层级。因此,高层级的特征图只能在隐式和间接的方式下进行优化,这会对最终特征融合的质量造成影响。此外,在高分辨率的低层级特征图上进行检测会带来较重的计算负担。因此,需要设计一个专为小目标检测任务量身定制的高效分层特征架构。 |
| 优化的样本分配策略:尽管当前的标签分配方案在通用目标检测和大目标上表现良好,但它们在处理极小目标时仍然面临巨大挑战,无论是基于重叠的策略还是基于分布的策略都是如此。因此,设计一个优化的策略来为尺寸有限的目标分配足够的正样本,可以显著稳定训练过程并进一步提升性能。 | 适用于小目标检测的评估指标:在某些特定场景下,小目标检测的首要任务是识别目标并获取其大致位置,而不是过度追求定位精度。因此,借鉴其他领域(如人群计数)的经验,设计一个适当的指标指导小目标检测架构在某些特定场景下的训练和推理,对领域未来的进一步发展至关重要。 | |
| 个人评论 | 本文将深度学习时代的小目标检测方法分为六个类别,介绍了各类别的代表性方法,对目标检测的难点进行了分析,对相关问题的研究方法进行了有条理的总结,有助于读者了解目标检测领域的相关知识。 由于现有的深度学习方法对于数据的依赖性,本文构建的小目标检测数据集包含足够丰富的实例,对该领域的研究有很大的帮助。 |
Abstract
小目标固有结构导致的视觉外观较差和噪声表示,使得小目标检测成为一项极具挑战性的任务。此外,用于评估小目标检测方法的大规模数据集仍然是一个瓶颈。
本文对小目标检测进行了全面的回顾。为了推动 SOD 领域的发展,论文构建了两个大规模的小目标检测数据集(Small Object Detection dAtasets,SODA),即 SODA-D 和 SODA-A,分别专注于驾驶场景(Driving)和遥感场景(Aerial)。
1. introduction
challenge:
1)从有限的、失真的小目标中学习正确特征的本就充满困难;2)缺乏针对小目标检测的大规模数据集。
小目标有限的大小和通用的特征提取方法导致得到的特征质量较低。
小目标检测可分为六类: sample-oriented methods, scale-aware methods, attention-based methods, feature-imitation methods, context-modeling methods, and focus-and-detect methods.
1.1 Problem Definition
object detection 是对实例进行分类和定位。Small object detection or tiny object detection,仅仅关注于检测那些有限大小的目标。在这个任务中,术语tiny和small通常由 面积阈值 或 长度阈值 定义。以COCO为例,所占面积小于等于1024像素的目标属于小目标范畴。
1.2 Comparisons with Previous Reviews
本文综述与现有的研究成果主要有两个方面的不同。
-
一个全面和及时的回顾专门针对跨多个领域的小对象检测任务。本文提供了一个系统的小目标检测的调查和一个可理解的、高度结构化的分类,根据所涉及的方法,将SOD方法分成六个主要类别,与以前的综述截然不同。
-
提出了两个针对小目标检测的大规模基准数据集,并在此基础上对几种具有代表性的检测算法进行了深入评价和分析。
1.3 Scope
本综述聚焦于 基于深度学习的小目标检测方法。
contributions:
-
综述了 深度学习时代小目标检测的发展,系统地介绍了该领域的最新进展,将该领域的方法划分为六大类,对这些方法的优缺点进行了深入分析,并回顾了跨越多个领域的小目标检测数据集。
-
发布了两个用于小目标检测的 large-scale benchmarks。
-
研究了几种有代表性的目标检测方法在本文的数据集上的性能。
2
2.1 Main Challenges
generic object detection(通用目标检测)的问题主要包括:intra-class variations, inaccurate localization, occluded object detection等。
小目标检测的 typical issues:
(1)Information loss: 对feature map进行下样会失去对小物体的表示能力。
(2)Noisy feature representation: 卷积操作后,小目标特征易被背景和其他 instance “污染”。
(3)Low tolerance for bounding box perturbation: 对于一个小目标,预测边界框的轻微偏差会导致IoU显著降低。这意味着与较大目标相比,小目标对于边界框的扰动容忍度较低,这使得回归分支的学习变得更加困难。
(4)Inadequate samples for training:小目标占据的区域相对较小,并且与先验框(锚点或点)的重叠有限。这对于传统的标签分配策略造成了巨大挑战,这些策略通常基于边界框或中心区域的overlaps来收集正负样本,在训练过程中导致小目标的正样本分配不足。
2.2 六类小目标检测算法
为了解决上述问题,现有的小目标检测方法通常在通用目标检测的 paradigms 上加以改进。
2.2.1 Sample-oriented methods
面向样本的方法 可以分为两派:通过数据增强增加小目标数量 或 设计最优的分配策略来使网络学习获得足够的样本。基于数据扩充的方法简单有效,但其性能提升依赖于数据集,即针对不同的数据集需要设计不同的增广策略。
Data-augmentation strategies: [55]通过复制+变换+粘贴到不同位置来增大样本量。 RRNet[56] 利用先验分割地图粘贴到有效位置,并进行尺度变换,减小尺度差异。 [57,58]基于分割和缩放功能的操作来获取更多的样本。 DS-GAN[59] 用GAN 生成小目标合成数据。但是 往往面临着性能改进不一致和迁移能力差的问题。
[55] Augmentation for small object detection [56]Rrnet: A hybrid detector for object detection in drone-captured images ICCVW, 2019 [57] Dense and small object detection in uav vision based on cascade network ICCVW, 2019 [58] Towards efficient detection for small objects via attention-guided detection network and data augmentation [59] A full data augmentation pipeline for small object detection based on generative adversarial networks
Optimized label assignment: 旨在缓解基于overlap- or distance-based 匹配方法 导致的sub-optimal采样结果。S3FD [60]通过设计scale compensation anchor matching strategy,增加了与 tiny faces匹配的锚点。 [61] 提出了期望最大重叠(EMO)得分,在计算重叠时考虑了锚点的步幅,并为 tiny faces启发了更好的锚点设置。[62] 提出DotD(两个边界框中心点之间的标准化欧氏距离)来替代常用的IoU。RFLA [63]在标签分配中测量每个特征点的高斯感受野与真实值之间的相似性,提升了主流检测器在小目标上的性能。但是 优化的标签分配方案容易引入低质量的样本,并且难以应付尺寸极小的目标。
[60]S3fd:Single shot scale-invariant face detector ICCV, 2017 [61]Seeing small faces from robust anchor’s perspective CVPR, 2018 [62]Dot distance for tiny object detection in aerial images CVPRW, 2021 [63]Rfla: Gaussian receptive based label assignment for tiny object detection ECCV, 2022
2.2.2 Scale-aware methods
尺度感知方法 的工作主要沿着两个方向进行。一种是通过设计多分支架构或量身定制的训练策略来构建特定尺度的检测器,另一种是通过融合hierarchical features来获得强大的小目标representations。
Scale-specific detectors: 致力于以最合理的尺度处理小目标,不同层次的特征主要用于检测相应尺度的目标。然而,以启发式方式将不同大小的目标映射到相应的尺度级别,这可能会使检测器产生困惑,因为单个层次的信息不足以进行准确的预测。
[69] 利用尺度相关的池化(Scale-Dependent Pooling,SDP)选择适当的特征层用于小目标的池化操作。MS-CNN [70]在不同的中间层生成目标候选框专注于特定尺度范围内的目标,为小目标提供最优感受野。DSFD [71]通过特征增强模块连接两个检测器,用于检测不同尺度的人脸。YOLOv3 [45]通过添加并行分支进行多尺度预测,其中高分辨率特征负责小目标。[2]提出了特征金字塔网络(Feature Pyramid Network,FPN),将不同尺度的物体分配给不同的金字塔层级,并启发了一系列变体,如NAS-FPN [72]、Bi-FPN [73]和RecursiveFPN [74]。此外,将尺度特定的检测器组合用于多尺度检测也得到了广泛探索。例如,[75]构建了并行子网络,其中小尺寸子网络专门用于检测小行人。SSH [76]将不同尺度的人脸检测器组合起来。TridentNet [77]构建了一个并行的多分支架构,每个分支具有不同尺度目标的最优感受野。QueryDet [78]设计了cascade query策略,避免对低层次特征进行冗余计算,从而在高分辨率特征图上高效地检测小目标。
[69] “Exploit all the layers: Fast and accurate cnn object detector with scale dependent pooling and cascaded rejection classifiers,” in CVPR, 2016, [70]“A unified multi-scale deep convolutional neural network for fast object detection ECCV, 2016 [71]Dsfd: Dual shot face detector CVPR, 2019 [2]Feature pyramid networks for object detection CVPR, 2017 [75]Scale-aware fast r-cnn for pedestrian detection [76]Ssh:Single stage headless face detector ICCV, 2017 [77]Scale-aware trident networks for object detection ICCV, 2019 [78] Querydet: Cascaded sparse query for accelerating high-resolution small object detection CVPR, 2022
还有一些方法开发特定的 data preparation strategies,以在训练过程中让检测器专注于特定尺度的实例。[79]设计了尺度归一化图像金字塔(Scale Normalization for Image Pyramids,SNIP),它只将分辨率在所需尺度范围内的实例用于训练,其余的实例被忽略,可以在最合理的尺度上处理小目标,同时不影响中大尺度目标的检测性能。后来,Sniper [80] 从多尺度图像金字塔中采样图像块进行高效训练。Najibi等人[81]提出了一种粗到细的pipeline。[82]设计了一种反馈驱动的训练范式,动态地指导数据准备,并进一步平衡小目标的训练损失。[7]引入了一种基于统计的匹配策略用于尺度一致性检测。
[79]An analysis of scale invariance in object detection-snip CVPR, 2018 [80]Sniper: Efficient multi-scale training [81]Autofocus: Efficient multiscale inference [82]Dynamic scale training for object detection [7]Scale match for tiny person detection WACV, 2020,
Hierarchical feature fusion: 旨在弥合低层和高层特征图之间的空间和语义信息差距。然而,在网络内部不同层级间信息的流动并不总是有利于小目标的表示,因而需要谨慎处理这一过程,防止小目标的原始响应被更深层次的信号淹没。
PANet [83] 使用双向路径丰富了特征层次结构,用准确的定位信号增强深层特征。[86] 将ROI池化后的特征在多个深度上与全局特征进行串联。StairNet [87] 使用反卷积扩大特征图,这种基于学习的上采样函数可以获得比传统的基于卷积核的上采样更精细的特征,并且允许不同金字塔层级的信息更高效地传播。IPG-Net [89],将图像金字塔输入到IPG变换模块,提取浅层特征来补充空间信息和细节。SSPNet[93]注意到基于FPN的方法会遇到梯度不一致的问题,从而降低了低层次特征的表达能力[92],SSPNet[93]强调了FPN中特定尺度在不同层次上的特征,并利用FPN中相邻层之间的关系来实现适当的特征共享。
[83]Path aggregation network for instance segmentation CVPR, 2018 [86]Mfrcnn: Incorporating multi-scale features and global information for traffic object detection [87]Stairnet: Top-down semantic aggregation for accurate one shot detection [89]Ipg-net: Image pyramid guidance network for small object detection [93]Sspnet:Scale selection pyramid network for tiny person detection from uav images
2.2.3 Attention-based methods
通过为特征图的不同部分分配不同的权重,注意模型可以强调有价值的区域,同时抑制了那些不必要的区域。自然地,人们可以使用这种方案来突出显示容易被背景和噪声模式主导的小目标。基于注意力的方法因其灵活的嵌入设计而备受推崇,并且可以插入几乎所有的小目标检测架构中。然而,性能改进是以大量计算开销为代价的,因为涉及到相关操作,并且当前的注意力范式缺乏监督信号和显式优化。
SCRDet [102]设计了一个面向对象的检测器,其中像素注意力和通道注意力在监督方式下进行训练,以突出显示小目标区域并消除噪声干扰。FBR-Net [103] 扩展了无锚点检测器FCOS, 提出基于层级的注意力,平衡了不同金字塔层级上的特征。KB-RANN [104]利用长期和短期的注意力神经网络来关注图像特征的特定部分,增强小目标的检测。[105] 设计了一个双通道模块来突出显示小目标的关键特征并抑制非目标信息。MSCCA [106] 通过用提出的增强通道注意力(ECA)块替换复杂的卷积组件,构建了一个轻量级的检测器,具有平衡的通道特征和较少的参数。[107] 设计了一个跨层注意力模块来获得更强的小目标响应。
[102]Scrdet: Towards more robust detection for small, cluttered and rotated objects ICCV, 2019 [103]An anchor-free method based on feature balancing and refinement network for multiscale ship detection in sar images [104]Feature selective small object detection via knowledge-based recurrent attentive neural network [105]Attention and feature fusion ssd for remote sensing object detection [106]Lightweight oriented object detection using multiscale context and enhanced channel attention in remote sensing images [107]Crosslayer attention network for small object detection in remote sensing imagery
2.2.4 Feature-imitation methods
小目标包含的信息有限,导致模型在分类和回归时能够利用的信息很少;与此同时,大目标往往具有清晰的视觉结构和更好的区分度。因此,一个自然而然的想法是通过模仿较大目标的区域特征来丰富小目标的特征表示。为此,已经提出了一些方案,可分为两类:基于相似性学习的特征模仿和基于超分辨率框架的方法。然而,无论是相似性学习方法还是超分辨率方法都必须避免塌陷问题并保持特征的多样性。此外,基于GAN的方法倾向于产生虚假的纹理和伪影,对检测产生负面影响。更糟糕的是,超分辨率架构使得端到端的优化变得复杂。
Similarity learning-based methods: 在通用检测器上施加额外的相似性约束,从而弥合小目标和大目标之间的表示差异。
Wu等人[110]提出了“自我模仿学习”方法,其中强制小尺寸行人的表示接近大尺寸行人的局部平均RoI特征。受人类视觉理解机制的记忆过程的启发,Kim等人[111]设计了一个大尺度嵌入学习框架,其中使用大尺度行人召回记忆(LPR Memory),并通过召回损失对整体架构进行优化,旨在引导小尺度和大尺度行人特征的趋于相同。
[110]Self-mimic learning for small-scale pedestrian detection [111]Robust small-scale pedestrian detection with cued recall via memory learning ICCV, 2021
Super-resolution-based frameworks: 这一路线的方法旨在恢复小目标的变形结构,而不仅仅是放大它们的模糊外观。
在使用反卷积和子像素卷积[111]的帮助下,[83]和[113] 获得了专门用于小目标检测的高分辨率特征。在自监督学习范式的指导下,[114]提出了一个引导特征上采样模块,以学习带有细节信息的放大特征表示。GAN[115] 具有通过生成器和鉴别器之间的 two-player minimax game 来生成视觉真实数据的能力,这启发研究人员探索这个强大的paradigm 来生成小目标的高质量表示。考虑到直接操作整个图像在特征提取阶段会导致不可忽视的计算成本[113],MTGAN [116]使用生成器网络对RoIs的块进行超分辨率处理。[117]将这种范例扩展到人脸检测任务,[118]则将超分辨率方法应用于小的候选区域以获得更好的性能。尽管超分辨率目标块可以部分重建小目标的模糊外观,但这种方案忽略了在网络预测中起重要作用的上下文线索 [119], [120]。为了解决这个问题,Li等人[121]设计了PerceptualGAN来挖掘和利用小尺度目标和大尺度目标之间的内在关联,其中生成器学习将小目标的弱表示映射到欺骗鉴别器的超分辨率表示。
[111]Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network CVPR, 2016 [113]Extended feature pyramid network for small object detection [114]Self-supervised feature augmentation for large image object detection [115]Generative adversarial nets [116]Sod-mtgan: Small object detection via multi-task generative adversarial network [117]“Finding tiny faces in the wild with generative adversarial network,” in CVPR, 2018 [118]“Object detection by a super-resolution method and a convolutional neural networks,” [119]Better to follow, follow to be better: Towards precise supervision of feature super-resolution for small object detection [120]An empirical study of context in object detection [121]Perceptual generative adversarial networks for small object detection
2.2.5 Context-modeling methods
人类可以有效地利用环境与对象之间的关系或对象之间的关联来完成对对象和场景的识别。捕捉语义或空间关联的先验知识被称为上下文信息,它传递了超越对象区域的证据或线索。信息丰富的上下文有时可以提供比对象本身更多的决策支持,特别是在识别视觉质量较差的对象时。从信息论的角度来看,考虑的特征类型越多,越有可能获得更高的检测准确率。然而,无论是整体上下文建模还是局部背景信息引导,哪些区域应该被编码为背景区域需要被谨慎对待。换句话说,当前的背景建模机制以启发式和经验方式确定上下文区域,不能保证所构建的目标表示具有足够的解释性和鲁棒性。
[28]使用包围候选区域的上下文区域的表示进行后续识别。[131]研究了如何有效地编码目标范围之外的区域,并以尺度不变的方式建模局部上下文信息来检测微小的人脸。PyramidBox [125]充分利用上下文线索,以找到与背景难以区分的小而模糊的人脸。同样地,图像中的对象之间的内在关联也可以被视为上下文。FS-SSD [134]利用隐含的空间上下文信息,即类内和类间实例之间的距离,来重新检测置信度较低的对象。假设原始的RoI池化操作会破坏小对象的结构,SINet [132]引入了一个上下文感知的RoI池化层来保持上下文信息。R2-CNN [133]采用全局注意块来抑制误报并高效地检测大规模遥感图像中的小对象。Zhang等人[137]捕捉了对象与全局场景(全局上下文)之间以及对象与其相邻实例(局部上下文)之间的关联,以提高小对象的性能。
[28]R-cnn for small object detection [131]Finding tiny faces CVPR, 2017 [125]Pyramidbox: A contextassisted single shot face detector ECCV, 2018 [134]Small object detection in unmanned aerial vehicle images using feature fusion and scaling-based single shot detector with spatial context analysis [132]Sinet: A scale-insensitive convolutional neural network for fast vehicle detection [133]R2-cnn: Fast tiny object detection in large-scale remote sensing images [137]Cad-net: A context-aware detection network for objects in remote sensing imagery
2.2.6 Focus-and-detect methods
通过过滤掉那些没有目标的区域,从而减少无用的操作来提升检测效率。由粗到精的方法首先抽象出包含目标的区域,然后对其进行检测。这种范式保证了小对象可以以更高的分辨率进行处理,从而减轻了信息丢失,提高了表示质量。where to focus? 目前的方法要么依靠手工添加标注,要么依靠分割网络、高斯混合模型等辅助体系结构,但前者需要费力的标注,后者则使端到端优化复杂化。
ClusDet [139]充分利用目标之间的语义和空间信息来生成聚类片段,然后进行检测。[140]和[141]都利用像素级监督进行密度估计,得到更准确的密度图,很好地描述了目标的分布。CRENet [142]设计了一个聚类算法来自适应地搜索聚类区域。[143]考虑到固定大小输入处理流程通常会导致对小目标的漏检,采用平铺方法实时检测高分辨率航空图像中的行人和车辆。F&S [147]引入了一个Focus&Detect框架,其中Focusing Network检测候选区域,然后将其裁剪和调整大小到更高的分辨率,实现了对小目标的准确检测。
[139]Clustered object detection in aerial images ICCV, 2019 [140]Coarse-grained density map guided object detection in aerial images [141]Density map guided object detection in aerial images [142]Object detection using clustering algorithm adaptive searching regions in aerial images [143]The power of tiling for small object detection [147]Focus-and-detect: A small object detection framework for aerial images
数据集对于基于深度学习的目标检测而言十分重要,小目标检测相关的数十个数据集相关的数据统计如下表。各个不同任务常用的数据集包括COCO、WiderFace、TinyPerson、TT100K、VisDrone、DOTA等。
4 BENCHMARKS —— SODA数据集
4.1 Data Acquisition and Annotation
为了推动小目标检测任务的进一步发展,论文选取了领域内两个代表性场景,驾驶场景和遥感场景,构建了一个大规模数据集——SODA,包含SODA-D和SODA-A。为了专注于小目标,只对面积小于等于2000的实例进行标注,具体的面积划分和定义如下表所示。
Data source: SODA-D中的图像主要来自MVD、self-shooting和互联网。SODA-A 利用Google Earth获取数据。
Dataset split: 将图像集分成三个子集:训练集、验证集和测试集,每个子集大约占用50%:20%:30% for SODA-D和40%:25%:35% for SODA-A。
SODA-D和SODA-A的实例均突出了“小”这一主要特点。尤其是当只关注Small面积类别时,SODA-D和SODA-A中实例的平均尺寸仅为20.31和14.75像素。
SODA-D 的数据特性
丰富的数据多样性:SODA-D中部分图像来源于MVD数据集[7],因而继承了MVD的一个重要特性:丰富的数据多样性。具体而言,SODA-D在位置、天气、时段、拍摄角度和场景等方面变化多样。较高的空间分辨率:SODA-D数据集中的图像具有非常高的分辨率及成像质量,这有利于小目标或微小目标的检测。忽略区域标注:数据集标注了大量的忽略(ignore)区域 ,尤其是SODA-D共有153976个忽略区域标注。两种情况时一个区域会被标记为忽略:第一,当目标符合预设类别,但其面积大于2000像素;第二,目标间高度重叠或者严重遮挡等难以区分其类别的情况。合理的忽略区域标注可以使得模型关注到真正具有挑战的小目标区域。
SODA-A 的数据特性
较大的实例密度差异:SODA-A中每张图像的目标实例数量在1到11134之间变化,这意味着本文的基准数据集不仅包含稀疏情况,还包括许多目标密集排列的图像。此外,SODA-A中每张图像的平均实例数为347.02,是DOTA数据集(159.18)的两倍以上。角度分布多样:SODA-A中的实例角度分布广泛,这种角度分布的多样性对于获得性能优异的有向目标检测器而言非常重要。位置多样性:SODA-A中的图像来自世界各地数百个城市,这实际上极大增加了数据的多样性(例如,SODA-A中不同区域的airplane类别目标的外观变化很大)。此外,由此带来的类内变化和复杂的背景造成了更多实际挑战。
5 EXPERIMENTS
基于提出的两个场景的大规模小目标数据集,本文对通用目标检测领域代表性的算法进行了性能评估和对比分析。SODA数据集沿用了COCO数据集的评价指标,同时也提供了Small面积下子面积区间的性能评估指标。
(1)SODA-D数据集的实验结果
SODA-D数据集的实验结果如表5所示,选取不同检测范式下的代表性算法进行评估。可以看到,即使是通用目标检测领域表现优异的算法,在面对小目标时,其性能仍然捉襟见肘。
表 5 SODA-D测试集上代表性算法的检测结果。其中Schedule表示训练时长,“1×”表示训练12轮,50e表示训练50轮。除YOLOX [8]和CornerNet [9]分别使用CSP-Darknet和HourglassNet-104作为主干网络以外,所有模型均使用ResNet-50 [10]作为主干网络。
基线检测器不同类别的检测结果如表6所示,对于rider和bicycle类别而言,除了目标面积小这一挑战以外,实例数目相对较少也是导致精度较低的一个重要原因。
表 6 SODA-D测试集上基线检测器的各类别检测结果。
此外,还测试了不同主干网络对于小目标检测性能的影响,其结果如表7所示。值得注意的是,当网络层数加深时,检测性能并不会得到显著提升甚至会下降。这也从侧面证明了不同于通用目标检测任务,对于小目标检测任务而言,更深的网络并不意味着更好的性能!
表 7 不同骨干网络的基线检测器在SODA-D 测试集上的检测结果
(2)SODA-A数据集的实验结果
选取了有向目标检测领域的数个代表性算法,在SODA-A测试集上的性能表现如表8所示。可以看到,双阶段算法的精度显著高于单阶段检测器。
表 8 SODA-A测试集上代表性有向目标检测算法的检测结果
基线检测器对于各类别的检测结果如表9所示,由于SODA-A数据集包含很多长宽比较大的目标类别,如large-vehicle,不同算法所采用的不同目标表示形式对最终的检测结果有很大影响。
表 9 SODA-A测试集上基线检测器的各类别检测结果
不同主干网络对于最终检测性能的影响如表10所示,值得注意的是,在通用目标检测领域表现出色的Swin-T [11]和ConvNext-T [12]在面对遥感影像的小目标时,能够为双阶段算法带来一致的性能提升,但却会降低单阶段检测器的性能。
表 10 不同骨干网络的基线检测器在SODA-A 测试集上的检测结果
6 CONCLUSION AND OUTLOOK
本文对小目标检测进行了全面回顾,首先对基于深度学习的小目标检测算法进行了系统性的综述,同时总结和回顾了常用的一些数据集。为了推动该领域的进一步发展,本文构建了第一个专为小目标检测定制的大规模数据集SODA,包含SODA-D和SODA-A。基于这两个数据集,本文对数个代表性算法进行了性能评估和对比。
高效特征提取网络:如前所述,现有的骨干网络可能不利于提取小目标的高质量特征表示。因而设计一个针对小目标的的高效骨干网络——既具有强大的特征提取能力,又能避免高计算成本和信息损失——是一个需要深入研究的关键问题。
高质量的层级化特征表示:特征金字塔(Feature Pyramid Network,FPN)[13]是小目标检测模型中不可或缺的一部分。然而,当前的特征金字塔架构对于小目标检测而言并不是最优的,这是因为在启发式的金字塔层级分配策略下,只有极少的样本被分配到更高的层级(实际上,在我们的基准实验中只有P2层级的特征负责检测)。因此,高层级的特征图只能在隐式和间接的方式下进行优化,这会对最终特征融合的质量造成影响。此外,在高分辨率的低层级特征图上进行检测会带来较重的计算负担。因此,需要设计一个专为小目标检测任务量身定制的高效分层特征架构。
优化的样本分配策略:尽管当前的标签分配方案在通用目标检测和大目标上表现良好,但它们在处理极小目标时仍然面临巨大挑战,无论是基于重叠的策略还是基于分布的策略都是如此。因此,设计一个优化的策略来为尺寸有限的目标分配足够的正样本,可以显著稳定训练过程并进一步提升性能。
适用于小目标检测的评估指标:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号