

- Aerial Target Detection Based on the Improved YOLOv3 Algorithm
- Aircraft Rotated Boxes Detection Method Based on YOLOv5
- Bottleneck transformers for visual recognition
- Learning RoI transformer for oriented object detection in aerial images
| 内容 | 描述 | |
|---|---|---|
| 论文信息 | - 论文标题:基于改进YOLOv3算法的空中目标检测 Aerial Target Detection Based on the Improved YOLOv3 Algorithm | - 作者:Lecheng Ouyang,Huali Wang - 发表日期:2019 - 期刊或会议名称:ICSAI |
| 摘要 | YOLOv3算法直接用于复杂背景下的空中目标检测,导致检测精度低,漏检率高。本文提出了一种改进的YOLOv3算法来检测空中目标。首先使用K-means聚类算法对数据集进行分析,选择合适的锚盒数量和大小,然后提高网络检测尺度,建立特征融合目标检测层。 | - 关键词:Target detection; YOLOv3 algorithm; Cluster analysis |
| 主要研究问题 | 空中目标检测 (aerial target detection) | 航拍图像目标检测技术难点:超远距离拍摄、目标间相互遮挡、背景噪声、光线突变等。背景复杂,导致目标小,特征不明显,难以检测,无法达到预期的检测效果。 |
| 主要贡献 | 1. 使用K-means聚类算法对数据集进行分析 2. 改进了YOLOv3的网络结构 | |
| 方法 | 略 | |
| 实验设计 | 数据集:PETS2005-Tracking 和 DOTA | 在两个数据集上,本文算法相较于原YOLOv3的 准确率 和 召回率 都得到了提高,改善效果明显。但是背景复杂的小目标仍然无法检测。 |
| 结论 | 通过对数据集进行聚类分析,得到合适的锚盒。在YOLOv3网络结构的基础上,根据目标大小,提高了网络结构中的检测规模。 改进后的YOLOv3算法不仅具有较高的precision 和 recall,而且检测速度快。 | |
| 个人评价 | 文中提出的模型改进策略或许在训练的数据集上过拟合了,虽然实验部分指出 相较于YOLOv3性能提升较大,但是在其他场景的泛化性能有限。论文发表时间有点早,现在YOLO系列算法已经更新发展到YOLOv8了 |
Aircraft Rotated Boxes Detection Method Based on YOLOv5
Baiqi X, Gangwu J, Jianhui L, et al. Aircraft Rotated Boxes Detection Method Based on YOLOv5[C]//2021 4th International Conference on Pattern Recognition and Artificial Intelligence (PRAI). IEEE, 2021: 390-394.
| 内容 | 描述 | |
|---|---|---|
| 论文信息 | - 论文标题:基于YOLOv5的飞机旋转目标检测方法 Aircraft Rotated Boxes Detection Method Based on YOLOv5 | - 作者:Xu Baiqi, Jiang Gangwu, Liu Jianhui, Wang Xin, Yu Peidong - 发表日期:2021 - 期刊或会议名称:PRAI |
| 摘要 | 提出了一种基于YOLOv5的飞机旋转目标检测方法。首先,引入圆形平滑标签,避免了角度值的突变;然后将骨干网中的卷积(convolution)替换为内卷(Involution ),以减少网络参数的数量;最后,在Neck之后引入Coordinate Attention,从特征中去除背景信息。 | - 关键词:remote sensing image, aircraft target, rotated boxes detection, circular smooth label, involution, coordinate attention |
| 主要研究问题 | 飞机旋转目标检测 | 遥感图像中的飞机目标具有目标尺寸小、布置方向任意的特点, |
| 主要贡献 | (1)引入圆形平滑标签(CSL)标注方法,缓解旋转目标标注方法边界处的loss随周期变化而突变的问题。 (2)使用Involution代替骨干网中的convolution,减小参数,提高网络特征提取能力。 (3)为了解决背景复杂的问题,引入坐标注意(Coordinate Attention)来抑制特征中的背景信息。 | |
| 方法 | 略 | |
| 实验设计 | 数据集:DOTA数据集中的飞机目标 |  该方法的检测结果优于其他方法,AP值达到90.68%,能有效检测出旋转飞机目标。 该方法的检测结果优于其他方法,AP值达到90.68%,能有效检测出旋转飞机目标。 |
| 结论 | 本文引入CSL,Involution,Coordinate Attention,能够检测任意朝向的飞机目标。然而,该方法在小样本数据集上的训练效果较差。因此,在接下来的工作中,将对小样本数据集进行进一步的研究。 | |
| 个人评价 | 作者将三个模块组合在一起,使得YOLOv5算法能够检测遥感图像中的旋转飞机目标,在实验中,与其他算法对比取得了最好的检测精度,但是没有明显的优势,还有提升空间。 作者提到该方法在小样本数据集上的训练效果较差。 另外,在消融实验中可以看出,检测精度的提高主要还是由于引入了Attention,而Involution的影响较小,作者也没有比较未添加CSL模块的检测精度。 | 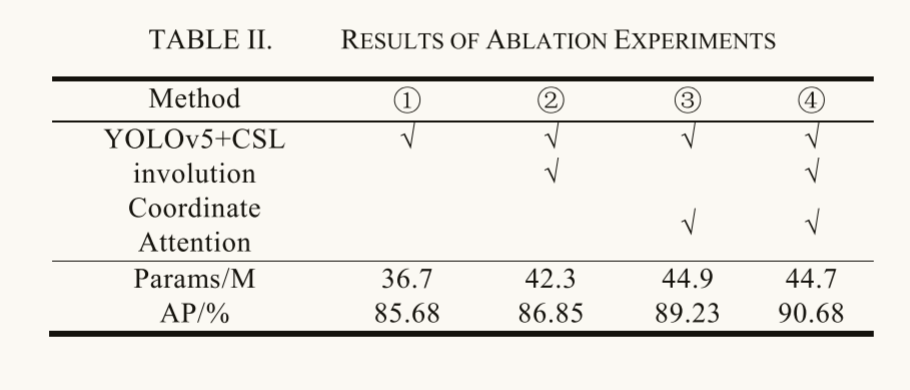 |
Bottleneck transformers for visual recognition
Srinivas A, Lin T Y, Parmar N, et al. Bottleneck transformers for visual recognition[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2021: 16519-16529.
| 内容 | 描述 | |
|---|---|---|
| 论文信息 | - 论文标题:Bottleneck transformers for visual recognition | - 作者:Aravind Srinivas Tsung-Yi Lin Niki Parmar Jonathon Shlens Pieter Abbeel Ashish Vaswani - 发表日期:2021 - 期刊或会议名称:CVPR |
| 摘要 | BoTNet在ResNet的最后三个瓶颈块中使用全局自注意替换空间卷积,在实例分割和对象检测方面显著改善了基线,同时减少了参数,延迟开销最小。 | |
| 主要研究问题 | 如何在CNN中引入global self-attention | 视觉中使用自注意时面临的挑战:(1)在目标检测和实例分割方面,图像尺寸(1024×1024)比图像分类(224 × 224)大得多。(2)训练和推理的计算和内存开销大。 |
| 主要贡献 | (1)使用卷积有效地从大图像学习抽象和低分辨率的特征图;(2)用全局自注意对卷积捕获的featuremap进行处理和聚合 | |
| 方法 | 在ResNet-50的结构基础上将C5的三个Bottleneck替换为带MHSA的Bottleneck。 这里C5的Bottleneck也不一定3个全用MHSA,为此文章也做了对比实验。 | 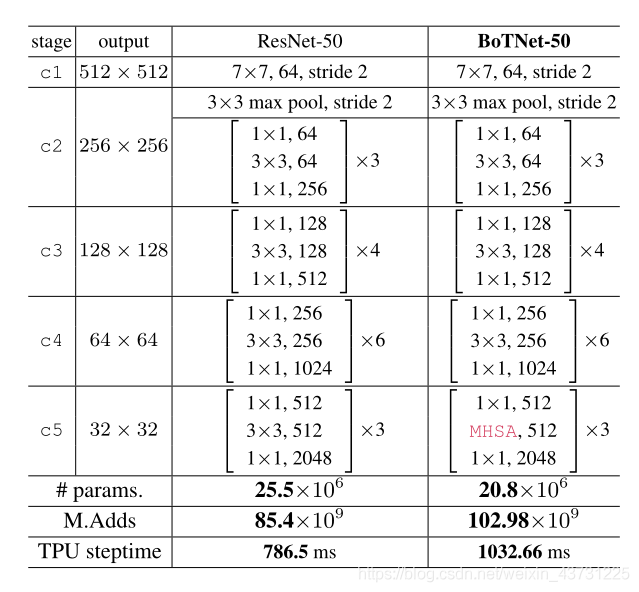 |
| 实验设计 | 实验了BoTNet在实例分割和目标检测方面的表现 | 单独使用的BoTNet在目标检测中取得了不错的结果 |
| 结论 | 将自注意机制应用到其他计算机视觉任务中,如特征点检测和三维形状预测,自监督学习的自注意机制,扩展到更大的数据集 是未来的研究方向 | |
| 个人评价 | BoTNet将self-attention引入到ResNet中,思路非常简单,但是却很powerful,超越了原始的ResNet模型,而且参数量更少,通过实验证明了方法的有效性。 CNN-based的模型更关注的是局部信息,而Transformer-based的模型先天有获取global信息的能力。Transformer作为是目前的研究热点,global和local attention 的结合或许会取得更好的结果 |
Learning RoI transformer for oriented object detection in aerial images
Ding J, Xue N, Long Y, et al. Learning RoI transformer for oriented object detection in aerial images[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 2849-2858.
| 内容 | 描述 | |
|---|---|---|
| 论文信息 | - 论文标题:Learning RoI transformer for oriented object detection in aerial images | - 作者:Jian Ding, Nan Xue, Yang Long, Gui-Song Xia∗, Qikai Lu - 发表日期:2019 - 期刊或会议名称:CVPR |
| 摘要 | RoI Transformer的核心思想是在RoI上应用空间变换,并在旋转框(OBB)标注的监督下学习变换参数。RoI Transformer是轻量级的,可以很容易地嵌入到检测器中,用于旋转目标的检测。 | |
| 主要研究问题 | 航拍图像的旋转目标检测 | 传统目标检测网络的常规操作对旋转和尺度变化的泛化能力有限,因此在设计roi和提取特征时要求具有一定的方向和尺度不变性。 |
| 主要贡献 | 1.提出了一种有监督旋转RoI学习器,它是一个可学习的模块,可以将HRoI转换为RRoI。这种设计不仅可以有效的缓解RoI与对象之间的错位,而且可以避免大量面向对象检测设计的锚点。 2.设计了旋转的位置敏感RoI对准模块,用于空间不变的特征提取,可以有效地帮助目标分类和位置回归 3.在多个大规模公开数据集上实现了最先进的性能。所提出的RoI Transformer可以很容易地嵌入到不同的主干网中,显著提高检测性能。 | |
| 方法 | 略 | |
| 实验设计 | 选择了DOTA和HRSC2016两个数据集 |  |
| 结论 | RoI Transformer有效地避免了区域特征与目标不匹配的问题。这种设计显著提高了旋转目标检测性能,而计算成本的增加微不足道。 | |
| 个人评价 | 旋转框检测模型RRPN通过生成大量旋转框完成检测,最主要的缺点是冗余计算导致检测速度很慢。本文提出RoI Transformer来解决此问题。RoI Transformer 是一个三阶段检测模型,主要由RRoI Leaner和RRoI Wraping两部分组成,核心思想是把RPN输出的水平锚框HRoI转换为旋转锚框RRoI。此策略无需增加锚点的数量且可以获得精确的RRoI。 本文的方法解决了旋转目标检测问题,但是针对不同目标的检测精度还有待提高 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号