Java之戳中痛点 - (3)三目运算符的两个操作数类型尽量一致 Java之戳中痛点 - (4)i++ 和 ++i 探究原理 Java之戳中痛点 - (1)易变业务使用脚本语言编写 Java之戳中痛点 - (2)取余用偶判断,不要用奇判断 (5)switch语句break不能忘以及default不同位置的用法 Java之戳中痛点 - (7)善用Java整型缓存池
Java之戳中痛点 - (3)三目运算符的两个操作数类型尽量一致
先看一个例子:

package com.test;
public class TernaryOperator {
public static void main(String[] args) {
int temp = 80;
String s1 = String.valueOf(temp<100?90:100);
String s2 = String.valueOf(temp<100?90:100.0);
System.out.println(s1);
System.out.println(s2);
System.out.println(s1.equals(s2));
}
}
结果:

看一下结果发现两个值不相等,这里有疑问了,两个表达式都是true,都是取第一个操作数的值,为什么第二个值确实90.0?
这里就仔细看一下:
第一个表达式 : 两个操作数都是int,所以返回值肯定是int
第二个表达式:第一个操作数是int,第二个操作数是float
试想一下,表达式不可能在true时返回int,在false时返回float,编译器是不允许的,所以进行了类型转换;
PS:三目运算符尽量保持两个操作数的类型一致,避免出现异常
附:转换规则
- 若两个操作数不可转换,则不做转换,返回值为Object类型
- 若两个操作数是明确的类型,按照基础数据类型的转换规则来处理(不包括boolean)
转换规则:从存储范围小的类型到存储范围大的类型。
具体规则为:byte→short(char)→int→long→float→double - 若两个操作数,一个是数字S,一个是表达式,类型标记为T,若S在T的范围之内,则S转换为T类型,若S在T的范围之外,则T转换为S类型
- 若两个操作数都是直接量数字(字面量),则返回值为范围较大的
Java之戳中痛点 - (4)i++ 和 ++i 探究原理
先看一个例子:
package com.test;
public class AutoIncrement {
public static void main(String[] args) {
int a=7;
System.out.println(++a);
System.out.println(a);
int b=7;
System.out.println(b++);
System.out.println(b);
}
}
结果也如预期的一样:
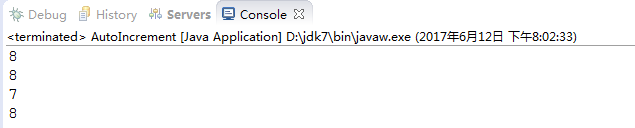
是不是回忆起大学老师讲的规则:自增有两种方式,分别是i++和++i;i++表示先赋值后加1;++i表示先加1再赋值;
那还有啥好讲的?(**上面的规则是片面的**)
那下来咱们看一个例子:
package com.test;
public class AutoIncrement {
public static void main(String[] args) {
int c = 0;
for(int i=0;i<10;i++){
c = c++;
}
System.out.println(c);
}
}
最后结果是多少?答案等于10?我可以肯定的告诉你错了,答案是0,这是为什么?
下面咱们讲一下Java是怎么样处理自增的:
i++ 和 ++i原理
i++ 即后加加,原理是:先自增,然后返回自增之前的值
++i 即前加加,原理是:先自增,然后返回自增后的值
重点:这是一般人所不知道的,记住:不论是前++还是后++,都有个共同点是先自增。
1) ++i 原理,等价于
i = i+1;
return i;
2) i++ 原理,用代码分析表示如下:
int temp = i;
i = i + 1;
return temp;
这3句代表就是上面所说的那样:i++是先自增,然后返回自增之前的值;
PS:不同语言对自增的处理不太一样: 在C++中,“count=count++”与“count++”等价;在Java,PHP中处理方式如上述解析;不同语言,自己可以测试一下
PS:关于执行效率的认识:
i++:取出i,复制i,增加i,返回副本;
++i:取出i,增加i,返回i;
i++要增加一个副本,无疑是要多耗内存,当然效率要低一点,当然只是一丢丢罢了,根本不会对程序运行有明显的影响。
我看过一篇博客,作者的主旨是两者的效率一样,地址 http://www.cnblogs.com/anrainie/p/6610379.html
表示有距离感0.0,个人认为JVM也在不断优化,具体有待研究...
Java之戳中痛点 - (1)易变业务使用脚本语言编写
脚本语言的3大特征:
1、灵活:脚本语言一般是动态类型,可以不声明变量类型直接使用,也可以在运行期改变类型;
2、便捷:脚本语言是解释性语言,在运行期变更非常方便,而不用重启服务
3、简单:脚本语言语法比较简单,易学
另外:java6以上默认支持JavaScript
Java SE6加入了对JSR223的实现, JSR223旨在定义一个统一的规范,使得java应用程序可以通过一套固定的接口定义与各个脚本引擎交互,从而达到java平台上调用各个脚本语言的目的。
接口定义在javax.script下面。从而使java语言可以执行javascript,ruby,python等动态语言。
其中javascript的解析引擎是使用Mozilla Rhino不过是经过修改的。Mozilla Rhino是一个开源的java实现javascript的项目,jdk6中引入了Rhino1.6R2 版本,有了java对javascript的实现,对于java开发人员来说是一个非常便利事情。 下面将介绍如何在java代码中使用javascript。相关的实现在javax.script 包下面。
定义了 Invocable 、ScriptEngine 、ScriptEngineFactory 、Bindings 、ScriptContext 这5个主要接口。
例子:
package com.test;
import java.io.FileNotFoundException;
import java.io.FileReader;
import javax.script.Bindings;
import javax.script.Invocable;
import javax.script.ScriptContext;
import javax.script.ScriptEngine;
import javax.script.ScriptEngineManager;
import javax.script.ScriptException;
/**
* java执行脚本语言
* @author jd
*
*/
public class javascript {
public static void main(String[] args){
//获取一个JavaScript执行引擎
ScriptEngine se = new ScriptEngineManager().getEngineByName("javascript");
//声明上下文 变量
Bindings bind = se.createBindings();
bind.put("variable","结果:");
//变量的作用域,当前引擎范围内(常量ScriptContext.ENGINE_SCOPE表示的作用域对应的是当前的脚本引擎,而ScriptContext.GLOBAL_SCOPE表示的作用域对应的是从同一引擎工厂中创建出来的所有脚本引擎对象。前者的优先级较高。)
se.setBindings(bind,ScriptContext.ENGINE_SCOPE);
try {
//执行js代码
se.eval(new FileReader("E:/model.js"));
//是否可调用方法
if(se instanceof Invocable){
Invocable in = (Invocable) se;
//执行js的方法
String result = (String) in.invokeFunction("formula",2,10);
System.out.println(result);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (ScriptException e) {
e.printStackTrace();
} catch (NoSuchMethodException e) {
e.printStackTrace();
}
}
}
情景1:
function formula(a,b){
return variable+ (a*b);
}
结果:
结果:20
情景2:
function formula(a,b){
return variable+ (a+b);
}
结果:12
情景...
所以在变更业务时,不需要重启 java服务器,就可顺利变更业务,对于变更频繁的业务,这就是很好的解决方案。
PS:Java 6 不仅仅提供代码级的脚本内置,还提供了jrunscript命令工具,它可以在批处理中发挥巨大的效能,而且不需要通过JVM解释脚本语言,可直接通过该工具运行脚本;
Java之戳中痛点 - (2)取余用偶判断,不要用奇判断
取余判断原则:取余用偶判断,不要用奇判断
先看一个 程序:
package com.test;
import java.util.Scanner;
public class t1 {
public static void main(String[] args) {
//接收键盘输入
Scanner in = new Scanner(System.in);
while(in.hasNextInt()){
int i = in.nextInt();
System.out.println(i%2==1?"奇数":"偶数");
}
}
}
再看一下结果:

这里就有疑问了,结果怎么出现了-1为偶数
看一下java取余算法(%标识符)怎么计算取余,*模拟*方法实现:
//被除数 dividend 除数divisor
public static int remaindar(int dividend,int divisor){
return dividend - dividend/divisor*divisor;
}
分析方法发现 -1取余还是 -1,所以被认定为偶数;
正确写法:
package com.test;
import java.util.Scanner;
public class t1 {
public static void main(String[] args) {
//接收键盘输入
Scanner in = new Scanner(System.in);
while(in.hasNextInt()){
int i = in.nextInt();
System.out.println(i%2==0?"偶数":"奇数");
}
}
}
结果:

(5)switch语句break不能忘以及default不同位置的用法
先看一段代码:
public class Test{
public static void main(String[] args){
System.out.println("2 = "+ toNumberCase(2));
}
}
public static String toNumberCase(int n){
String str = "";
switch(n){
case 0: str = "我是0";
case 1: str = "我是1";
case 2: str = "我是2";
case 3: str = "我是3";
case 4: str = "我是4";
case 5: str = "我是5";
case 6: str = "我是6";
case 7: str = "我是7";
case 8: str = "我是8";
case 9: str = "我是9";
}
return str;
}
结果是 "2 = 我是2" ?其实不是,结果是

先来分析一下:
由于每个case语句后面少加了break关键字。程序从”case 2"后面的语句开始执行,直到找到break语句结束,可惜的是我们的程序中没有break语句,
于是在程序执行的过程中,str的赋值语句会执行多次,从等于"我是0"、等于"我是1”...等于"我是9",Switch语句执行结束了。于是结果就是如此了。
结论:switch-case语句,如果在每个case语句后面少加了break关键字。程序从该case分支继续执行下一个分支,直到遇见break后或执行完最后一个分支,switch语句执行结束。记住在case语句后面随手写上break语句,养成良好的习惯。
PS:对于此类问题,还有一个简单的解决办法:修改Eclipse的警告级别。Performaces->Java->Compiler->Errors/Warnings->Potential Programming->problems,然后修改'switch' case fall-through为Error级别,你如果没有在case语句中加入break,Eclipse会直接报错。
补充:defalut放在不同位置,对结果的影响
先看几个例子:
例子1:
package com.test;
public class testbreak {
public static void main(String[] args) {
System.out.println("10 = "+ toNumberCase(10));
}
public static String toNumberCase(int n){
String str = "";
switch(n){
default : str = "我是default";
case 0: str = "我是0"; break;
case 1: str = "我是1"; break;
case 2: str = "我是2"; break;
case 3: str = "我是3"; break;
case 4: str = "我是4"; break;
case 5: str = "我是5"; break;
case 6: str = "我是6"; break;
case 7: str = "我是7"; break;
case 8: str = "我是8"; break;
case 9: str = "我是9"; break;
}
return str;
}
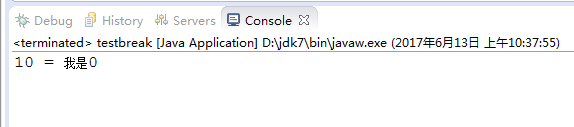
}
结果:
例子2:
package com.test;
public class testbreak {
public static void main(String[] args) {
System.out.println("10 = "+ toNumberCase(10));
}
public static String toNumberCase(int n){
String str = "";
switch(n){
case 0: str = "我是0"; break;
case 1: str = "我是1"; break;
case 2: str = "我是2"; break;
case 3: str = "我是3"; break;
case 4: str = "我是4"; break;
default : str = "我是default";
case 5: str = "我是5"; break;
case 6: str = "我是6"; break;
case 7: str = "我是7"; break;
case 8: str = "我是8"; break;
case 9: str = "我是9"; break;
}
return str;
}
}
结果:

例子3:
package com.test;
public class testbreak {
public static void main(String[] args) {
System.out.println("10 = "+ toNumberCase(10));
}
public static String toNumberCase(int n){
String str = "";
switch(n){
case 0: str = "我是0"; break;
case 1: str = "我是1"; break;
case 2: str = "我是2"; break;
case 3: str = "我是3"; break;
case 4: str = "我是4"; break;
case 5: str = "我是5"; break;
case 6: str = "我是6"; break;
case 7: str = "我是7"; break;
case 8: str = "我是8"; break;
case 9: str = "我是9"; break;
default : str = "我是default";
}
return str;
}
}
结果:

前3个例子,我把default放在不同的位置, 但是没有加break
接下来再看几个例子:
例子4:
package com.test;
public class testbreak {
public static void main(String[] args) {
System.out.println("10 = "+ toNumberCase(10));
}
public static String toNumberCase(int n){
String str = "";
switch(n){
default : str = "我是default"; break;
case 0: str = "我是0"; break;
case 1: str = "我是1"; break;
case 2: str = "我是2"; break;
case 3: str = "我是3"; break;
case 4: str = "我是4"; break;
case 5: str = "我是5"; break;
case 6: str = "我是6"; break;
case 7: str = "我是7"; break;
case 8: str = "我是8"; break;
case 9: str = "我是9"; break;
}
return str;
}
}
结果:

例子5:
package com.test;
public class testbreak {
public static void main(String[] args) {
System.out.println("10 = "+ toNumberCase(10));
}
public static String toNumberCase(int n){
String str = "";
switch(n){
case 0: str = "我是0"; break;
case 1: str = "我是1"; break;
case 2: str = "我是2"; break;
case 3: str = "我是3"; break;
case 4: str = "我是4"; break;
default : str = "我是default"; break;
case 5: str = "我是5"; break;
case 6: str = "我是6"; break;
case 7: str = "我是7"; break;
case 8: str = "我是8"; break;
case 9: str = "我是9"; break;
}
return str;
}
}
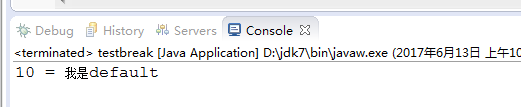
结果:
例子6:
package com.test;
public class testbreak {
public static void main(String[] args) {
System.out.println("10 = "+ toNumberCase(10));
}
public static String toNumberCase(int n){
String str = "";
switch(n){
case 0: str = "我是0"; break;
case 1: str = "我是1"; break;
case 2: str = "我是2"; break;
case 3: str = "我是3"; break;
case 4: str = "我是4"; break;
case 5: str = "我是5"; break;
case 6: str = "我是6"; break;
case 7: str = "我是7"; break;
case 8: str = "我是8"; break;
case 9: str = "我是9"; break;
default : str = "我是default"; break;
}
return str;
}
}
结果:

再看这3个例子,每个都加break
总结:
基础逻辑都是:default的运用,是当switch语句里,所有的case语句都不满足条件时,则执行default语句
在这里我们要分几种情况讨论:
default在switch开头:
若所有case都不满足条件,则执行default语句,并执行default语句之后的case语句,直到break或结束
default在switch中间:(同上)
若所有case都不满足条件,则执行default语句,并执行default语句之后的case语句,直到break或结束
default在switch末尾:
若所有case语句都不满足条件,则执行default语句,结束;若有case满足,则执行case语句直到遇到break或switch语句结束,所以default在最后一行时break可以省略不写(但是不建议省略,以求严谨)
Java之戳中痛点 - (7)善用Java整型缓存池
先看一段代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
package com.test;import java.util.Scanner;public class IntegerCache { public static void main(String[] args) { Scanner input = new Scanner(System.in); while(input.hasNextInt()){ int ii = input.nextInt(); System.out.println("===" + ii + "的相等判断 ==="); //通过两个new产生的Integer对象 Integer i = new Integer(ii); Integer j = new Integer(ii); System.out.println("new的对象:" + (i == j)); //基本类型转换为包装类型后比较 i = ii; j = ii; System.out.println("基本类型转换的对象:" + (i == j)); //通过静态方法生成的一个实例 i= Integer.valueOf(ii); j = Integer.valueOf(ii); System.out.println("valueOf的对象:" + (i == j)); } }} |
结果:

看看不同数据的测试结果,如果你感兴趣可以测试一下其他的数据,最后发现-128 到 127 基础类型转化的对象和valueOf转化的对象 == 是 true
下面解释一下原因:
1、new产生的Integer对象
new声明的就是要生成一个新的对象,2个对象比较内存地址肯定不相等,比较结果为false
2、装箱生成的对象
对于这一点首先要说明的是装箱动作是通过Integer.valueOf方法进行的。
Integer i = 100; (注意:不是 int i = 100; )
实际上,执行上面那句代码的时候,系统为我们执行了:Integer i = Integer.valueOf(100); 此即基本数据类型的自动装箱功能。
|
1
2
3
4
5
6
7
|
//valueOf如何生成对象:public static Integer valueOf(int i) { if (i >= IntegerCache.low && i <= IntegerCache.high) return IntegerCache.cache[i + (-IntegerCache.low)]; return new Integer(i);} |
这是JDK的源码,low=-128,h=127,这段代码意为如果是-128到127之间的int类型转换为Integer对象,则直接从IntegerCache里获取,来看看IntegerCache这个类
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
private static class IntegerCache { static final int low = -128; static final int high; // 内部静态数组,容纳-128到127之间的对象 static final Integer cache[]; static { // high value may be configured by property int h = 127; String integerCacheHighPropValue = sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high"); if (integerCacheHighPropValue != null) { try { int i = parseInt(integerCacheHighPropValue); i = Math.max(i, 127); // Maximum array size is Integer.MAX_VALUE h = Math.min(i, Integer.MAX_VALUE - (-low) -1); } catch( NumberFormatException nfe) { // If the property cannot be parsed into an int, ignore it. } } high = h; cache = new Integer[(high - low) + 1]; int j = low; for(int k = 0; k < cache.length; k++) cache[k] = new Integer(j++); // range [-128, 127] must be interned (JLS7 5.1.7) assert IntegerCache.high >= 127; } private IntegerCache() {}} |
结论:
在创建Integer对象,尽量少用new创建,尽量使用valueOf,利用整型池的提高系统性能,通过包装类的valueOf生成包装实例可以提高空间和时间性能。
另外:在判断对象是否相等的时候尽量使用equals方法,避免使用“==”产生非预期结果。
附1:
Integer 可以通过参数改变缓存范围(附:最大值 127 可以通过 JVM 的启动参数 -XX:AutoBoxCacheMax=size 修改)
-XX:AutoBoxCacheMax 这个参数是设置Integer缓存上限的参数。
理论上讲,当系统需要频繁使用Integer时,或者说堆内存中存在大量的Integer对象时,可以考虑提高Integer缓存上限,避免JVM重复创造对象,提高内存的使用率,减少GC的频率,从而提高系统的性能
理论归理论,这个参数能否提高系统系统关键还是要看堆中Integer对象到底有多少、以及Integer的创建的方式,如果堆中的Integer对象很少,重新设置这个参数并不会提高系统的性能。
即使堆中存在大量的Integer对象,也要看Integer对象是如何产生的
1. 大部分Integer对象通过Integer.valueOf()产生。说明代码里存在大量的拆箱与装箱操作。这时候设置这个参数会系统性能有所提高
2. 大部分Integer对象通过反射,new产生。这时候Integer对象的产生大部分不会走valueOf()方法,所以设置这个参数也是无济于事
附2:
其他缓存的对象:
这种缓存行为不仅适用于Integer对象。我们针对所有整数类型的类都有类似的缓存机制。
Byte 有 ByteCache 用于缓存 Byte 对象(-128 到 127)
Short 有 ShortCache 用于缓存 Short 对象(-128 到 127)
Long 有 LongCache 用于缓存 Long 对象(-128 到 127)
Character 有 CharacterCache 用于缓存 Character 对象(0 到 127)
Float 没有缓存
Doulbe 没有缓存
除了 Integer 可以通过参数改变范围外,其它的都不行。
附3:
关于垃圾回收器:
Integer i = 127;
i = null; //不会被垃圾回收器回收,这里的代码不会有对象符合垃圾回收器的条件,i 虽然被赋予null,但它之前指向的是cache中的Integer对象,而cache没有被赋null,所以Integer 127这个对象还是存在的
Integer i = 200;
i = null; //会被垃圾回收器回收,而如果 i 大于127或小于-128,则它所指向的对象将符合垃圾回收的条件

 浙公网安备 33010602011771号
浙公网安备 33010602011771号