【原创】分布式之数据库和缓存双写一致性方案解析(三) 前端面试送命题(二)-callback,promise,generator,async-await JS的进阶技巧 前端面试送命题(一)-JS三座大山 Nodejs的运行原理-科普篇 优化设计提高sql类数据库的性能 简单理解token机制
【原创】分布式之数据库和缓存双写一致性方案解析(三)
正文
博主本来觉得,《分布式之数据库和缓存双写一致性方案解析》,一文已经十分清晰。然而这一两天,有人在微信上私聊我,觉得应该要采用
先删缓存,再更新数据库,再删缓存这一方案作为缓存更新策略,而不是先更新数据库,再删缓存。并且搬出了两篇大佬的文章,《Cache Aside Pattern》,《缓存与数据库不一致,咋办?》,希望博主能加以说明。因为问的人太多了,所以才有了这篇文章的诞生。
正文
在开始这篇文章之前,我们先自己思考一下以下两个更新策略
方案一
(1)删缓存
(2)更数据库
(3)删缓存
方案二
(1)更数据库
(2)删缓存
大家看下面的文章前,自己先思考一下,方案一的步骤(1)有没有存在的必要?
先上一个结论:方案二存在的缺点,方案一全部存在,且方案一比方案二多一个步骤,所以应该选方案二。
下面,针对《Cache Aside Pattern》,《缓存与数据库不一致,咋办?》这两篇文章提出的论点,提出小小的质疑。这两篇文章认为方案二不行的原因,主要有以下两点
(1)方案二在步骤(2),出现删缓存失败的情况下,会出现数据不一致的情形,如下图所示
(2)方案二存在下面的主从同步,导致cache不一致问题,如下图所示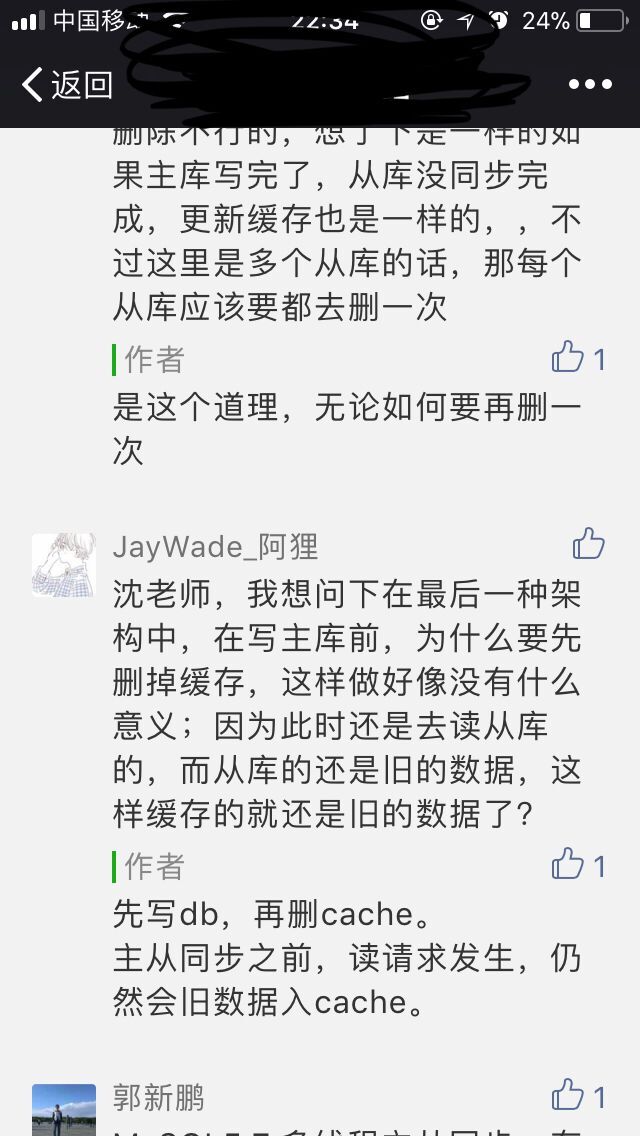
大致流程就是,线程A写,线程B读,会有以下流程出现
(1)缓存刚好失效
(2)线程A写入master数据库,slave还没同步
(3)线程B发现缓存失效,去slave读到旧值
(4)线程A删除缓存
(5)线程B把旧值放入缓存
然而大家发现了么,这两篇文章提出的反对意见,在该文作者自己所提出的方案一里头也是存在的?
(1)针对删缓存失败问题
方案一的步骤(3)也会可能出现删除缓存失败问题,可是作者没有加以详细说明。
(2)针对数据不一致问题
线程A写,线程B读,会有以下流程出现
(1)线程A删除缓存
(2)线程A写入master数据库,slave还没同步
(3)线程B发现缓存失效,去slave读到旧值
(4)线程A删除缓存
(5)线程B把旧值放入缓存
综上所述,我们应该选择方案二,而不是方案一。方案二存在的缺点,方案一全部存在,且方案一步骤上多了一步,增加了不稳定因素。
总结
该文章只是纠正了一下目前流传的观点的正确性,并没有针对任何人。技术的世界,只论技术。
前言
本篇文章适合前端架构师,或者进阶的前端开发人员;我在面试vmware前端架构师的时候,被问到关于callback,promise,generator,async-await的问题。
首先我们回顾一下javascript异步的发展历程。
ES6 以前:
回调函数(callback);nodejs express 中常用,ajax中常用。
ES6:
promise对象; nodejs最早有bluebird promise的雏形,axios中常用。
generator函数;nodejs koa框架使用率很高。
ES7:
async/await语法; 当前最常用的异步语法,nodejs koa2 完全使用该语法。
回调函数callback
回调函数实际就是一个参数;将一个函数当做参数传到另一个函数里,当那个函数执行完后,再执行传进去的这个函数;这个过程就叫做回调。
回调字面也好理解,就是先处理本体函数,再处理回调的函数,举个例子,方便大家理解。

function A(callback){
console.log("我是主体函数");
callback();
}
function B(){
console.log("我是回调函数");
}
A(B);
/*输出结果
我是主体函数
我是回调函数
*/
上面的例子很好理解,首先执行主体函数A,打印结果:我是主题函数;然后执行回调函数callback 也就是B,打印结果:我是回调函数。
promise对象
promise 对象用于一个异步操作的最终完成(或最终失败)及其结果的表示。
简单地说就是处理一个异步请求。我们经常会做些断言,如果我赢了你就嫁给我,如果输了我就嫁给你之类的断言。这就是promise的中文含义:断言,一个成功,一个失败。
举个例子,方便大家理解:
promise构造函数的参数是一个函数,我们把它称为处理器函数,处理器函数接收两个函数reslove和reject作为其参数,当异步操作顺利执行则执行reslove函数, 当异步操作中发生异常时,则执行reject函数。通过resolve传入得的值,可以在then方法中获取到,通过reject传入的值可以在chatch方法中获取到。
因为then和catch都返回一个相同的promise对象,所以可以进行链式调用。
function readFileByPromise("a.txt"){
//显示返回一个promise对象
return new Promise((resolve,reject)=>{
fs.readFile(path,"utf8",function(err,data){
if(err)
reject(err);
else
resolve(data);
})
})
}
//书写方式二
readFileByPromise("a.txt").then( data =>{
//打印文件中的内容
console.log(data);
}).catch( error =>{
//抛出异常,
console.log(error);
})
generator函数
ES6的新特性generator函数(面试的时候挂在这里),中文译为生成器,在以前一个函数中的代码要么被调用,要么不被调用,还不存在能暂停的情况,generator让代码暂停成待执行,定义一个生成器很简单,在函数名前加个*号,使用上也与普通函数有区别。
举个例子,方便大家理解:
function *Calculate(a,b){
let sum=a+b;
console.log(sum);
let sub=a-b;
console.log(sub);
}
上面便是一个简单的generator声明例子。
generator函数不能直接调用,直接调用generator函数会返回一个对象,只有调用该对象的next()方法才能执行函数里的代码。
let gen=Calculate(2,7);
执行该函数:
gen.next(); /*打印 9 -5 */
其实单独介绍generator并没有太大的价值,要配合key yield,才能真正发挥generator的价值。yield能将生Generator函数的代码逻辑分割成多个部分,下面改写上面的生成器函数。
function *Calculate(a,b){
let sum=a+b;
yield console.log(sum);
let sub=a-b;
yield console.log(sub);
}
let gen=Calculate(2,7);
gen.next();
/*输出
9*/
可以看到这段代码执行到第一个yield处就停止了,如果要让里边所有的代码都执行完就得反复调用next()方法
let gen=Calculate(2,7); gen.next(); gen.next(); /*输出 9 -5*/
在用一个例子,来说明generator函数与回调函数的区别:
回调函数:
fs.readFile("a.txt",(err,data)=>{
if(!err){
console.log(data);
fs.readFile("b.txt",(err,data)=>{
if(!err)
console.log(data);
})
}
})
这是一个典型的回调嵌套,过多的回调嵌套造成代码的可读性和可维护性大大降低,形成了令人深恶痛绝的回调地狱,试想如果有一天让你按顺序读取10个文件,那就得嵌套10层,再或者需求变更,读取顺序要变了先读b.txt,再度a.txt那改来真的不要太爽。
generator函数:
function readFile(path) {
fs.readFile(path,"utf8",function(err,data){
it.next(data);
})
}
function *main() {
var result1 = yield readFile("a.txt");
console.log(result1);
var result2 = yield readFile("b.txt");
console.log(result2);
var result3 = yield readFile("c.txt");
console.log(result3);
}
var it = main();
it.next();
generator函数的强大在于允许你通过一些实现细节来将异步过程隐藏起来,依然使代码保持一个单线程、同步语法的代码风格。这样的语法使得我们能够很自然的方式表达我们程序的步骤/语句流程,而不需要同时去操作一些异步的语法格式。
async-await
async函数返回一个promise对象,如果在async函数中返回一个直接量,async会通过Promise.resolve封装成Promise对象。
我们可以通过调用promise对象的then方法,获取这个直接量。
async function test(){
return "Hello World";
}
var result=test();
console.log(result);
//打印Promise { 'Hello World' }
那如过async函数不返回值,又会是怎么样呢?
async function test(){
}
var result=test();
console.log(result);
//打印Promise { undefined }
await会暂停当前async的执行,await会阻塞代码的执行,直到await后的表达式处理完成,代码才能继续往下执行。
await后的表达式既可以是一个Promise对象,也可以是任何要等待的值。
如果await等到的是一个 Promise 对象,await 就忙起来了,它会阻塞后面的代码,等着 Promise 对象 resolve,然后得到 resolve 的值,作为 await 表达式的运算结果。
上边你看到阻塞一词,不要惊慌,async/await只是一种语法糖,代码执行与多个callback嵌套调用没有区别,本质并不是同步代码,它只是让你思考代码逻辑的时候能够以同步的思维去思考,避开回调地狱,简而言之-async/await是以同步的思维去写异步的代码,所以async/await并不会影响node的并发数,大家可以大胆的应用到项目中去!
如果它等到的不是一个 Promise 对象,那 await 表达式的运算结果就是它等到的东西。
举个例子,方便大家理解:
function A() {
return "Hello ";
}
async function B(){
return "World";
}
async function C(){
//等待一个字符串
var s1=await A();
//等待一个promise对象,await的返回值是promise对象resolve的值,也就是"World"
var s2=await B();
console.log(s1+s2);
}
C();
//打印"Hello World"
前言
你真的了解JS吗,看完全篇,你可能对人生产生疑问。
typeof
typeof运算符,把类型信息当做字符串返回。
//正则表达式 是个什么 ? typeof /s/ // object //null typeof null // object
正则表达式并不是一个‘function’,而是一个object。在大多数语言中,null 代表的是一个空指针(0x00),但是在js中,null为一个object。
instanceof
instanceof运算符,用来测试一个对象在其原型链中是否存在一个构造函数:prototype
//语法 object instanceof constructor
function Person(){};
var p =new Person();
p instanceof Person; //true
但
[] instanceof window.frames[0].Array // false
因为 Array.prototype !== window.frames[0].Array.prototype ,因此,我们必须使用Array.isArray(obj)或者Object.prototype.toString.call(obj) === "[object Array]" 来判断obj是否为数组。
Object.prototype.toString
根据上面提到的,可以使用该方法获取对象类型的字符串。
//call的使用可以看博主前面的文章。(使用apply亦可) var toString = Object.prototype.toString; toString.call(new Date); // [object Date] toString.call(new String); // [object String] toString.call(Math); // [object Math] toString.call(/s/); // [object RegExp] toString.call([]); // [object Array] toString.call(undefined); // [object Undefined] toString.call(null); // [object Null]
作用域安全与构造函数
构造函数:使用new调用的函数,当使用new调用时,构造函数内的this会指向新创建的对象实例。
function Dog(name, age){
this.name = name;
this.age = age;
}
let dog = new Dog("柴犬", 5);
dog.name // 柴犬
如果我们没有使用new又会如何?
let dog = Dog("柴犬", 5);
dog.name // undefined
window.name // 柴犬
这是因为在没有使用new关键字时,this在当前情况被解析成window,所以属性就被分配到window上了。
function Dog(name, age){
if(this instanceof Dog){
this.name = name;
this.age = age;
}else{
return new Dog(name, age);
}
}
let dog1 = new Person("柴犬", 5);
dog1.name // 柴犬
let dog2 = Dog("柯基犬", 20);
dog2 .name // 柯基犬
使用上面的方法,就可以再不使用new的情况下,正常构造函数。
惰性载入函数
一个函数如下:
function foo(){
if(a != b){
console.log('111') //返回结果1
}else{
console.log('222') //返回结果2
}
}
a和b是不变的,那么无论执行多少次,结果都是不变的,但是每一次都要执行if判断语句,这样就造成了资源浪费。
而惰性载入函数,便可以解决这个问题。
function foo(){
if(a != b){
foo = function(){
console.log('111')
}
}else{
foo = function(){
console.log('222')
}
}
return foo();
}
var foo = (function foo(){
if(a != b){
return function(){
console.log('111')
}
}else{
return function(){
console.log('222')
}
}
})();
如上函数所示:第一次执行后便会对foo进行赋值,覆盖之前的函数,所以再次执行,便不会在执行if判断语句。
fun.bind(thisarg[,arg1[,arg2[,....]]])绑定函数
thisarg:当绑定函数被调用时,该参数会作为原函数运行时的this指向。当使用new时,该参数无效。
arg:当绑定时,这些参数将传递给被绑定的方法。
例子:
let person = {
name: 'addone',
click: function(e){
console.log(this.name)
}
}
let btn = document.getElementById('btn');
EventUtil.addHandle(btn, 'click', person.click);
这里创建了一个person对象,然后将person.click方法分配给DOM,但是当你按按钮时,会打印undefied,原因是this指向了DOM而不是person。
解决方法,当时是使用绑定函数了:
EventUtil.addHandle(btn, 'click', person.click.bind(person));
函数柯里化
柯里化是把接受多个参数的函数转变成接受单一参数的函数。
//简单例子,方便你明白柯里化
function add(num1, num2){
return num1 + num2;
}
function curryAdd(num2){
return add(1, num2);
}
add(2, 3) // 5
curryAdd(2) // 3
下面是柯里化函数的通用方法:
function curry(fn){
var args = Array.prototype.slice.call(arguments, 1);
return function(){
let innerArgs = Array.prototype.slice.call(arguments);
let finalArgs = args.concat(innerArgs);
return fn.apply(null, finalArgs);
}
}
Array.prototype.slice.call(arguments, 1)来获取第一个参数后的所有参数。在函数中,同样调用 Array.prototype.slice.call(arguments)让innerArgs存放所有的参数, 然后用contact将内部外部参数组合起来,用apply传递函数。
function add(num1, num2){
return num1 + num2;
}
let curryAdd1 = curry(add, 1);
curryAdd1(2); // 3
let curryAdd2 = curry(add, 1, 2);
curryAdd2(); // 3
不可扩展对象
默认情况下对象都是可扩展的,无论是扩展属性或是方法。
let dog = { name: '柴犬' };
dog.age = 5;
如第二行,我们为dog扩展了age属性。
使用Object.preventExtensions()可以阻止扩展行为。
let dog = { name: '柴犬' };
Object.preventExtensions(dog);
dog.age = 20;
dog.age // undefined
还可以使用 Object.isExtensible()来判断对象是否支持扩展。
let dog = { name: 'addone' };
Object.isExtensible(dog); // true
Object.preventExtensions(dog);
Object.isExtensible(dog); // false。
密封的对象
密封后的对象不可扩展,且不能删除属性和方法。
使用Object.seal()来进行密封。
let dog = { name: '柴犬' };
Object.seal(dog);
dog.age = 20;
delete dog.name;
dog.age // undefined
dog.name // 柴犬
当然也有Object.isSealed()来判断是否密封
let dog = { name: '柴犬' };
Object.isExtensible(dog); // true
Object.isSealed(dog); // false
Object.seal(dog);
Object.isExtensible(dog); // false
Object.isSealed(dog); // true
冻结对象
冻结对象为防篡改级别最高的,密封,且不能修改。
使用Object.freeze()来进行冻结。
let dog= { name: '柴犬' };
Object.freeze(dog);
dog.age = 20;
delete dog.name;
dog.name = '吉娃娃'
dog.age // undefined
dog.name // 柴犬
当然也有Object.isFrozen()来判断是否冻结
let dog = { name: '柴犬' };
Object.isExtensible(dog); // true
Object.isSealed(dog); // false
Object.isFrozen(dog); // false
Object.freeze(dog);
Object.isExtensible(dog); // false
Object.isSealed(dog); // true
Object.isFrozen(dog); // true
数组分块
浏览器对长时间运行的脚本进行了制约,如果运行时间超过特定时间或者特定长度,便不会继续执行。
如果发现某个循环占用了大量的时间,那么就要面对下面两个问题:
1.该循环是否必须同步完成?
2.数据是否必须按顺序完成?
如果是否,那么我们可以使用一种叫做数组分块的技术。基本思路是为要处理的项目创建一个列队,然后使用定时取出一个要处理的项目进行处理,以此类推。
function chunk(array, process, context){
setTimeout(function(){
// 取出下一个项目进行处理
let item = array.shift();
process.call(item);
if(array.length > 0){
setTimeout(arguments.callee, 100);
}
}, 100)
}
这里设置三个参数,要处理的数组,处理的函数,运行该函数的环境。
节流函数
节流函数目的是为了防止某些操作执行的太快,比如onresize,touch等事件。这种高频率的操作可能会使浏览器崩溃,为了避免这种情况,可以采用节流的方式。
function throttle(method, context){
clearTimeout(method.tId);
method.tId = setTimeout(function(){
method.call(context);
}, 100)
}
这里接收两个参数,要执行的函数,和执行的环境。执行时先clear之前的定时器,然后将当前定时器赋值给方法的tId,之后调用call来确定函数的执行环境。
function resizeDiv(){
let div = document.getElementById('div');
div.style.height = div.offsetWidth + "px";
}
window.onresize = function(){
throttle(resizeDiv);
}
前言
本篇文章比较适合3年以上的前端工作者,JS三座大山分别指:原型与原型链,作用域及闭包,异步和单线程。
原型与原型链
说到原型,就不得不提一下构造函数,首先我们看下面一个简单的例子:
function Dog(name,age){
this.name = name;
this.age = age;
}
let dog1 = new Dog("哈士奇",3);
let dog2 = new Dog("泰迪",2);
首先创造空的对象,再让this指向这个对象,通过this.name进行赋值,最终返回this,这其实也是new 一个对象的过程。
其实: let obj = {} 是 let obj = new Object()的语法糖; let arr = [] 是 let arr = new Array()的语法糖; function Dog(){...} 是 let Dog = new Fucntion()的语法糖。
那什么是原型那?在js中,所有对象都是Object的实例,并继承Object.prototype的属性和方法,但是有一些是隐性的。
我们来看一下原型的规则:
1.所有的引用类型(包括数组,对象,函数)都具有对象特性;可自由扩展属性。
var obj = {};
obj.attribute = "三座大山";
var arr = [];
arr.attribute = "三座大山";
function fn1 () {}
fn1.attribute = "三座大山";
2.所有的引用类型(包括数组,对象,函数)都有隐性原型属性(__proto__),值也是一个普通的对象。
console.log(obj.__proto__);
3.所有的函数,都有一个prototype属性,值也是一个普通的对象。
console.log(obj.prototype);
4.所有的引用类型的__proto__属性值都指向构造函数的prototype属性值。
console.log(obj.__proto__ === Object.prototype); // true
5.当试图获取对象属性时,如果对象本身没有这个属性,那就会去他的__proto__(prototype)中去寻找。
function Dog(name){
this.name = name;
}
Dog.prototype.callName = function (){
console.log(this.name,"wang wang");
}
let dog1 = new Dog("Three Mountain");
dog1.printName = function (){
console.log(this.name);
}
dog1.callName(); // Three Mountain wang wang
dog1.printName(); // Three Mountain
原型链:如下图。

我找一个属性,首先会在f.__proto__中去找,因为属性值为一个对象,那么就会去f.__proto__.__proto__去找,同理如果还没找到,就会一直向上去查找,直到结果为null为止。这个串起来的链即为原型链。
作用域及闭包
讲到作用域,你会想到什么?当然是执行上下文。每个函数都有自己的excution context,和variable object。这些环境用于储存上下文中的变量,函数声明,参数等。只有函数才能制造作用域。
PS:for if else 不能创造作用域。
console.log(a) ; // undefined var a = 1;
//可理解为
var a;
console.log(a); // undefined
a = 1;
执行console.log时,a只是被声明出来,并没有赋值;所以结果当然是undefined。
this
本质上来说,在js里this是一个指向函数执行环境的指针。this永远指向最后调用它的对象,并且在执行时才能获取值,定义是无法确认他的值。
var a = {
name : "A",
fn : function (){
console.log (this.name)
}
}
a.fn() // this === a
a 调用了fn() 所以此时this为a
a.fn.call ({name : "B"}) // this === {name : "B"}
使用call(),将this的值指定为{name:"B"}
var fn1 = a.fn
fn1() // this === window
虽然指定fn1 = a.fn,但是调用是有window调用,所以this 为window
this有多种使用场景,下面我会主要介绍4个使用场景:
1.作为构造函数执行
function Student(name,age) {
this.name = name // this === s
this.age = age // this === s
//return this
}
var s = new Student("py1988",30)
首先new 字段会创建一个空的对象,然后调用apply()函数,将this指向这个空对象。这样的话,函数内部的this就会被空对象代替。
2.作为普通函数执行
function fn () {
console.log (this) // this === window
}
fn ()
3.作为对象属性执行
var obj = {
name : "A",
printName : function () {
console.log (this.name) // this === obj
}
}
obj.printName ()
4.call(),apply(),bind()
三个函数可以修改this的指向,具体请往下看:
var name = "小明" , age = "17"
var obj = {
name : "安妮",
objAge : this.age,
fun : function () {
console.log ( this.name + "今年" + this.age )
}
}
console.log(obj.objAge) // 17
obj.fun() // 安妮今年undefined
var name = "小明" , age = "17"
var obj = {
name : "安妮",
objAge :this.age,
fun : function (like,dislike) {
console.log (this.name + "今年" + this.age ,"喜欢吃" + like + "不喜欢吃" + dislike)
}
}
var a = { name : "Jay", age : 23 }
obj.fun.call(a,"苹果","香蕉") // Jay今年23 喜欢吃苹果不喜欢吃香蕉
obj.fun.apply(a,["苹果","香蕉"]) // Jay今年23 喜欢吃苹果不喜欢吃香蕉
obj.fun.bind(a,"苹果","香蕉")() // Jay今年23 喜欢吃苹果不喜欢吃香蕉
首先call,apply,bind第一个参数都是this指向的对象,call和apply如果第一个参数指向null或undefined时,那么this会指向windows对象。
call,apply,bind的执行方式如上例所示。call,apply都是改变上下文中的this,并且是立即执行的。bind方法可以让对应的函数想什么时候调用就什么时候调用。
闭包
闭包的概念很抽象,看下面的例子你就会理解什么叫闭包了:
function a(){
var n = 0;
this.fun = function () {
n++;
console.log(n);
};
}
var c = new a();
c.fun(); //1
c.fun(); //2
闭包就是能够读取其他函数内部变量的函数。在js中只有函数内部的子函数才能读取局部变量。所以可以简单的理解为:定义在内部函数的函数。
用途主要有两个:
1)前面提到的,读取函数内部的变量。
2)让变量值始终保持在内存中。
异步和单线程
我们先感受下异步。
console.log("start");
setTimeout(function () {
console.log("medium");
}, 1000);
console.log("end");
使用异步后,打印的顺序为 start-> end->medium。因为没有阻塞。
为什么会产生异步呢?
首先因为js为单线程,也就是说CPU同一时间只能处理一个事务。得按顺序,一个一个处理。
如上例所示,第一步:执行第一行打印 “start”;第二步:执行setTimeout,将其中的函数分存起来,等待时间结束后执行;第三步:执行最后一行,打印“end”;第四部:处于空闲状态,查看暂存中,是否有可执行的函数;第五步:执行分存函数。
为什么js引擎是单线程?
js的主要用途是与用户互动,以及操作DOM,这决定它只能是单线程。例:一个线程要添加DOM节点,一个线程要删减DOM节点,容易造成分歧。
为了更好使用多CPU,H5提供了web Worker 标准,允许js创建多线程,但是子线程受到主线程控制,而且不得操作DOM。
任务列队
单线程就意味着,所有的任务都要排队,前一个结束,才会执行后面的任务。如果列队是因为计算量大,CPU忙不过来,倒也算了。但是更多的时候,CPU是闲置的,因为IO设备处理得很慢,例如 ajax读取网络数据。js设计者便想到,主线程完全可以不管IO设备,将其挂起,然后执行后面的任务。等后面的任务结束掉,在反过头来处理挂起的任务。
好,我们来梳理一下:
1)所有的同步任务都在主线程上执行,行程一个执行栈。
2)除了主线程之外,还存在一个任务列队,只要一步任务有了运行结果,就在任务列队中植入一个时间。
3)主线程完成所有任务,就会读取列队任务,并将其执行。
4)重复上面三步。
只要主线程空了,就会读取任务列队,这就是js的运行机制,也被称为 event loop(事件循环)。
前言
Nodejs目前处境稍显尴尬,很多语言都已经拥有异步非阻塞的能力。阿里的思路是比较合适的,但是必须要注意,绝对不能让node做太多的业务逻辑,他只适合接收生成好的数据,然后或渲染后,或直接发送到客户端。
为什么nodejs 还可以成为主流技术哪?
是因为nodejs 对于大前端来说还是非常重要的技术!!!如果你理解nodejs 的编程原理,很容易就会理解angularjs,reactjs 和vuejs 的设计原理。
NodeJS
Node是一个服务器端JavaScript解释器,用于方便地搭建响应速度快、易于扩展的网络应用。Node使用事件驱动,非阻塞I/O 模型而得以轻量和高效,非常适合在分布式设备上运行数据密集型的实时应用。
Node是一个可以让JavaScript运行在浏览器之外的平台。它实现了诸如文件系统、模块、包、操作系统 API、网络通信等Core JavaScript没有或者不完善的功能。历史上将JavaScript移植到浏览器外的计划不止一个,但Node.js 是最出色的一个。
V8引擎
V8 JavaScript引擎是Google用于其Chrome浏览器的底层JavaScript引擎。很少有人考虑JavaScript在客户机上实际做了些什么!
实际上,JavaScript引擎负责解释并执行代码。Google使用V8创建了一个用C++编写的超快解释器,该解释器拥有另一个独特特征;您可以下载该引擎并将其嵌入任何应用程序。V8 JavaScript引擎并不仅限于在一个浏览器中运行。
因此,Node实际上会使用Google编写的V8 JavaScript引擎,并将其重建为可在服务器上使用。
事件驱动
在我们使用Java,PHP等语言实现编程的时候,我们面向对象编程是完美的编程设计,这使得他们对其他编程方法不屑一顾。却不知大名鼎鼎Node使用的却是事件驱动编程的思想。那什么是事件驱动编程。
事件驱动编程,为需要处理的事件编写相应的事件处理程序。代码在事件发生时执行。
为需要处理的事件编写相应的事件处理程序。要理解事件驱动和程序,就需要与非事件驱动的程序进行比较。实际上,现代的程序大多是事件驱动的,比如多线程的程序,肯定是事件驱动的。早期则存在许多非事件驱动的程序,这样的程序,在需要等待某个条件触发时,会不断地检查这个条件,直到条件满足,这是很浪费cpu时间的。而事件驱动的程序,则有机会释放cpu从而进入睡眠态(注意是有机会,当然程序也可自行决定不释放cpu),当事件触发时被操作系统唤醒,这样就能更加有效地使用cpu。
来看一张简单的事件驱动模型(uml):

事件驱动模型主要包含3个对象:事件源、事件和事件处理程序。
事件源:产生事件的地方(html元素)
事件:点击/鼠标操作/键盘操作等等
事件对象:当某个事件发生时,可能会产生一个事件对象,该时间对象会封装好该时间的信息,传递给事件处理程序
事件处理程序:响应用户事件的代码
运行原理
当我们搜索Node.js时,夺眶而出的关键字就是 “单线程,异步I/O,事件驱动”,应用程序的请求过程可以分为俩个部分:CPU运算和I/O读写,CPU计算速度通常远高于磁盘读写速度,这就导致CPU运算已经完成,但是不得不等待磁盘I/O任务完成之后再继续接下来的业务。
所以I/O才是应用程序的瓶颈所在,在I/O密集型业务中,假设请求需要100ms来完成,其中99ms化在I/O上。如果需要优化应用程序,让他能同时处理更多的请求,我们会采用多线程,同时开启100个、1000个线程来提高我们请求处理,当然这也是一种可观的方案。
但是由于一个CPU核心在一个时刻只能做一件事情,操作系统只能通过将CPU切分为时间片的方法,让线程可以较为均匀的使用CPU资源。但操作系统在内核切换线程的同时也要切换线程的上线文,当线程数量过多时,时间将会被消耗在上下文切换中。所以在大并发时,多线程结构还是无法做到强大的伸缩性。
那么是否可以另辟蹊径呢?!我们先来看看单线程,《深入浅出Node》一书提到 “单线程的最大好处,是不用像多线程编程那样处处在意状态的同步问题,这里没有死锁的存在,也没有线程上下文切换所带来的性能上的开销”,那么一个线程一次只能处理一个请求岂不是无稽之谈,先让我们看张图:

Node.js的单线程并不是真正的单线程,只是开启了单个线程进行业务处理(cpu的运算),同时开启了其他线程专门处理I/O。当一个指令到达主线程,主线程发现有I/O之后,直接把这个事件传给I/O线程,不会等待I/O结束后,再去处理下面的业务,而是拿到一个状态后立即往下走,这就是“单线程”、“异步I/O”。
I/O操作完之后呢?Node.js的I/O 处理完之后会有一个回调事件,这个事件会放在一个事件处理队列里头,在进程启动时node会创建一个类似于While(true)的循环,它的每一次轮询都会去查看是否有事件需要处理,是否有事件关联的回调函数需要处理,如果有就处理,然后加入下一个轮询,如果没有就退出进程,这就是所谓的“事件驱动”。这也从Node的角度解释了什么是”事件驱动”。
在node.js中,事件主要来源于网络请求,文件I/O等,根据事件的不同对观察者进行了分类,有文件I/O观察者,网络I/O观察者。事件驱动是一个典型的生产者/消费者模型,请求到达观察者那里,事件循环从观察者进行消费,主线程就可以马不停蹄的只关注业务不用再去进行I/O等待。
优点
Node 公开宣称的目标是 “旨在提供一种简单的构建可伸缩网络程序的方法”。我们来看一个简单的例子,在 Java和 PHP 这类语言中,每个连接都会生成一个新线程,每个新线程可能需要 2 MB的配套内存。在一个拥有 8 GB RAM 的系统上,理论上最大的并发连接数量是 4,000 个用户。随着您的客户群的增长,如果希望您的 Web 应用程序支持更多用户,那么,您必须添加更多服务器。所以在传统的后台开发中,整个 Web 应用程序架构(包括流量、处理器速度和内存速度)中的瓶颈是:服务器能够处理的并发连接的最大数量。这个不同的架构承载的并发数量是不一致的。
而Node的出现就是为了解决这个问题:更改连接到服务器的方式。在Node 声称它不允许使用锁,它不会直接阻塞 I/O 调用。Node在每个连接发射一个在 Node 引擎的进程中运行的事件,而不是为每个连接生成一个新的 OS 线程(并为其分配一些配套内存)。
缺点
如上所述,nodejs的机制是单线程,这个线程里面,有一个事件循环机制,处理所有的请求。在事件处理过程中,它会智能地将一些涉及到IO、网络通信等耗时比较长的操作,交由worker threads去执行,执行完了再回调,这就是所谓的异步IO非阻塞吧。但是,那些非IO操作,只用CPU计算的操作,它就自己扛了,比如算什么斐波那契数列之类。它是单线程,这些自己扛的任务要一个接着一个地完成,前面那个没完成,后面的只能干等。因此,对CPU要求比较高的CPU密集型任务多的话,就有可能会造成号称高性能,适合高并发的node.js服务器反应缓慢。
适合场景
1、RESTful API
这是适合 Node 的理想情况,因为您可以构建它来处理数万条连接。它仍然不需要大量逻辑;它本质上只是从某个数据库中查找一些值并将它们组成一个响应。由于响应是少量文本,入站请求也是少量的文本,因此流量不高,一台机器甚至也可以处理最繁忙的公司的 API 需求。
2、实时程序
比如聊天服务
聊天应用程序是最能体现 Node.js 优点的例子:轻量级、高流量并且能良好的应对跨平台设备上运行密集型数据(虽然计算能力低)。同时,聊天也是一个非常值得学习的用例,因为它很简单,并且涵盖了目前为止一个典型的 Node.js 会用到的大部分解决方案。
3、单页APP
ajax很多。现在单页的机制似乎很流行,比如phonegap做出来的APP,一个页面包打天下的例子比比皆是。
总而言之,NodeJS适合运用在高并发、I/O密集、少量业务逻辑的场景
前言
在一个项目中,技术的统一性是最重要的,数据库的设计则是重点中的重点。NoSQL 是目前最流行的数据库,但是其实用性和功能性远不如sql数据库。
实际很多SQL数据库被诟病的性能问题大多是源于程序员的不合理设计,一个好的设计可以使sql类数据库提高几倍的性能。
1.细节的优化
字段尽量设置为not null 。
规范字段大小,越小越好。
表名规范前缀。
一个表尽量储存一个对象。
char永远比varchar更高效。
timestamp 比datetime小一倍。
避免字串ID。
单条查询最后用limit 1。
不用mysql内置函数,因为不会建立查询缓存。
使用ip而不是域名作为数据库的路径,避免dns解析。
2.使用sql内置功能
例如trigger,procedure,event...等等,可以有效减少后端代码的运用,但是不适合处理高触发的项目。
3.选择适合的存储引擎
最常见的就是InnoDB 与 MyISAM. 两者区别请自行百度。
4.将数据保存至内存中
从内存中读取数据,最大限度减少磁盘的操作,相关内容会在后面详细解释。
5.提高磁盘读写速度
6.充分使用索引 INDEX
|
1
2
|
mysql> DROP INDEX index_name ON tab; //添加indexmysql> ALTER TABLE tab DROP INDEX index_name ; //删除index |
7.使用内存磁盘
现在基础设施都过硬,所以可以将sql 目录迁移到内存磁盘上。
8.读写分离设计
随着系统变得越来越庞大,特别是当它们拥有很差的SQL时,一台数据库服务器通常不足以处理负载。但是多个数据库意味着重复,除非你对数据进行了分离。更一般地,这意味着建立主/从副本系统,其中程序会对主库编写所有的Update、Insert和Delete变更语句,而所有Select的数据都读取自从数据库(或者多个从数据库)。
尽管概念上很简单,但是想要合理、精确地实现并不容易,这可能需要大量的代码工作。因此,即便在开始时使用同一台数据库服务器,也要尽早计划在php中使用分离的DB连接来进行读写操作。如果正确地完成该项工作,那么系统就可以扩展到2台、3台甚至12台服务器,并具备高可用性和稳定性。
9.使用memcache或者redis
之前的博客有相关的介绍。
10.SQL数据库分散式布局
将数据库分散到多个服务器上,分担数据库工作压力。
在简单理解cookie/session机制这篇文章中,简要阐述了cookie和session的原理。本文将要简单阐述另一个同cookie/session同样重要的技术术语:token。
什么是token
token的意思是“令牌”,是服务端生成的一串字符串,作为客户端进行请求的一个标识。
当用户第一次登录后,服务器生成一个token并将此token返回给客户端,以后客户端只需带上这个token前来请求数据即可,无需再次带上用户名和密码。
简单token的组成;uid(用户唯一的身份标识)、time(当前时间的时间戳)、sign(签名,token的前几位以哈希算法压缩成的一定长度的十六进制字符串。为防止token泄露)。
身份认证概述
由于HTTP是一种没有状态的协议,它并不知道是谁访问了我们的应用。这里把用户看成是客户端,客户端使用用户名还有密码通过了身份验证,不过下次这个客户端再发送请求时候,还得再验证一下。
通用的解决方法就是,当用户请求登录的时候,如果没有问题,在服务端生成一条记录,在这个记录里可以说明登录的用户是谁,然后把这条记录的id发送给客户端,客户端收到以后把这个id存储在cookie里,下次该用户再次向服务端发送请求的时候,可以带上这个cookie,这样服务端会验证一下cookie里的信息,看能不能在服务端这里找到对应的记录,如果可以,说明用户已经通过了身份验证,就把用户请求的数据返回给客户端。
以上所描述的过程就是利用session,那个id值就是sessionid。我们需要在服务端存储为用户生成的session,这些session会存储在内存,磁盘,或者数据库。
基于token机制的身份认证
使用token机制的身份验证方法,在服务器端不需要存储用户的登录记录。大概的流程:
客户端使用用户名和密码请求登录。服务端收到请求,验证用户名和密码。验证成功后,服务端会生成一个token,然后把这个token发送给客户端。客户端收到token后把它存储起来,可以放在cookie或者Local Storage(本地存储)里。客户端每次向服务端发送请求的时候都需要带上服务端发给的token。服务端收到请求,然后去验证客户端请求里面带着token,如果验证成功,就向客户端返回请求的数据。
利用token机制进行登录认证,可以有以下方式:
a.用设备mac地址作为token
客户端:客户端在登录时获取设备的mac地址,将其作为参数传递到服务端
服务端:服务端接收到该参数后,便用一个变量来接收,同时将其作为token保存在数据库,并将该token设置到session中。客户端每次请求的时候都要统一拦截,将客户端传递的token和服务器端session中的token进行对比,相同则登录成功,不同则拒绝。
此方式客户端和服务端统一了唯一的标识,并且保证每一个设备拥有唯一的标识。缺点是服务器端需要保存mac地址;优点是客户端无需重新登录,只要登录一次以后一直可以使用,对于超时的问题由服务端进行处理。
b.用sessionid作为token
客户端:客户端携带用户名和密码登录
服务端:接收到用户名和密码后进行校验,正确就将本地获取的sessionid作为token返回给客户端,客户端以后只需带上请求的数据即可。
此方式的优点是方便,不用存储数据,缺点就是当session过期时,客户端必须重新登录才能请求数据。
当然,对于一些保密性较高的应用,可以采取两种方式结合的方式,将设备mac地址与用户名密码同时作为token进行认证。
APP利用token机制进行身份认证
用户在登录APP时,APP端会发送加密的用户名和密码到服务器,服务器验证用户名和密码,如果验证成功,就会生成相应位数的字符产作为token存储到服务器中,并且将该token返回给APP端。
以后APP再次请求时,凡是需要验证的地方都要带上该token,然后服务器端验证token,成功返回所需要的结果,失败返回错误信息,让用户重新登录。其中,服务器上会给token设置一个有效期,每次APP请求的时候都验证token和有效期。
token的存储
token可以存到数据库中,但是有可能查询token的时间会过长导致token丢失(其实token丢失了再重新认证一个就好,但是别丢太频繁,别让用户没事儿就去认证)。
为了避免查询时间过长,可以将token放到内存中。这样查询速度绝对就不是问题了,也不用太担心占据内存,就算token是一个32位的字符串,应用的用户量在百万级或者千万级,也是占不了多少内存的。
token的加密
token是很容易泄露的,如果不进行加密处理,很容易被恶意拷贝并用来登录。加密的方式一般有:
在存储的时候把token进行对称加密存储,用到的时候再解密。文章最开始提到的签名sign:将请求URL、时间戳、token三者合并,通过算法进行加密处理。
最好是两种方式结合使用。
还有一点,在网络层面上token使用明文传输的话是非常危险的,所以一定要使用HTTPS协议。
总结
以上就是对于token在用户身份认证过程中的简单总结。希望没有技术背景的产品经理们在和开发哥哥沟通的时候不要再被这些技术术语问住了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号