【转】.NET(C#):浅谈程序集清单资源和RESX资源 关于单元测试的思考--Asp.Net Core单元测试最佳实践 封装自己的dapper lambda扩展-设计篇 编写自己的dapper lambda扩展-使用篇 正确理解CAP定理 Quartz.NET的使用(附源码) 整理自己的.net工具库 GC的前世与今生 Visual Studio Package 插件开发之自动生
【转】.NET(C#):浅谈程序集清单资源和RESX资源
目录
程序集清单资源
在程序集中嵌入资源的最简单方法是什么?那就是使用Visual Studio中的“嵌入式资源(Embedded Resource)”创建选项,相当于使用csc的”/resource”参数。具体步骤,首先在Visual Studio的工程中选择资源文件,然后选择“属性”,接着在属性框中的Build Action中选择Embedded Resource,如下图,把a.file作为资源文件。

这个a.file成为嵌入资源后,它将会作为清单资源(Manifest Resource)存入程序集清单中(Assembly Manifest):

程序集清单是程序集不可缺少的元素,上图来自MSDN,可以参考更多关于程序集或者程序集清单的信息在这里:http://msdn.microsoft.com/zh-cn/library/1w45z383(v=VS.100).aspx,本文就不再多说了。
接下来要关心的是怎样使用程序集清单中的资源。
我们可以使用Assembly类的GetManifestResourceNames方法,返回程序集的所有清单资源的文件名。
或者Assembly.GetMenifestResourceStream方法返回指定资源的流。
比如刚才那个包含a.file的程序集。
var ass =Assembly.GetExecutingAssembly();
foreach(var file in ass.GetManifestResourceNames())
Console.WriteLine(file);
输出
Mgen.a.file
前面的Mgen是程序集的默认命名空间,VS在编译后会自动把命名空间加在文件名的前面的。
接下来使用GetManifestResourceStream来读取文件内容:
var ass =Assembly.GetExecutingAssembly();
var stream = ass.GetManifestResourceStream("Mgen.a.file");
/* 操作Stream对象来读取文件信息 */
RESX资源文件
另外一种创建资源的形式就是RESX资源文件,这个通过VS的添加文件中的“资源文件”类型。RESX文件相比手动创建上面讲的程序集清单资源最大的优势就是:
- 支持多语言
- 快速创建资源
- 管理方便
RESX可以支持多语言,Visual Studio编译后会出现附属程序集(satellite assembly),事实上是连接器(AL.exe)做这份工作。程序在执行在不同语言环境会搜索相应语言的资源。同时Visual Studio还提供了强大的RESX的资源编辑器。
同程序集清单资源一样,我们还是要弄懂所谓RESX资源到底是怎么存的。
现在,在工程中创建一个Resource1.resx,编辑它,添加一个b.file文件,再添加一个字符串,随便写个名称。
完成后,你会发现工程里多了些文件:

a.file是上面我们手动加的程序集清单资源。而Resource1.resx中的文件被存到了一个叫Resources的文件夹内(图中的b.file)。
检查这两个文件的属性中的Build Action,你会发现,Resources内的文件的Build Action都是None,VS不会对他们进行任何操作的,就好像他们不在工程里似的。而RESX文件的Build Action则是Embedded Resource,它会成为程序员清单资源,不同于不同程序集清单资源,RESX在编译时下面的Custom Tool是一个叫ResXFileCodeGenerator的工具:

这个工具会把所有RESX的资源连起来创建成一个二进制文件,VS最后把这个生成的文件最终作为程序集清单资源文件保存到程序集中。这个二进制资源文件的扩展名是.resources。
此时再运行上面讲的Assembly.GetManifestResourceNames方法来枚举程序集清单资源文件,输出会成:
Mgen.a.file
Mgen.Resource1.resources
Resource1.resx文件会最终编译成Mgen.Resource1.resources资源文件。
整个过程可以看这张图:

使用ResourceReader和ResourceSet解析二进制资源文件
建议先读这篇文章来先了解IResourceReader,IResourceWriter和ResourceSet类型:.NET(C#):使用IResourceReader,IResourceWriter和ResourceSet。这里就不在讲这三个类型的使用。
上面讲过,RESX资源文件最终会被编译成.resources扩展名的资源文件(二进制)并保存在程序集清单资源(assembly manifest resource)。
下面我们用.NET中的.resources二进制资源文件的解析类ResourceReader和ResourceSet来手动解析这个.resources文件。
代码:
//+ using System.Resources
staticvoid Main()
{
using (Stream resources =Assembly.GetExecutingAssembly().GetManifestResourceStream("Mgen.Resource1.resources"))
{
//使用IResourceReader
ReadUsingResourceReader(resources);
//重新定位Stream
resources.Seek(0, SeekOrigin.Begin);
//使用ResourceSet
ReadUsingResourceSet(resources);
}
}
//使用IResourceReader
staticvoid ReadUsingResourceReader(Stream st)
{
Console.WriteLine("== 使用IResourceReader");
IResourceReader rr =newResourceReader(st);
var iter = rr.GetEnumerator();
while (iter.MoveNext())
Console.WriteLine("键: {0} 值: {1}", iter.Key, iter.Value);
//不需要调用IResourceReader.Dispose,Stream会在Main方法中被Dipose
}
//使用ResourceSet
staticvoid ReadUsingResourceSet(Stream st)
{
Console.WriteLine("== 使用ResourceSet");
ResourceSet rs =newResourceSet(newResourceReader(st));
Console.WriteLine(BitConverter.ToString((byte[])rs.GetObject("b")));
Console.WriteLine(rs.GetString("String1"));
//不需要调用ResourceSet.Dispose,Stream会在Main方法中被Dipose
}
这将会以ResourceReader和ResourceSet两种方式输出b.file的字节内容和String1字符串。
使用ResourceManager解析二进制资源文件
关于ResourceManager类型的使用,可以参考:.NET(C#):使用ResourceManager类型。这里就不再多讲了。
我们就直接使用ResourceManager,还是上面的工程,用ResourceManager来解析这个.resources二进制的资源文件。
代码:
//+ using System.Resources
ResourceManager resManager =newResourceManager(typeof(Resource1));
//等效于:new ResourceManager("Mgen.Resource1", Assembly.GetExecutingAssembly());
//此时ResourceManager.BaseName是Type.FullName正好是Mgen.Resource1
//获取file.b的内容
Console.WriteLine(BitConverter.ToString((byte[])resManager.GetObject("b")));
//获取资源中的字符串
Console.WriteLine(resManager.GetString("String1"));
这将会输出b.file的字节内容和String1字符串。
小看RESX资源文件的Designer.cs文件
最后再让我们看看RESX资源文件后面的那个xxx.Designer.cs文件。

它定义了资源读取的一个类,比如资源文件名称是Resource1,这个类的名称就是Resource1。这个类其实就是内部包装了一个上面讲的ResourceManager,并且根据用户RESX定义的资源数据显示的定义具有强类型的属性值用来读取文件。
其内部ResourceManager是这样被初始化的,可以看到,ResourceManager.BaseName就是程序集清单资源的名称 (注意ResourceManager.BaseName属性没有CultureInfo名称和.resources扩展名,但是有命名空间(其实完全就 是文件名),所以本例中的Mgen.Resource1.resources程序集清单资源文件的ResourceManager初始化BaseName 就是:Mgen.Resource1。)
internalstaticglobal::System.Resources.ResourceManager ResourceManager {
get {
if (object.ReferenceEquals(resourceMan, null)) {
global::System.Resources.ResourceManager temp =newglobal::System.Resources.ResourceManager("Mgen.Resource1", typeof(Resource1).Assembly);
resourceMan = temp;
}
return resourceMan;
}
}
接着RESX中定义的文件b和字符串String1资源完全就是ResourceManager的方法的包装,比如b文件读取返回字节数组,就是调用ResourceManager.GetObject,然后转换成byte[]:
internalstaticbyte[] b {
get {
object obj = ResourceManager.GetObject("b", resourceCulture);
return ((byte[])(obj));
}
}
好了,就到这里吧,希望读者读完文章后对RESX文件和程序集清单资源有更好的理解!
关于单元测试的思考--Asp.Net Core单元测试最佳实践
2018-07-07 22:23 by 李玉宝, 615 阅读, 3 评论, 收藏, 编辑
在我们码字过程中,单元测试是必不可少的。但在从业过程中,很多开发者却对单元测试望而却步。有些时候并不是不想写,而是常常会碰到下面这些问题,让开发者放下了码字的脚步:
- 这个类初始数据太麻烦,你看:new MyService(new User("test",1), new MyDAO(new Connection(......)),new ToManyPropsClass(......) .....) 。我:。。。
- 这个代码内部逻辑都是和Cookie有关,我单元测试不好整啊,还是得启动到浏览器里一个按钮一个按钮点。
- 这个代码内部读了配置文件,单元测试也不能给我整个配置文件啊?
- 这个代码主要是验证WebAPI入口得模型绑定,必须得调用一次啊?
这些问题确实存在,但它们阻止不了我们那颗要写单元测试的心。单元测试的优点很多,你或许可以不管。但至少能让你从那些需要在浏览器里点击10多下的操作里解脱出来。本文从一个简单的逻辑测试出发,慢慢拉开测试的大幕,让你爱上测试。文章主要是传播一些单元测试的理念,其次才是介绍asp.net core中的单元测试。
本文使用的环境为asp.net core 2.1 webapi,代码可以直接下载:https://github.com/yubaolee/DotNetCoreUnitTestSamples 为了方便阅读,以一个最简单的逻辑为例:

public class UserService{
public bool CheckLogin(UserInfo user)
{
return user.Name == user.Password; //登录逻辑,为了看着舒服,少点
}
}
public class UserInfo{
public string Name { get; set; }
public string Password { get; set; }
}
测试的WebAPI控制器如下:
public class ValuesController : ControllerBase
{
private UserService _service;
public ValuesController(UserService service)
{
_service = service;
}
[HttpGet]
[Route("checklogin")]
public bool CheckLogin([FromQuery]UserInfo user)
{
return _service.CheckLogin(user);
}
}
都已准备完毕,那么,开始我们的表演吧:
普通业务的单元测试
public class TestService
{
private UserService _service;
[SetUp]
public void Init()
{
var server = new TestServer(WebHost.CreateDefaultBuilder().UseStartup<Startup>());
_service = server.Host.Services.GetService<UserService>();
}
[Test]
public void TestLogin()
{
bool result = _service.CheckLogin(new UserInfo { Name = "yubao", Password = "yubao" });
Assert.IsTrue(result);
}
}
在做业务测试过程中要善于使用注入功能,而不是使用new对象的方式,比如这里的Host.Services.GetService,防止出现new MyService(new User("test",1), new MyDAO(new Connection(......)),new ToManyPropsClass(......) .....)这种尴尬。用的越多你就越能体会这种做法的好处。我在openauth.net中使用的是autofac的AutofacServiceProvider。
测试Controller
很多时候我们需要测试顶层的controller(八成是controller里混的有业务逻辑)。这时我们可以快速的写出下面的测试代码:
public class TestController
{
private ValuesController _controller;
[SetUp]
public void Init()
{
var server = new TestServer(WebHost.CreateDefaultBuilder().UseStartup<Startup>());
_controller = server.Host.Services.GetService<ValuesController>();
}
[Test]
public void TestLogin()
{
bool result = _controller.CheckLogin(new UserInfo{Name = "yubao",Password = "yubao"});
Assert.IsTrue(result);
}
}
这段代码在JAVA spring mvc框架下是没有问题的,但在asp.net core 中,你会发现:

获取不到controller?spring mvc的理念就是万物皆服务,哪怕是一个controller也是一个普通的服务。但微软不喜欢这样,默认时它要掌控controller的生死(The Subtle Perils of Controller Dependency Injection in ASP.NET Core MVC 有人在声讨微软了)。所以我们不能通过普通的ServicCollection来注入和获取它,除非你指明Controller As Service,如下:
public void ConfigureServices(IServiceCollection services)
{
services.AddMvc().AddControllersAsServices().SetCompatibilityVersion(CompatibilityVersion.Version_2_1);
}
这时即可顺利测试通过。
测试含有HTTP上下文的业务逻辑,比如Cookie、URL中的QueryString
在平时的代码过程中,常常会和HTTP上下文HttpContext打交道,最常见的如request、response、cookie、querystring等,比如我们新的逻辑:
public class UserService
{
private IHttpContextAccessor _httpContextAccessor;
public UserService(IHttpContextAccessor httpContextAccessor)
{
_httpContextAccessor = httpContextAccessor;
}
public bool IsLogin()
{
return _httpContextAccessor.HttpContext.Request.Cookies["username"] != null;
}
}
这时如何测试呢?马丁福勒在他的大作《企业应用架构模式》中明确指出“测试桩”的概念,来应对这种情况。各种Mock框架应运而生。比如我最喜欢的Moq:
public class TestCookie
{
private UserService _service;
[SetUp]
public void Init()
{
var httpContextAccessorMock = new Mock<IHttpContextAccessor>();
httpContextAccessorMock.Setup(x => x.HttpContext.Request.Cookies["username"]).Returns("yubaolee");
var server = new TestServer(WebHost.CreateDefaultBuilder()
.ConfigureServices(u =>u.AddScoped(x =>httpContextAccessorMock.Object))
.UseStartup<Startup>());
_service = server.Host.Services.GetService<UserService>();
}
[Test]
public void TestLogin()
{
bool result = _service.IsLogin();
Assert.IsTrue(result);
}
}
测试一次HTTP请求
有时我们需要测试Mvc框架的模型绑定,看看一次客户端的请求是否能被正确解析,亦或者测试WebAPI入口的一些Filter AOP等是否被正确触发,这时就需要测试一次HTTP请求。从严格意义上来讲这种测试已经脱离的单元测试的范畴,属于集成测试。但这种测试代码可以节省我们大量的重复劳动。asp.net core中可以通过TestServer快速实现这种模拟:
public class TestHttpRequest
{
private TestServer _testServer;
[SetUp]
public void Init()
{
_testServer = new TestServer(WebHost.CreateDefaultBuilder().UseStartup<Startup>());
}
[Test]
public void TestLogin()
{
var client = _testServer.CreateClient();
var result = client.GetStringAsync("/api/values/checklogin?name=yubao&password=yubao");
Console.WriteLine(result.Result);
}
}
在进行单元测试的过程中,测试的理念(或者TDD的思维?)异常重要,它能帮助你构建和谐优美的代码。
给正在努力的您几条建议(附开源代码)
虽说今天不说技术,但我也整理了自己的开源项目(工具库、扩展库、仓储库等)分享给大家,希望大家互相学习。
Sikiro.Tookits.Files-基于NPOI的简单导入导出封装库
Sikiro.Tookits.LocalCache-本地缓存封装
Sikiro.Nosql.Mongo-基于原生驱动的mongo仓储层封装
Sikiro.DapperLambdaExtension.MsSql-基于dapper的lambda表达式扩展封装
Sikiro.NoSql.Redis-Redis仓储层封装
AutoBuildEntity-集成vs的生成实体插件
这也为了兑现去年在《整理自己的.net工具库》 所有承诺源码开放的诺言。好,废话不多说进入正文。
封装自己的dapper lambda扩展-设计篇
前言
昨天开源了业务业余时间自己封装的dapper lambda扩展,同时写了篇博文《编写自己的dapper lambda扩展-使用篇》简单的介绍了下其使用,今天将分享下它的设计思路
链式编程
其实就是将多个方法通过点(.)将它们串接起来,让代码更加简洁, 可读性更强。
new SqlConnection("").QuerySet<User>()
.Where(a => a.Name == "aasdasd")
.OrderBy(a => a.CreateTime)
.Top(10)
.Select(a => a.Name).ToList();
其原理是类的调用方法的返回值类型为类本身或其基类,选择返回基类的原因是为了做降级约束,例如我希望使用了Top之后接着Select和ToList,无法再用where或orderBy。
UML图

原型代码
CommandSet

public class CommandSet<T> : IInsert<T>, ICommand<T>
{
#region 方法
public int Insert(T entity)
{
throw new NotImplementedException();
}
public int Update(T entity)
{
throw new NotImplementedException();
}
public int Update(Expression<Func<T, T>> updateExpression)
{
throw new NotImplementedException();
}
public int Delete()
{
throw new NotImplementedException();
}
public IInsert<T> IfNotExists(Expression<Func<T, bool>> predicate)
{
throw new NotImplementedException();
}
public ICommand<T> Where(Expression<Func<T, bool>> predicate)
{
throw new NotImplementedException();
}
#endregion
}
public interface ICommand<T>
{
int Update(T entity);
int Update(Expression<Func<T, T>> updateExpression);
int Delete();
}
public interface IInsert<T>
{
int Insert(T entity);
}
public static class Database
{
public static QuerySet<T> QuerySet<T>(this SqlConnection sqlConnection)
{
return new QuerySet<T>();
}
public static CommandSet<T> CommandSet<T>(this SqlConnection sqlConnection)
{
return new CommandSet<T>();
}
}
QuerySet
public class QuerySet<T> : IAggregation<T>
{
#region 方法
public T Get()
{
throw new NotImplementedException();
}
public List<T> ToList()
{
throw new NotImplementedException();
}
public PageList<T> PageList(int pageIndex, int pageSize)
{
throw new NotImplementedException();
}
public List<T> UpdateSelect(Expression<Func<T, T>> @where)
{
throw new NotImplementedException();
}
public IQuery<TResult> Select<TResult>(Expression<Func<T, TResult>> selector)
{
throw new NotImplementedException();
}
public IOption<T> Top(int num)
{
throw new NotImplementedException();
}
public IOrder<T> OrderBy<TProperty>(Expression<Func<T, TProperty>> field)
{
throw new NotImplementedException();
}
public IOrder<T> OrderByDescing<TProperty>(Expression<Func<T, TProperty>> field)
{
throw new NotImplementedException();
}
public int Count()
{
throw new NotImplementedException();
}
public bool Exists()
{
throw new NotImplementedException();
}
public QuerySet<T> Where(Expression<Func<T, bool>> predicate)
{
throw new NotImplementedException();
}
#endregion
}
public interface IAggregation<T> : IOrder<T>
{
int Count();
bool Exists();
}
public interface IOrder<T> : IOption<T>
{
IOrder<T> OrderBy<TProperty>(Expression<Func<T, TProperty>> field);
IOrder<T> OrderByDescing<TProperty>(Expression<Func<T, TProperty>> field);
}
public interface IOption<T> : IQuery<T>, IUpdateSelect<T>
{
IQuery<TResult> Select<TResult>(Expression<Func<T, TResult>> selector);
IOption<T> Top(int num);
}
public interface IUpdateSelect<T>
{
List<T> UpdateSelect(Expression<Func<T, T>> where);
}
public interface IQuery<T>
{
T Get();
List<T> ToList();
PageList<T> PageList(int pageIndex, int pageSize);
}
以上为基本的设计模型,具体实现如有问题可以查看我的源码。
表达式树的解析
具体实现的时候会涉及到很多的表达式树的解析,例如where条件、部分字段update,而我实现的时候一共两步:先修树,再翻译。然而无论哪步都得对表达式树进行遍历。
表达式树
百度的定义:也称为“表达式目录树”,以数据形式表示语言级代码,它是一种抽象语法树或者说是一种数据结构。
我对它的理解是,它本质是一个二叉树,节点拥有自己的属性像nodetype。
而它的遍历方式为前序遍历
前序遍历
百度的定义:历首先访问根结点然后遍历左子树,最后遍历右子树。在遍历左、右子树时,仍然先访问根结点,然后遍历左子树,最后遍历右子树,以下图为例
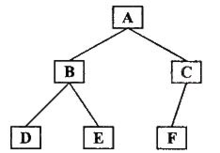
其遍历结果为:ABDECF
以一个实际例子:
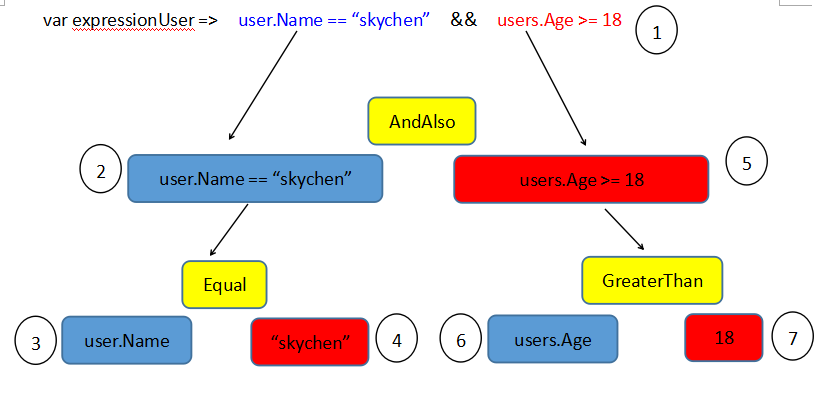
从上图可以看出,我们会先遍历到根节点的NodeType AndAlso翻译为 and ,然后到节点2,NodeType的Equal翻译为 = ,再到3节点翻译为 Name,再到4节点翻译为'skychen',那么将3、4节点拼接起来就为Name = 'skychen',如果类推6、7为Age >= 18,最后拼接这个语句为 Name = 'skychen' and Age >= 18。
修树
修树的目的,为了我们更好的翻译,例如DateTime.Now表达式树里的NodeType为MemberAccess,我希望转换成NodeType为Constant类型,以'2018-06-27 16:18:00'这个值作为翻译。
结束
以上为设计和实现的要点,具体的实现问题可以查看源码,如果有建议和疑问可以在下方留言,如果对您起到作用,希望您点一下推荐作为对我的支持。
再次双手奉上源码:https://github.com/SkyChenSky/Sikiro.DapperLambdaExtension.MsSql
编写自己的dapper lambda扩展-使用篇
前言
这是针对dapper的一个扩展,支持lambda表达式的写法,链式风格让开发者使用起来更加优雅、直观。现在暂时只有MsSql的扩展,也没有实现事务的写法,将会在后续的版本补充。
这是个人业余的开源小项目,如果大家有更好的实现方式和好的建议欢迎拍砖
本项目已经在github上开源了:Sikiro.DapperLambdaExtension.MsSql
去年写了《整理自己的.net工具库》,里面提供的源码重新发布到了github并用新的项目名Sikiro.Tookits
这两个项目都发布到Nuget上了,可以在Nuget搜索Sikiro可以全部查看到
另外该项目会用到一些表达式树的知识,如果有兴趣的朋友可以先去了解,我之前也写过一篇简单的文章《表达式树的解析.》
下面是简单的使用介绍
开始
Nuget
你可以运行以下下命令在你的项目中安装 Sikiro.DapperLambdaExtension.MsSql。
PM> Install-Package Sikiro.DapperLambdaExtension.MsSqlSqlConnection
var con = new SqlConnection("Data Source=192.168.13.46;Initial Catalog=SkyChen;Persist Security Info=True;User ID=sa;Password=123456789");定义User
[Table("SYS_USER")]
public class SysUser
{
/// <summary>
/// 主键
/// </summary>
[Key]
[Required]
[StringLength(32)]
[Display(Name = "主键")]
[Column("SYS_USERID")]
public string SysUserid { get; set; }
/// <summary>
/// 创建时间
/// </summary>
[Required]
[Display(Name = "创建时间")]
[Column("CREATE_DATETIME")]
public DateTime CreateDatetime { get; set; }
/// <summary>
/// 邮箱
/// </summary>
[Required]
[StringLength(32)]
[Display(Name = "邮箱")]
[Column("EMAIL")]
public string Email { get; set; }
/// <summary>
/// USER_STATUS
/// </summary>
[Required]
[Display(Name = "USER_STATUS")]
[Column("USER_STATUS")]
public int UserStatus { get; set; }
}Insert
con.CommandSet<SysUser>().Insert(new SysUser
{
CreateDatetime = DateTime.Now,
Email = "287245177@qq.com",
SysUserid = Guid.NewGuid().ToString("N"),
UserName = "chengong",
});当不存在某条件记录Insert
con.CommandSet<SysUser>().IfNotExists(a => a.Email == "287245177@qq.com").Insert(new SysUser
{
CreateDatetime = DateTime.Now,
Email = "287245177@qq.com",
SysUserid = Guid.NewGuid().ToString("N"),
UserName = "chengong",
});UPDATE
您可以根据某个条件把指定字段更新
con.CommandSet<SysUser>().Where(a => a.Email == "287245177@qq.com").Update(a => new SysUser { Email = "123456789@qq.com" });也可以根据主键来更新整个实体字段信息
User.Email = "123456789@qq.com";
condb.CommandSet<SysUser>().Update(User);DELETE
您可以根据条件来删除数据
con.CommandSet<SysUser>().Where(a => a.Email == "287245177@qq.com").Delete()QUERY
GET
获取过滤条件的一条数据(第一条)
con.QuerySet<SysUser>().Where(a => a.Email == "287245177@qq.com").Get()TOLIST
当然我们也可以查询出符合条件的数据集
con.QuerySet<SysUser>().Where(a => a.Email == "287245177@qq.com").OrderBy(b => b.Email).Top(10).Select(a => a.Email).ToList();PAGELIST
还有分页
con.QuerySet<SysUser>().Where(a => a.Email == "287245177@qq.com")
.OrderBy(a => a.CreateDatetime)
.Select(a => new SysUser { Email = a.Email, CreateDatetime = a.CreateDatetime, SysUserid = a.SysUserid })
.PageList(1, 10);UPDATESELECT
先更新再把结果查询出来
con.QuerySet<SysUser>().Where(a => a.Email == "287245177@qq.com")
.OrderBy(a => a.CreateDatetime)
.Select(a => new SysUser { Email = a.Email })
.UpdateSelect(a => new SysUser { Email = "2530665632@qq.com" });事务功能
con.Transaction(tc =>
{
var sysUserid = tc.QuerySet<SysUser>().Where(a => a.Email == "287245177@qq.com").Select(a => a.SysUserid).Get();
tc.CommandSet<SysUser>().Where(a => a.SysUserid == sysUserid).Delete();
tc.CommandSet<SysUser>().Insert(new SysUser
{
CreateDatetime = DateTime.Now,
Email = "287245177@qq.com",
Mobile = "13536059332",
RealName = "大笨贞",
SysUserid = Guid.NewGuid().ToString("N"),
UserName = "fengshuzhen",
UserStatus = 1,
UserType = 1,
Password = "asdasdad"
});
});最后来一个完整的DEMO
using (var con = new SqlConnection("Data Source=192.168.13.46;Initial Catalog=SkyChen;Persist Security Info=True;User ID=sa;Password=123456789"))
{
con.CommandSet<SysUser>().Insert(new SysUser
{
CreateDatetime = DateTime.Now,
Email = "287245177@qq.com",
SysUserid = Guid.NewGuid().ToString("N"),
UserName = "chengong",
});
var model = con.QuerySet<SysUser>().Where(a => a.Email == "287245177@qq.com").Get();
con.CommandSet<SysUser>().Where(a => a.SysUserid == model.SysUserid)
.Update(a => new SysUser { Email = "2548987@qq.com" });
con.CommandSet<SysUser>().Where(a => a.SysUserid == model.SysUserid).Delete();
}其他
除了简单的CURD还有Count、Sum、Exists
结束
第一个版本有未完善的地方,如果大家有很好的建议欢迎随时向我提,希望得到大家的建议后能良好的改善升级
正确理解CAP定理
前言
CAP的理解我也看了很多书籍,也看了不少同行的博文,基本每个人的理解都不一样,而布鲁尔教授得定义又太过的简单,没有具体描述和场景案例分析。因此自己参考部分资料梳理了一篇与大家互相分享一下。
标题写了正确理解,或许某些点不是百分百正确或者有歧义,但是希望与各位分享讨论后达到最终正确,
简介
CAP定理,又被称作布鲁尔定理(Brewer's theorem),是埃里克·布鲁尔教授在2000 年提出的一个猜想,它指出对于一个分布式系统来说,不可能同时满足以下三点:
- Consistency(一致性): where all nodes see the same data at the same time.(所有节点在同一时间具有相同的数据)
- Availability(可用性): which guarantees that every request receives a response about whether it succeeded or failed.(保证每个请求不管成功或者失败都有响应)
- Partition tolerance(分隔容忍): where the system continues to operate even if any one part of the system is lost or fails.(系统中任意信息的丢失或失败不会影响系统的继续运作)
很多书籍与文章引用Robert Greiner在2014年8月写的一篇博文 http://robertgreiner.com/2014/08/cap-theorem-revisited/。相比与看着布鲁尔教授一脸懵逼的定义,Robert Greiner的更加容易理解。
定义
原文:In a distributed system (a collection of interconnected nodes that share data.), you can only have two out of the following three guarantees across a write/read pair: Consistency, Availability, and Partition Tolerance - one of them must be sacrificed.
翻译:在一个分布式系统(指互相连接并共享数据的节点的集合)中,当涉及读写操作时,只能保证一致性(Consistence)、可用性(Availability)、分区容错性(Partition Tolerance)三者中的两个,另外一个必须被牺牲。
关键字:interconnected nodes(互连节点)、share data(共享数据)、a write/read pair(读/写)
从上面一段话,有几个,也就是说我们聊CAP定理的时候,是在具有数据读写、数据共享和节点互连的前提下,对上面三者选其二,也是建议我们不要花费时间与精力同时满足三者。
举例说明,web集群、memcached集群不属于讨论对象
- web集群只是资源复制分配在不同的节点上,然而节点间没有互连、也没有数据共享(sessionid、memory cache)。
- memcached集群数据存储是通过客户端实现哈希一致性,但是集群节点间不互连的,也没有数据共享。
总得来说,CAP定理讨论的并不是分布式系统所有的功能。
一致性(Consistency)
原文:A read is guaranteed to return the most recent write for a given client.
翻译:对某个指定的客户端来说,读操作保证能够返回最新的写操作结果
关键字:a given client(指定的客户端)。
这里的一致性与我们平常了解ACID的一致性有点偏差,ACID的一致性关注的是数据库的数据完整性。
上面定义没说明是所有节点必须在同一时间数据一致,而关注点在客户端,假如有个场景,您在ATM(客户端)往某张银行卡存500元后,立刻在ATM发起查询余额的时候会显示加了500元后的余额,随后我们也能把这500元取出来。查询余额读操作可以是写后立刻读的主库,也或者写后某个时间段过后(中途无写)读从库。
可用性(Availability)
原文:A non-failing node will return a reasonable response within a reasonable amount of time (no error or timeout).
翻译:非故障节点将在合理的时间内返回合理的响应(不是错误或超时)。
关键字:non-failing node(非故障节点)、reasonable response(合理的响应)
这里的可用性和我们平常所理解的高可用性有点偏差,高可用性指系统无中断的执行其功能的能力。
已故障的节点就不具有可用性了,因为请求结果要么error要么 timeout。合理的响应没有说明是成功还是失败,但是响应应该具有是否成功的精确描述。例如我们读取sql server集群的某从库,同步需要时间,读取出来可能不是最新的数据,但却是合理的响应。
分区容错性(Partition tolerance)
原文:The system will continue to function when network partitions occur.
翻译:当网络分区发生时,系统将继续正常运作
关键字:continue to function(继续正常运作)
假如做了一个redis的一主两从的集群,某天某个从节点因为网络故障变成不可用,但是另外的一主一从仍然能正常运作,那么我们认为它具有分区容错性。
CA-牺牲分区容错性
作为分布式系统,分区必然总会发生(2年1次50分钟还是1年3次共10分钟?),因此认为CAP的讨论是大部分建立在P确立前提下。假设我们牺牲了P这个时候因为网络故障发生了分区导致节点不可用,这个时候请求响应了error、timeout,与可用性的定义相冲突了。
但是,我们又假如分区大部分时间是不存在的,这时对单节点的读\写,那么就无需作出C、A的取舍。但是上面说分区总会发生这不互相矛盾么,还是取舍。假如1年时间内99.99%时间是正常的,不可用时间为0.01%(52.56分钟)不可用,若这个时间属于业务接受范围,或者只在某个地区(华南、华北、华中?)有影响,那么CA也是可以选择的。
PC-牺牲可用性
最典型的案例是RDBMS集群与Redis集群,这两种都是利用主从复制实现读写分离的方案。假如两者都是建立一主多从的集群,在主节点写入数据,为了保证随后的读操作获取最新数据(一致性),这个读操作仍会请求主节点(读写分离的复杂点在从库同步不及时导致业务的异常,为了保证业务的正常性写后的读会请求主库),某个从节点挂了但是只要主节点和其他从节点仍然正常运作,就满足分区容错性。但是哪天主节点因为网络故障导致写操作的error或者timeout,那么这个系统就不可用了(牺牲可用性)。
这个时候可以引入其他功能和机制完成,例如Redis哨兵模式、故障转移功能。
PA-牺牲一致性
最典型的案例是Cassanda集群和Riak集群,这种类型的分布式数据库,可以任意节点写入,任意节点读取,当作为集群出现,无论写入哪个节点,都将会把该节点的数据同步到其他节点上,因为这种同步方式,读取数据时只要访问一个节点就足够了(喜欢任意访问也不拦着你),但是因为其他节点数据同步原因,数据可能并不是最新的(牺牲一致性)。如果当前节点因为网络异常导致分区变得不可用(无论读\写),可以转移访问节点(可用性)。
另外这里说的牺牲一致性,并不代表放弃一致性,而PA选择的是最终一致性(系统中所有的数据副本,在经过一段时间的同步后,最终能够达到一个一致的状态)
总结
上面涉及“牺牲”字眼,并不代表非此即彼的选择,可以根据子系统、模块之间的设计上进行混搭使用(例如PA和PC、CA和PC)。
本文对CAP定理做了一个简单的梳理描述,参考了部分书籍和文章加上自己的理解希望可以跟大家做个分享,如果有不同建议和看法包括文章内描述错误,请在下方评论指出,我将及时作出修改。
Quartz.NET的使用(附源码)
简介
虽然Quartz.NET被园子里的大神们写烂了,自己还是整理了一篇,结尾会附上源码地址。
Quartz.NET是一款功能齐全的开源作业调度框架,小至的应用程序,大到企业系统都可以适用。Quartz是作者James House用JAVA语言编写的,而Quartz.NET是从Quartz移植过来的C#版本。
在一般企业,可以利用Quartz.Net框架做各种的定时任务,例如,数据迁移、跑报表等等。
另外还有一款Hangfire https://www.hangfire.io/,也是作业调度框架,有自带监控web后台,比Quartz.Net更加易用,简单。但是Cron最低只支持到分钟级。然而Hangfire不是今天的主角,有机会再介绍。
简单例子
新建一个控制台项目,通过Nuget管理下载Quartz包

using System;
using System.Collections.Specialized;
using Quartz;
using Quartz.Impl;
namespace QuartzDotNetDemo
{
class Program
{
static void Main(string[] args)
{
//创建一个调度器工厂
var props = new NameValueCollection
{
{ "quartz.scheduler.instanceName", "QuartzDotNetDemo" }
};
var factory = new StdSchedulerFactory(props);
//获取调度器
var sched = factory.GetScheduler();
sched.Start();
//定义一个任务,关联"HelloJob"
var job = JobBuilder.Create<HelloJob>()
.WithIdentity("myJob", "group1")
.Build();
//由触发器每40秒触发执行一次任务
var trigger = TriggerBuilder.Create()
.WithIdentity("myTrigger", "group1")
.StartNow()
.WithSimpleSchedule(x => x
.WithIntervalInSeconds(40)
.RepeatForever())
.Build();
sched.ScheduleJob(job, trigger);
}
}
public class HelloJob : IJob
{
public void Execute(IJobExecutionContext context)
{
Console.WriteLine("你好");
}
}
}
一个简单的调度任务流程如下:

概念
有几个重要类和概念需要了解一下:
- IScheduler - 与调度器交互的主要API.
- IJob -由执行任务实现的接口。
- IJobDetail - 定义Job实例
- ITrigger - 按照定义的时间让任务执行的组件.
- JobBuilder - 用于定义或者创建JobDetai
- TriggerBuilder -用于定义或生成触发器实例
他们之间的关系大概如下:

当有空闲线程同时,到了该执行的时间,那么就会由Trigger去触发绑定的Job执行它的Excute方法,假如这次没执行完,却到了下一次的运行时间,如果有空闲线程就仍然会再次执行。但是如果没有空闲线程,会等到腾出空闲的线程才会执行,但是超过quartz.jobStore.misfireThreshold设置的时间就会放弃这次的运行。
当然也可以在Job贴上DisallowConcurrentExecution标签让Job进行单线程跑,避免没跑完时的重复执行。
改造
在第一个简单的demo里是无法良好的在实际中使用,因此我们需要改造一下。
需要的第三方包:
- Autofac version="4.6.2"
- Autofac.Extras.Quartz version="3.4.0"
- Common.Logging version="3.4.1"
- Common.Logging.Core version="3.4.1"
- Common.Logging.Log4Net1213 version="3.4.1"
- log4net version="2.0.3"
- Newtonsoft.Json version="10.0.3"
- Quartz version="2.6.1"
- Topshelf version="4.0.3"
- Topshelf.Autofac version="3.1.1"
- Topshelf.Log4Net version="3.2.0"
- Topshelf.Quartz version="0.4.0.1"
Topshelf
Topshelf是一款为了方便安装部署在Windows系统下而诞生的宿主框架,它基于控制台项目,为开发人员带来更方便的调试和部署。
官网:https://topshelf.readthedocs.io/en/latest/index.html
那我们可以在Program.cs里写入以下代码:
using Topshelf;
using Topshelf.Autofac;
namespace QuartzDotNetDemo
{
class Program
{
static void Main(string[] args)
{
HostFactory.Run(config =>
{
config.SetServiceName(JobService.ServiceName);
config.SetDescription("Quartz.NET的demo");
config.UseLog4Net();
config.UseAutofacContainer(JobService.Container);
config.Service<JobService>(setting =>
{
JobService.InitSchedule(setting);
setting.ConstructUsingAutofacContainer();
setting.WhenStarted(o => o.Start());
setting.WhenStopped(o => o.Stop());
});
});
}
}
}
JobService
此类用来读取配置信息、初始化调度任务和注入ioc容器
public class JobService
{
#region 初始化
private static readonly ILog Log = LogManager.GetLogger(typeof(JobService));
private const string JobFile = "JobsConfig.xml";
private static readonly string JobNamespceFormat;
public static readonly string ServiceName;
private static readonly Jobdetail[] JobList;
public static IContainer Container;
static JobService()
{
var job = JobFile.XmlToObject<JobsConfig>();
ServiceName = job.Quartz.ServiceName;
JobNamespceFormat = job.Quartz.Namespace;
JobList = job.Quartz.JobList.JobDetail;
Log.Info("Jobs.xml 初始化完毕");
InitContainer();
}
#endregion
/// <summary>
/// 初始化调度任务
/// </summary>
/// <param name="svc"></param>
public static void InitSchedule(ServiceConfigurator<JobService> svc)
{
svc.UsingQuartzJobFactory(Container.Resolve<IJobFactory>);
foreach (var job in JobList)
{
svc.ScheduleQuartzJob(q =>
{
q.WithJob(JobBuilder.Create(Type.GetType(string.Format(JobNamespceFormat, job.JobName)))
.WithIdentity(job.JobName, ServiceName)
.Build);
q.AddTrigger(() => TriggerBuilder.Create()
.WithCronSchedule(job.Cron)
.Build());
Log.InfoFormat("任务 {0} 已完成调度设置", string.Format(JobNamespceFormat, job.JobName));
});
}
Log.Info("调度任务 初始化完毕");
}
/// <summary>
/// 初始化容器
/// </summary>
private static void InitContainer()
{
var builder = new ContainerBuilder();
builder.RegisterModule(new QuartzAutofacFactoryModule());
builder.RegisterModule(new QuartzAutofacJobsModule(typeof(JobService).Assembly));
builder.RegisterType<JobService>().AsSelf();
var execDir = Path.GetDirectoryName(Assembly.GetExecutingAssembly().Location);
var files = Directory.GetFiles(execDir, "QuartzDotNetDemo.*.dll", SearchOption.TopDirectoryOnly);
if (files.Length > 0)
{
var assemblies = new Assembly[files.Length];
for (var i = 0; i < files.Length; i++)
assemblies[i] = Assembly.LoadFile(files[i]);
builder.RegisterAssemblyTypes(assemblies)
.Where(t => t.GetInterfaces().ToList().Contains(typeof(IService)))
.AsSelf()
.InstancePerLifetimeScope();
}
Container = builder.Build();
Log.Info("IOC容器 初始化完毕");
}
public bool Start()
{
Log.Info("服务已启动");
return true;
}
public bool Stop()
{
Container.Dispose();
Log.Info("服务已关闭");
return false;
}
}
触发器类型
一共有4种:
- WithCalendarIntervalSchedule
- WithCronSchedule
- WithDailyTimeIntervalSchedule
- WithSimpleSchedule
在项目中使用的是WithCronSchedule,因为cron表达式更加灵活、方便。
Cron表达式
| 字段名 | 是否必填 | 值范围 | 特殊字符 |
|---|---|---|---|
| Seconds | YES | 0-59 | , - * / |
| Minutes | YES | 0-59 | , - * / |
| Hours | YES | 0-23 | , - * / |
| Day of month | YES | 1-31 | , - * ? / L W |
| Month | YES | 1-12 or JAN-DEC | , - * / |
| Day of week | YES | 1-7 or SUN-SAT | , - * ? / L # |
| Year | NO | empty, 1970-2099 | , - * / |
例子:
"0 0/5 * * * ?" ---- 每5分钟触发一次
"10 0/5 * * * ?" -----每5分钟触发一次,每分钟10秒(例如:10:00:10 am,10:05:10,等等)
"0 0/30 8-9 5,20 * ?" ----在每个月的第5到20个小时之间,每隔半小时就会触发一个触发点。请注意,触发器不会在上午10点触发,仅在8点,8点30分,9点和9点30分
BaseJob
我们定义一个BaseJob写入公共处理逻辑,例如:业务逻辑禁用、公共异常日志消息推送等等。再由具体的Job去继承重写基类的ExecuteJob,简单的适配器模式运用。
public abstract class BaseJob : IJob
{
protected readonly CommonService CommonService;
protected BaseJob(CommonService commonService)
{
CommonService = commonService;
}
public void Execute(IJobExecutionContext context)
{
//公共逻辑
CommonService.Enabled();
//job逻辑
ExecuteJob(context);
}
public abstract void ExecuteJob(IJobExecutionContext context);
}
结束
最后按照惯例双手奉上demo源码。https://github.com/SkyChenSky/QuartzDotNetDemo.git
整理自己的.net工具库
前言
今天我会把自己平日整理的工具库给开放出来,提供给有需要的朋友,如果有朋友平常也在积累欢迎提意见,我会乐意采纳并补充完整。按照惯例在文章结尾给出地址^_^。
之前我开放其他源码的时候(Framework.MongoDB、AutoBuildEntity),都有引用我的Framework工具库,但是为什么现在才开放出来呢原因有几点:
- 相对简单平常收集的朋友应该有很多
- 真想要可以去我开源代码反编译
- 被评论说Framework.dll有猫腻
首先借用社区里的88大哥一句话,开源的意义在于开源之后有其他公司可以深入底层,然后推出自己的产品和工具,这样生态就会越来越庞大。然而我的东西开源出去,为了配合文章让读者更方便的去理解,同时希望在我的基础上找到问题并改进。
做技术的,主要是开拓思路,通过模仿与交流后,你领悟的是你的,你学习到别人的也是你的。
但是!我并不提倡“面包已经给你了,非要等别人嚼碎了再喂到你嘴里?”。源码都已经给出去了,有问题只要主动调试一下,实在想知道里面干了什么就反编译一下,主动迈出这一步,问题解决了,想了解的了解到了,得到的经验和知识都是你的,何乐而不为呢?
本文章不针对也不是为了喷某人,一来我不希望自己“走歪路”告诫自己,二来提醒下刚入行的萌新。净化.net环境从我做起吧。
Framework功能点

- 验证标签(中文、邮箱、身份证、手机号)
- 集合根据条件去重扩展方法
- EmitMapper封装
- 加解密扩展方法
- 字符串扩展方法
- Object扩展方法
- 类型转换
- 本地缓存封装
- Log4net的封装
- HttpWeb的封装
- 有序guid的封装
- Json.net的封装
推荐书籍
简单介绍几本书介绍给大家看看
- 大话设计模式(可以反复多读几遍)
- CLR via C#(工具书有疑问就看)
- 重构 改善既有代码的设计
- NoSql精粹
- 微服务设计
结尾
双手奉上源码 https://github.com/SkyChenSky/Framework.Toolkits 。
下图是我在vs online上的源码,代码会在我整理好和文章一起放出,但是里面有部分完成度不高,所以得一步一步来。

GC的前世与今生
原文地址:http://kb.cnblogs.com/page/106720/
作者: spring yang
GC的前世与今生
虽然本文是以.NET作为目标来讲述GC,但是GC的概念并非才诞生不久。早在1958年,由鼎鼎大名的图林奖得主John McCarthy所实现的Lisp语言就已经提供了GC的功能,这是GC的第一次出现。Lisp的程序员认为内存管理太重要了,所以不能由程序员自己来管理。
但后来的日子里Lisp却没有成气候,采用内存手动管理的语言占据了上风,以C为代表。出于同样的理由,不同的人却又不同的看法,C程序员认为内存管理太重要了,所以不能由系统来管理,并且讥笑Lisp程序慢如乌龟的运行速度。的确,在那个对每一个Byte都要精心计算的年代GC的速度和对系统资源的大量占用使很多人的无法接受。而后,1984年由Dave Ungar开发的Smalltalk语言第一次采用了Generational garbage collection的技术(这个技术在下文中会谈到),但是Smalltalk也没有得到十分广泛的应用。
直到20世纪90年代中期GC才以主角的身份登上了历史的舞台,这不得不归功于Java的进步,今日的GC已非吴下阿蒙。Java采用VM(Virtual Machine)机制,由VM来管理程序的运行当然也包括对GC管理。90年代末期.NET出现了,.NET采用了和Java类似的方法由CLR(Common Language Runtime)来管理。这两大阵营的出现将人们引入了以虚拟平台为基础的开发时代,GC也在这个时候越来越得到大众的关注。
为什么要使用GC呢?也可以说是为什么要使用内存自动管理?有下面的几个原因:
1、提高了软件开发的抽象度;
2、程序员可以将精力集中在实际的问题上而不用分心来管理内存的问题;
3、可以使模块的接口更加的清晰,减小模块间的偶合;
4、大大减少了内存人为管理不当所带来的Bug;
5、使内存管理更加高效。
总的说来就是GC可以使程序员可以从复杂的内存问题中摆脱出来,从而提高了软件开发的速度、质量和安全性。
什么是GC
GC如其名,就是垃圾收集,当然这里仅就内存而言。Garbage Collector(垃圾收集器,在不至于混淆的情况下也成为GC)以应用程序的root为基础,遍历应用程序在Heap上动态分配的所有对象[2],通过识别它们是否被引用来确定哪些对象是已经死亡的、哪些仍需要被使用。已经不再被应用程序的root或者别的对象所引用的对象就是已经死亡的对象,即所谓的垃圾,需要被回收。这就是GC工作的原理。为了实现这个原理,GC有多种算法。比较常见的算法有Reference Counting,Mark Sweep,Copy Collection等等。目前主流的虚拟系统.NET CLR,Java VM和Rotor都是采用的Mark Sweep算法。
一、Mark-Compact 标记压缩算法
简单地把.NET的GC算法看作Mark-Compact算法。阶段1: Mark-Sweep 标记清除阶段,先假设heap中所有对象都可以回收,然后找出不能回收的对象,给这些对象打上标记,最后heap中没有打标记的对象都是可以被回收的;阶段2: Compact 压缩阶段,对象回收之后heap内存空间变得不连续,在heap中移动这些对象,使他们重新从heap基地址开始连续排列,类似于磁盘空间的碎片整理。

Heap内存经过回收、压缩之后,可以继续采用前面的heap内存分配方法,即仅用一个指针记录heap分配的起始地址就可以。主要处理步骤:将线程挂起→确定roots→创建reachable objects graph→对象回收→heap压缩→指针修复。可以这样理解roots:heap中对象的引用关系错综复杂(交叉引用、循环引用),形成复杂的graph,roots是CLR在heap之外可以找到的各种入口点。
GC搜索roots的地方包括全局对象、静态变量、局部对象、函数调用参数、当前CPU寄存器中的对象指针(还有finalization queue)等。主要可以归为2种类型:已经初始化了的静态变量、线程仍在使用的对象(stack+CPU register) 。 Reachable objects:指根据对象引用关系,从roots出发可以到达的对象。例如当前执行函数的局部变量对象A是一个root object,他的成员变量引用了对象B,则B是一个reachable object。从roots出发可以创建reachable objects graph,剩余对象即为unreachable,可以被回收 。
 指针修复是因为compact过程移动了heap对象,对象地址发生变化,需要修复所有引用指针,包括stack、CPU register中的指针以及heap中其他对象的引用指针。Debug和release执行模式之间稍有区别,release模式下后续代码没有引用的对象是unreachable的,而debug模式下需要等到当前函数执行完毕,这些对象才会成为unreachable,目的是为了调试时跟踪局部对象的内容。传给了COM+的托管对象也会成为root,并且具有一个引用计数器以兼容COM+的内存管理机制,引用计数器为0时,这些对象才可能成为被回收对象。Pinned objects指分配之后不能移动位置的对象,例如传递给非托管代码的对象(或者使用了fixed关键字),GC在指针修复时无法修改非托管代码中的引用指针,因此将这些对象移动将发生异常。pinned objects会导致heap出现碎片,但大部分情况来说传给非托管代码的对象应当在GC时能够被回收掉。
指针修复是因为compact过程移动了heap对象,对象地址发生变化,需要修复所有引用指针,包括stack、CPU register中的指针以及heap中其他对象的引用指针。Debug和release执行模式之间稍有区别,release模式下后续代码没有引用的对象是unreachable的,而debug模式下需要等到当前函数执行完毕,这些对象才会成为unreachable,目的是为了调试时跟踪局部对象的内容。传给了COM+的托管对象也会成为root,并且具有一个引用计数器以兼容COM+的内存管理机制,引用计数器为0时,这些对象才可能成为被回收对象。Pinned objects指分配之后不能移动位置的对象,例如传递给非托管代码的对象(或者使用了fixed关键字),GC在指针修复时无法修改非托管代码中的引用指针,因此将这些对象移动将发生异常。pinned objects会导致heap出现碎片,但大部分情况来说传给非托管代码的对象应当在GC时能够被回收掉。
二、 Generational 分代算法
程序可能使用几百M、几G的内存,对这样的内存区域进行GC操作成本很高,分代算法具备一定统计学基础,对GC的性能改善效果比较明显。将对象按照生命周期分成新的、老的,根据统计分布规律所反映的结果,可以对新、老区域采用不同的回收策略和算法,加强对新区域的回收处理力度,争取在较短时间间隔、较小的内存区域内,以较低成本将执行路径上大量新近抛弃不再使用的局部对象及时回收掉。分代算法的假设前提条件:
1、大量新创建的对象生命周期都比较短,而较老的对象生命周期会更长;
2、对部分内存进行回收比基于全部内存的回收操作要快;
3、新创建的对象之间关联程度通常较强。heap分配的对象是连续的,关联度较强有利于提高CPU cache的命中率,.NET将heap分成3个代龄区域: Gen 0、Gen 1、Gen 2;
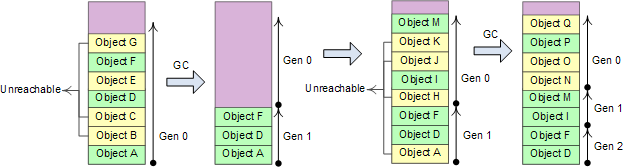
Heap分为3个代龄区域,相应的GC有3种方式: # Gen 0 collections, # Gen 1 collections, #Gen 2 collections。如果Gen 0 heap内存达到阀值,则触发0代GC,0代GC后Gen 0中幸存的对象进入Gen1。如果Gen 1的内存达到阀值,则进行1代GC,1代GC将Gen 0 heap和Gen 1 heap一起进行回收,幸存的对象进入Gen2。
2代GC将Gen 0 heap、Gen 1 heap和Gen 2 heap一起回收,Gen 0和Gen 1比较小,这两个代龄加起来总是保持在16M左右;Gen2的大小由应用程序确定,可能达到几G,因此0代和1代GC的成本非常低,2代GC称为full GC,通常成本很高。粗略的计算0代和1代GC应当能在几毫秒到几十毫秒之间完成,Gen 2 heap比较大时,full GC可能需要花费几秒时间。大致上来讲.NET应用运行期间,2代、1代和0代GC的频率应当大致为1:10:100。
三、Finalization Queue和Freachable Queue
这两个队列和.NET对象所提供的Finalize方法有关。这两个队列并不用于存储真正的对象,而是存储一组指向对象的指针。当程序中使用了new操作符在Managed Heap上分配空间时,GC会对其进行分析,如果该对象含有Finalize方法则在Finalization Queue中添加一个指向该对象的指针。
在GC被启动以后,经过Mark阶段分辨出哪些是垃圾。再在垃圾中搜索,如果发现垃圾中有被Finalization Queue中的指针所指向的对象,则将这个对象从垃圾中分离出来,并将指向它的指针移动到Freachable Queue中。这个过程被称为是对象的复生(Resurrection),本来死去的对象就这样被救活了。为什么要救活它呢?因为这个对象的Finalize方法还没有被执行,所以不能让它死去。Freachable Queue平时不做什么事,但是一旦里面被添加了指针之后,它就会去触发所指对象的Finalize方法执行,之后将这个指针从队列中剔除,这是对象就可以安静的死去了。
.NET Framework的System.GC类提供了控制Finalize的两个方法,ReRegisterForFinalize和SuppressFinalize。前者是请求系统完成对象的Finalize方法,后者是请求系统不要完成对象的Finalize方法。ReRegisterForFinalize方法其实就是将指向对象的指针重新添加到Finalization Queue中。这就出现了一个很有趣的现象,因为在Finalization Queue中的对象可以复生,如果在对象的Finalize方法中调用ReRegisterForFinalize方法,这样就形成了一个在堆上永远不会死去的对象,像凤凰涅槃一样每次死的时候都可以复生。
托管资源:
.NET中的所有类型都是(直接或间接)从System.Object类型派生的。
CTS中的类型被分成两大类——引用类型(reference type,又叫托管类型[managed type]),分配在内存堆上;值类型(value type),分配在堆栈上。如图:
值类型在栈里,先进后出,值类型变量的生命有先后顺序,这个确保了值类型变量在退出作用域以前会释放资源。比引用类型更简单和高效。堆栈是从高地址往低地址分配内存。
引用类型分配在托管堆(Managed Heap)上,声明一个变量在栈上保存,当使用new创建对象时,会把对象的地址存储在这个变量里。托管堆相反,从低地址往高地址分配内存,如图:
.NET中超过80%的资源都是托管资源。
非托管资源:
ApplicationContext, Brush, Component, ComponentDesigner, Container, Context, Cursor, FileStream, Font, Icon, Image, Matrix, Object, OdbcDataReader, OleDBDataReader, Pen, Regex, Socket, StreamWriter, Timer, Tooltip, 文件句柄, GDI资源, 数据库连接等等资源。可能在使用的时候很多都没有注意到!
.NET的GC机制有这样两个问题:
首先,GC并不是能释放所有的资源。它不能自动释放非托管资源。
第二,GC并不是实时性的,这将会造成系统性能上的瓶颈和不确定性。
GC并不是实时性的,这会造成系统性能上的瓶颈和不确定性。所以有了IDisposable接口,IDisposable接口定义了Dispose方法,这个方法用来供程序员显式调用以释放非托管资源。使用using语句可以简化资源管理。
示例:
///summary
/// 执行SQL语句,返回影响的记录数
////summary
///param name="SQLString"SQL语句/param
///returns影响的记录数/returns
publicstaticint ExecuteSql(string SQLString)
{
using (SqlConnection connection =new SqlConnection(connectionString))
{
using (SqlCommand cmd =new SqlCommand(SQLString, connection))
{
try
{
connection.Open();
int rows = cmd.ExecuteNonQuery();
return rows;
}
catch (System.Data.SqlClient.SqlException e)
{
connection.Close();
throw e;
}
finally
{
cmd.Dispose();
connection.Close();
}
}
}
}
当你用Dispose方法释放未托管对象的时候,应该调用GC.SuppressFinalize。如果对象正在终结队列(finalization queue), GC.SuppressFinalize会阻止GC调用Finalize方法。因为Finalize方法的调用会牺牲部分性能。如果你的Dispose方法已经对委托管资源作了清理,就没必要让GC再调用对象的Finalize方法(MSDN)。附上MSDN的代码,大家可以参考。
publicclass BaseResource : IDisposable
{
// 指向外部非托管资源
private IntPtr handle;
// 此类使用的其它托管资源.
private Component Components;
// 跟踪是否调用.Dispose方法,标识位,控制垃圾收集器的行为
privatebool disposed =false;
// 构造函数
public BaseResource()
{
// Insert appropriate constructor code here.
}
// 实现接口IDisposable.
// 不能声明为虚方法virtual.
// 子类不能重写这个方法.
publicvoid Dispose()
{
Dispose(true);
// 离开终结队列Finalization queue
// 设置对象的阻止终结器代码
//
GC.SuppressFinalize(this);
}
// Dispose(bool disposing) 执行分两种不同的情况.
// 如果disposing 等于 true, 方法已经被调用
// 或者间接被用户代码调用. 托管和非托管的代码都能被释放
// 如果disposing 等于false, 方法已经被终结器 finalizer 从内部调用过,
//你就不能在引用其他对象,只有非托管资源可以被释放。
protectedvirtualvoid Dispose(bool disposing)
{
// 检查Dispose 是否被调用过.
if (!this.disposed)
{
// 如果等于true, 释放所有托管和非托管资源
if (disposing)
{
// 释放托管资源.
Components.Dispose();
}
// 释放非托管资源,如果disposing为 false,
// 只会执行下面的代码.
CloseHandle(handle);
handle = IntPtr.Zero;
// 注意这里是非线程安全的.
// 在托管资源释放以后可以启动其它线程销毁对象,
// 但是在disposed标记设置为true前
// 如果线程安全是必须的,客户端必须实现。
}
disposed =true;
}
// 使用interop 调用方法
// 清除非托管资源.
[System.Runtime.InteropServices.DllImport("Kernel32")]
privateexternstatic Boolean CloseHandle(IntPtr handle);
// 使用C# 析构函数来实现终结器代码
// 这个只在Dispose方法没被调用的前提下,才能调用执行。
// 如果你给基类终结的机会.
// 不要给子类提供析构函数.
~BaseResource()
{
// 不要重复创建清理的代码.
// 基于可靠性和可维护性考虑,调用Dispose(false) 是最佳的方式
Dispose(false);
}
// 允许你多次调用Dispose方法,
// 但是会抛出异常如果对象已经释放。
// 不论你什么时间处理对象都会核查对象的是否释放,
// check to see if it has been disposed.
publicvoid DoSomething()
{
if (this.disposed)
{
thrownew ObjectDisposedException();
}
}
// 不要设置方法为virtual.
// 继承类不允许重写这个方法
publicvoid Close()
{
// 无参数调用Dispose参数.
Dispose();
}
publicstaticvoid Main()
{
// Insert code here to create
// and use a BaseResource object.
}
}
GC.Collect() 方法
作用:强制进行垃圾回收。
GC的方法:
|
名称 |
说明 |
|
Collect() |
强制对所有代进行即时垃圾回收。 |
|
Collect(Int32) |
强制对零代到指定代进行即时垃圾回收。 |
|
Collect(Int32, GCCollectionMode) |
强制在 GCCollectionMode 值所指定的时间对零代到指定代进行垃圾回收 |
GC注意事项:
1、只管理内存,非托管资源,如文件句柄,GDI资源,数据库连接等还需要用户去管理。
2、循环引用,网状结构等的实现会变得简单。GC的标志-压缩算法能有效的检测这些关系,并将不再被引用的网状结构整体删除。
3、GC通过从程序的根对象开始遍历来检测一个对象是否可被其他对象访问,而不是用类似于COM中的引用计数方法。
4、GC在一个独立的线程中运行来删除不再被引用的内存。
5、GC每次运行时会压缩托管堆。
6、你必须对非托管资源的释放负责。可以通过在类型中定义Finalizer来保证资源得到释放。
7、对象的Finalizer被执行的时间是在对象不再被引用后的某个不确定的时间。注意并非和C++中一样在对象超出声明周期时立即执行析构函数
8、Finalizer的使用有性能上的代价。需要Finalization的对象不会立即被清除,而需要先执行Finalizer.Finalizer,不是在GC执行的线程被调用。GC把每一个需要执行Finalizer的对象放到一个队列中去,然后启动另一个线程来执行所有这些Finalizer,而GC线程继续去删除其他待回收的对象。在下一个GC周期,这些执行完Finalizer的对象的内存才会被回收。
9、.NET GC使用"代"(generations)的概念来优化性能。代帮助GC更迅速的识别那些最可能成为垃圾的对象。在上次执行完垃圾回收后新创建的对象为第0代对象。经历了一次GC周期的对象为第1代对象。经历了两次或更多的GC周期的对象为第2代对象。代的作用是为了区分局部变量和需要在应用程序生存周期中一直存活的对象。大部分第0代对象是局部变量。成员变量和全局变量很快变成第1代对象并最终成为第2代对象。
10、GC对不同代的对象执行不同的检查策略以优化性能。每个GC周期都会检查第0代对象。大约1/10的GC周期检查第0代和第1代对象。大约1/100的GC周期检查所有的对象。重新思考Finalization的代价:需要Finalization的对象可能比不需要Finalization在内存中停留额外9个GC周期。如果此时它还没有被Finalize,就变成第2代对象,从而在内存中停留更长时间。
Visual Studio Package 插件开发之自动生成实体工具
前言
这一篇是VS插件基于Visual Studio SDK扩展开发的,可能有些朋友看到【生成实体】心里可能会暗想,T4模板都可以做了、动软不是已经做了么、不就是读库保存文件到指定路径么……
我希望做的效果是:
1.工具集成到vs上
2.动作完成后体现到项目(添加、删除项目项)
3.使用简单、轻量、灵活(配置化)
4.不依赖ORM(前两点有点像EF的DBFirst吧?)
文章最后会给上源码地址。
下面是效果图:

处理流程
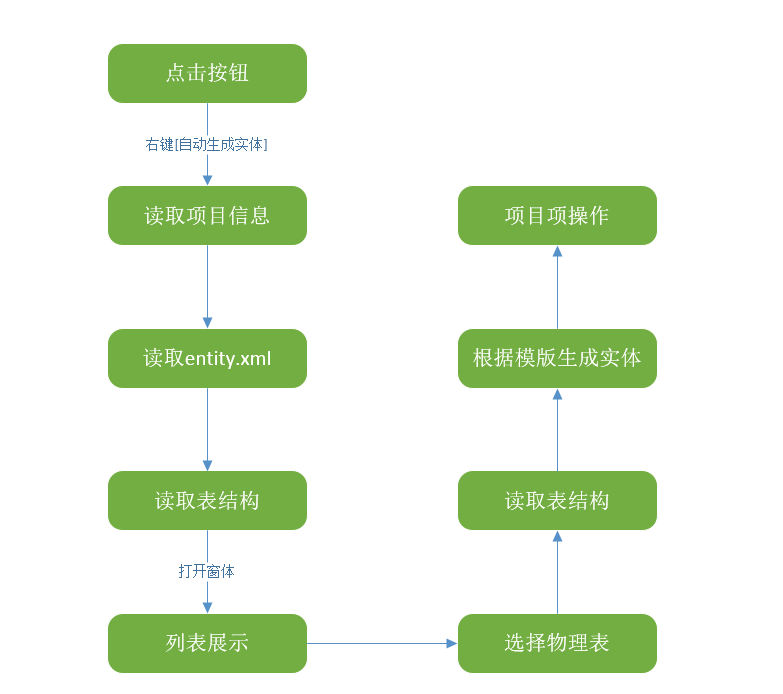
以上是完整处理流程,我打算选择部分流程来讲。如果有对Visual Studio Package开发还没一个认识,可以看我之前写的一篇《Visual Studio Package 插件开发》。
按钮的位置
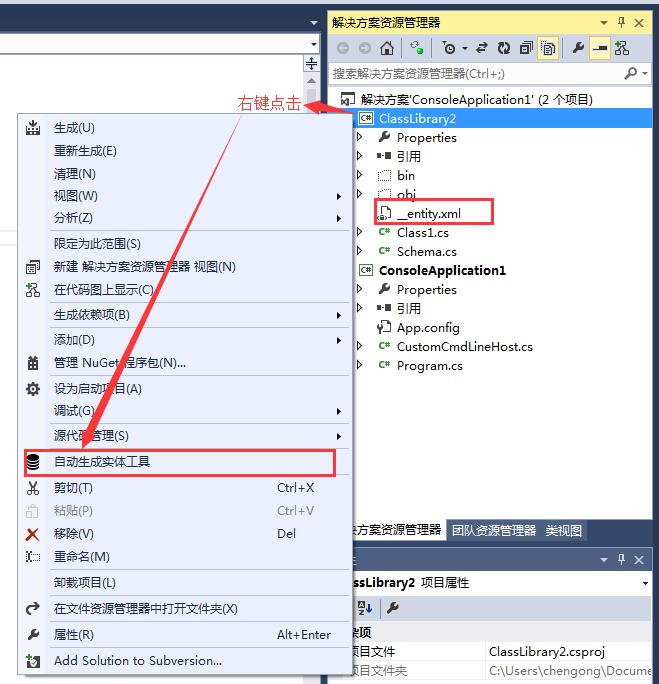
从上图看见,按钮是在选中项目右键弹出的菜单栏里。
打开vsct文件,修改Group的Parent节点,修改对应的guid和id。
之前那边文章有提到在文件:您的vs安装目录\VisualStudio2013\VSSDK\VisualStudioIntegration\Common\Inc\vsshlids.h 可以找到需要修改的名称,但是右键是没有在文件里定义,因此我们需要另外换一种方法。
1、打开注册表编辑器(打开运行窗口,输入regedit),
2、路径[HKEY_CURRENT_USER\Software\Microsoft\VisualStudio\12.0\General],
3、右击-新建-DWORD(32-位)值(D),其命名为EnableVSIPLogging
4、并将其值改为1。重启VS,打开项目
5、按下Ctrl+Shift,对项目点击右键,就会弹出窗口(如下图)

Guid和CmdID的值就是我们需要的,在vsct文件Symbols节点添加GuidSymbol项,value上图的{D309F791-903F-11D0-9EFC-00A0C911004F},IDSymbol项value为1026。
最后在Group的Parent节点的属性guid和id改为与上面对应,下面代码为例子。
<CommandTable xmlns="http://schemas.microsoft.com/VisualStudio/2005-10-18/CommandTable" xmlns:xs="http://www.w3.org/2001/XMLSchema">
<Commands package="guidAutoBuildEntityPkg">
<Groups>
<Group guid="guidAutoBuildEntityCmdSet" id="MyMenuGroup" priority="0x0600">
<Parent guid="guidCodeWindowRightClickCmdSet" id="CodeWindowRightClickMenu"/>
</Group>
</Groups>
</Commands>
<Symbols>
<GuidSymbol name="guidAutoBuildEntityPkg" value="{c095f8f8-3f87-4eac-8dc0-44939a85b2f2}" />
<GuidSymbol name="guidCodeWindowRightClickCmdSet" value="{D309F791-903F-11D0-9EFC-00A0C911004F}">
<IDSymbol name="CodeWindowRightClickMenu" value="1026" />
</GuidSymbol>
</Symbols>
</CommandTable>
读取选中项目信息
重点是DTE 接口的使用,MSDN的描述是:DTE 接口Visual Studio 自动化对象模型中的顶级对象。强大到当前开发环境中任何属性可以拿到例如:当前打开的文档集合,解决方案下的项目信息……剩下自己看,传送门
下面是代码示例:
var dte = (DTE)GetService(typeof(SDTE));
/// <summary>
/// 获取选中项目的信息
/// </summary>
/// <param name="dte"></param>
/// <returns></returns>
public static SelectedProject GetSelectedProjectInfo(this DTE dte)
{
var selectedItems = dte.SelectedItems;
var projectName = (from SelectedItem item in selectedItems select item.Name).ToList();
if (!selectedItems.MultiSelect && selectedItems.Count == 1)
{
var selectProject = selectedItems.Item(projectName.First());
var projectFileList = (from ProjectItem projectItem in selectProject.Project.ProjectItems
where projectItem.Name.EndsWith(".cs")
select Path.GetFileNameWithoutExtension(projectItem.Name)).ToList();
return new SelectedProject(selectProject.Project.FullName, selectProject.Project, projectFileList);
}
return null;
}
读取实体配置信息
配置存放两点信息:数据库连接、类文件模版,同时我们约定存放在项目根目录下。如下图
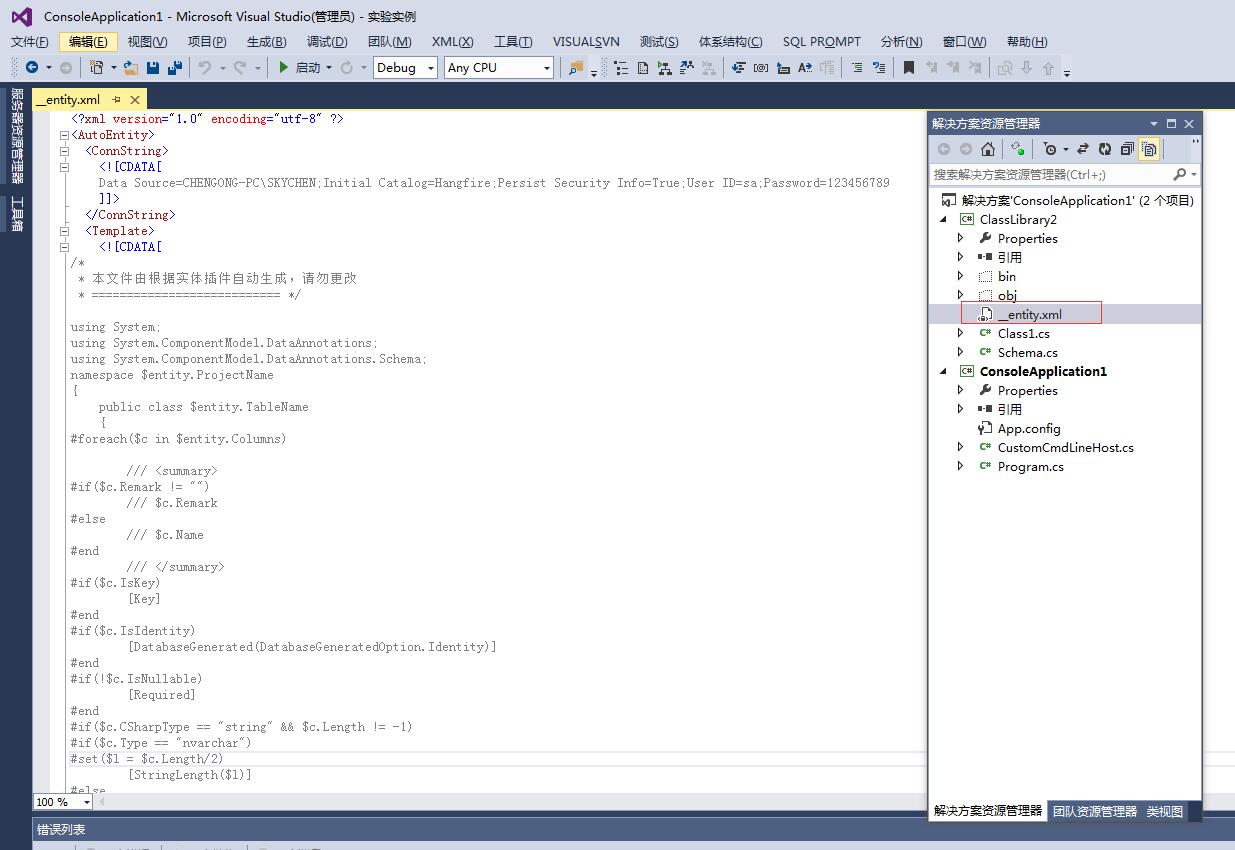
那么,剩下就是XML的基本获取处理了。__entity.xml的模版在源码里,可自行拷贝去需要使用的项目,以下是代码示例:
private void AutoBuildEntityEvent(object sender, EventArgs e)
{
var autoBuildEntityContent = new AutoBuildEntityContent ();
//读取选中项目下的配置信息
var entityXmlModel = new EntityXml(autoBuildEntityContent.SelectedProject.EntityXmlPath);
entityXmlModel.Load();
autoBuildEntityContent.EntityXml = entityXmlModel;
new MainForm(autoBuildEntityContent).ShowDialog();
}
public class EntityXml
{
private readonly string _path;
public EntityXml(string path)
{
_path = path;
}
public string ConnString { get; private set; }
public string EntityTemplate { get; private set; }
/// <summary>
/// 读取_entity.xml
/// </summary>
/// <returns></returns>
public EntityXml Load()
{
var xml = new XmlDocument();
xml.Load(_path);
var autoEntityNode = xml.SelectSingleNode("AutoEntity");
if (autoEntityNode != null)
{
var connStringNode = autoEntityNode.SelectSingleNode("ConnString");
if (connStringNode != null)
{
ConnString = connStringNode.InnerText;
}
var templatesNodes = autoEntityNode.SelectSingleNode("Template");
if (templatesNodes != null)
{
EntityTemplate = templatesNodes.InnerText;
}
}
return this;
}
}
读取物理表
查询当前数据库的表集合,传给窗体做列表展示,直接上代码:
/// <summary>
/// 物理表
/// </summary>
public class DbTable
{
public string TableName { get; private set; }
public List<TableColumn> Columns { get; set; }
private readonly string _conn;
public DbTable(string conn)
{
_conn = conn;
}
public DbTable(string tableName, List<TableColumn> columns)
{
TableName = tableName;
Columns = columns;
}
public List<string> QueryTablesName()
{
var result = SqlHelper.Query(_conn, @"SELECT name FROM sysobjects WHERE xtype IN ( 'u','v' ); ");
return (from DataRow row in result.Rows select row[0].ToString()).ToList();
}
public List<DbTable> GetTables(List<string> tablesName)
{
if (!tablesName.Any())
return new List<DbTable>();
var t = new TableColumn(_conn);
var columns = t.QueryColumn(tablesName);
return columns.GroupBy(a => a.TableName).Select(a => new DbTable(a.Key, a.ToList())).ToList();
}
}
读取表结构
选择响应的表后,查询出对应的表结构,一般实体的所需要的信息有:列名、列备注、类型、长度、是否主键、是否自增长、是否可空,继续上代码:
/// <summary>
/// 物理表的列信息
/// </summary>
public class TableColumn
{
private readonly string _connStr;
public TableColumn()
{
}
public TableColumn(string connStr)
{
_connStr = connStr;
}
public string TableName { get; private set; }
public string Name { get; private set; }
public string Remark { get; private set; }
public string Type { get; private set; }
public int Length { get; private set; }
public bool IsIdentity { get; private set; }
public bool IsKey { get; private set; }
public bool IsNullable { get; private set; }
public string CSharpType
{
get
{
return SqlHelper.MapCsharpType(Type, IsNullable);
}
}
/// <summary>
/// 查询列信息
/// </summary>
/// <param name="tablesName"></param>
/// <returns></returns>
public List<TableColumn> QueryColumn(List<string> tablesName)
{
#region 表结构
var paramKey = string.Join(",", tablesName.Select((a, index) => "@p" + index));
var paramVal = tablesName.Select((a, index) => new SqlParameter("@p" + index, a)).ToArray();
var sql = string.Format(@"SELECT obj.name AS tablename ,
col.name ,
ISNULL(ep.[value], '') remark ,
t.name AS type ,
col.length ,
COLUMNPROPERTY(col.id, col.name, 'IsIdentity') AS isidentity ,
CASE WHEN EXISTS ( SELECT 1
FROM dbo.sysindexes si
INNER JOIN dbo.sysindexkeys sik ON si.id = sik.id
AND si.indid = sik.indid
INNER JOIN dbo.syscolumns sc ON sc.id = sik.id
AND sc.colid = sik.colid
INNER JOIN dbo.sysobjects so ON so.name = si.name
AND so.xtype = 'PK'
WHERE sc.id = col.id
AND sc.colid = col.colid ) THEN 1
ELSE 0
END AS iskey ,
col.isnullable
FROM dbo.syscolumns col
LEFT JOIN dbo.systypes t ON col.xtype = t.xusertype
INNER JOIN dbo.sysobjects obj ON col.id = obj.id
AND obj.xtype IN ( 'U', 'v' )
AND obj.status >= 0
LEFT JOIN dbo.syscomments comm ON col.cdefault = comm.id
LEFT JOIN sys.extended_properties ep ON col.id = ep.major_id
AND col.colid = ep.minor_id
AND ep.name = 'MS_Description'
LEFT JOIN sys.extended_properties epTwo ON obj.id = epTwo.major_id
AND epTwo.minor_id = 0
AND epTwo.name = 'MS_Description'
WHERE obj.name IN ({0});", paramKey);
#endregion
var result = SqlHelper.Query(_connStr, sql, paramVal);
return (from DataRow row in result.Rows
select new TableColumn
{
IsIdentity = Convert.ToBoolean(row["isidentity"]),
IsKey = Convert.ToBoolean(row["iskey"]),
IsNullable = Convert.ToBoolean(row["isnullable"]),
Length = Convert.ToInt32(row["length"]),
Name = row["name"].ToString(),
Remark = row["remark"].ToString(),
TableName = row["tablename"].ToString(),
Type = row["type"].ToString()
}).ToList();
}
}
根据模板生成代码
开始我是尝试用T4的,发现不方便,繁杂的声明。因此我选择了nVelocity,这里不做太多介绍,附上相关文章学习,传送门
// <summary>
/// 初始化模板引擎
/// </summary>
public static string ProcessTemplate(string template, Dictionary<string, object> param)
{
var templateEngine = new VelocityEngine();
templateEngine.SetProperty(RuntimeConstants.RESOURCE_LOADER, "file");
templateEngine.SetProperty(RuntimeConstants.INPUT_ENCODING, "utf-8");
templateEngine.SetProperty(RuntimeConstants.OUTPUT_ENCODING, "utf-8");
templateEngine.SetProperty(RuntimeConstants.FILE_RESOURCE_LOADER_PATH, AppDomain.CurrentDomain.BaseDirectory);
var context = new VelocityContext();
foreach (var item in param)
{
context.Put(item.Key, item.Value);
}
templateEngine.Init();
var writer = new StringWriter();
templateEngine.Evaluate(context, writer, "mystring", template);
return writer.GetStringBuilder().ToString();
}
之前已经拿到的文件模版,通过上面的方法输出类文本,保存到选中项目的根目录下。
 View Code
View Code操作项目
终于到了最后一步了,部分人以为保存了文件后就完事了,最后通过包含文件就完事了。我们还是有点追求的,既然做成了插件就要更加的方便化。
通过之前[读取选中项目信息]步骤拿到的EnvDTE.Project ProjectDte,使用以下扩展方法进行添加、删除项目项。
View Code附加
部分同学可能想调试的时候会出现:无法直接启动“类库输出类型”项目,可以在项目属性-调试配置:
1.启动配置外部程序:C:\Program Files (x86)\Microsoft Visual Studio 12.0\Common7\IDE\devenv.exe
2.命令行参数:/rootsuffix Exp

估计有同学会制作自己的图标,另外附上两条icon制作的网站:
http://iconfont.cn/search/index
http://www.easyicon.net/covert/
结尾
整篇文章的技术难点并不多,但是因为插件开发的资料相对较少,80%的时间花去找接口文档、找资料。
此工具的原型是公司架构师的,公司所有开发都在用,但是他把源码丢了………………好奇心使我重新实现了一份,当然了,说不定哪天带团队的时候会用上。
最后双手奉上源码,并不是什么牛逼的东西,希望可以帮助需要的同学。https://github.com/SkyChenSky/AutoBuildEntity

 浙公网安备 33010602011771号
浙公网安备 33010602011771号