

第一节: Timer的定时任务的复习、Quartz.Net的入门使用、Aop思想的体现 第十九节: 结合【表达式目录树】来封装EF的BaseDal层的方法 第二十节: 深入理解并发机制以及解决方案(锁机制、EF自有机制、队列模式等) 框架搭建篇 第二十一节:ADO层次上的海量数据处理方案(SqlBulkCopy类插入和更新) 第十四节: 介绍四大并发集合类并结合单例模式下的队列来说明线程
第一节: Timer的定时任务的复习、Quartz.Net的入门使用、Aop思想的体现
一. 前奏-Timer类实现定时任务
在没有引入第三方开源的定时调度框架之前,我们处理一些简单的定时任务同时都是使用Timer类, DotNet中的Timer类有三个,分别位于不同的命名空间下,分别是:
①.位于System.Windows.Forms里,即定时器控件,不过多介绍了
②.位于System.Threading.Timer类里 (重点介绍)
③.位于System.Timers.Timer类里 (不介绍)
下面重点介绍第二种,位于Threading下面的Timer类,观察其源码,发现有多种构造函数,我们重点介绍其中的一种。

分享一段代码:2秒后开启该线程,然后每隔4s调用一次。
1 //2秒后开启该线程,然后每隔4s调用一次
2 System.Threading.Timer timer = new System.Threading.Timer((n) =>
3 {
4 //书写业务逻辑
5 Console.WriteLine("我是定时器中的业务逻辑哦{0}",n);
6 }, "1", 2000, 4000);
分析总结:上面的代码显而易见,只能控制:延迟多久开始执行,每隔多久执行一次,至于执行多少次、什么时间关闭均无法实现,更不用说处理一些复杂的时间间隔了,所以Timer类仅仅适合处理对时间要求非常简单的定时任务。
二. 进入主题-Quartz.Net的入门使用
使用步骤:
前提:通过NuGet引入程序集或者直接下载源码进行引入,然后分五步走。
步骤一:创建作业调度池(Scheduler)
步骤二:创建一个具体的作业即job (具体的job需要单独在一个文件中执行)
步骤三:创建并配置一个触发器即trigger
步骤四:将job和trigger加入到作业调度池中
步骤五:开启调度
下面分享一段简单的代码(立即执行、每隔一秒执行一次、永久执行)

1 /// <summary>
2 /// Quartz框架的使用
3 /// </summary>
4 public static void Show()
5 {
6 //1.创建作业调度池(Scheduler)
7 IScheduler scheduler =StdSchedulerFactory.GetDefaultScheduler();
8
9 //2.创建一个具体的作业即job (具体的job需要单独在一个文件中执行)
10 var job = JobBuilder.Create<HelloJob>().Build();
11
12 //3.创建并配置一个触发器即trigger 1s执行一次
13 var trigger = TriggerBuilder.Create().WithSimpleSchedule(x => x.WithIntervalInSeconds(1)
14 .RepeatForever()).Build();
15 //4.将job和trigger加入到作业调度池中
16 scheduler.ScheduleJob(job, trigger);
17
18 //5.开启调度
19 scheduler.Start();
20 }
1 /// <summary>
2 /// 实现IJob接口
3 /// </summary>
4 class HelloJob : IJob
5 {
6 void IJob.Execute(IJobExecutionContext context)
7 {
8 Console.WriteLine("Hellow JOB");
9 }
10 }
分析:每个Job都需要实现IJob接口,并且显式的实现Execute方法;创建调度器除了上述方法外,还可以:
1 //另外一种创建调度池的方法 2 var factory = new StdSchedulerFactory(); 3 IScheduler scheduler2 = factory.GetScheduler();
执行结果:

三. 扩展-Aop思想的体现
我们想在每次Job执行的前后,分别执行一段通用的业务,但有不想和原业务写在一起,这个时候就需要面向切面编程了,即AOP思想的体现。
Quartz.Net中Aop思想通过JobListener来实现,代码如下:
1 /// <summary>
2 /// Quartz中的AOP思想
3 /// </summary>
4 public static void AopShow()
5 {
6 //1.创建Schedule
7 IScheduler scheduler = StdSchedulerFactory.GetDefaultScheduler();
8
9 //2.创建job (具体的job需要单独在一个文件中执行)
10 var job = JobBuilder.Create<HelloJob>().Build();
11
12 //3.配置trigger 1s执行一次
13 var trigger = TriggerBuilder.Create().WithSimpleSchedule(x => x.WithIntervalInSeconds(1)
14 .RepeatForever()).Build();
15 //AOP配置
16 scheduler.ListenerManager.AddJobListener(new MyAopListener(), GroupMatcher<JobKey>.AnyGroup());
17
18 //4.将job和trigger加入到作业调度池中
19 scheduler.ScheduleJob(job, trigger);
20
21 //5. 开始调度
22 scheduler.Start();
23 }
24 /// <summary>
25 /// Aop类
26 /// </summary>
27 public class MyAopListener : IJobListener
28 {
29 public string Name
30 {
31 get
32 {
33 return "hello world";
34 }
35 }
36 public void JobExecutionVetoed(IJobExecutionContext context)
37 {
38
39 }
40 public void JobToBeExecuted(IJobExecutionContext context)
41 {
42 Console.WriteLine("执行前写入日志");
43 }
44 public void JobWasExecuted(IJobExecutionContext context, JobExecutionException jobException)
45 {
46 Console.WriteLine("执行后写入日志");
47 }
48 }
执行结果:

第十九节: 结合【表达式目录树】来封装EF的BaseDal层的方法
一. 简介
该章节,可以说是一个简单轻松的章节,只要你对Expression表达式树、EF的基本使用、泛型有所了解,那么本章节实质上就是一个非常简单的封装章节,便于我们快捷开发。
PS:在该章节对于EF的上下文怎么处理,怎么来的,不做介绍,在后续的框架篇将详细介绍,下面的EF上下文,将直接使用db代替。
如果你对Expression、EF的增删改查、泛型生疏的话,可以先阅读以下章节:
(1). Expression表达式目录树:http://www.cnblogs.com/yaopengfei/p/7486870.html
(2). EF的基本增删改查:http://www.cnblogs.com/yaopengfei/p/7674715.html
(3). 泛型的使用:http://www.cnblogs.com/yaopengfei/p/6880629.html
二. 代码封装分享
下面的代码封装,主要就是围绕EF的增删改查进行封装以及各自对应的扩展,其中包括事务一体的封装、事务分离的封装、集成 Z.EntityFramework.Extensions 插件的封装、以及EF调用SQL语句的封装。
1. EF调用SQL语句:
1 /// <summary>
2 /// 执行增加,删除,修改操作(或调用存储过程)
3 /// </summary>
4 /// <param name="sql"></param>
5 /// <param name="pars"></param>
6 /// <returns></returns>
7 public int ExecuteSql(string sql, params SqlParameter[] pars)
8 {
9 return db.Database.ExecuteSqlCommand(sql, pars);
10 }
11
12 /// <summary>
13 /// 执行查询操作
14 /// </summary>
15 /// <typeparam name="T"></typeparam>
16 /// <param name="sql"></param>
17 /// <param name="pars"></param>
18 /// <returns></returns>
19 public List<T> ExecuteQuery<T>(string sql, params SqlParameter[] pars)
20 {
21 return db.Database.SqlQuery<T>(sql, pars).ToList();
22 }
2. EF增删改查封装(事务一体)
(1). 新增
1 public int Add(T model)
2 {
3 DbSet<T> dst = db.Set<T>();
4 dst.Add(model);
5 return db.SaveChanges();
6 }
(2). 删除
1 /// <summary>
2 /// 删除(适用于先查询后删除的单个实体)
3 /// </summary>
4 /// <param name="model">需要删除的实体</param>
5 /// <returns></returns>
6 public int Del(T model)
7 {
8 db.Set<T>().Attach(model);
9 db.Set<T>().Remove(model);
10 return db.SaveChanges();
11 }
12 /// <summary>
13 /// 根据条件删除(支持批量删除)
14 /// </summary>
15 /// <param name="delWhere">传入Lambda表达式(生成表达式目录树)</param>
16 /// <returns></returns>
17 public int DelBy(Expression<Func<T, bool>> delWhere)
18 {
19 List<T> listDels = db.Set<T>().Where(delWhere).ToList();
20 listDels.ForEach(d =>
21 {
22 db.Set<T>().Attach(d);
23 db.Set<T>().Remove(d);
24 });
25 return db.SaveChanges();
26 }
(3). 查询
1 /// <summary>
2 /// 根据条件查询
3 /// </summary>
4 /// <param name="whereLambda">查询条件(lambda表达式的形式生成表达式目录树)</param>
5 /// <returns></returns>
6 public List<T> GetListBy(Expression<Func<T, bool>> whereLambda)
7 {
8 return db.Set<T>().Where(whereLambda).ToList();
9 }
10 /// <summary>
11 /// 根据条件排序和查询
12 /// </summary>
13 /// <typeparam name="Tkey">排序字段类型</typeparam>
14 /// <param name="whereLambda">查询条件</param>
15 /// <param name="orderLambda">排序条件</param>
16 /// <param name="isAsc">升序or降序</param>
17 /// <returns></returns>
18 public List<T> GetListBy<Tkey>(Expression<Func<T, bool>> whereLambda, Expression<Func<T, Tkey>> orderLambda, bool isAsc = true)
19 {
20 List<T> list = null;
21 if (isAsc)
22 {
23 list = db.Set<T>().Where(whereLambda).OrderBy(orderLambda).ToList();
24 }
25 else
26 {
27 list = db.Set<T>().Where(whereLambda).OrderByDescending(orderLambda).ToList();
28 }
29 return list;
30 }
31 /// <summary>
32 /// 分页查询
33 /// </summary>
34 /// <typeparam name="Tkey">排序字段类型</typeparam>
35 /// <param name="pageIndex">页码</param>
36 /// <param name="pageSize">页容量</param>
37 /// <param name="whereLambda">查询条件</param>
38 /// <param name="orderLambda">排序条件</param>
39 /// <param name="isAsc">升序or降序</param>
40 /// <returns></returns>
41 public List<T> GetPageList<Tkey>(int pageIndex, int pageSize, Expression<Func<T, bool>> whereLambda, Expression<Func<T, Tkey>> orderLambda, bool isAsc = true)
42 {
43
44 List<T> list = null;
45 if (isAsc)
46 {
47 list = db.Set<T>().Where(whereLambda).OrderBy(orderLambda)
48 .Skip((pageIndex - 1) * pageSize).Take(pageSize).ToList();
49 }
50 else
51 {
52 list = db.Set<T>().Where(whereLambda).OrderByDescending(orderLambda)
53 .Skip((pageIndex - 1) * pageSize).Take(pageSize).ToList();
54 }
55 return list;
56 }
57 /// <summary>
58 /// 分页查询输出总行数
59 /// </summary>
60 /// <typeparam name="Tkey">排序字段类型</typeparam>
61 /// <param name="pageIndex">页码</param>
62 /// <param name="pageSize">页容量</param>
63 /// <param name="whereLambda">查询条件</param>
64 /// <param name="orderLambda">排序条件</param>
65 /// <param name="isAsc">升序or降序</param>
66 /// <returns></returns>
67 public List<T> GetPageList<Tkey>(int pageIndex, int pageSize, ref int rowCount, Expression<Func<T, bool>> whereLambda, Expression<Func<T, Tkey>> orderLambda, bool isAsc = true)
68 {
69 int count = 0;
70 List<T> list = null;
71 count = db.Set<T>().Where(whereLambda).Count();
72 if (isAsc)
73 {
74 var iQueryList = db.Set<T>().Where(whereLambda).OrderBy(orderLambda)
75 .Skip((pageIndex - 1) * pageSize).Take(pageSize);
76
77 list = iQueryList.ToList();
78 }
79 else
80 {
81 var iQueryList = db.Set<T>().Where(whereLambda).OrderByDescending(orderLambda)
82 .Skip((pageIndex - 1) * pageSize).Take(pageSize);
83 list = iQueryList.ToList();
84 }
85 rowCount = count;
86 return list;
87 }
(4). 修改
1 /// <summary>
2 /// 修改
3 /// </summary>
4 /// <param name="model">修改后的实体</param>
5 /// <returns></returns>
6 public int Modify(T model)
7 {
8 db.Entry(model).State = EntityState.Modified;
9 return db.SaveChanges();
10 }
11
12 /// <summary>
13 /// 单实体扩展修改(把不需要修改的列用LAMBDA数组表示出来)
14 /// </summary>
15 /// <param name="model">要修改的实体对象</param>
16 /// <param name="ignoreProperties">不须要修改的相关字段</param>
17 /// <returns>受影响的行数</returns>
18 public int Modify(T model, params Expression<Func<T, object>>[] ignoreProperties)
19 {
20 using (DbContext db = new DBContextFactory().GetDbContext())
21 {
22 db.Set<T>().Attach(model);
23
24 DbEntityEntry entry = db.Entry<T>(model);
25 entry.State = EntityState.Unchanged;
26
27 Type t = typeof(T);
28 List<PropertyInfo> proInfos = t.GetProperties(BindingFlags.Instance | BindingFlags.Public).ToList();
29
30 Dictionary<string, PropertyInfo> dicPros = new Dictionary<string, PropertyInfo>();
31 proInfos.ForEach(
32 p => dicPros.Add(p.Name, p)
33 );
34
35 if (ignoreProperties != null)
36 {
37 foreach (var ignorePropertyExpression in ignoreProperties)
38 {
39 //根据表达式得到对应的字段信息
40 var ignorePropertyName = new PropertyExpressionParser<T>(ignorePropertyExpression).Name;
41 dicPros.Remove(ignorePropertyName);
42 }
43 }
44
45 foreach (string proName in dicPros.Keys)
46 {
47 entry.Property(proName).IsModified = true;
48 }
49 return db.SaveChanges();
50 }
51 }
52
53 /// <summary>
54 /// 批量修改(非lambda)
55 /// </summary>
56 /// <param name="model">要修改实体中 修改后的属性 </param>
57 /// <param name="whereLambda">查询实体的条件</param>
58 /// <param name="proNames">lambda的形式表示要修改的实体属性名</param>
59 /// <returns></returns>
60 public int ModifyBy(T model, Expression<Func<T, bool>> whereLambda, params string[] proNames)
61 {
62 List<T> listModifes = db.Set<T>().Where(whereLambda).ToList();
63 Type t = typeof(T);
64 List<PropertyInfo> proInfos = t.GetProperties(BindingFlags.Instance | BindingFlags.Public).ToList();
65 Dictionary<string, PropertyInfo> dicPros = new Dictionary<string, PropertyInfo>();
66 proInfos.ForEach(p =>
67 {
68 if (proNames.Contains(p.Name))
69 {
70 dicPros.Add(p.Name, p);
71 }
72 });
73 foreach (string proName in proNames)
74 {
75 if (dicPros.ContainsKey(proName))
76 {
77 PropertyInfo proInfo = dicPros[proName];
78 object newValue = proInfo.GetValue(model, null);
79 foreach (T m in listModifes)
80 {
81 proInfo.SetValue(m, newValue, null);
82 }
83 }
84 }
85 return db.SaveChanges();
86 }
87
88 /// <summary>
89 /// 批量修改(支持lambda)
90 /// </summary>
91 /// <param name="model">要修改实体中 修改后的属性 </param>
92 /// <param name="whereLambda">查询实体的条件</param>
93 /// <param name="proNames">lambda的形式表示要修改的实体属性名</param>
94 /// <returns></returns>
95 public int ModifyBy(T model, Expression<Func<T, bool>> whereLambda, params Expression<Func<T, object>>[] proNames)
96 {
97 List<T> listModifes = db.Set<T>().Where(whereLambda).ToList();
98 Type t = typeof(T);
99 List<PropertyInfo> proInfos = t.GetProperties(BindingFlags.Instance | BindingFlags.Public).ToList();
100 Dictionary<string, PropertyInfo> dicPros = new Dictionary<string, PropertyInfo>();
101 if (proNames != null)
102 {
103 foreach (var myProperyExp in proNames)
104 {
105 var my_ProName = new PropertyExpressionParser<T>(myProperyExp).Name;
106 proInfos.ForEach(p =>
107 {
108 if (p.Name.Equals(my_ProName))
109 {
110 dicPros.Add(p.Name, p);
111 }
112 });
113 if (dicPros.ContainsKey(my_ProName))
114 {
115 PropertyInfo proInfo = dicPros[my_ProName];
116 object newValue = proInfo.GetValue(model, null);
117 foreach (T m in listModifes)
118 {
119 proInfo.SetValue(m, newValue, null);
120 }
121 }
122 }
123 }
124 return db.SaveChanges();
125 }
126
3. EF增删改封装(事务分离)
(1). 事务批量处理
1 /// <summary>
2 /// 事务批量处理
3 /// </summary>
4 /// <returns></returns>
5 public int SaveChange()
6 {
7 return db.SaveChanges();
8 }
(2). 新增
1 /// <summary>
2 /// 新增
3 /// </summary>
4 /// <param name="model">需要新增的实体</param>
5 public void AddNo(T model)
6 {
7 db.Set<T>().Add(model);
8 }
(3). 修改
1 /// <summary>
2 /// 修改
3 /// </summary>
4 /// <param name="model">修改后的实体</param>
5 public void ModifyNo(T model)
6 {
7 db.Entry(model).State = EntityState.Modified;
8 }
(4). 删除
/// <summary>
/// 删除
/// </summary>
/// <param name="model">需要删除的实体</param>
public void DelNo(T model)
{
db.Entry(model).State = EntityState.Deleted;
}
/// <summary>
/// 条件删除
/// </summary>
/// <param name="delWhere">需要删除的条件</param>
public void DelByNo(Expression<Func<T, bool>> delWhere)
{
List<T> listDels = db.Set<T>().Where(delWhere).ToList();
listDels.ForEach(d =>
{
db.Set<T>().Attach(d);
db.Set<T>().Remove(d);
});
}
4. Z.EntityFramework.Extensions 插件封装
方案一:在使用EF事务分离的方法的前提下,单独调用提交方法
1 /// <summary>
2 /// 事务提交,速度约为saveChange的10倍-15倍
3 /// </summary>
4 public void BulkSaveChanges()
5 {
6 db.BulkSaveChanges();
7 }
方案二:插件特有的增删改方法
/// <summary>
/// 新增
/// </summary>
/// <param name="model">新增的实体集合</param>
public void BulkInsert(List<T> model)
{
db.BulkInsert<T>(model);
}
/// <summary>
/// 删除
/// </summary>
/// <param name="model">需要删除的实体集合</param>
public void BulkDelete(List<T> model)
{
db.BulkDelete<T>(model);
}
/// <summary>
/// 根据条件删除
/// </summary>
/// <param name="delWhere">删除条件</param>
public void BulkDeleteBy(Expression<Func<T, bool>> delWhere)
{
List<T> listDels = db.Set<T>().Where(delWhere).ToList();
db.BulkDelete<T>(listDels);
}
/// <summary>
/// 需要修改的实体集合
/// </summary>
/// <param name="model"></param>
public void BulkUpdate(List<T> model)
{
db.BulkUpdate<T>(model);
}
第二十节: 深入理解并发机制以及解决方案(锁机制、EF自有机制、队列模式等)
一. 理解并发机制
1. 什么是并发,并发与多线程有什么关系?
①. 先从广义上来说,或者从实际场景上来说.
高并发通常是海量用户同时访问(比如:12306买票、淘宝的双十一抢购),如果把一个用户看做一个线程的话那么并发可以理解成多线程同时访问,高并发即海量线程同时访问。
(ps:我们在这里模拟高并发可以for循环多个线程即可)
②.从代码或数据的层次上来说.
多个线程同时在一条相同的数据上执行多个数据库操作。
2. 从代码层次上来说,给并发分类。
①.积极并发(乐观并发、乐观锁):无论何时从数据库请求数据,数据都会被读取并保存到应用内存中。数据库级别没有放置任何显式锁。数据操作会按照数据层接收到的先后顺序来执行。
积极并发本质就是运行冲突发生,然后在代码本身采取一种合理的方式去解决这个并发冲突,常见的方式有:
a.忽略冲突强制更新:数据库会保存最后一次更新操作(以更新为例),会损失很多用户的更新操作。
b.部分更新:允许所有的更改,但是不允许更新完整的行,只有特定用户拥有的列更新了。这就意味着,如果两个用户更新相同的记录但却不同的列,那么这两个更新都会成功,而且来自这两个用户的更改都是可见的。(EF默认实现不了这种情况、可以考略SQL语句、或者EF扩展只允许修改指定列来处理这种问题)
c.询问用户:当一个用户尝试更新一个记录时,但是该记录自从他读取之后已经被别人修改了,这时应用程序就会警告该用户该数据已经被某人更改了,然后询问他是否仍然要重写该数据还是首先检查已经更新的数据。(EF可以实现这种情况,在后面详细介绍)
d.拒绝修改:当一个用户尝试更新一个记录时,但是该记录自从他读取之后已经被别人修改了,此时告诉该用户不允许更新该数据,因为数据已经被某人更新了。
(EF可以实现这种情况,在后面详细介绍)
②.消极并发(悲观并发、悲观锁):无论何时从数据库请求数据,数据都会被读取,然后该数据上就会加锁,因此没有人能访问该数据。这会降低并发出现问题的机会,缺点是加锁是一个昂贵的操作,会降低整个应用程序的性能。
消极并发的本质就是永远不让冲突发生,通常的处理凡是是只读锁和更新锁。
a. 当把只读锁放到记录上时,应用程序只能读取该记录。如果应用程序要更新该记录,它必须获取到该记录上的更新锁。如果记录上加了只读锁,那么该记录仍然能够被想要只读锁的请求使用。然而,如果需要更新锁,该请求必须等到所有的只读锁释放。同样,如果记录上加了更新锁,那么其他的请求不能再在这个记录上加锁,该请求必须等到已存在的更新锁释放才能加锁。
总结,这里我们可以简单理解把并发业务部分用一个锁(如:lock,实质是数据库锁,后面章节单独介绍)锁住,使其同时只允许一个线程访问即可。
b. 加锁会带来很多弊端:
(1):应用程序必须管理每个操作正在获取的所有锁;
(2):加锁机制的内存需求会降低应用性能
(3):多个请求互相等待需要的锁,会增加死锁的可能性。
总结:尽量不要使用消极并发,EF默认是不支持消极并发的!!!
注意:EF默认就是积极并发,当然EF也可以配置成消极并发。
二. 并机制的解决方案
1. 从架构的角度去解决(大层次 如:12306买票)
nginx负载均衡、数据库读写分离、多个业务服务器、多个数据库服务器、NoSQL, 使用队列来处理业务,将高并发的业务依次放到队列中,然后按照先进先出的原则, 逐个处理(队列的处理可以采用 Redis、RabbitMq等等)
(PS:在后面的框架篇章里详细介绍该方案)
2. 从代码的角度去解决(在服务器能承载压力的情况下,并发访问同一条数据)
实际的业务场景:如进销存类的项目,涉及到同一个物品的出库、入库、库存,我们都知道库存在数据库里对应了一条记录,入库要查出现在库存的数量,然后加上入库的数量,假设两个线程同时入库,假设查询出来的库存数量相同,但是更新库存数量在数据库层次上是有先后,最终就保留了后更新的数据,显然是不正确的,应该保留的是两次入库的数量和。
(该案例的实质:多个线程同时在一条相同的数据上执行多个数据库操作)
事先准备一张数据库表:

解决方案一:(最常用的方式)
给入库和出库操作加一个锁,使其同时只允许一个线程访问,这样即使两个线程同时访问,但在代码层数上,由于锁的原因,还是有先有后的,这样就保证了入库操作的线程唯一性,当然库存量就不会出错了.
总结:该方案可以说是适合处理小范围的并发且锁内的业务执行不是很复杂。假设一万线程同时入库,每次入库要等2s,那么这一万个线程执行完成需要的总时间非常多,显然不适合。
(这种方式的实质就是给核心业务加了个lock锁,这里就不做测试了)
解决方案二:EF处理积极并发带来的冲突
1. 配置准备
(1). 针对DBFirst模式,可以给相应的表额外加一列RowVersion,byte类型,并且在Edmx模型上给该字段的并发模式设置为fixed(默认为None),这样该表中所有字段都监控并发。
如果不想监视所有列(在不添加RowVersion的情况下),只需在Edmx模型是给特定的字段的并发模式设置为fixed,这样只有被设置的字段被监测并发。
测试结果: (DBFirst模式下的并发测试)
事先在UserInfor1表中插入一条id、userName、userSex、userAge均为1的数据(清空数据)。
测试情况1:
在不设置RowVersion并发模式为Fixed的情况下,两个线程修改不同字段(修改同一个字段一个道理),后执行的线程的结果覆盖前面的线程结果.
发现测试结果为:1,1,男,1 ; 显然db1线程修改的结果被db2线程给覆盖了. (修改同一个字段一个道理)

1 {
2 //1.创建两个EF上下文,模拟代表两个线程
3 var db1 = new ConcurrentTestDBEntities();
4 var db2 = new ConcurrentTestDBEntities();
5
6 UserInfor1 user1 = db1.UserInfor1.Find("1");
7 UserInfor1 user2 = db2.UserInfor1.Find("1");
8
9 //2. 执行修改操作
10 //(db1的线程先执行完修改操作,并保存)
11 user1.userName = "ypf";
12 db1.Entry(user1).State = EntityState.Modified;
13 db1.SaveChanges();
14
15 //(db2的线程在db1线程修改完成后,执行修改操作)
16 try
17 {
18 user2.userSex = "男";
19 db2.Entry(user2).State = EntityState.Modified;
20 db2.SaveChanges();
21
22 Console.WriteLine("测试成功");
23 }
24 catch (Exception)
25 {
26 Console.WriteLine("测试失败");
27 }
28 }
测试情况2:
设置RowVersion并发模式为Fixed的情况下,两个线程修改不同字段(修改同一个字段一个道理),如果该条数据已经被修改,利用DbUpdateConcurrencyException可以捕获异常,进行积极并发的冲突处理。测试结果如下:
a.RefreshMode.ClientWins: 1,1,男,1
b.RefreshMode.StoreWins: 1,ypf,1,1
c.ex.Entries.Single().Reload(); 1,ypf,1,1
1 {
2 //1.创建两个EF上下文,模拟代表两个线程
3 var db1 = new ConcurrentTestDBEntities();
4 var db2 = new ConcurrentTestDBEntities();
5
6 UserInfor1 user1 = db1.UserInfor1.Find("1");
7 UserInfor1 user2 = db2.UserInfor1.Find("1");
8
9 //2. 执行修改操作
10 //(db1的线程先执行完修改操作,并保存)
11 user1.userName = "ypf";
12 db1.Entry(user1).State = EntityState.Modified;
13 db1.SaveChanges();
14
15 //(db2的线程在db1线程修改完成后,执行修改操作)
16 try
17 {
18 user2.userSex = "男";
19 db2.Entry(user2).State = EntityState.Modified;
20 db2.SaveChanges();
21
22 Console.WriteLine("测试成功");
23 }
24 catch (DbUpdateConcurrencyException ex)
25 {
26 Console.WriteLine("测试失败:" + ex.Message);
27
28 //1. 保留上下文中的现有数据(即最新,最后一次输入)
29 //var oc = ((IObjectContextAdapter)db2).ObjectContext;
30 //oc.Refresh(RefreshMode.ClientWins, user2);
31 //oc.SaveChanges();
32
33 //2. 保留原始数据(即数据源中的数据代替当前上下文中的数据)
34 //var oc = ((IObjectContextAdapter)db2).ObjectContext;
35 //oc.Refresh(RefreshMode.StoreWins, user2);
36 //oc.SaveChanges();
37
38 //3. 保留原始数据(而Reload处理也就是StoreWins,意味着放弃当前内存中的实体,重新到数据库中加载当前实体)
39 ex.Entries.Single().Reload();
40 db2.SaveChanges();
41 }
42 }
测试情况3:
在不设置RowVersion并发模式为Fixed的情况下(也不需要RowVersion这个字段),单独设置userName字段的并发模式为Fixed,两个线程同时修改该字段,利用DbUpdateConcurrencyException可以捕获异常,进行积极并发的冲突处理,但如果是两个线程同时修改userName以外的字段,将不能捕获异常,将走EF默认的处理方式,后执行的覆盖先执行的。
a.RefreshMode.ClientWins: 1,ypf2,1,1
b.RefreshMode.StoreWins: 1,ypf,1,1
c.ex.Entries.Single().Reload(); 1,ypf,1,1
1 {
2 //1.创建两个EF上下文,模拟代表两个线程
3 var db1 = new ConcurrentTestDBEntities();
4 var db2 = new ConcurrentTestDBEntities();
5
6 UserInfor1 user1 = db1.UserInfor1.Find("1");
7 UserInfor1 user2 = db2.UserInfor1.Find("1");
8
9 //2. 执行修改操作
10 //(db1的线程先执行完修改操作,并保存)
11 user1.userName = "ypf";
12 db1.Entry(user1).State = EntityState.Modified;
13 db1.SaveChanges();
14
15 //(db2的线程在db1线程修改完成后,执行修改操作)
16 try
17 {
18 user2.userName = "ypf2";
19 db2.Entry(user2).State = EntityState.Modified;
20 db2.SaveChanges();
21
22 Console.WriteLine("测试成功");
23 }
24 catch (DbUpdateConcurrencyException ex)
25 {
26 Console.WriteLine("测试失败:" + ex.Message);
27
28 //1. 保留上下文中的现有数据(即最新,最后一次输入)
29 var oc = ((IObjectContextAdapter)db2).ObjectContext;
30 oc.Refresh(RefreshMode.ClientWins, user2);
31 oc.SaveChanges();
32
33 //2. 保留原始数据(即数据源中的数据代替当前上下文中的数据)
34 //var oc = ((IObjectContextAdapter)db2).ObjectContext;
35 //oc.Refresh(RefreshMode.StoreWins, user2);
36 //oc.SaveChanges();
37
38 //3. 保留原始数据(而Reload处理也就是StoreWins,意味着放弃当前内存中的实体,重新到数据库中加载当前实体)
39 //ex.Entries.Single().Reload();
40 //db2.SaveChanges();
41 }
42 }
(2). 针对CodeFirst模式,需要有这样的一个属性 public byte[] RowVersion { get; set; },并且给属性加上特性[Timestamp],这样该表中所有字段都监控并发。如果不想监视所有列(在不添加RowVersion的情况下),只需给特定的字段加上特性 [ConcurrencyCheck],这样只有被设置的字段被监测并发。
除了再配置上不同于DBFirst模式以为,是通过加特性的方式来标记并发,其它捕获并发和积极并发的几类处理方式均同DBFirst模式相同。(这里不做测试了)
2. 积极并发处理的三种形式总结:
利用DbUpdateConcurrencyException可以捕获异常,然后:
a. RefreshMode.ClientWins:保留上下文中的现有数据(即最新,最后一次输入)
b. RefreshMode.StoreWins:保留原始数据(即数据源中的数据代替当前上下文中的数据)
c.ex.Entries.Single().Reload(); 保留原始数据(而Reload处理也就是StoreWins,意味着放弃当前内存中的实体,重新到数据库中加载当前实体)
3. 该方案总结:
这种模式实质上就是获取异常告诉程序,让开发人员结合需求自己选择怎么处理,但这种模式是解决代码层次上的并发冲突,并不是解决大数量同时访问崩溃问题的。
解决方案三:利用队列来解决业务上的并发(架构层次上其实也是这种思路解决的)
1.先分析:
前面说过所谓的高并发,就是海量的用户同时向服务器发送请求,进行某个业务处理(比如定时秒杀的抢单),而这个业务处理是需要 一定时间的。
2.处理思路:
将海量用户的请求放到一个队列里(如:Queue),先不进行业务处理,然后另外一个服务器从线程中读取这个请求(MVC框架可以放到Gloabl全局里),依次进行业务里,至于处理完成后,是否需要告诉客户端,可以根据实际需求来定,如果需要的话(可以借助Socket、Signlar、推送等技术来进行).
特别注意:读取队列的线程是一直在运行,只要队列中有数据,就给他拿出来.
这里使用Queue队列,可以参考:http://www.cnblogs.com/yaopengfei/p/8322016.html
(PS:架构层次上的处理方案无非,队列是单独一台服务器,执行从队列读取的是另外一台业务服务器,处理思想是相同的)
队列单例类的代码:
1 /// <summary>
2 /// 单例类
3 /// </summary>
4 public class QueueUtils
5 {
6 /// <summary>
7 /// 静态变量:由CLR保证,在程序第一次使用该类之前被调用,而且只调用一次
8 /// </summary>
9 private static readonly QueueUtils _QueueUtils = new QueueUtils();
10
11 /// <summary>
12 /// 声明为private类型的构造函数,禁止外部实例化
13 /// </summary>
14 private QueueUtils()
15 {
16
17 }
18 /// <summary>
19 /// 声明属性,供外部调用,此处也可以声明成方法
20 /// </summary>
21 public static QueueUtils instanse
22 {
23 get
24 {
25 return _QueueUtils;
26 }
27 }
28
29
30 //下面是队列相关的
31 System.Collections.Queue queue = new System.Collections.Queue();
32
33 private static object o = new object();
34
35 public int getCount()
36 {
37 return queue.Count;
38 }
39
40 /// <summary>
41 /// 入队方法
42 /// </summary>
43 /// <param name="myObject"></param>
44 public void Enqueue(object myObject)
45 {
46 lock (o)
47 {
48 queue.Enqueue(myObject);
49 }
50 }
51 /// <summary>
52 /// 出队操作
53 /// </summary>
54 /// <returns></returns>
55 public object Dequeue()
56 {
57 lock (o)
58 {
59 if (queue.Count > 0)
60 {
61 return queue.Dequeue();
62 }
63 }
64 return null;
65 }
66
67 }
临时存储数据类的代码:
1 /// <summary>
2 /// 该类用来存储请求信息
3 /// </summary>
4 public class TempInfor
5 {
6 /// <summary>
7 /// 用户编号
8 /// </summary>
9 public string userId { get; set; }
10 }
模拟高并发入队,单独线程出队的代码:
1 {
2 //3.1 模拟高并发请求 写入队列
3 {
4 for (int i = 0; i < 100; i++)
5 {
6 Task.Run(() =>
7 {
8 TempInfor tempInfor = new TempInfor();
9 tempInfor.userId = Guid.NewGuid().ToString("N");
10 //下面进行入队操作
11 QueueUtils.instanse.Enqueue(tempInfor);
12
13 });
14 }
15 }
16 //3.2 模拟另外一个线程队列中读取数据请求标记,进行相应的业务处理(该线程一直运行,不停止)
17 Task.Run(() =>
18 {
19 while (true)
20 {
21 if (QueueUtils.instanse.getCount() > 0)
22 {
23 //下面进行出队操作
24 TempInfor tempInfor2 = (TempInfor)QueueUtils.instanse.Dequeue();
25
26 //拿到请求标记,进行相应的业务处理
27 Console.WriteLine("id={0}的业务执行成功", tempInfor2.userId);
28 }
29 }
30 });
31 //3.3 模拟过了一段时间(6s后),又有新的请求写入
32 Thread.Sleep(6000);
33 Console.WriteLine("6s的时间已经过去了");
34 {
35 for (int j = 0; j < 100; j++)
36 {
37 Task.Run(() =>
38 {
39 TempInfor tempInfor = new TempInfor();
40 tempInfor.userId = Guid.NewGuid().ToString("N");
41 //下面进行入队操作
42 QueueUtils.instanse.Enqueue(tempInfor);
43
44 });
45 }
46 }
47 }
3.下面案例的测试结果:
一次输出100条数据,6s过后,再一次输出100条数据。

4. 总结:
该方案是一种迂回的方式处理高并发,在业内这种思想也是非常常见,但该方案也有一个弊端,客户端请求的实时性很难保证,或者即使要保证(比如引入实时通讯技术),
也要付出不少代价.
解决方案四:自己扩展EF只修改指定字段(处理同时修改同一条记录的不同字段问题)
分析这里有两个思路,分别是:
①:把不修改的属性排除掉。 ②:只标记要修改的属性。
显然这两种思路是解决不了同一个字段上的并发的,那么同一条记录上不同字段的并发能否解决呢(即合并处理)?下面接着分析:
(在Expression表达式目录树章节进行处理)
解决方案五: 利用数据库自有的锁机制进行处理
(在后面数据锁机制章节进行介绍)
框架搭建篇
1. 基础框架搭建
方案一: MVC5+EF6+Spring.Net+T4 (DBFirst 模式)
方案二: MVC6+EF6+Unity (CodeFirst模式)
结合主要的设计模式+AOP思想
2. 日志系统和异常处理
方案一: Log4Net
方案二:ELK
3. 整合定时任务框架
Quartz.Net
4. 整合实时通讯框架
SignalR
5. 权限系统的构建
按钮级别的权限设计,从需求分析→数据库设计→代码实现
6. 整合EasyUi框架
常见控件的使用
分析目前公司内部正在使用的皮肤样式
7. 常用类的封装,便于快捷开发
基础封装类
大数据量处理的封装类
8. 缓存的引入,优化系统性能,为后面分布式框架的打造做准备
服务器端缓存
Memecached
9. 完善框架的健壮性
导出功能(Excel的导出、word导出、pdf导出)
打印功能
10. 框架结构升级
引入Redis 或 RabbitMQ,打造分布式队列
Nagix负载均衡
11. 框架延伸
.Net Core2.0
Linux基础
/// <summary>
/// 通过线程对数据上下文进行一个优化
/// </summary>
public class DBContextFactory: IDBContextFactory
{
public DbContext GetDbContext()
{
DbContext dbContext = CallContext.GetData(typeof(DBContextFactory).Name) as DbContext;
if (dbContext == null)
{
dbContext = new MagicDBEntities();
CallContext.SetData(typeof(DBContextFactory).Name,dbContext);
}
return dbContext;
}
}
第二十一节:ADO层次上的海量数据处理方案(SqlBulkCopy类插入和更新)
一. 简介
1. 背景:
虽然前面EF的扩展插件Z.EntityFramework.Extensions,性能很快,而且也很方便,但是该插件要收费,使用免费版本的话,需要定期更新,如果不更新,将失效,非常麻烦,这个时候SqlBulkCopy类既免费又高效,显得非常合适了。
2. 使用步骤:
①. 引入命名空间:using System.Data.SqlClient;
②. 使用DataTable构造与目标数据库表结构相同的字段,并给其赋值。
③. 使用SqlBulkCopy类,将内存表中的数据一次性插入到目标表中。(看下面的封装可知,可以自行设置插入块的大小)
补充:调用下面的封装这种形式必须内存表中的字段名和数据库表中的字段名一一对应。
二. 使用方式及其性能测试
1. 涉及到的数据库结构:

2. 数据库连接字符串
<add name="CodeFirstModel2" connectionString="data source=localhost;initial catalog=EFDB2;persist security info=True;user id=sa;password=123456;MultipleActiveResultSets=True;App=EntityFramework" providerName="System.Data.SqlClient" />
3. 代码实践
有两种插入方式,一种是按部就班的每个字段 内存表和数据表进行映射,这个情况无须名称一致,只要映射正确即可。另外一种方式是,直接调用下面的封装方法即可,这种要求内存表中字段和数据库表中的字段名称必须完全一致,一一对应,这样就省去了方法一 中一一匹配映射的繁琐步骤了。
1 public class SqlBulkCopyTest
2 {
3 public static void TestSqlBulkCopy()
4 {
5 //一. 构造DataTable结构并且给其赋值
6 //1.定义与目标表的结构一致的内存表 排除自增id列
7 DataTable dtSource = new DataTable();
8 //列名称如果和目标表设置为一样,则后面可以不用进行字段映射
9 dtSource.Columns.Add("id");
10 dtSource.Columns.Add("t21");
11 dtSource.Columns.Add("t22");
12 //2. 向dt中增加4W条测试数据
13 DataRow dr;
14 for (int i = 0; i <40000; i++)
15 {
16 // 创建与dt结构相同的DataRow对象
17 dr = dtSource.NewRow();
18 dr["id"] = Guid.NewGuid().ToString("N");
19 dr["t21"] = "Name" + i;
20 dr["t22"] = "Address" + i;
21 // 将dr追加到dt中
22 dtSource.Rows.Add(dr);
23 }
24 //二.将内存表dt中的4W条数据一次性插入到t_Data表中的相应列中
25 System.Diagnostics.Stopwatch st = new System.Diagnostics.Stopwatch();
26 st.Start();
27 string connStr = ConfigurationManager.ConnectionStrings["CodeFirstModel2"].ToString();
28
29 #region 01-按部就班一一对应
30 //{
31 // using (SqlBulkCopy copy = new SqlBulkCopy(connStr))
32 // {
33 // //1 指定数据插入目标表名称
34 // copy.DestinationTableName = "TestTwo";
35
36 // //2 告诉SqlBulkCopy对象 内存表中的 字段和目标表中的字段 对应起来(这里有多个重载,也可以用索引对应)
37 // //前面是内存表,后面是目标表即数据库中的字段
38 // copy.ColumnMappings.Add("id", "id");
39 // copy.ColumnMappings.Add("t21", "t21");
40 // copy.ColumnMappings.Add("t22", "t22");
41
42 // //3 将内存表dt中的数据一次性批量插入到目标表中
43 // copy.WriteToServer(dtSource);
44 // }
45 //}
46
47 #endregion
48
49 #region 02-调用封装
50 {
51 AddByBluckCopy(connStr, dtSource, "TestTwo");
52 }
53 #endregion
54
55 st.Stop();
56 Console.WriteLine("数据插入成功,总耗时为:" + st.ElapsedMilliseconds + "毫秒");
57
58 }
59
60 /// <summary>
61 /// 海量数据插入方法
62 /// (调用该方法需要注意,DataTable中的字段名称必须和数据库中的字段名称一一对应)
64 /// </summary>
65 /// <param name="connectstring">数据连接字符串</param>
66 /// <param name="table">内存表数据</param>
67 /// <param name="tableName">目标数据的名称</param>
68 public static void AddByBluckCopy(string connectstring,DataTable table, string tableName)
69 {
70 if (table != null && table.Rows.Count > 0)
71 {
72 using (SqlBulkCopy bulk = new SqlBulkCopy(connectstring))
73 {
74 bulk.BatchSize = 1000;
75 bulk.BulkCopyTimeout = 100;
76 bulk.DestinationTableName = tableName;
77 bulk.WriteToServer(table);
78 }
79 }
80 }
81 }
4. 性能测试的结论

根据上述的数据测试可以看出来,SqlBulkCopy在处理大数据量插入上速度非常快,甚至比付费的插件Z.EntityFramework.Extensions都要快,所以值得参考和推荐。
既然SqlBulkCopy解决大数据量的插入问题,那么删除和更新怎么办呢? 详见 第二十三节: EF性能篇(三)之基于开源组件 Z.EntityFrameWork.Plus.EF6解决EF性能问题
先记下地址,后面补充一下
https://github.com/MikaelEliasson/EntityFramework.Utilities
第十四节: 介绍四大并发集合类并结合单例模式下的队列来说明线程安全和非安全的场景及补充性能调优问题。
一. 四大并发集合类
背景:我们目前使用的所有集合都是线程不安全的 。
A. ConcurrentBag:就是利用线程槽来分摊Bag中的所有数据,链表的头插法,0代表移除最后一个插入的值.
(等价于同步中的List)
B. ConcurrentStack:线程安全的Stack是使用Interlocked来实现线程安全, 而没有使用内核锁.
(等价于同步中的数组)
C. ConcurrentQueue: 队列的模式,先进先出
(等价于同步中的队列)
D. ConcurrentDictionary: 字典的模式
(等价于同步中的字典)
以上四种安全的并发集合类,也可以采用同步版本+Lock锁(或其它锁)来实现
代码实践:
01-ConcurrentBag
{
Console.WriteLine("---------------- 01-ConcurrentBag ---------------------");
ConcurrentBag<int> bag = new ConcurrentBag<int>();
bag.Add(1);
bag.Add(2);
bag.Add(33);
//链表的头插法,0代表移除最后一个插入的值
var result = 0;
//flag为true,表示移除成功,并且返回被移除的值
var flag = bag.TryTake(out result);
Console.WriteLine("移除的值为:{0}", result);
}
#endregion
02-ConcurrentStack
{
Console.WriteLine("---------------- 02-ConcurrentStack ---------------------");
ConcurrentStack<int> stack = new ConcurrentStack<int>();
stack.Push(1);
stack.Push(2);
stack.Push(33);
//链表的头插法,0代表移除最后一个插入的值
var result = 0;
//flag为true,表示移除成功,并且返回被移除的值
var flag = stack.TryPop(out result);
Console.WriteLine("移除的值为:{0}", result);
}
#endregion
03-ConcurrentQueue
{
Console.WriteLine("---------------- 03-ConcurrentQueue ---------------------");
ConcurrentQueue<int> queue = new ConcurrentQueue<int>();
queue.Enqueue(1);
queue.Enqueue(2);
queue.Enqueue(33);
//队列的模式,先进先出,0代表第一个插入的值
var result = 0;
//flag为true,表示移除成功,并且返回被移除的值
var flag = queue.TryDequeue(out result);
Console.WriteLine("移除的值为:{0}", result);
}
#endregion
04-ConcurrentDictionary
{
Console.WriteLine("---------------- 04-ConcurrentDictionary ---------------------");
ConcurrentDictionary<int, int> dic = new ConcurrentDictionary<int, int>();
dic.TryAdd(1, 10);
dic.TryAdd(2, 11);
dic.TryAdd(3, 12);
dic.ContainsKey(3);
//下面是输出字典中的所有值
foreach (var item in dic)
{
Console.WriteLine(item.Key + item.Value);
}
}
#endregion
代码结果:

二. 队列的综合案例
上面介绍了四大安全线程集合类和与其对应的不安全的线程集合类,可能你会比较疑惑,到底怎么安全了,那些不安全的集合类怎么能变成安全呢,下面以队列为例,来解决这些疑惑。
1. 测试Queue队列并发情况下是不安全的(存在资源竞用的问题),ConcurrentQueue队列在并发情况下是安全的。
2. 利用Lock锁+Queue队列,实现多线程并发情况下的安全问题,即等同于ConcurrentQueue队列的效果。
经典案例测试:开启100个线程进行入队操作,正常所有的线程执行结束后,队列中的个数应该为100.
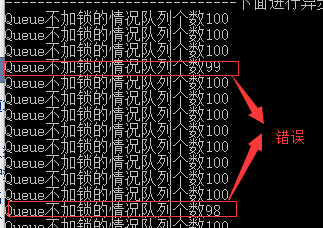
①. Queue不加锁的情况:结果出现99、98、100,显然是出问题了。
{
Queue queue = new Queue();
object o = new object();
int count = 0;
List<Task> taskList = new List<Task>();
for (int i = 0; i < 100; i++)
{
var task = Task.Run(() =>
{
queue.Enqueue(count++);
});
taskList.Add(task);
}
Task.WaitAll(taskList.ToArray());
//发现队列个数在不加锁的情况下 竟然不同 有100,有99
Console.WriteLine("Queue不加锁的情况队列个数" + queue.Count);
}
②. Queue加锁的情况:结果全是100,显然是正确的。
1 {
2 Queue queue = new Queue();
3 object o = new object();
4 int count = 0;
5 List<Task> taskList = new List<Task>();
6 for (int i = 0; i < 100; i++)
7 {
8 var task = Task.Run(() =>
9 {
10 lock (o)
11 {
12 queue.Enqueue(count++);
13 }
14 });
15 taskList.Add(task);
16 }
17
18 Task.WaitAll(taskList.ToArray());
19 //发现队列个数在全是100
20 Console.WriteLine("Queue加锁的情况队列个数" + queue.Count);
21 }

③. ConcurrentQueue不加锁的情况:结果全是100,显然是正确,同时证明ConcurrentQueue队列本身就是线程安全的。
1 {
2 ConcurrentQueue<int> queue = new ConcurrentQueue<int>();
3 object o = new object();
4 int count = 0;
5 List<Task> taskList = new List<Task>();
6
7 for (int i = 0; i < 100; i++)
8 {
9 var task = Task.Run(() =>
10 {
11 queue.Enqueue(count++);
12 });
13 taskList.Add(task);
14 }
15 Task.WaitAll(taskList.ToArray());
16 //发现队列个数不加锁的情形=也全是100,证明ConcurrentQueue是线程安全的
17 Console.WriteLine("ConcurrentQueue不加锁的情况下队列个数" + queue.Count);
18 }

3. 在实际项目中,如果使用队列来实现一个业务,该队列需要是全局的,这个时候就需要使用单例(ps:单例是不允许被实例化的,可以通过单例类中的属性或者方法的形式来获取这个类),同时,队列的入队和出队操作,如果使用Queue队列,需要配合lock锁,来解决多线程下资源的竞用问题。
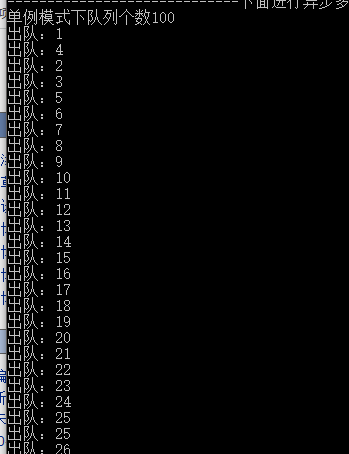
经典案例:开启100个线程对其进行入队操作,然后主线程输入队列的个数,并且将队列中的内容输出.
结果:队列的个数为100,输出内容1-100依次输出。
1 /// <summary>
2 /// 单例类
3 /// </summary>
4 public class QueueUtils
5 {
6 /// <summary>
7 /// 静态变量:由CLR保证,在程序第一次使用该类之前被调用,而且只调用一次
8 /// </summary>
9 private static readonly QueueUtils _QueueUtils = new QueueUtils();
10
11 /// <summary>
12 /// 声明为private类型的构造函数,禁止外部实例化
13 /// </summary>
14 private QueueUtils()
15 {
16
17 }
18 /// <summary>
19 /// 声明属性,供外部调用,此处也可以声明成方法
20 /// </summary>
21 public static QueueUtils instanse
22 {
23 get
24 {
25 return _QueueUtils;
26 }
27 }
28
29
30 //下面是队列相关的
31 Queue queue = new Queue();
32
33 private static object o = new object();
34
35 public int getCount()
36 {
37 return queue.Count;
38 }
39
40 /// <summary>
41 /// 入队方法
42 /// </summary>
43 /// <param name="myObject"></param>
44 public void Enqueue(object myObject)
45 {
46 lock (o)
47 {
48 queue.Enqueue(myObject);
49 }
50 }
51 /// <summary>
52 /// 出队操作
53 /// </summary>
54 /// <returns></returns>
55 public object Dequeue()
56 {
57 lock (o)
58 {
59 if (queue.Count > 0)
60 {
61 return queue.Dequeue();
62 }
63 }
64 return null;
65 }
66
67 }
1 {
2 int count = 1;
3 List<Task> taskList = new List<Task>();
4 for (int i = 0; i < 100; i++)
5 {
6 var task = Task.Run(() =>
7 {
8 QueueUtils.instanse.Enqueue(count++);
9 });
10 taskList.Add(task);
11 }
12
13 Task.WaitAll(taskList.ToArray());
14 //发现队列个数在全是100
15 Console.WriteLine("单例模式下队列个数" + QueueUtils.instanse.getCount());
16
17 //下面是出队相关的业务
18 while (QueueUtils.instanse.getCount() > 0)
19 {
20 Console.WriteLine("出队:" + QueueUtils.instanse.Dequeue());
21 }
22 }
 。。。。。。。。。。。
。。。。。。。。。。。
三. 常见的几类性能调优
PS:
1. 常见的一级事件:CPU占用过高、死锁问题、内存爆满
a. CPU过高:查看是否while(true)中的业务过于复杂,导致cpu一直在高负荷运行。
b. 死锁问题:乱用lock,千万不要lock中再加lock,多个lock重叠
c. 内存爆满:字符串的无限增长,全局的静态变量过多。
2. 补充几个常用的性能调优的方式
a. 使用字典类型Dictionary<T,T>,代替只有两个属性的对象或匿名对象。
b. 使用数组代替只有两个属性的对象或匿名对象。
比如:
index:存放id
value:存放数量或其他属性
3. 返璞归真,使用最原始的代码代替简洁漂亮的代码。
4. 合理的使用多线程,业务复杂的尽可能的并发执行(或者异步)。
5. 运用设计模式,使代码简洁、易于扩展。
第十三节:实际开发中使用最多的监视锁Monitor、lock语法糖的扩展、混合锁的使用(ManualResetEvent、SemaphoreSlim、ReaderWriterLockSlim)
一. 监视锁(Monitor和lock)
1. Monitor类,限定线程个数的一把锁,两个核心方法:
Enter:锁住某个资源。
Exit:退出某一个资源。
测试案例:开启5个线程同时对一个变量进行自增操作,结果变量有序的输出,说明该锁同时只允许一个线程访问。
但是写法很麻烦,每次都要try-catch-finally,还要声明bool变量。这个时候lock语法糖就很好的解决了这个问题。
代码实践:
1 static object lockMe = new object();
2 {
3 for (int i = 0; i < 5; i++)
4 {
5 Task.Factory.StartNew(() =>
6 {
7 for (int j = 0; j < 100; j++)
8 {
9 var b = false;
10 try
11 {
12 Monitor.Enter(lockMe, ref b);
13 Console.WriteLine(num++);
14 }
15 catch (Exception)
16 {
17
18 throw;
19 }
20 finally
21 {
22 if (b)
23 {
24 Monitor.Exit(lockMe);
25 }
26 }
27
28 }
29
30 });
31 }
32 }
2. lock语法糖
使用很简单,声明一个静态的object类型变量,调用lock语法糖,将共享变量放入其中,即可保证lock内同时只能一个线程访问。
代码实践:
1 {
2 for (int i = 0; i < 5; i++)
3 {
4 Task.Factory.StartNew(() =>
5 {
6 for (int j = 0; j < 100; j++)
7 {
8 lock (lockMe)
9 {
10 Console.WriteLine(num++);
11 }
12 }
13 });
14 }
15 }
二. 混合锁
1. 简介:混合锁=用户模式锁+内核模式锁,先在用户模式下内旋,如果超过一定的阈值,会切换到内核锁,在内旋模式下,我们会看到大量的Sleep(0),Sleep(1),Yield等语法。
Thread.Sleep(1) 让线程休眠1ms
Thread.Sleep(0) 让线程放弃当前的时间片,让本线程更高或者同等线程得到时间片运行。
Thread.Yield() 让线程立即放弃当前的时间片,可以让更低级别的线程得到运行,当其他thread时间片用完,本thread再度唤醒。
混合锁包括以下三种:ManualResetEventSlim、SemaphoreSlim、ReaderWriterLockSlim,这三种混合锁,要比他们对应的内核模式锁 (ManualResetEvent、Semaphore、ReaderWriterLock),的性能高的多。
2. ManualResetEventSlim
构造函数默认为false,可以使用Wait方法替代WaitOne方法,支持任务取消. (详细的代码同内核版本类似,这里不做测试了)
3. SemaphoreSlim
用法和内核版本类似,使用Wait方法代替WaitOne方法,Release方法不变。(详细的代码同内核版本类似,这里不做测试了)
4. ReaderWriterLockSlim
用法和内核版本类似,但是四个核心方法换成了:
锁读的两个核心方法:EnterReadLock、ExitReadLock。
锁写的两个核心方法:EnterWriteLock、ExitWriteLock。
(详细的代码同内核版本类似,这里不做测试了)
第十二节:深究内核模式锁的使用场景(自动事件锁、手动事件锁、信号量、互斥锁、读写锁、动态锁)
一. 整体介绍
温馨提示:内核模式锁,在不到万不得已的情况下,不要使用它,因为代价太大了,有很多种替代方案。
内核模式锁包括:
①:事件锁
②:信号量
③:互斥锁
④:读写锁
⑤:动态锁
二. 事件锁
事件锁包括:
A. 自动事件锁(AutoResetEvent)
使用场景:可以用此锁实现多线程环境下某个变量的自增.
现实场景: 进站火车闸机,我们用火车票来实现进站操作.
true: 表示终止状态,闸机中没有火车票
false: 表示费终止状态,闸机中此时有一张火车票
B.手动事件锁(ManualResetEvent)
现实场景:有人看守的铁道栅栏(和自动事件锁不一样,不能混用)
true: 栅栏没有合围,没有阻止行人通过铁路
false:栅栏合围了, 阻止行人通过
* 下面案例发现,锁不住,自增仍然是无序的输出了.
* 核心方法:WaitOne和Set
代码实践-自动事件锁:
1 static AutoResetEvent autoResetLock1 = new AutoResetEvent(true);
2 static AutoResetEvent autoResetLock2 = new AutoResetEvent(false);
3 static int num2 = 0;
4 {
5 //1. 能输出
6 {
7 autoResetLock1.WaitOne();
8 Console.WriteLine("autoResetLock1检验通过,可以通行");
9 autoResetLock1.Set();
10 }
11
12 //2. 不能输出
13 {
14 autoResetLock2.WaitOne();
15 Console.WriteLine("autoResetLock2检验通过,可以通行");
16 autoResetLock2.Set();
17 }
18
19 //3.下面代码的结果:num从0-249,有序的发现可以锁住。
20 {
21 for (int i = 0; i < 5; i++)
22 {
23 Task.Factory.StartNew(() =>
24 {
25 for (int j = 0; j < 50; j++)
26 {
27 try
28 {
29 autoResetLock1.WaitOne();
30 Console.WriteLine(num2++);
31 autoResetLock1.Set();
32 }
33 catch (Exception ex)
34 {
35 Console.WriteLine(ex.Message);
36 }
37
38 }
39 });
40 }
41 }
42 }
代码实践-手动事件锁:
1 static int num2 = 0;
2 static ManualResetEvent mreLock = new ManualResetEvent(true);
3 //下面代码锁不住,仍然是无序的输出了
4 {
5 for (int i = 0; i < 5; i++)
6 {
7 Task.Factory.StartNew(() =>
8 {
9 for (int j = 0; j < 50; j++)
10 {
11 try
12 {
13 mreLock.WaitOne();
14 Console.WriteLine(num2++);
15 mreLock.Set();
16 }
17 catch (Exception ex)
18 {
19 Console.WriteLine(ex.Message);
20 }
21
22 }
23 });
24 }
25 }
三. 信号量
信号量:
* 核心类:Semaphore,通过int数值来控制线程个数。
* 通过观察构造函数 public Semaphore(int initialCount, int maximumCount);:
* initialCount: 可以同时授予的信号量的初始请求数。
* maximumCount: 可以同时授予的信号量的最大请求数。
* static Semaphore seLock = new Semaphore(1, 1); //表示只允许一个线程通过
* 下面的案例可以有序的输出。
* 核心方法:WaitOne和Release
代码实践:
1 static Semaphore seLock = new Semaphore(1, 1); //只允许一个线程通过
2 //下面代码锁住了,可以有序的输出 3 { 4 for (int i = 0; i < 5; i++) 5 { 6 Task.Factory.StartNew(() => 7 { 8 for (int j = 0; j < 50; j++) 9 { 10 try 11 { 12 seLock.WaitOne(); 13 Console.WriteLine(num2++); 14 seLock.Release(); 15 } 16 catch (Exception ex) 17 { 18 Console.WriteLine(ex.Message); 19 } 20 21 } 22 }); 23 } 24 }
四. 互斥锁
互斥锁:
核心方法:WaitOne和ReleaseMutex
下面案例可以锁住,有序输出
总结以上三种类型的锁,都有一个WaitOne方法,观察源码可知,都继承于WaitHandle类。
代码实践:
1 static Mutex mutex = new Mutex();
2 //下面代码锁住了,可以有序的输出
3 {
4 for (int i = 0; i < 5; i++)
5 {
6 Task.Factory.StartNew(() =>
7 {
8 for (int j = 0; j < 50; j++)
9 {
10 try
11 {
12 mutex.WaitOne();
13 Console.WriteLine(num2++);
14 mutex.ReleaseMutex();
15 }
16 catch (Exception ex)
17 {
18 Console.WriteLine(ex.Message);
19 }
20
21 }
22 });
23 }
24 }
五. 读写锁
读写锁(ReaderWriterLock):
背景:多个线程读,一个线程写,如果写入的时间太久,此时读的线程会被卡死,这个时候就要用到读写锁了。
锁读的两个核心方法:AcquireReaderLock和ReleaseReaderLock。
锁写的两个核心方法:AcquireWriterLock和ReleaseWriterLock。
代码实践:
1 static ReaderWriterLock rwlock = new ReaderWriterLock();
2 private void button24_Click(object sender, EventArgs e)
3 {
4 #region 01-读写锁
5 {
6 //开启5个线程执行读操作
7 for (int i = 0; i < 5; i++)
8 {
9 Task.Run(() =>
10 {
11 Read();
12 });
13 }
14 //开启1个线程执行写操作
15 Task.Factory.StartNew(() =>
16 {
17 Write();
18 });
19 }
20 #endregion
21
22 }
23 /// <summary>
24 /// 线程读
25 /// </summary>
26 static void Read()
27 {
28 while (true)
29 {
30 Thread.Sleep(10);
31 rwlock.AcquireReaderLock(int.MaxValue);
32 Console.WriteLine("当前 t={0} 进行读取 {1}", Thread.CurrentThread.ManagedThreadId, DateTime.Now);
33 rwlock.ReleaseReaderLock();
34 }
35 }
36 /// <summary>
37 /// 线程写
38 /// </summary>
39 static void Write()
40 {
41 while (true)
42 {
43 Thread.Sleep(300);
44 rwlock.AcquireWriterLock(int.MaxValue);
45 Console.WriteLine("当前 t={0} 进行写入 {1}", Thread.CurrentThread.ManagedThreadId, DateTime.Now);
46 rwlock.ReleaseWriterLock();
47 }
48 }
六. 动态锁
动态锁(CountdownEvent):
* 作用:限制线程数的一个机制。
* 业务场景:有Orders、Products、Users表,我们需要多个线程从某一张表中读取数据。
* 比如:Order表10w,10个线程读取。(每个线程读1w)
Product表5w,5个线程读取。(每个线程读1w)
User表2w,2个线程读取。(每个线程读1w)
三个核心方法:
①.Reset方法:重置当前的线程数量上限。(初始化的时候,默认设置一个上限)
②.Signal方法:将当前的线程数量执行减1操作。(使用一个thread,这个线程数量就会减1操作,直到为0后,继续下一步)
③.Wait方法:相当于我们的Task.WaitAll方法。
代码实践:
1 //初始化线程数量上限为10.
2 static CountdownEvent cdLock = new CountdownEvent(10);
3 private void button25_Click(object sender, EventArgs e)
4 {
5 //加载Orders搞定
6 cdLock.Reset(10);
7 for (int i = 0; i < 10; i++)
8 {
9 Task.Factory.StartNew(() =>
10 {
11 LoadOrder();
12 });
13 }
14 cdLock.Wait();
15 Console.WriteLine("所有的Orders都加载完毕。。。。。。。。。。。。。。。。。。。。。");
16
17 //加载Product搞定
18 cdLock.Reset(5);
19 for (int i = 0; i < 5; i++)
20 {
21 Task.Run(() =>
22 {
23 LoadProduct();
24 });
25 }
26 cdLock.Wait();
27 Console.WriteLine("所有的Products都加载完毕。。。。。。。。。。。。。。。。。。。。。");
28
29 //加载Users搞定
30 cdLock.Reset(2);
31 for (int i = 0; i < 2; i++)
32 {
33 Task.Factory.StartNew(() =>
34 {
35 LoadUser();
36 });
37 }
38 cdLock.Wait();
39 Console.WriteLine("所有的Users都加载完毕。。。。。。。。。。。。。。。。。。。。。");
40
41 Console.WriteLine("所有的表数据都执行结束了。。。恭喜恭喜。。。。");
42 Console.Read();
43 }
44 static void LoadOrder()
45 {
46 //书写具体的业务逻辑
47 Console.WriteLine("当前LoadOrder正在加载中。。。{0}", Thread.CurrentThread.ManagedThreadId);
48 //线程数量减1
49 cdLock.Signal();
50
51 }
52 static void LoadProduct()
53 {
54 //书写具体的业务逻辑
55 Console.WriteLine("当前LoadProduct正在加载中。。。{0}", Thread.CurrentThread.ManagedThreadId);
56 //线程数量减1
57 cdLock.Signal();
58 }
59 static void LoadUser()
60 {
61 //书写具体的业务逻辑
62 Console.WriteLine("当前LoadUser正在加载中。。。{0}", Thread.CurrentThread.ManagedThreadId);
63 //线程数量减1
64 cdLock.Signal();
65 }
第十一节:深究用户模式锁的使用场景(异变结构、互锁、旋转锁)
一. 锁机制的背景介绍
本章节,将结合多线程来介绍锁机制, 那么问题来了,什么是锁呢? 为什么需要锁? 为什么要结合多线程来介绍锁呢?锁的使用场景又是什么呢? DotNet中又有哪些锁呢?
在接下来的几个章节中,将陆续解答这些问题。
PS:
多个线程对一个共享资源进行使用的时候,会出问题, 比如实际的业务场景,入库和出库操作同时进行,库存量就会存在并发问题。所以锁就是用来解决多线程资源竞用的问题。
Net领域中,锁机制非常多,比如:时间锁、信号量、互斥锁、读写锁、互锁、异变结构,主要我们可以把他们划分为三大类:
①.用户模式锁:就是通过一些cpu指令或者一个死循环,来达到达到线程的等待和休眠。
②.内核模式锁:就是调用win32底层的代码,来实现thread的各种操作。
③.混合锁:用户模式+内核模式
其中用户模式锁又分为这么几类:异变结构、互锁和旋转锁。
二. 异变结构
背景:一个线程读,一个线程写,在release模式下会出现bug,导致主线程无法执行,原因在前面章节已经介绍过了。
方式一:利用MemoryBarrier方法进行处理 。(前面章节已介绍)
方式二:利用VolatileRead/Write方法进行处理。 (前面章节已介绍)
方式三:volatile关键字进行处理,我的read和write都是从memrory中读取,读取的都是最新的。(下面的案例使用volatile关键字后,主线程可以执行)
代码实践:
1 public static volatile bool isStop = false;
2 //使用Volatile关键字处理 3 var t = new Thread(() => 4 { 5 var isSuccess = false; 6 while (!isStop) 7 { 8 isSuccess = !isSuccess; 9 } 10 }); 11 t.Start(); 12 Thread.Sleep(1000); 13 isStop = true; 14 t.Join(); 15 Console.WriteLine("主线程执行结束!"); 16 Console.ReadLine();
代码结论:使用volatile关键字进行修饰,解决共享资源的竞用问题。
三. 互锁
互锁结构(Interlocked类),常用的方法有:
* Increment:自增操作
* Decrement:自减操作
* Add: 增加指定的值
* Exchange: 赋值
* CompareExchange: 比较赋值
代码实践:
1 {
2 //1. 自增
3 {
4 int a = 1;
5 Interlocked.Increment(ref a);
6 Console.WriteLine("自增后的数据为:{0}", a);
7 }
8 //2. 自减
9 {
10 int b = 2;
11 Interlocked.Decrement(ref b);
12 Console.WriteLine("自减后的数据为:{0}", b);
13 }
14 //3. 增加操作
15 {
16 int c = 3;
17 Interlocked.Add(ref c, 4);
18 Console.WriteLine("增加后的数据为:{0}", c);
19
20 }
21 //4. 赋值操作
22 {
23 int d = 4;
24 Interlocked.Exchange(ref d, 55);
25 Console.WriteLine("赋值后的数据为:{0}", d);
26
27 }
28 //5. 比较赋值
29 {
30 //Interlocked.CompareExchange(ref num1, sum, num2); // num1==num2 ; num1=sum;
31 int ee = 5;
32 Interlocked.CompareExchange(ref ee, 15, 5);
33 Console.WriteLine("比较赋值后的数据为:{0}", ee);
34
35 Interlocked.CompareExchange(ref ee, 100, 15);
36 Console.WriteLine("比较赋值后的数据为:{0}", ee);
37
38 }
39
40 }
代码结果:

四. 旋转锁
旋转锁(SpinLock), 特殊的业务逻辑让thread在用户模式下进行自选,欺骗cpu当前thread正在运行中。
SpinLock类有两个核心方法,分别是:Enter和Exit方法。
代码实践:
1 {
2 //下面代码的结果:num从0-249,且是有序的。
3 //如果把旋转锁去掉,num将没有任何顺序
4 for (int i = 0; i < 5; i++)
5 {
6 Task.Factory.StartNew(() =>
7 {
8 for (int j = 0; j < 50; j++)
9 {
10 try
11 {
12 var b = false;
13 sl.Enter(ref b);
14 Console.WriteLine(num++);
15 }
16 catch (Exception ex)
17 {
18 Console.WriteLine(ex.Message);
19 }
20 finally
21 {
22 sl.Exit();
23 }
24 }
25 });
26 }
27 }
代码结果:下面代码的结果:num从0-249,且是有序的;如果将旋转锁的代码去掉,num的输出将没有任何顺序可言。
第十节:利用async和await简化异步编程模式的几种写法
一. async和await简介
PS:简介
1. async和await这两个关键字是为了简化异步编程模型而诞生的,使的异步编程跟简洁,它本身并不创建新线程,但在该方法内部开启多线程,则另算。
2. 这两个关键字适用于处理一些文件IO操作。
3. 好处:代码简介,把异步的代码写成了同步的形式,提高了开发效率。
坏处:如果使用同步思维去理解,容易出问题,返回值对不上。
二. 几种用法
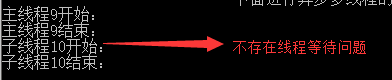
情况1:当只有async,没有await时,方法会有个警告,和普通的多线程方法没有什么区别,不存在线程等待的问题。
代码实践:
1 private static async void Test1()
2 {
3 //主线程执行
4 Console.WriteLine("主线程{0}开始:", Thread.CurrentThread.ManagedThreadId);
5 //启动新线程完成任务
6 Task task = Task.Run(() =>
7 {
8 Console.WriteLine("子线程{0}开始:", Thread.CurrentThread.ManagedThreadId);
9 Thread.Sleep(3000);
10 Console.WriteLine("子线程{0}结束:", Thread.CurrentThread.ManagedThreadId);
11 });
12 //主线程执行
13 Console.WriteLine("主线程{0}结束:", Thread.CurrentThread.ManagedThreadId);
14 }
代码结果:
情况2:不推荐void返回值,使用Task来代替Task和Task<T>能够使用await, Task.WhenAny, Task.WhenAll等方式组合使用,async Void 不行。
代码实践:
1 /// <summary>
2 /// 不推荐void返回值,使用Task来代替
3 /// Task和Task<T>能够使用await, Task.WhenAny, Task.WhenAll等方式组合使用。async Void 不行
4 /// </summary>
5 private static async void Test2()
6 {
7 //主线程执行
8 Console.WriteLine("主线程{0}开始:", Thread.CurrentThread.ManagedThreadId);
9 //启动新线程完成任务
10 Task task = Task.Run(() =>
11 {
12 Console.WriteLine("子线程{0}开始:", Thread.CurrentThread.ManagedThreadId);
13 Thread.Sleep(3000);
14 Console.WriteLine("子线程{0}结束:", Thread.CurrentThread.ManagedThreadId);
15 });
16 await task; //等待子线程执行完毕,方可执行后面的语句
17 Console.WriteLine("主线程{0}结束:", Thread.CurrentThread.ManagedThreadId);
18 }
代码结果:

情况3:async Task == async void。 区别:Task和Task<T>能够使用await, Task.WhenAny, Task.WhenAll等方式组合使用,async Void 不行。
代码实践:
1 /// <summary>
2 /// 无返回值 async Task == async void
3 /// Task和Task<T>能够使用await, Task.WhenAny, Task.WhenAll等方式组合使用,async Void 不行
4 /// </summary>
5 private static async Task Test3()
6 {
7 //主线程执行
8 Console.WriteLine("主线程{0}开始:", Thread.CurrentThread.ManagedThreadId);
9 //启动新线程完成任务
10 Task task = Task.Run(() =>
11 {
12 Console.WriteLine("子线程{0}开始:", Thread.CurrentThread.ManagedThreadId);
13 Thread.Sleep(3000);
14 Console.WriteLine("子线程{0}结束:", Thread.CurrentThread.ManagedThreadId);
15 });
16 await task; //等待子线程执行完毕,方可执行后面的语句
17 Console.WriteLine("主线程{0}结束:", Thread.CurrentThread.ManagedThreadId);
18 }
代码结果:
情况4和情况5:说明要使用子线程中的变量,一定要等子线程执行结束后再使用。
代码实践:
1 /// <summary>
2 /// 带返回值的Task,要使用返回值,一定要等子线程计算完毕才行
3 /// </summary>
4 /// <returns></returns>
5 private static async Task<long> Test4()
6 {
7 //主线程执行
8 Console.WriteLine("主线程{0}开始:", Thread.CurrentThread.ManagedThreadId);
9 long result = 0;
10 //启动新线程完成任务
11 Task task = Task.Run(() =>
12 {
13 for (long i = 0; i < 100; i++)
14 {
15 result += i;
16 }
17 });
18 await task; //等待子线程执行完毕,方可执行后面的语句
19 Console.WriteLine("主线程{0}结束:", Thread.CurrentThread.ManagedThreadId);
20 Console.WriteLine("result:{0}", result);
21 return result;
22 }
1 /// <summary>
2 /// 带返回值的Task,要使用返回值,一定要等子线程计算完毕才行
3 /// 与情况四形成对比,没有等待,最终结果不准确
4 /// </summary>
5 /// <returns></returns>
6 private static Task<long> Test5()
7 {
8 //主线程执行
9 Console.WriteLine("主线程{0}开始:", Thread.CurrentThread.ManagedThreadId);
10 long result = 0;
11 //启动新线程完成任务
12 TaskFactory taskFactory = new TaskFactory();
13 Task<long> task = taskFactory.StartNew<long>(() =>
14 {
15 for (long i = 0; i < 100; i++)
16 {
17 result += i;
18 }
19 return 1;
20 });
21 Console.WriteLine("主线程{0}结束:", Thread.CurrentThread.ManagedThreadId);
22 Console.WriteLine("result:{0}", result);
23 return task;
24 }
代码结果:
以上两种情况,第一种情况含有线程等待的结果为4950,第二个情况么有线程等待,结果不准确(即共享变量竞用问题)。

