

C#设计模式总结 C#设计模式(22)——访问者模式(Vistor Pattern) C#设计模式总结 .NET Core launch.json 简介 利用Bootstrap Paginator插件和knockout.js完成分页功能 图片在线裁剪和图片上传总结 循序渐进学.Net Core Web Api开发系列【2】:利用Swagger调试WebApi
C#设计模式总结
一、 设计原则
使用设计模式的根本原因是适应变化,提高代码复用率,使软件更具有可维护性和可扩展性。并且,在进行设计的时候,也需要遵循以下几个原则:单一职责原则、开放封闭原则、里氏代替原则、依赖倒置原则、接口隔离原则、合成复用原则和迪米特法则。下面就分别介绍了每种设计原则。
1.1 单一职责原则
就一个类而言,应该只有一个引起它变化的原因。如果一个类承担的职责过多,就等于把这些职责耦合在一起,一个职责的变化可能会影响到其他的职责。另外,把多个职责耦合在一起,也会影响复用性。
1.2 开闭原则(Open-Closed Principle)
开闭原则即OCP(Open-Closed Principle缩写)原则,该原则强调的是:一个软件实体(指的类、函数、模块等)应该对扩展开放,对修改关闭。即每次发生变化时,要通过添加新的代码来增强现有类型的行为,而不是修改原有的代码。
符合开闭原则的最好方式是提供一个固有的接口,然后让所有可能发生变化的类实现该接口,让固定的接口与相关对象进行交互。
1.3 里氏代替原则(Liskov Substitution Principle)
Liskov Substitution Principle,LSP(里氏代替原则)指的是子类必须替换掉它们的父类型。也就是说,在软件开发过程中,子类替换父类后,程序的行为是一样的。只有当子类替换掉父类后,此时软件的功能不受影响时,父类才能真正地被复用,而子类也可以在父类的基础上添加新的行为。
1.4 依赖倒置原则
依赖倒置(Dependence Inversion Principle, DIP)原则指的是抽象不应该依赖于细节,细节应该依赖于抽象,也就是提出的 “面向接口编程,而不是面向实现编程”。这样可以降低客户与具体实现的耦合。
1.5 接口隔离原则
接口隔离原则(Interface Segregation Principle, ISP)指的是使用多个专门的接口比使用单一的总接口要好。也就是说不要让一个单一的接口承担过多的职责,而应把每个职责分离到多个专门的接口中,进行接口分离。过于臃肿的接口是对接口的一种污染。
1.6 合成复用原则
合成复用原则(Composite Reuse Principle, CRP)就是在一个新的对象里面使用一些已有的对象,使之成为新对象的一部分。新对象通过向这些对象的委派达到复用已用功能的目的。简单地说,就是要尽量使用合成/聚合,尽量不要使用继承。
要使用好合成复用原则,首先需要区分"Has—A"和“Is—A”的关系:
1)“Is—A”是指一个类是另一个类的“一种”,是属于的关系;
2)而“Has—A”则不同,它表示某一个角色具有某一项责任。
导致错误的使用继承而不是聚合的常见的原因是错误地把“Has—A”当成“Is—A”。例如:

实际上,雇员、经理、学生描述的是一种角色。比如,一个人是“经理”必然是“雇员”。在上面的设计中,一个人无法同时拥有多个角色,是“雇员”就不能再是“学生”了,这显然不合理,因为现在很多在职研究生,即使雇员也是学生。
上面的设计的错误源于把“角色”的等级结构与“人”的等级结构混淆起来了,误把“Has—A”当作"Is—A"。具体的解决方法就是抽象出一个角色类:

1.7 迪米特法则
迪米特法则(Law of Demeter,LoD)又叫最少知识原则(Least Knowledge Principle,LKP),指的是一个对象应当对其他对象有尽可能少的了解。也就是说,一个模块或对象应尽量少的与其他实体之间发生相互作用,使得系统功能模块相对独立,这样当一个模块修改时,影响的模块就会越少,扩展起来更加容易。
关于迪米特法则其他的一些表述有:只与你直接的朋友们通信,不要跟“陌生人”说话。
外观模式(Facade Pattern)和中介者模式(Mediator Pattern)就使用了迪米特法则。
二、创建型模式
创建型模式就是用来创建对象的模式,抽象了实例化的过程。所有的创建型模式都有两个共同点。第一,它们都将系统使用哪些具体类的信息封装起来;第二,它们隐藏了这些类的实例是如何被创建和组织的。创建型模式包括单例模式、工厂方法模式、抽象工厂模式、建造者模式和原型模式。
单例模式:解决的是实例化对象的个数的问题,比如抽象工厂中的工厂、对象池等。除了Singleton之外,其他创建型模式解决的都是 new 所带来的耦合关系。
抽象工厂:创建一系列相互依赖对象,并能在运行时改变系列。
工厂方法:创建单个对象,在Abstract Factory有使用到。
原型模式:通过拷贝原型来创建新的对象。
工厂方法,抽象工厂, 建造者都需要一个额外的工厂类来负责实例化“一个对象”,而Prototype则是通过原型(一个特殊的工厂类)来克隆“易变对象”。
下面详细介绍下它们。
2.1 单例模式
单例模式指的是确保某一个类只有一个实例,并提供一个全局访问点。解决的是实体对象个数的问题,而其他的建造者模式都是解决new所带来的耦合关系问题。其实现要点有:
类只有一个实例。问:如何保证呢?答:通过私有构造函数来保证类外部不能对类进行实例化。
提供一个全局的访问点。问:如何实现呢?答:创建一个返回该类对象的静态方法。
单例模式的结构图如下所示:

2.2 工厂方法模式
工厂方法模式指的是定义一个创建对象的工厂接口,由其子类决定要实例化的类,将实际创建工作推迟到子类中。它强调的是”单个对象“的变化。其实现要点有:
定义一个工厂接口。问:如何实现呢?答:声明一个工厂抽象类。
由其具体子类创建对象。问:如何去实现呢?答:创建派生于工厂抽象类,即由具体工厂去创建具体产品,既然要创建产品,自然需要产品抽象类和具体产品类了。
其具体的UML结构图如下所示:

在工厂方法模式中,工厂类与具体产品类具有平行的等级结构,它们之间是一一对应关系。
2.3 抽象工厂模式
抽象工厂模式指的是提供一个创建一系列相关或相互依赖对象的接口,使得客户端可以在不必指定产品的具体类型的情况下,创建多个产品族中的产品对象,强调的是”系列对象“的变化。其实现要点有:
提供一系列对象的接口。问:如何去实现呢?答:提供多个产品的抽象接口。
创建多个产品族中的多个产品对象。问:如何做到呢?答:每个具体工厂创建一个产品族中的多个产品对象,多个具体工厂就可以创建多个产品族中的多个对象了。
具体的UML结构图如下所示:

2.4 建造者模式
建造者模式指的是将一个产品的内部表示与产品的构造过程分割开来,从而可以使一个建造过程生成具体不同的内部表示的产品对象。强调的是产品的构造过程。其实现要点有:
将产品的内部表示与产品的构造过程分割开来。问:如何把它们分割开呢?答:不要把产品的构造过程放在产品类中,而是由建造者类来负责构造过程,产品的内部表示放在产品类中,这样不就分割开了嘛。
具体的UML结构图如下所示:

2.5 原型工厂模式
原型模式指的是通过给出一个原型对象来指明所要创建的对象类型,然后用复制的方法来创建出更多的同类型对象。其实现要点有:
给出一个原型对象。问:如何办到呢?答:很简单嘛,直接给出一个原型类就好了。
通过复制的方法来创建同类型对象。问:又是如何实现呢?答:.NET可以直接调用MemberwiseClone方法来实现浅拷贝。
具体的UML结构图如下所示:

三、结构型模式
结构型模式,顾名思义讨论的是类和对象的结构 ,主要用来处理类或对象的组合。它包括两种类型,一是类结构型模式,指的是采用继承机制来组合接口或实现;二是对象结构型模式,指的是通过组合对象的方式来实现新的功能。它包括适配器模式、桥接模式、装饰者模式、组合模式、外观模式、享元模式和代理模式。
适配器模式:注重转换接口,将不吻合的接口适配对接。
桥接模式:注重分离接口与其实现,支持多维度变化。
组合模式:注重统一接口,将“一对多”的关系转化为“一对一”的关系。
装饰者模式:注重稳定接口,在此前提下为对象扩展功能。
外观模式:注重简化接口,简化组件系统与外部客户程序的依赖关系。
享元模式:注重保留接口,在内部使用共享技术对对象存储进行优化。
代理模式:注重假借接口,增加间接层来实现灵活控制。
3.1 适配器模式
适配器模式意在转换接口,它能够使原本不能再一起工作的两个类一起工作。所以经常用来在类库的复用、代码迁移等方面。例如DataAdapter类就应用了适配器模式。适配器模式包括类适配器模式和对象适配器模式,具体结构如下图所示,左边是类适配器模式,右边是对象适配器模式。

3.2 桥接模式
桥接模式旨在将抽象化与实现化解耦,使得两者可以独立地变化。意思就是说,桥接模式把原来基类的实现化细节再进一步进行抽象,构造到一个实现化的结构中,然后再把原来的基类改造成一个抽象化的等级结构,这样就可以实现系统在多个维度的独立变化,桥接模式的结构图如下所示。

3.3 装饰者模式
装饰者模式又称包装(Wrapper)模式,它可以动态地给一个对象添加一些额外的功能。装饰者模式较继承生成子类的方式更加灵活。虽然装饰者模式能够动态地将职责附加到对象上,但它也会造成产生一些细小的对象,增加了系统的复杂度。具体的结构图如下所示。

3.4 组合模式
组合模式又称为部分—整体模式。组合模式将对象组合成树形结构,用来表示整体与部分的关系。组合模式使得客户端将单个对象和组合对象同等对待。如在.NET中WinForm中的控件,TextBox、Label等简单控件继承与Control类,同时GroupBox这样的组合控件也是继承于Control类。组合模式的具体结构图如下所示。

3.5 外观模式
在系统中,客户端经常需要与多个子系统进行交互,这样导致客户端会随着子系统的变化而变化。此时,可以使用外观模式把客户端与各个子系统解耦。外观模式指的是为子系统中的一组接口提供一个一致的门面,它提供了一个高层接口,这个接口使子系统更加容易使用。如电信的客户专员,你可以让客户专员来完成冲话费,修改套餐等业务,而不需要自己去与各个子系统进行交互。具体类结构图如下所示:

3.6 享元模式
在系统中,如果我们需要重复使用某个对象时。此时,如果重复地使用new操作符来创建这个对象的话,这对系统资源是一个极大的浪费,既然每次使用的都是同一个对象,为什么不能对其共享呢?这也是享元模式出现的原因。
享元模式运用共享的技术有效地支持细粒度的对象,使其进行共享。在.NET类库中,String类的实现就使用了享元模式,String类采用字符串驻留池的来使字符串进行共享。更多内容参考博文:http://www.cnblogs.com/artech/archive/2010/11/25/internedstring.html。享元模式的具体结构图如下所示:

3.7 代理模式
在系统开发中,有些对象由于网络或其他的障碍,以至于不能直接对其访问。此时可以通过一个代理对象来实现对目标对象的访问。如.NET中的调用Web服务等操作。
代理模式指的是给某一个对象提供一个代理,并由代理对象控制对原对象的访问。具体的结构图如下所示:

注:外观模式、适配器模式和代理模式区别?
解答:这三个模式的相同之处是,它们都是作为客户端与真实被使用的类或系统之间的一个中间层,起到让客户端间接调用真实类的作用。不同之处在于,所应用的场合和意图不同。
代理模式与外观模式主要区别在于:
1)客户对象无法直接访问对象,只能由代理对象提供访问。
2)而外观对象提供对各个子系统简化访问调用接口。
而适配器模式则不需要虚构一个代理者,目的是复用原有的接口。
外观模式是定义新的接口,而适配器则是复用一个原有的接口。
另外,它们应用设计的不同阶段。外观模式用于设计的前期,因为系统需要前期就需要依赖于外观。而适配器应用于设计完成之后,当发现设计完成的类无法协同工作时,可以采用适配器模式。然而,很多情况下在设计初期就要考虑适配器模式的使用,如涉及到大量第三方应用接口的情况;代理模式是设计完成后,想以服务的方式提供给其他客户端进行调用,此时其他客户端可以使用代理模式来对模块进行访问。
总之,代理模式提供与真实类一致的接口,旨在用代理类来访问真实的类。外观模式旨在简化接口。适配器模式旨在转换接口。
四、行为型模式
行为型模式是对在不同对象之间划分责任和算法的抽象化。行为模式不仅仅关于类和对象,还关于它们之间的相互作用。行为型模式又分为类的行为模式和对象的行为模式两种。
类的行为模式——使用继承关系在几个类之间分配行为。
对象的行为模式——使用对象聚合的方式来分配行为。
行为型模式包括11种模式:模板方法模式、命令模式、迭代器模式、观察者模式、中介者模式、状态模式、策略模式、责任链模式、访问者模式、解释器模式和备忘录模式。
模板方法模式:封装算法结构,定义算法骨架,支持算法子步骤变化。
命令模式:注重将请求封装为对象,支持请求的变化,通过将一组行为抽象为对象,实现行为请求者和行为实现者之间的解耦。
迭代器模式:注重封装特定领域变化,支持集合的变化,屏蔽集合对象内部复杂结构,提供客户程序对它的透明遍历。
观察者模式:注重封装对象通知,支持通信对象的变化,实现对象状态改变,通知依赖它的对象并更新。
中介者模式:注重封装对象间的交互,通过封装一系列对象之间的复杂交互,使他们不需要显式相互引用,实现解耦。
状态模式:注重封装与状态相关的行为,支持状态的变化,通过封装对象状态,从而在其内部状态改变时改变它的行为。
策略模式:注重封装算法,支持算法的变化,通过封装一系列算法,从而可以随时独立于客户替换算法。
责任链模式:注重封装对象责任,支持责任的变化,通过动态构建职责链,实现事务处理。
访问者模式:注重封装对象操作变化,支持在运行时为类结构添加新的操作,在类层次结构中,在不改变各类的前提下定义作用于这些类实例的新的操作。
备忘录模式:注重封装对象状态变化,支持状态保存、恢复。
解释器模式:注重封装特定领域变化,支持领域问题的频繁变化,将特定领域的问题表达为某种语法规则下的句子,然后构建一个解释器来解释这样的句子,从而达到解决问题的目的。
4.1 模板方法模式
在现实生活中,有论文模板,简历模板等。在现实生活中,模板的概念是给定一定的格式,然后其他所有使用模板的人可以根据自己的需求去实现它。同样,模板方法也是这样的。
模板方法模式是在一个抽象类中定义一个操作中的算法骨架,而将一些具体步骤实现延迟到子类中去实现。模板方法使得子类可以不改变算法结构的前提下,重新定义算法的特定步骤,从而达到复用代码的效果。具体的结构图如下所示:

4.2 命令模式
命令模式属于对象的行为模式,命令模式把一个请求或操作封装到一个对象中,通过对命令的抽象化来使得发出命令的责任和执行命令的责任分隔开。命令模式的实现可以提供命令的撤销和恢复功能。具体的结构图如下所示:

4.3 迭代器模式
迭代器模式是针对集合对象而生的,对于集合对象而言,必然涉及到集合元素的添加删除操作,也肯定支持遍历集合元素的操作。此时,如果把遍历操作也放在集合对象的话,集合对象就承担太多的责任了。所以进行责任分离,把集合的遍历放在另一个对象中,这个对象就是迭代器对象。
迭代器模式提供了一种方法来顺序访问一个集合对象中各个元素,而又无需暴露该对象的内部表示,这样既可以做到不暴露集合的内部结构,又可以让外部代码透明地访问集合内部元素。具体的结构图如下所示:

4.4 观察者模式
在现实生活中,处处可见观察者模式,例如,微信中的订阅号,订阅博客和QQ微博中关注好友,这些都属于观察者模式的应用。
观察者模式定义了一种一对多的依赖关系,让多个观察者对象同时监听某一个主题对象,这个主题对象在状态发生变化时,会通知所有观察者对象,使它们能够自动更新自己的行为。具体结构图如下所示:

4.5 中介者模式
在现实生活中,有很多中介者模式的身影,例如QQ游戏平台,聊天室、QQ群和短信平台,这些都是中介者模式在现实生活中的应用。
中介者模式,定义了一个中介对象来封装一系列对象之间的交互关系。中介者使各个对象之间不需要显式地相互引用,从而使耦合性降低,而且可以独立地改变它们之间的交互行为。具体的结构图如下所示:

4.6 状态模式
每个对象都有其对应的状态,而每个状态又对应一些相应的行为,如果某个对象有多个状态时,那么就会对应很多的行为。那么对这些状态的判断和根据状态完成的行为,就会导致多重条件语句,并且如果添加一种新的状态时,需要更改之前现有的代码。这样的设计显然违背了开闭原则,状态模式正是用来解决这样的问题的。
状态模式——允许一个对象在其内部状态改变时自动改变其行为,对象看起来就像是改变了它的类。具体的结构图如下所示:

4.7 策略模式
在现实生活中,中国的所得税,分为企业所得税、外商投资企业或外商企业所得税和个人所得税。针对于这3种所得税,每种所计算的方式不同。个人所得税有个人所得税的计算方式,而企业所得税有其对应计算方式。如果不采用策略模式来实现这样一个需求的话,我们会定义一个所得税类,该类有一个属性来标识所得税的类型,并且有一个计算税收的CalculateTax()方法。在该方法体内需要对税收类型进行判断,通过if-else语句来针对不同的税收类型来计算其所得税。这样的实现确实可以解决这个场景,但是这样的设计不利于扩展。如果系统后期需要增加一种所得税时,此时不得不回去修改CalculateTax方法来多添加一个判断语句,这样明白违背了“开放——封闭”原则。此时,我们可以考虑使用策略模式来解决这个问题,既然税收方法是这个场景中的变化部分,此时自然可以想到对税收方法进行抽象,这也是策略模式实现的精髓所在。
策略模式是对算法的包装,是把使用算法的责任和算法本身分割开,委派给不同的对象负责。策略模式通常把一系列的算法包装到一系列的策略类里面。用一句话慨括策略模式就是——“将每个算法封装到不同的策略类中,使得它们可以互换”。下面是策略模式的结构图:

4.8 责任链模式
在现实生活中,有很多请求并不是一个人说了就算的。例如面试时的工资,低于1万的薪水可能技术经理就可以决定了,但是1万~1万5的薪水可能技术经理就没这个权利批准,可能需要请求技术总监的批准。
责任链模式——某个请求需要多个对象进行处理,从而避免请求的发送者和接收之间的耦合关系。将这些对象连成一条链子,并沿着这条链子传递该请求,直到有对象处理它为止。具体结构图如下所示:

4.9 访问者模式
访问者模式是封装一些施加于某种数据结构之上的操作。一旦这些操作需要修改的话,接受这个操作的数据结构则可以保存不变。访问者模式适用于数据结构相对稳定的系统, 它把数据结构和作用于数据结构之上的操作之间的耦合度降低,使得操作集合可以相对自由地改变。具体结构图如下所示:

4.10 备忘录模式
生活中的手机通讯录备忘录,操作系统备份点,数据库备份等都是备忘录模式的应用。备忘录模式是在不破坏封装的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态,这样以后就可以把该对象恢复到原先的状态。具体的结构图如下所示:

4.11 解释器模式
解释器模式是一个比较少用的模式,所以我自己也没有对该模式进行深入研究。在生活中,英汉词典的作用就是实现英文和中文互译,这就是解释器模式的应用。
解释器模式是给定一种语言,定义它文法的一种表示,并定义一种解释器。这个解释器使用该表示来解释语言中的句子。具体的结构图如下所示:

五、总结
23种设计模式,是前辈们总结出来解决问题的方式。它们追求的宗旨还是保证系统的低耦合高内聚,指导它们的原则无非就是封装变化,责任单一,面向接口编程等设计原则。
参考链接:http://www.cnblogs.com/zhili/p/DesignPatternSummery.html
C#设计模式(22)——访问者模式(Vistor Pattern)
一、引言
在上一篇博文中分享了责任链模式,责任链模式主要应用在系统中的某些功能需要多个对象参与才能完成的场景。在这篇博文中,我将为大家分享我对访问者模式的理解。
二、访问者模式介绍
2.1 访问者模式的定义
访问者模式是封装一些施加于某种数据结构之上的操作。一旦这些操作需要修改的话,接受这个操作的数据结构则可以保存不变。访问者模式适用于数据结构相对稳定的系统, 它把数据结构和作用于数据结构之上的操作之间的耦合度降低,使得操作集合可以相对自由地改变。
数据结构的每一个节点都可以接受一个访问者的调用,此节点向访问者对象传入节点对象,而访问者对象则反过来执行节点对象的操作。这样的过程叫做“双重分派”。节点调用访问者,将它自己传入,访问者则将某算法针对此节点执行。
2.2 访问者模式的结构图
从上面描述可知,访问者模式是用来封装某种数据结构中的方法。具体封装过程是:每个元素接受一个访问者的调用,每个元素的Accept方法接受访问者对象作为参数传入,访问者对象则反过来调用元素对象的操作。具体的访问者模式结构图如下所示。

这里需要明确一点:访问者模式中具体访问者的数目和具体节点的数目没有任何关系。从访问者的结构图可以看出,访问者模式涉及以下几类角色。
- 抽象访问者角色(Vistor):声明一个活多个访问操作,使得所有具体访问者必须实现的接口。
- 具体访问者角色(ConcreteVistor):实现抽象访问者角色中所有声明的接口。
- 抽象节点角色(Element):声明一个接受操作,接受一个访问者对象作为参数。
- 具体节点角色(ConcreteElement):实现抽象元素所规定的接受操作。
- 结构对象角色(ObjectStructure):节点的容器,可以包含多个不同类或接口的容器。
2.3 访问者模式的实现
在讲诉访问者模式的实现时,我想先不用访问者模式的方式来实现某个场景。具体场景是——现在我想遍历每个元素对象,然后调用每个元素对象的Print方法来打印该元素对象的信息。如果此时不采用访问者模式的话,实现这个场景再简单不过了,具体实现代码如下所示:

1 namespace DonotUsevistorPattern
2 {
3 // 抽象元素角色
4 public abstract class Element
5 {
6 public abstract void Print();
7 }
8
9 // 具体元素A
10 public class ElementA : Element
11 {
12 public override void Print()
13 {
14 Console.WriteLine("我是元素A");
15 }
16 }
17
18 // 具体元素B
19 public class ElementB : Element
20 {
21 public override void Print()
22 {
23 Console.WriteLine("我是元素B");
24 }
25 }
26
27 // 对象结构
28 public class ObjectStructure
29 {
30 private ArrayList elements = new ArrayList();
31
32 public ArrayList Elements
33 {
34 get { return elements; }
35 }
36
37 public ObjectStructure()
38 {
39 Random ran = new Random();
40 for (int i = 0; i < 6; i++)
41 {
42 int ranNum = ran.Next(10);
43 if (ranNum > 5)
44 {
45 elements.Add(new ElementA());
46 }
47 else
48 {
49 elements.Add(new ElementB());
50 }
51 }
52 }
53 }
54
55 class Program
56 {
57 static void Main(string[] args)
58 {
59 ObjectStructure objectStructure = new ObjectStructure();
60 // 遍历对象结构中的对象集合,访问每个元素的Print方法打印元素信息
61 foreach (Element e in objectStructure.Elements)
62 {
63 e.Print();
64 }
65
66 Console.Read();
67 }
68 }
69 }
上面代码很准确了解决了我们刚才提出的场景,但是需求在时刻变化的,如果此时,我除了想打印元素的信息外,还想打印出元素被访问的时间,此时我们就不得不去修改每个元素的Print方法,再加入相对应的输入访问时间的输出信息。这样的设计显然不符合“开-闭”原则,即某个方法操作的改变,会使得必须去更改每个元素类。既然,这里变化的点是操作的改变,而每个元素的数据结构是不变的。所以此时就思考——能不能把操作于元素的操作和元素本身的数据结构分开呢?解开这两者的耦合度,这样如果是操作发现变化时,就不需要去更改元素本身了,但是如果是元素数据结构发现变化,例如,添加了某个字段,这样就不得不去修改元素类了。此时,我们可以使用访问者模式来解决这个问题,即把作用于具体元素的操作由访问者对象来调用。具体的实现代码如下所示:
1 namespace VistorPattern
2 {
3 // 抽象元素角色
4 public abstract class Element
5 {
6 public abstract void Accept(IVistor vistor);
7 public abstract void Print();
8 }
9
10 // 具体元素A
11 public class ElementA :Element
12 {
13 public override void Accept(IVistor vistor)
14 {
15 // 调用访问者visit方法
16 vistor.Visit(this);
17 }
18 public override void Print()
19 {
20 Console.WriteLine("我是元素A");
21 }
22 }
23
24 // 具体元素B
25 public class ElementB :Element
26 {
27 public override void Accept(IVistor vistor)
28 {
29 vistor.Visit(this);
30 }
31 public override void Print()
32 {
33 Console.WriteLine("我是元素B");
34 }
35 }
36
37 // 抽象访问者
38 public interface IVistor
39 {
40 void Visit(ElementA a);
41 void Visit(ElementB b);
42 }
43
44 // 具体访问者
45 public class ConcreteVistor :IVistor
46 {
47 // visit方法而是再去调用元素的Accept方法
48 public void Visit(ElementA a)
49 {
50 a.Print();
51 }
52 public void Visit(ElementB b)
53 {
54 b.Print();
55 }
56 }
57
58 // 对象结构
59 public class ObjectStructure
60 {
61 private ArrayList elements = new ArrayList();
62
63 public ArrayList Elements
64 {
65 get { return elements; }
66 }
67
68 public ObjectStructure()
69 {
70 Random ran = new Random();
71 for (int i = 0; i < 6; i++)
72 {
73 int ranNum = ran.Next(10);
74 if (ranNum > 5)
75 {
76 elements.Add(new ElementA());
77 }
78 else
79 {
80 elements.Add(new ElementB());
81 }
82 }
83 }
84 }
85
86 class Program
87 {
88 static void Main(string[] args)
89 {
90 ObjectStructure objectStructure = new ObjectStructure();
91 foreach (Element e in objectStructure.Elements)
92 {
93 // 每个元素接受访问者访问
94 e.Accept(new ConcreteVistor());
95 }
96
97 Console.Read();
98 }
99 }
100 }
从上面代码可知,使用访问者模式实现上面场景后,元素Print方法的访问封装到了访问者对象中了(我觉得可以把Print方法封装到具体访问者对象中。),此时客户端与元素的Print方法就隔离开了。此时,如果需要添加打印访问时间的需求时,此时只需要再添加一个具体的访问者类即可。此时就不需要去修改元素中的Print()方法了。
三、访问者模式的应用场景
每个设计模式都有其应当使用的情况,那让我们看看访问者模式具体应用场景。如果遇到以下场景,此时我们可以考虑使用访问者模式。
- 如果系统有比较稳定的数据结构,而又有易于变化的算法时,此时可以考虑使用访问者模式。因为访问者模式使得算法操作的添加比较容易。
- 如果一组类中,存在着相似的操作,为了避免出现大量重复的代码,可以考虑把重复的操作封装到访问者中。(当然也可以考虑使用抽象类了)
- 如果一个对象存在着一些与本身对象不相干,或关系比较弱的操作时,为了避免操作污染这个对象,则可以考虑把这些操作封装到访问者对象中。
四、访问者模式的优缺点
访问者模式具有以下优点:
- 访问者模式使得添加新的操作变得容易。如果一些操作依赖于一个复杂的结构对象的话,那么一般而言,添加新的操作会变得很复杂。而使用访问者模式,增加新的操作就意味着添加一个新的访问者类。因此,使得添加新的操作变得容易。
- 访问者模式使得有关的行为操作集中到一个访问者对象中,而不是分散到一个个的元素类中。这点类似与"中介者模式"。
- 访问者模式可以访问属于不同的等级结构的成员对象,而迭代只能访问属于同一个等级结构的成员对象。
访问者模式也有如下的缺点:
- 增加新的元素类变得困难。每增加一个新的元素意味着要在抽象访问者角色中增加一个新的抽象操作,并在每一个具体访问者类中添加相应的具体操作。
五、总结
访问者模式是用来封装一些施加于某种数据结构之上的操作。它使得可以在不改变元素本身的前提下增加作用于这些元素的新操作,访问者模式的目的是把操作从数据结构中分离出来。
C#设计模式总结
一、引言
经过这段时间对设计模式的学习,自己的感触还是很多的,因为我现在在写代码的时候,经常会想想这里能不能用什么设计模式来进行重构。所以,学完设计模式之后,感觉它会慢慢地影响到你写代码的思维方式。这里对设计模式做一个总结,一来可以对所有设计模式进行一个梳理,二来可以做一个索引来帮助大家收藏。
PS: 其实,很早之前我就看过所有的设计模式了,但是并没有写博客,但是不久就很快忘记了,也没有起到什么作用,这次以博客的形式总结出来,发现效果还是很明显的,因为通过这种总结的方式,我对它理解更深刻了,也记住的更牢靠了,也影响了自己平时实现功能的思维。所以,我鼓励大家可以通过做笔记的方式来把自己学到的东西进行梳理,这样相信可以理解更深,更好,我也会一直写下来,之后打算写WCF一系列文章。
其实WCF内容很早也看过了,并且博客园也有很多前辈写的很好,但是,我觉得我还是需要自己总结,因为只有这样,知识才是自己的,别人写的多好,你看了之后,其实还是别人了,所以鼓励大家几点(对于这几点,也是对自己的一个提醒):
- 要动手实战别人博客中的例子;
- 实现之后进行总结,可以写博客也可以自己记录云笔记等;
- 想想能不能进行扩展,进行举一反三。
系列导航:
C#设计模式(5)——建造者模式(Builder Pattern)
C#设计模式(6)——原型模式(Prototype Pattern)
C#设计模式(7)——适配器模式(Adapter Pattern)
C#设计模式(8)——桥接模式(Bridge Pattern)
C#设计模式(9)——装饰者模式(Decorator Pattern)
C#设计模式(10)——组合模式(Composite Pattern)
C#设计模式(11)——外观模式(Facade Pattern)
C#设计模式(12)——享元模式(Flyweight Pattern)
C#设计模式(13)——代理模式(Proxy Pattern)
C#设计模式(14)——模板方法模式(Template Method)
C#设计模式(15)——命令模式(Command Pattern)
C#设计模式(16)——迭代器模式(Iterator Pattern)
C#设计模式(17)——观察者模式(Observer Pattern)
C#设计模式(18)——中介者模式(Mediator Pattern)
C#设计模式(19)——状态者模式(State Pattern)
C#设计模式(20)——策略者模式(Stragety Pattern)
C#设计模式(22)——访问者模式(Vistor Pattern)
C#设计模式(23)——备忘录模式(Memento Pattern)
二、 设计原则
使用设计模式的根本原因是适应变化,提高代码复用率,使软件更具有可维护性和可扩展性。并且,在进行设计的时候,也需要遵循以下几个原则:单一职责原则、开放封闭原则、里氏代替原则、依赖倒置原则、接口隔离原则、合成复用原则和迪米特法则。下面就分别介绍了每种设计原则。
2.1 单一职责原则
就一个类而言,应该只有一个引起它变化的原因。如果一个类承担的职责过多,就等于把这些职责耦合在一起,一个职责的变化可能会影响到其他的职责,另外,把多个职责耦合在一起,也会影响复用性。
2.2 开闭原则(Open-Closed Principle)
开闭原则即OCP(Open-Closed Principle缩写)原则,该原则强调的是:一个软件实体(指的类、函数、模块等)应该对扩展开放,对修改关闭。即每次发生变化时,要通过添加新的代码来增强现有类型的行为,而不是修改原有的代码。
符合开闭原则的最好方式是提供一个固有的接口,然后让所有可能发生变化的类实现该接口,让固定的接口与相关对象进行交互。
2.3 里氏代替原则(Liskov Substitution Principle)
Liskov Substitution Principle,LSP(里氏代替原则)指的是子类必须替换掉它们的父类型。也就是说,在软件开发过程中,子类替换父类后,程序的行为是一样的。只有当子类替换掉父类后,此时软件的功能不受影响时,父类才能真正地被复用,而子类也可以在父类的基础上添加新的行为。为了就来看看违反了LSP原则的例子,具体代码如下所示:
public class Rectangle
{
public virtual long Width { get; set; }
public virtual long Height { get; set; }
}
// 正方形
public class Square : Rectangle
{
public override long Height
{
get
{
return base.Height;
}
set
{
base.Height = value;
base.Width = value;
}
}
public override long Width
{
get
{
return base.Width;
}
set
{
base.Width = value;
base.Height = value;
}
}
}
class Test
{
public void Resize(Rectangle r)
{
while (r.Height >= r.Width)
{
r.Width += 1;
}
}
var r = new Square() { Width = 10, Height = 10 };
new Test().Resize(r);
}
上面的设计,正如上面注释的一样,在执行SmartTest的resize方法时,如果传入的是长方形对象,当高度大于宽度时,会自动增加宽度直到超出高度。但是如果传入的是正方形对象,则会陷入死循环。此时根本原因是,矩形不能作为正方形的父类,既然出现了问题,可以进行重构,使它们俩都继承于四边形类。重构后的代码如下所示:
// 四边形
public abstract class Quadrangle
{
public virtual long Width { get; set; }
public virtual long Height { get; set; }
}
// 矩形
public class Rectangle : Quadrangle
{
public override long Height { get; set; }
public override long Width { get; set; }
}
// 正方形
public class Square : Quadrangle
{
public long _side;
public Square(long side)
{
_side = side;
}
}
class Test
{
public void Resize(Quadrangle r)
{
while (r.Height >= r.Width)
{
r.Width += 1;
}
}
static void Main(string[] args)
{
var s = new Square(10);
new Test().Resize(s);
}
}
2.4 依赖倒置原则
依赖倒置(Dependence Inversion Principle, DIP)原则指的是抽象不应该依赖于细节,细节应该依赖于抽象,也就是提出的 “面向接口编程,而不是面向实现编程”。这样可以降低客户与具体实现的耦合。
2.5 接口隔离原则
接口隔离原则(Interface Segregation Principle, ISP)指的是使用多个专门的接口比使用单一的总接口要好。也就是说不要让一个单一的接口承担过多的职责,而应把每个职责分离到多个专门的接口中,进行接口分离。过于臃肿的接口是对接口的一种污染。
2.6 合成复用原则
合成复用原则(Composite Reuse Principle, CRP)就是在一个新的对象里面使用一些已有的对象,使之成为新对象的一部分。新对象通过向这些对象的委派达到复用已用功能的目的。简单地说,就是要尽量使用合成/聚合,尽量不要使用继承。
要使用好合成复用原则,首先需要区分"Has—A"和“Is—A”的关系。
“Is—A”是指一个类是另一个类的“一种”,是属于的关系,而“Has—A”则不同,它表示某一个角色具有某一项责任。导致错误的使用继承而不是聚合的常见的原因是错误地把“Has—A”当成“Is—A”.例如:

实际上,雇员、经历、学生描述的是一种角色,比如一个人是“经理”必然是“雇员”。在上面的设计中,一个人无法同时拥有多个角色,是“雇员”就不能再是“学生”了,这显然不合理,因为现在很多在职研究生,即使雇员也是学生。
上面的设计的错误源于把“角色”的等级结构与“人”的等级结构混淆起来了,误把“Has—A”当作"Is—A"。具体的解决方法就是抽象出一个角色类:

2.7 迪米特法则
迪米特法则(Law of Demeter,LoD)又叫最少知识原则(Least Knowledge Principle,LKP),指的是一个对象应当对其他对象有尽可能少的了解。也就是说,一个模块或对象应尽量少的与其他实体之间发生相互作用,使得系统功能模块相对独立,这样当一个模块修改时,影响的模块就会越少,扩展起来更加容易。
关于迪米特法则其他的一些表述有:只与你直接的朋友们通信;不要跟“陌生人”说话。
外观模式(Facade Pattern)和中介者模式(Mediator Pattern)就使用了迪米特法则。
三、创建型模式
创建型模式就是用来创建对象的模式,抽象了实例化的过程。所有的创建型模式都有两个共同点。第一,它们都将系统使用哪些具体类的信息封装起来;第二,它们隐藏了这些类的实例是如何被创建和组织的。创建型模式包括单例模式、工厂方法模式、抽象工厂模式、建造者模式和原型模式。
- 单例模式:解决的是实例化对象的个数的问题,比如抽象工厂中的工厂、对象池等,除了Singleton之外,其他创建型模式解决的都是 new 所带来的耦合关系。
- 抽象工厂:创建一系列相互依赖对象,并能在运行时改变系列。
- 工厂方法:创建单个对象,在Abstract Factory有使用到。
- 原型模式:通过拷贝原型来创建新的对象。
工厂方法,抽象工厂, 建造者都需要一个额外的工厂类来负责实例化“一个对象”,而Prototype则是通过原型(一个特殊的工厂类)来克隆“易变对象”。
下面详细介绍下它们。
3.1 单例模式
单例模式指的是确保某一个类只有一个实例,并提供一个全局访问点。解决的是实体对象个数的问题,而其他的建造者模式都是解决new所带来的耦合关系问题。其实现要点有:
- 类只有一个实例。问:如何保证呢?答:通过私有构造函数来保证类外部不能对类进行实例化
- 提供一个全局的访问点。问:如何实现呢?答:创建一个返回该类对象的静态方法
单例模式的结构图如下所示:

3.2 工厂方法模式
工厂方法模式指的是定义一个创建对象的工厂接口,由其子类决定要实例化的类,将实际创建工作推迟到子类中。它强调的是”单个对象“的变化。其实现要点有:
- 定义一个工厂接口。问:如何实现呢?答:声明一个工厂抽象类
- 由其具体子类创建对象。问:如何去实现呢?答:创建派生于工厂抽象类,即由具体工厂去创建具体产品,既然要创建产品,自然需要产品抽象类和具体产品类了。
其具体的UML结构图如下所示:

在工厂方法模式中,工厂类与具体产品类具有平行的等级结构,它们之间是一一对应关系。
3.3 抽象工厂模式
抽象工厂模式指的是提供一个创建一系列相关或相互依赖对象的接口,使得客户端可以在不必指定产品的具体类型的情况下,创建多个产品族中的产品对象,强调的是”系列对象“的变化。其实现要点有:
- 提供一系列对象的接口。问:如何去实现呢?答:提供多个产品的抽象接口
- 创建多个产品族中的多个产品对象。问:如何做到呢?答:每个具体工厂创建一个产品族中的多个产品对象,多个具体工厂就可以创建多个产品族中的多个对象了。
具体的UML结构图如下所示:

3.4 建造者模式
建造者模式指的是将一个产品的内部表示与产品的构造过程分割开来,从而可以使一个建造过程生成具体不同的内部表示的产品对象。强调的是产品的构造过程。其实现要点有:
- 将产品的内部表示与产品的构造过程分割开来。问:如何把它们分割开呢?答:不要把产品的构造过程放在产品类中,而是由建造者类来负责构造过程,产品的内部表示放在产品类中,这样不就分割开了嘛。
具体的UML结构图如下所示:

3.5 原型工厂模式
原型模式指的是通过给出一个原型对象来指明所要创建的对象类型,然后用复制的方法来创建出更多的同类型对象。其实现要点有:
- 给出一个原型对象。问:如何办到呢?答:很简单嘛,直接给出一个原型类就好了。
- 通过复制的方法来创建同类型对象。问:又是如何实现呢?答:.NET可以直接调用MemberwiseClone方法来实现浅拷贝
具体的UML结构图如下所示:

四、结构型模式
结构型模式,顾名思义讨论的是类和对象的结构 ,主要用来处理类或对象的组合。它包括两种类型,一是类结构型模式,指的是采用继承机制来组合接口或实现;二是对象结构型模式,指的是通过组合对象的方式来实现新的功能。它包括适配器模式、桥接模式、装饰者模式、组合模式、外观模式、享元模式和代理模式。
- 适配器模式注重转换接口,将不吻合的接口适配对接
- 桥接模式注重分离接口与其实现,支持多维度变化
- 组合模式注重统一接口,将“一对多”的关系转化为“一对一”的关系
- 装饰者模式注重稳定接口,在此前提下为对象扩展功能
- 外观模式注重简化接口,简化组件系统与外部客户程序的依赖关系
- 享元模式注重保留接口,在内部使用共享技术对对象存储进行优化
- 代理模式注重假借接口,增加间接层来实现灵活控制
4.1 适配器模式
适配器模式意在转换接口,它能够使原本不能再一起工作的两个类一起工作,所以经常用来在类库的复用、代码迁移等方面。例如DataAdapter类就应用了适配器模式。适配器模式包括类适配器模式和对象适配器模式,具体结构如下图所示,左边是类适配器模式,右边是对象适配器模式。

4.2 桥接模式
桥接模式旨在将抽象化与实现化解耦,使得两者可以独立地变化。意思就是说,桥接模式把原来基类的实现化细节再进一步进行抽象,构造到一个实现化的结构中,然后再把原来的基类改造成一个抽象化的等级结构,这样就可以实现系统在多个维度的独立变化,桥接模式的结构图如下所示。

4.3 装饰者模式
装饰者模式又称包装(Wrapper)模式,它可以动态地给一个对象添加一些额外的功能,装饰者模式较继承生成子类的方式更加灵活。虽然装饰者模式能够动态地将职责附加到对象上,但它也会造成产生一些细小的对象,增加了系统的复杂度。具体的结构图如下所示。

4.4 组合模式
组合模式又称为部分—整体模式。组合模式将对象组合成树形结构,用来表示整体与部分的关系。组合模式使得客户端将单个对象和组合对象同等对待。如在.NET中WinForm中的控件,TextBox、Label等简单控件继承与Control类,同时GroupBox这样的组合控件也是继承于Control类。组合模式的具体结构图如下所示。

4.5 外观模式
在系统中,客户端经常需要与多个子系统进行交互,这样导致客户端会随着子系统的变化而变化,此时可以使用外观模式把客户端与各个子系统解耦。外观模式指的是为子系统中的一组接口提供一个一致的门面,它提供了一个高层接口,这个接口使子系统更加容易使用。如电信的客户专员,你可以让客户专员来完成冲话费,修改套餐等业务,而不需要自己去与各个子系统进行交互。具体类结构图如下所示:

4.6 享元模式
在系统中,如何我们需要重复使用某个对象时,此时如果重复地使用new操作符来创建这个对象的话,这对系统资源是一个极大的浪费,既然每次使用的都是同一个对象,为什么不能对其共享呢?这也是享元模式出现的原因。
享元模式运用共享的技术有效地支持细粒度的对象,使其进行共享。在.NET类库中,String类的实现就使用了享元模式,String类采用字符串驻留池的来使字符串进行共享。更多内容参考博文:http://www.cnblogs.com/artech/archive/2010/11/25/internedstring.html。享元模式的具体结构图如下所示。

4.7 代理模式
在系统开发中,有些对象由于网络或其他的障碍,以至于不能直接对其访问,此时可以通过一个代理对象来实现对目标对象的访问。如.NET中的调用Web服务等操作。
代理模式指的是给某一个对象提供一个代理,并由代理对象控制对原对象的访问。具体的结构图如下所示。

注:外观模式、适配器模式和代理模式区别?
解答:这三个模式的相同之处是,它们都是作为客户端与真实被使用的类或系统之间的一个中间层,起到让客户端间接调用真实类的作用,不同之处在于,所应用的场合和意图不同。
代理模式与外观模式主要区别在于,代理对象无法直接访问对象,只能由代理对象提供访问,而外观对象提供对各个子系统简化访问调用接口,而适配器模式则不需要虚构一个代理者,目的是复用原有的接口。外观模式是定义新的接口,而适配器则是复用一个原有的接口。
另外,它们应用设计的不同阶段,外观模式用于设计的前期,因为系统需要前期就需要依赖于外观,而适配器应用于设计完成之后,当发现设计完成的类无法协同工作时,可以采用适配器模式。然而很多情况下在设计初期就要考虑适配器模式的使用,如涉及到大量第三方应用接口的情况;代理模式是模式完成后,想以服务的方式提供给其他客户端进行调用,此时其他客户端可以使用代理模式来对模块进行访问。
总之,代理模式提供与真实类一致的接口,旨在用来代理类来访问真实的类,外观模式旨在简化接口,适配器模式旨在转换接口。
五、行为型模式
行为型模式是对在不同对象之间划分责任和算法的抽象化。行为模式不仅仅关于类和对象,还关于它们之间的相互作用。行为型模式又分为类的行为模式和对象的行为模式两种。
- 类的行为模式——使用继承关系在几个类之间分配行为。
- 对象的行为模式——使用对象聚合的方式来分配行为。
行为型模式包括11种模式:模板方法模式、命令模式、迭代器模式、观察者模式、中介者模式、状态模式、策略模式、责任链模式、访问者模式、解释器模式和备忘录模式。
- 模板方法模式:封装算法结构,定义算法骨架,支持算法子步骤变化。
- 命令模式:注重将请求封装为对象,支持请求的变化,通过将一组行为抽象为对象,实现行为请求者和行为实现者之间的解耦。
- 迭代器模式:注重封装特定领域变化,支持集合的变化,屏蔽集合对象内部复杂结构,提供客户程序对它的透明遍历。
- 观察者模式:注重封装对象通知,支持通信对象的变化,实现对象状态改变,通知依赖它的对象并更新。
- 中介者模式:注重封装对象间的交互,通过封装一系列对象之间的复杂交互,使他们不需要显式相互引用,实现解耦。
- 状态模式:注重封装与状态相关的行为,支持状态的变化,通过封装对象状态,从而在其内部状态改变时改变它的行为。
- 策略模式:注重封装算法,支持算法的变化,通过封装一系列算法,从而可以随时独立于客户替换算法。
- 责任链模式:注重封装对象责任,支持责任的变化,通过动态构建职责链,实现事务处理。
- 访问者模式:注重封装对象操作变化,支持在运行时为类结构添加新的操作,在类层次结构中,在不改变各类的前提下定义作用于这些类实例的新的操作。
- 备忘录模式:注重封装对象状态变化,支持状态保存、恢复。
- 解释器模式:注重封装特定领域变化,支持领域问题的频繁变化,将特定领域的问题表达为某种语法规则下的句子,然后构建一个解释器来解释这样的句子,从而达到解决问题的目的。
5.1 模板方法模式
在现实生活中,有论文模板,简历模板等。在现实生活中,模板的概念是给定一定的格式,然后其他所有使用模板的人可以根据自己的需求去实现它。同样,模板方法也是这样的。
模板方法模式是在一个抽象类中定义一个操作中的算法骨架,而将一些具体步骤实现延迟到子类中去实现。模板方法使得子类可以不改变算法结构的前提下,重新定义算法的特定步骤,从而达到复用代码的效果。具体的结构图如下所示。

以生活中做菜为例子实现的模板方法结构图
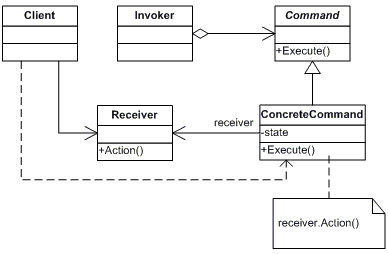
5.2 命令模式
命令模式属于对象的行为模式,命令模式把一个请求或操作封装到一个对象中,通过对命令的抽象化来使得发出命令的责任和执行命令的责任分隔开。命令模式的实现可以提供命令的撤销和恢复功能。具体的结构图如下所示。
5.3 迭代器模式
迭代器模式是针对集合对象而生的,对于集合对象而言,必然涉及到集合元素的添加删除操作,也肯定支持遍历集合元素的操作,此时如果把遍历操作也放在集合对象的话,集合对象就承担太多的责任了,此时可以进行责任分离,把集合的遍历放在另一个对象中,这个对象就是迭代器对象。
迭代器模式提供了一种方法来顺序访问一个集合对象中各个元素,而又无需暴露该对象的内部表示,这样既可以做到不暴露集合的内部结构,又可以让外部代码透明地访问集合内部元素。具体的结构图如下所示。

5.4 观察者模式
在现实生活中,处处可见观察者模式,例如,微信中的订阅号,订阅博客和QQ微博中关注好友,这些都属于观察者模式的应用。
观察者模式定义了一种一对多的依赖关系,让多个观察者对象同时监听某一个主题对象,这个主题对象在状态发生变化时,会通知所有观察者对象,使它们能够自动更新自己的行为。具体结构图如下所示:

5.5 中介者模式
在现实生活中,有很多中介者模式的身影,例如QQ游戏平台,聊天室、QQ群和短信平台,这些都是中介者模式在现实生活中的应用。
中介者模式,定义了一个中介对象来封装一系列对象之间的交互关系。中介者使各个对象之间不需要显式地相互引用,从而使耦合性降低,而且可以独立地改变它们之间的交互行为。具体的结构图如下所示:

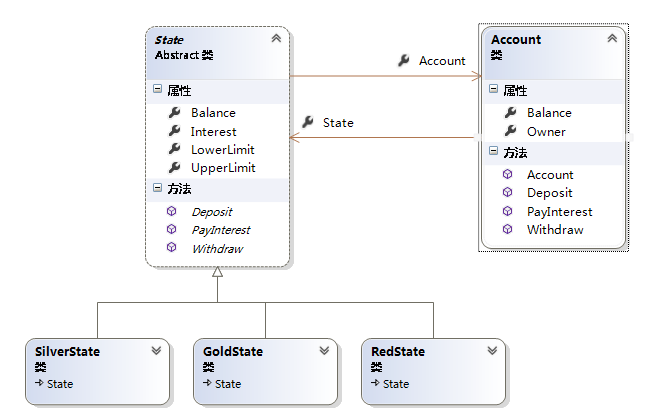
5.6 状态模式
每个对象都有其对应的状态,而每个状态又对应一些相应的行为,如果某个对象有多个状态时,那么就会对应很多的行为。那么对这些状态的判断和根据状态完成的行为,就会导致多重条件语句,并且如果添加一种新的状态时,需要更改之前现有的代码。这样的设计显然违背了开闭原则,状态模式正是用来解决这样的问题的。
状态模式——允许一个对象在其内部状态改变时自动改变其行为,对象看起来就像是改变了它的类。具体的结构图如下所示:
5.7 策略模式
在现实生活中,中国的所得税,分为企业所得税、外商投资企业或外商企业所得税和个人所得税,针对于这3种所得税,每种所计算的方式不同,个人所得税有个人所得税的计算方式,而企业所得税有其对应计算方式。如果不采用策略模式来实现这样一个需求的话,我们会定义一个所得税类,该类有一个属性来标识所得税的类型,并且有一个计算税收的CalculateTax()方法,在该方法体内需要对税收类型进行判断,通过if-else语句来针对不同的税收类型来计算其所得税。这样的实现确实可以解决这个场景,但是这样的设计不利于扩展,如果系统后期需要增加一种所得税时,此时不得不回去修改CalculateTax方法来多添加一个判断语句,这样明白违背了“开放——封闭”原则。此时,我们可以考虑使用策略模式来解决这个问题,既然税收方法是这个场景中的变化部分,此时自然可以想到对税收方法进行抽象,这也是策略模式实现的精髓所在。
策略模式是对算法的包装,是把使用算法的责任和算法本身分割开,委派给不同的对象负责。策略模式通常把一系列的算法包装到一系列的策略类里面。用一句话慨括策略模式就是——“将每个算法封装到不同的策略类中,使得它们可以互换”。下面是策略模式的结构图:

5.8 责任链模式
在现实生活中,有很多请求并不是一个人说了就算的,例如面试时的工资,低于1万的薪水可能技术经理就可以决定了,但是1万~1万5的薪水可能技术经理就没这个权利批准,可能需要请求技术总监的批准。
责任链模式——某个请求需要多个对象进行处理,从而避免请求的发送者和接收之间的耦合关系。将这些对象连成一条链子,并沿着这条链子传递该请求,直到有对象处理它为止。具体结构图如下所示:

5.9 访问者模式
访问者模式是封装一些施加于某种数据结构之上的操作。一旦这些操作需要修改的话,接受这个操作的数据结构则可以保存不变。访问者模式适用于数据结构相对稳定的系统, 它把数据结构和作用于数据结构之上的操作之间的耦合度降低,使得操作集合可以相对自由地改变。具体结构图如下所示:
5.10 备忘录模式
生活中的手机通讯录备忘录,操作系统备份点,数据库备份等都是备忘录模式的应用。备忘录模式是在不破坏封装的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态,这样以后就可以把该对象恢复到原先的状态。具体的结构图如下所示:

5.11 解释器模式
解释器模式是一个比较少用的模式,所以我自己也没有对该模式进行深入研究,在生活中,英汉词典的作用就是实现英文和中文互译,这就是解释器模式的应用。
解释器模式是给定一种语言,定义它文法的一种表示,并定义一种解释器,这个解释器使用该表示来解释器语言中的句子。具体的结构图如下所示:

六、总结
23种设计模式,其实前辈们总结出来解决问题的方式,它们追求的宗旨还是保证系统的低耦合高内聚,指导它们的原则无非就是封装变化,责任单一,面向接口编程等设计原则。之后,我会继续分享自己WCF的学习过程,尽管博客园中有很多WCF系列,之前觉得没必要写,觉得会用就行了,但是不写,总感觉知识不是自己的,感觉没有深入,所以还是想写这样一个系列,希望各位博友后面多多支持。
PS: 很多论坛都看到初学者问,WCF现在还有没有必要深入学之类的问题,因为他们觉得这些技术可能会过时,说不定到时候微软又推出了一个新的SOA的实现方案了,那岂不是白花时间深入学了,所以就觉得没必要深入去学,知道用就可以了。对于这个问题,我之前也有这样同样的感觉,但是现在我觉得,尽管WCF技术可能会被替换,但深入了解一门技术,重点不是知道一些更高深API的调用啊,而是了解它的实现机制和思维方式,即使后面这个技术被替代了,其背后机制也肯定是相似的。所以深入了解了一个技术,你就会感觉新的技术熟悉,对其感觉放松。并且,你深入了解完一门技术之后,你面试时也敢说你很好掌握了这门技术,而不至于说平时使用的很多,一旦深入问时却不知道背后实现原理。这也是我要写WCF系列的原因。希望这点意见对一些初学者有帮助。
.NET Core launch.json 简介
1.环境 Windows,.NET Core 2.0,VS Code
dotnet> dotnet new console -o myApp
2.launch.json配置文件
{
// Use IntelliSense to find out which attributes exist for C# debugging
// Use hover for the description of the existing attributes
// For further information visit https://github.com/OmniSharp/omnisharp-vscode/blob/master/debugger-launchjson.md
"version": "0.2.0",
"configurations": [
{
"name": ".NET Core Launch (console)",
"type": "coreclr",
"request": "launch",
"preLaunchTask": "build",
// If you have changed target frameworks, make sure to update the program path.
"program": "${workspaceFolder}/myApp/bin/Debug/netcoreapp2.0/myApp.dll",
"args": [],
"cwd": "${workspaceFolder}/myApp",
// For more information about the 'console' field, see https://github.com/OmniSharp/omnisharp-vscode/blob/master/debugger-launchjson.md#console-terminal-window
"console": "internalConsole",
"stopAtEntry": false,
"internalConsoleOptions": "openOnSessionStart"
},
{
"name": ".NET Core Attach",
"type": "coreclr",
"request": "attach",
"processId": "${command:pickProcess}"
}
,]
}
在launch.json中
利用Bootstrap Paginator插件和knockout.js完成分页功能
在最近一个项目中,需要结合一堆条件查询并对查询的结果数据完成一个简单分页功能,可是做着做着,自己的思路越来越模糊,做到心态崩溃!!! 哈哈
特此花点时间重新总结,并从最简单的分页,然后向多条件查询分页慢慢过渡,或许有人觉得这个很简单(可以绕道啦,哈哈),却是对基础知识的一次学习过程。
Demo地址:https://gitee.com/530521314/Pagination.git
本文地址:https://www.cnblogs.com/CKExp/p/9218904.html
一、环境介绍
分页功能很多已有的很完美的插件或是第三方应用包都能够完美实现,我在此利用了一些前端插件来完成分页功能。
前端的Bootstrap Paginator插件完成前端分页数字之类的切换展示;
利用knockout.js插件完成分页数据的绑定;
在后端,利用asp.net core mvc 完成分页信息的接收和处理工作。
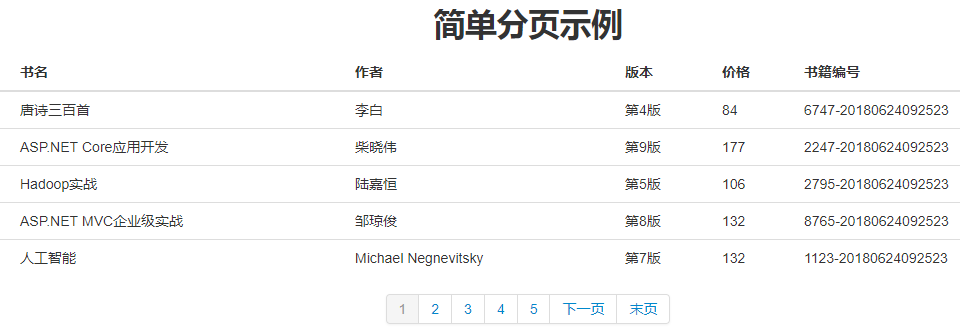
二、简单分页
完成对已有数据的分页功能,不带条件查询。
首先,一上来便是完成数据绑定工作:
1 bookList: ko.mapping.fromJS(@Html.Raw(Newtonsoft.Json.JsonConvert.SerializeObject(Model))),//展示数据 2 pageEntity: ko.mapping.fromJS(@Html.Raw(Newtonsoft.Json.JsonConvert.SerializeObject(new PageRequestViewModel()))),//分页信息
页面刚展示的时候得有分页数据吧,可以在当页面展示的时候,数据也带过来了,也可以页面展示后,再通过ajax去后台调用,我选择后者。
在页面启动时,调用该函数完成初始化页面数据。
1 getBookData: function () {
2 var pageEntity = ko.mapping.toJS(viewModel.pageEntity);
3 $.ajax({
4 url: '@Url.Action("SampleGetData")',
5 type: 'POST',
6 dataType: 'json',
7 data: pageEntity,
8 success: function (result) {
9 ko.mapping.fromJS(result.data, viewModel.bookList);
10 options.totalPages = result.totalCount > 0 ? result.totalCount % options.numberOfPages == 0 ?
11 result.totalCount / options.numberOfPages : (result.totalCount / options.numberOfPages) + 1 : 1;
12 $('#pagination').bootstrapPaginator(options);
13 }
14 });
15 }
分页信息(当前页面,页面展示数据条数)带过去,后台根据分页信息完成数据查询,并获得总的记录条数用于前端页面计算总页数。
1 [HttpPost]
2 public IActionResult SampleGetData(PageRequestViewModel pageEntity)
3 {
4 var bookList = PageDataSeed.GetPageDataList()
5 .Skip((pageEntity.PageIndex - 1) * pageEntity.PageSize)
6 .Take(pageEntity.PageSize);
7
8 var pageResultViewModel = new PageResultViewModel<Book>()
9 {
10 PageIndex = pageEntity.PageIndex,
11 PageSize = pageEntity.PageSize,
12 TotalCount = PageDataSeed.GetPageDataList().Count(),
13 Data = bookList
14 };
15
16 return Json(pageResultViewModel);
17 }
根据分页信息查询也就搞定了,当点击底部的页面码的时候得改变当前分页信息,然后要切换当前分页信息所对应的数据出来,在Bootstrap paginator插件中,点击页面码有一个函数onPageClicked,点击具体的某一页后,根据参数page获得页面,改变当前展示的页面码数字,并对分页信息修改,然后再次调用ajax获得新数据。
1 onPageClicked: function (event, originalEvent, type, page) {
2 options.currentPage = page;
3 viewModel.pageEntity.PageIndex = page;
4 viewModel.getBookData();
5 },
至此,简单分页功能便搞定了,在此实现中,偏重于前端实现分页逻辑,后台只是取得相应的数据。
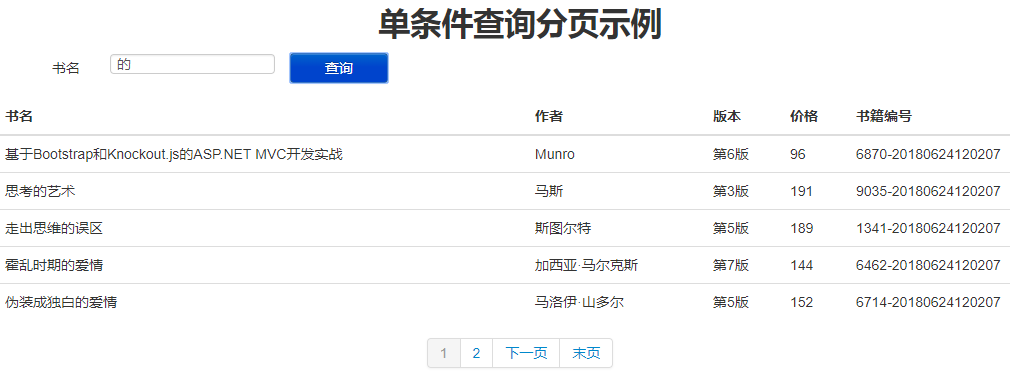
三、单条件查询分页
复制一份简单分页后,改造下加入一个根据书名条件项,查询后完成分页功能。
首先加入书名绑定,在此用了两个书名,第二个是有目的性的留着,也只是我的理解,条件查询后,如果底部展示有多页,那么我在点击每一页的时候,我的查询条件不能动吧,基于此考虑的。
1 bookName: ko.observable(), 2 bookNameBackup: ko.observable(),
数据查询部分改动不大,主要是把查询条件加入进来,因此只改动data参数即可。
1 getBookData: function () {
2 var pageEntity = ko.mapping.toJS(viewModel.pageEntity);
3 $.ajax({
4 url: '@Url.Action("SingleQueryGetData")',
5 type: 'POST',
6 dataType: 'json',
7 data: {"pageEntity":pageEntity, "bookName":viewModel.bookName()},
8 success: function (result) {
9 ko.mapping.fromJS(result.data, viewModel.bookList);
10 options.totalPages = result.totalCount > 0 ? result.totalCount % options.numberOfPages == 0 ?
11 result.totalCount / options.numberOfPages : (result.totalCount / options.numberOfPages) + 1 : 1;
12 $('#pagination').bootstrapPaginator(options);
13 }
14 });
15 },
前端Html部分加入单条件项,以书名为例,查询按钮绑定点击后的触发函数
1 <div class="form-group"> 2 <label for="bookName" class="col-sm-2 control-label">书名</label> 3 <div class="col-sm-2"> 4 <input type="text" class="form-control" id="bookName" data-bind="value:bookName"> 5 </div> 6 <button class="btn btn-primary col-sm-1" data-bind="click:queryBookList">查询</button> 7 </div>
点击查询后执行函数,将当前页面重置为1,查询数据,并记录该次查询的查询条件。
1 //查询
2 queryBookList: function () {
3 options.currentPage = 1;
4 viewModel.pageEntity.PageIndex = options.currentPage;
5 viewModel.getBookData();
6 viewModel.bookNameBackup(viewModel.bookName());//记录查询条件,分页点击时需要用到
7 }
查询完毕,然后假设底部还存在很多页面码可以选择,当我们点击页面码的时候,因为查询条件仍然存在,我们点击后仍然会完成分页功能,但是!!!
当把查询条件清空,比如在此demo中,把书名置空,此时不点查询按钮,而是直接点击页面码,那情况会如何呢,查询条件已经没了;
或是说查询条件为空时,输入查询条件,不点查询按钮,直接点击页面码;
这都是不合理的情形,点击页面码的时候肯定得保证原查询条件的存在,至少我是这么想的,或许您有更好的建议,请告诉我,十分感谢。这也就是我在之前设置了一个监控对象bookNameBackup的原因,备份查询条件,防止点击页码切换时查询条件变更的情形。
前端已经改好了,然后进入后端来改一下,先对条件判空处理,然后执行相应的逻辑。
1 [HttpPost]
2 public IActionResult SingleQueryGetData(PageRequestViewModel pageEntity, string bookName)
3 {
4 IEnumerable<Book> bookList = PageDataSeed.GetPageDataList();
5 PageResultViewModel<Book> pageResultViewModel = null;
6
7 if (!string.IsNullOrEmpty(bookName))
8 bookList = bookList.Where(b => b.BookName.Contains(bookName));
9
10 var books = bookList.Skip((pageEntity.PageIndex - 1) * pageEntity.PageSize)
11 .Take(pageEntity.PageSize);
12
13 pageResultViewModel = new PageResultViewModel<Book>()
14 {
15 PageIndex = pageEntity.PageIndex,
16 PageSize = pageEntity.PageSize,
17 TotalCount = bookList.Count(),
18 Data = books
19 };
20
21 return Json(pageResultViewModel);
22 }
单条件查询分页功能也就搞定了,查询和点击页面码所执行的逻辑是不一样的,虽然都调用到了最终的数据查询方法,但是对于条件的处理是不一样的。
四、多条件查询分页
对单条件查询分页下多加入几个条件,进入到多条件查询,变化其实不大,只是为了方便管理如此多的查询条件,改成了以对象形式管理
首先绑定查询对象信息,该对象中包括了三个查询条件,书名,作者,出版社,仍然设置一个备份对象,原因和单条件查询下是一样的。
1 queryItemEntity: ko.mapping.fromJS(@Html.Raw(Newtonsoft.Json.JsonConvert.SerializeObject(new QueryItemViewModel()))),//查询条件信息 2 queryItemEntityBackup: ko.mapping.fromJS(@Html.Raw(Newtonsoft.Json.JsonConvert.SerializeObject(new QueryItemViewModel()))),//查询条件信息备份
页面的查询条件多了,通过queryItemEntity为前缀展示,也方便维护
1 <div id="queryItem" class="form-horizontal"> 2 <div class="form-group"> 3 <label for="bookName" class="col-sm-2 control-label">书名</label> 4 <div class="col-sm-2"> 5 <input type="text" class="form-control" id="bookName" data-bind="value:queryItemEntity.BookName"> 6 </div> 7 <label for="author" class="col-sm-2 control-label">作者</label> 8 <div class="col-sm-2"> 9 <input type="text" class="form-control" id="author" data-bind="value:queryItemEntity.Author"> 10 </div> 11 <label for="press" class="col-sm-2 control-label">出版社</label> 12 <div class="col-sm-2"> 13 <input type="text" class="form-control" id="press" data-bind="value:queryItemEntity.Press"> 14 </div> 15 </div> 16 <button class="btn btn-primary" data-bind="click:queryBookList">查询</button> 17 </div>
查询条件改动,也使得数据查询部分的条件改变了,将查询条件整体封装,而不是零散的传递,改动之处加入了第三行将ko上的查询条件信息转换为JS对象和改变了参数data的值。
1 getBookData: function () {
2 var pageEntity = ko.mapping.toJS(viewModel.pageEntity);
3 var queryItemEntity = ko.mapping.toJS(viewModel.queryItemEntity);
4
5 $.ajax({
6 url: '@Url.Action("MultipleQueryGetData")',
7 type: 'POST',
8 dataType: 'json',
9 data: { "pageEntity": pageEntity, "queryItemEntity": queryItemEntity},
10 success: function (result) {
11 ko.mapping.fromJS(result.data, viewModel.bookList);
12 options.totalPages = result.totalCount > 0 ? result.totalCount % options.numberOfPages == 0 ?
13 result.totalCount / options.numberOfPages : (result.totalCount / options.numberOfPages) + 1 : 1;
14 $('#pagination').bootstrapPaginator(options);
15 }
16 });
17 },
点击按钮查询处的逻辑还是没有改变,仍然是查询记录并将查询条件备份,用于分页控件中页面码的点击函数。
1 //查询
2 queryBookList: function () {
3 options.currentPage = 1;
4 viewModel.pageEntity.PageIndex = options.currentPage;
5 viewModel.getBookData();
6 ko.mapping.fromJS(viewModel.queryItemEntity, viewModel.queryItemEntityBackup);//记录查询条件,分页点击时需要用到
7 }
对于前端来讲改动并不是很大,无非是将查询条件封装一下,同样后端的改动只是多个查询条件的过滤,依次比对三个查询条件是否为空,并挨个去完成查询的过滤。
1 [HttpPost]
2 public IActionResult MultipleQueryGetData(PageRequestViewModel pageEntity, QueryItemViewModel queryItemEntity)
3 {
4 var bookList = PageDataSeed.GetPageDataList();
5
6 #region 条件过滤
7 if (!string.IsNullOrEmpty(queryItemEntity.BookName))
8 bookList = bookList.Where(b => b.BookName.Contains(queryItemEntity.BookName)).ToList();
9 if (!string.IsNullOrEmpty(queryItemEntity.Author))
10 bookList = bookList.Where(b => b.Author.Contains(queryItemEntity.Author)).ToList();
11 if (!string.IsNullOrEmpty(queryItemEntity.Press))
12 bookList = bookList.Where(b => b.Press.Contains(queryItemEntity.Press)).ToList();
13 #endregion
14
15 var books = bookList.Skip((pageEntity.PageIndex - 1) * pageEntity.PageSize).Take(pageEntity.PageSize);
16
17 var pageResultViewModel = new PageResultViewModel<Book>()
18 {
19 PageIndex = pageEntity.PageIndex,
20 PageSize = pageEntity.PageSize,
21 TotalCount = bookList.Count(),
22 Data = books
23 };
24
25 return Json(pageResultViewModel);
26 }
多条件查询分页的效果展示
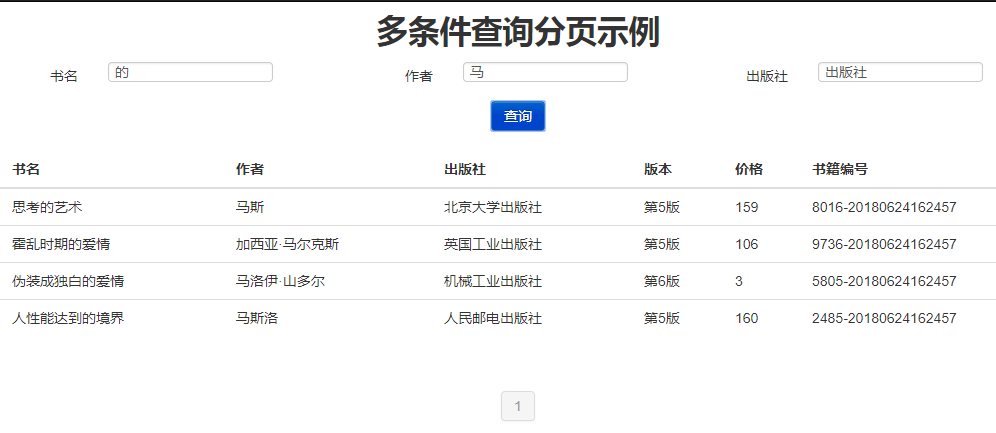
至此,查询功能算是简单完成了,或许还有漏洞地方,没有发现,特别是逻辑漏洞,防不胜防,望多指教,感谢。
设计一个小Demo一方面是对分页功能进行一下总结,以防自己若干天或是若干年后还需要,可以回来看看,一方面也是如果有需要的朋友可以加快编码和设计的过程。
码云上存放Demo的地址:https://gitee.com/530521314/Pagination.git
2018-6-24,望技术有成后能回来看见自己的脚步
图片在线裁剪和图片上传总结
上周需要做一个图片上传并且将上传的图片在线可以裁剪展示,觉得这个功能很有用,但是找参考资料的时候却并不是很多,因此来将我用到的总结总结,也让有需要的博友们直接借鉴。
首先环境介绍:
1、asp.net mvc网站,用到的前端插件是JCrop和Bootstrap-fileinput,在后端用框架自带的一些类库进行处理即可。
JCrop插件是用来裁剪图片的,页面上裁剪就是保存裁剪的位置信息,然后将位置信息转给后台在后台进行实际图片裁剪功能。
插件地址:http://code.ciaoca.com/jquery/jcrop/demo/
Bootstrap-fileinput插件是Bootstrap下的文件上传的插件,功能强大,我将依靠这个完成文件的上传,当然也能够使用其他的文件上传工具。
插件地址:http://plugins.krajee.com/file-input
文件上传后页面上展示的图片是以Data URI Scheme方式进行展示的。
Data URI Scheme知识点:https://blog.csdn.net/aoshilang2249/article/details/51009947
2、asp.net core mvc网站,前端插件不变,但是在后端不能够使用自带类库了,core下面的图片处理相关的类库还没有完全移植过来,只能够借用第三方类库SixLabors.ImageSharp。
快速浏览

@{
ViewBag.Title = "文件上传";
}
<link href="@Url.Content("~/Content/Jcrop/jquery.Jcrop.css")" rel="stylesheet" />
<link href="@Url.Content("~/Content/bootstrap-fileinput/fileinput.css")" rel="stylesheet" />
<br />
<button class="btn btn-primary" data-toggle="modal" data-target="#myModal">头像</button>
<div class="modal fade" id="myModal" tabindex="-1" role="dialog" aria-labelledby="myModalLabel" aria-hidden="true">
<div class="modal-dialog">
<div class="modal-content">
<div class="modal-header">
<button type="button" class="close" data-dismiss="modal" aria-hidden="true">×</button>
<h4 class="modal-title" id="myModalLabel">图片上传</h4>
</div>
<div class="modal-body">
<div class="row">
<div class="col-md-6" style="width: 300px;">
<img id="cut-img" class="thumbnail" style="width: 300px;height:300px;" src="~/Content/defaultAvatar.jpg"><br />
</div>
<div class="col-md-5">
<input type="file" name="txt_file" id="txt_file" multiple class="file-loading" /><br />
<h4>图片说明:</h4>
<p>1、图片格式需要jpg、gif、png为后缀名.</p>
<p>2、图片可以在线裁剪大小,以裁剪后为最终结果.</p>
<p>3、图片上传完毕即可关闭窗口.</p>
</div>
</div>
</div>
</div>
</div>
</div>
@section scripts{
<script src="@Url.Content("~/Scripts/Jcrop/jquery.Jcrop.js")"></script>
<script src="@Url.Content("~/Scripts/bootstrap-fileinput/fileinput.js")"></script>
<script src="@Url.Content("~/Scripts/bootstrap-fileinput/zh.js")"></script>
<script type="text/javascript">
//http://code.ciaoca.com/jquery/jcrop/
//http://code.ciaoca.com/jquery/jcrop/demo/animation
//http://plugins.krajee.com/file-input
//http://plugins.krajee.com/file-advanced-usage-demo#advanced-example-5
var tailorInfo = "";
//初始化fileinput
function FileInput() {
var oFile = new Object();
oFile.Init = function (ctrlName, uploadUrl) {
var control = $('#' + ctrlName);
//初始化上传控件的样式
control.fileinput({
language: 'zh', //设置语言
browseLabel: '选择',
browseIcon: "<i class=\"glyphicon glyphicon-picture\"></i> ",
browseClass: "btn btn-primary", //按钮样式
uploadUrl: uploadUrl, //上传的地址
allowedFileExtensions: ['jpg', 'gif', 'png'],//接收的文件后缀
showUpload: true, //是否显示上传按钮
showCaption: false,//是否显示标题
showPreview: false,//隐藏预览
dropZoneEnabled: false,//是否显示拖拽区域
uploadAsync: true,//采用异步
autoReplace: true,
//minImageWidth: 50,
//minImageHeight: 50,
//maxImageWidth: 1000,
//maxImageHeight: 1000,
//maxFileSize: 0,//单位为kb,如果为0表示不限制文件大小
//minFileCount: 0,
maxFileCount: 1, //表示允许同时上传的最大文件个数
enctype: 'multipart/form-data',
validateInitialCount: true,
previewFileIcon: "<i class='glyphicon glyphicon-king'></i>",
msgFilesTooMany: "选择上传的文件数量({n}) 超过允许的最大数值{m}!",
uploadExtraData: function () {
return { "tailorInfo": tailorInfo }
}
});
}
return oFile;
};
function PageInit() {
var jcorp = null;
var _this = this;
var fileInput = new FileInput();
fileInput.Init("txt_file", "@Url.Action("UpLoadFile")");
var input = $('#txt_file');
//图片上传完成后
input.on("fileuploaded", function (event, data, previewId, index) {
if (data.response.success) {
jcorp.destroy();
$('#cut-img').attr('src', data.response.newImage);//Data URI Scheme形式
//$('#cut-img').attr('src', data.response.newImage + "?t=" + Math.random());//加尾巴解决缓存问题
}
alert(data.response.message);
});
//选择图片后触发
input.on('change', function (event, data, previewId, index) {
var img = $('#cut-img');
if (input[0].files && input[0].files[0]) {
var reader = new FileReader();
reader.readAsDataURL(input[0].files[0]);
reader.onload = function (e) {
img.removeAttr('src');
img.attr('src', e.target.result);
img.Jcrop({
setSelect: [0, 0, 260, 290],
handleSize: 10,
aspectRatio: 1,//选框宽高比
bgFade: false,
bgColor: 'black',
bgOpacity: 0.3,
onSelect: updateCords
}, function () {
jcorp = this;
});
};
if (jcorp != undefined) {
jcorp.destroy();
}
}
function updateCords(obj) {
tailorInfo = JSON.stringify({ "PictureWidth": $('.jcrop-holder').css('width'), "PictureHeight": $('.jcrop-holder').css('height'), "CoordinateX": obj.x, "CoordinateY": obj.y, "CoordinateWidth": obj.w, "CoordinateHeight": obj.h });
console.log(tailorInfo);
}
});
//上传出现错误
input.on('fileuploaderror', function (event, data, msg) {
alert(msg);
//jcorp.destroy();
//$('#cut-img').attr('src', '/Content/defaultAvatar.jpg');
return false;
});
//移除图片
input.on('fileclear', function (event) {
console.log("fileclear");
jcorp.destroy();
$('#cut-img').attr('src', '/Content/defaultAvatar.jpg');
});
};
$(function () {
PageInit();
});
</script>
}
public class FileInputController : Controller
{
[HttpGet]
public ActionResult UpLoadFile()
{
return View();
}
[HttpPost]
public ActionResult UpLoadFile(string tailorInfo)
{
var success = false;
var message = string.Empty;
var newImage = string.Empty;
try
{
var tailorInfoEntity = JsonConvert.DeserializeObject<TailorInfo>(tailorInfo);
tailorInfoEntity.PictureWidth = tailorInfoEntity.PictureWidth.Replace("px", "");
tailorInfoEntity.PictureHeight = tailorInfoEntity.PictureHeight.Replace("px", "");
var file = HttpContext.Request.Files[0];
if (file != null && file.ContentLength != 0)
{
newImage = ImageHelper.TailorImage(file.InputStream, tailorInfoEntity);
success = true;
message = "保存成功";
}
}
catch (Exception ex)
{
message = "保存失败" + ex.Message;
}
return Json(new { success = success, message = message, newImage = newImage });
}
}
/// <summary>
/// 前端裁剪信息及前端图片展示规格
/// </summary>
public class TailorInfo
{
public string PictureWidth { get; set; }
public string PictureHeight { get; set; }
public int CoordinateX { get; set; }
public int CoordinateY { get; set; }
public int CoordinateWidth { get; set; }
public int CoordinateHeight { get; set; }
}
/// <summary>
/// 图片处理
/// </summary>
public static class ImageHelper
{
/// <summary>
/// 图片按照实际比例放大
/// </summary>
/// <param name="content"></param>
/// <param name="tailorInfo"></param>
/// <returns></returns>
public static string TailorImage(Stream content, TailorInfo tailorInfo)
{
var scaleWidth = Convert.ToInt16(tailorInfo.PictureWidth);
var scaleHeight = Convert.ToInt16(tailorInfo.PictureHeight);
Bitmap sourceBitmap = new Bitmap(content);
double scaleWidthPercent = Convert.ToDouble(sourceBitmap.Width) / scaleWidth;
double scaleHeightPercent = Convert.ToDouble(sourceBitmap.Height) / scaleHeight;
double realX = scaleWidthPercent * tailorInfo.CoordinateX;
double realY = scaleHeightPercent * tailorInfo.CoordinateY;
double realWidth = scaleWidthPercent * tailorInfo.CoordinateWidth;
double realHeight = scaleHeightPercent * tailorInfo.CoordinateHeight;
return CropImage(content, (int)realX, (int)realY, (int)realWidth, (int)realHeight);
}
/// <summary>
/// 生成新图片
/// </summary>
/// <param name="content"></param>
/// <param name="x"></param>
/// <param name="y"></param>
/// <param name="cropWidth"></param>
/// <param name="cropHeight"></param>
/// <returns></returns>
public static string CropImage(byte[] content, int x, int y, int cropWidth, int cropHeight)
{
using (MemoryStream stream = new MemoryStream(content))
{
return CropImage(stream, x, y, cropWidth, cropHeight);
}
}
/// <summary>
/// 生成新图片
/// </summary>
/// <param name="content"></param>
/// <param name="x"></param>
/// <param name="y"></param>
/// <param name="cropWidth"></param>
/// <param name="cropHeight"></param>
/// <returns></returns>
public static string CropImage(Stream content, int x, int y, int cropWidth, int cropHeight)
{
using (Bitmap sourceBitmap = new Bitmap(content))
{
Bitmap bitSource = new Bitmap(sourceBitmap, sourceBitmap.Width, sourceBitmap.Height);
Rectangle cropRect = new Rectangle(x, y, cropWidth, cropHeight);
using (Bitmap newBitMap = new Bitmap(cropWidth, cropHeight))
{
newBitMap.SetResolution(sourceBitmap.HorizontalResolution, sourceBitmap.VerticalResolution);
using (Graphics g = Graphics.FromImage(newBitMap))
{
g.InterpolationMode = InterpolationMode.HighQualityBicubic;
g.SmoothingMode = SmoothingMode.HighQuality;
g.PixelOffsetMode = PixelOffsetMode.HighQuality;
g.CompositingQuality = CompositingQuality.HighQuality;
g.DrawImage(bitSource, new Rectangle(0, 0, newBitMap.Width, newBitMap.Height), cropRect, GraphicsUnit.Pixel);
return BitmapToBytes(newBitMap);
}
}
}
}
/// <summary>
/// 图片转到byte数组
/// </summary>
/// <param name="source"></param>
/// <returns></returns>
public static string BitmapToBytes(Bitmap source)
{
ImageCodecInfo codec = ImageCodecInfo.GetImageEncoders()[4];
EncoderParameters parameters = new EncoderParameters(1);
parameters.Param[0] = new EncoderParameter(Encoder.Quality, 100L);
using (MemoryStream tmpStream = new MemoryStream())
{
source.Save(tmpStream, codec, parameters);
byte[] data = new byte[tmpStream.Length];
tmpStream.Seek(0, SeekOrigin.Begin);
tmpStream.Read(data, 0, (int)tmpStream.Length);
return SaveImageToLocal(data);
}
}
/// <summary>
/// 存储图片到本地文件系统
/// </summary>
/// <param name="binary"></param>
public static string SaveImageToLocal(byte[] binary)
{
//根据用户信息生成图片名 todo
var path = Path.Combine(AppDomain.CurrentDomain.BaseDirectory, @"Content\avatar.png");
File.WriteAllBytes(path, binary);
return "data:images/png;base64," + Convert.ToBase64String(binary);//Data URI Scheme形式
//return @"/Content/avatar.png";//Url形式
}
}
git地址:https://gitee.com/530521314/TailorImage.git
步骤:
一、引用前端插件
加入JCrop插件,在官网下载或是git上下载均可,引用这两个文件即可,注意引用地址正确哈。
<link href="@Url.Content("~/Content/Jcrop/jquery.Jcrop.css")" rel="stylesheet" />
<script src="@Url.Content("~/Scripts/Jcrop/jquery.Jcrop.js")"></script>
加入Bootstrap插件,同样下载或是git上下载,不建议通过nuget或是bower下载,会下载一大堆的东西,很多用不到的。引用如下文件。
<link href="@Url.Content("~/Content/bootstrap-fileinput/fileinput.css")" rel="stylesheet" />
<script src="@Url.Content("~/Scripts/bootstrap-fileinput/fileinput.js")"></script>
<script src="@Url.Content("~/Scripts/bootstrap-fileinput/zh.js")"></script>
我是直接在页面上引用的并没有将其移动到模板上出于一些因素,暂时可以不讨论这里,页面引用结构:
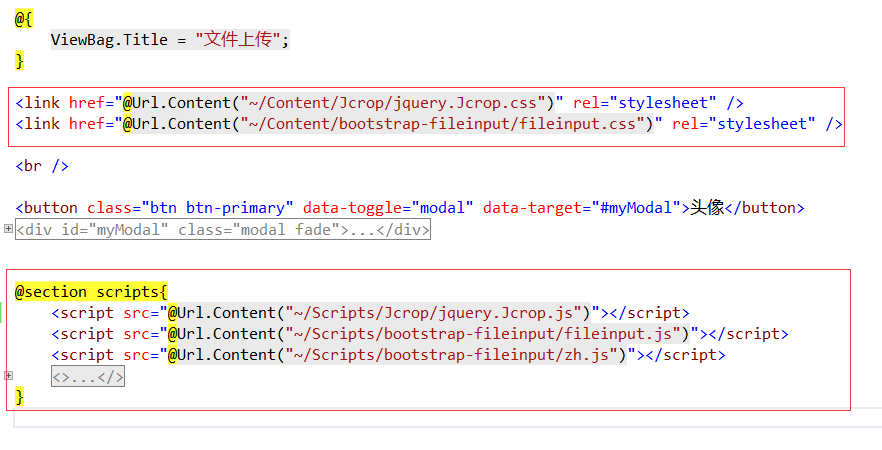
二、前端文件上传页面设计
加入文件上传元素,一行代码即可,没错就一行:
<input type="file" name="txt_file" id="txt_file" multiple class="file-loading" /><br />
加入文件上传相关的js代码:
//初始化fileinput
function FileInput() {
var oFile = new Object();
oFile.Init = function (ctrlName, uploadUrl) {
var control = $('#' + ctrlName);
//初始化上传控件的样式
control.fileinput({
language: 'zh', //设置语言
browseLabel: '选择',
browseIcon: "<i class=\"glyphicon glyphicon-picture\"></i> ",
browseClass: "btn btn-primary", //按钮样式
uploadUrl: uploadUrl, //上传的地址
allowedFileExtensions: ['jpg', 'gif', 'png'],//接收的文件后缀
showUpload: true, //是否显示上传按钮
showCaption: false,//是否显示标题
showPreview: false,//隐藏预览
dropZoneEnabled: false,//是否显示拖拽区域
uploadAsync: true,//采用异步
autoReplace: true,
//minImageWidth: 50,
//minImageHeight: 50,
//maxImageWidth: 1000,
//maxImageHeight: 1000,
//maxFileSize: 0,//单位为kb,如果为0表示不限制文件大小
//minFileCount: 0,
maxFileCount: 1, //表示允许同时上传的最大文件个数
enctype: 'multipart/form-data',
validateInitialCount: true,
previewFileIcon: "<i class='glyphicon glyphicon-king'></i>",
msgFilesTooMany: "选择上传的文件数量({n}) 超过允许的最大数值{m}!",
uploadExtraData: function () {
return { "tailorInfo": tailorInfo }
}
});
}
return oFile;
};
然后实例化一个fileinput
var fileInput = new FileInput();
fileInput.Init("txt_file", "@Url.Action("UpLoadFile")");
至此文件上传前端页面已经OK了,接下来加入图片裁剪功能。
三、前端图片裁剪页面设计
裁剪的话不能够在文件上传的框中进行直接裁剪,而是通过一个图片标签进行裁剪,因此加入一个图片标签
<img id="cut-img" class="thumbnail" style="width: 300px;height:300px;" src="~/Content/defaultAvatar.jpg"><br />
裁剪的js代码
var input = $('#txt_file');
//选择图片后触发
input.on('change', function (event, data, previewId, index) {
var img = $('#cut-img');
if (input[0].files && input[0].files[0]) {
var reader = new FileReader();
reader.readAsDataURL(input[0].files[0]);
reader.onload = function (e) {
img.removeAttr('src');
img.attr('src', e.target.result);
//关键在这里
img.Jcrop({
setSelect: [0, 0, 260, 290],
handleSize: 10,
aspectRatio: 1,//选框宽高比
bgFade: false,
bgColor: 'black',
bgOpacity: 0.3,
onSelect: updateCords
}, function () {
jcorp = this;
});
};
if (jcorp != undefined) {
jcorp.destroy();
}
}
function updateCords(obj) {
tailorInfo = JSON.stringify({ "PictureWidth": $('.jcrop-holder').css('width'), "PictureHeight": $('.jcrop-holder').css('height'), "CoordinateX": obj.x, "CoordinateY": obj.y, "CoordinateWidth": obj.w, "CoordinateHeight": obj.h });
console.log(tailorInfo);
}
});
至此前端页面文件上传和裁剪可以直接使用了。
四、后端文件上传和裁剪设计
将裁剪信息传递到后端,前端可以使用到Bootstrap-fileinput的一个属性uploadExtraData,可以传递除文件外的一些信息过来。当然如果看了Bootstrap-fileinput,其实是有两种模式,模式一是直接表单提交,额外属性直接用相关字段即可保存提交,我用的是模式二,异步上传,额外的信息只能通过属性uploadExtraData来保存提交。
获得上传过来的图片信息,通过图片辅助类的处理得到图片的的地址,这个是用的DataURI Scheme协议,可以直接在图片上展示图片,而不需要用相对/绝对路径的形式,某宝好像就是这样。这样一来,小图片可以直接转换成Base64的形式保存在数据库,而不需要依赖本地的文件系统了,不错额。
[HttpPost]
public ActionResult UpLoadFile(string tailorInfo)
{
var success = false;
var message = string.Empty;
var newImage = string.Empty;
try
{
var tailorInfoEntity = JsonConvert.DeserializeObject<TailorInfo>(tailorInfo);
tailorInfoEntity.PictureWidth = tailorInfoEntity.PictureWidth.Replace("px", "");
tailorInfoEntity.PictureHeight = tailorInfoEntity.PictureHeight.Replace("px", "");
var file = HttpContext.Request.Files[0];
if (file != null && file.ContentLength != 0)
{
newImage = ImageHelper.TailorImage(file.InputStream, tailorInfoEntity);
success = true;
message = "保存成功";
}
}
catch (Exception ex)
{
message = "保存失败" + ex.Message;
}
return Json(new { success = success, message = message, newImage = newImage });
}
图片辅助类
/// <summary>
/// 图片处理
/// </summary>
public static class ImageHelper
{
/// <summary>
/// 图片按照实际比例放大
/// </summary>
/// <param name="content"></param>
/// <param name="tailorInfo"></param>
/// <returns></returns>
public static string TailorImage(Stream content, TailorInfo tailorInfo)
{
var scaleWidth = Convert.ToInt16(tailorInfo.PictureWidth);
var scaleHeight = Convert.ToInt16(tailorInfo.PictureHeight);
Bitmap sourceBitmap = new Bitmap(content);
double scaleWidthPercent = Convert.ToDouble(sourceBitmap.Width) / scaleWidth;
double scaleHeightPercent = Convert.ToDouble(sourceBitmap.Height) / scaleHeight;
double realX = scaleWidthPercent * tailorInfo.CoordinateX;
double realY = scaleHeightPercent * tailorInfo.CoordinateY;
double realWidth = scaleWidthPercent * tailorInfo.CoordinateWidth;
double realHeight = scaleHeightPercent * tailorInfo.CoordinateHeight;
return CropImage(content, (int)realX, (int)realY, (int)realWidth, (int)realHeight);
}
/// <summary>
/// 生成新图片
/// </summary>
/// <param name="content"></param>
/// <param name="x"></param>
/// <param name="y"></param>
/// <param name="cropWidth"></param>
/// <param name="cropHeight"></param>
/// <returns></returns>
public static string CropImage(byte[] content, int x, int y, int cropWidth, int cropHeight)
{
using (MemoryStream stream = new MemoryStream(content))
{
return CropImage(stream, x, y, cropWidth, cropHeight);
}
}
/// <summary>
/// 生成新图片
/// </summary>
/// <param name="content"></param>
/// <param name="x"></param>
/// <param name="y"></param>
/// <param name="cropWidth"></param>
/// <param name="cropHeight"></param>
/// <returns></returns>
public static string CropImage(Stream content, int x, int y, int cropWidth, int cropHeight)
{
using (Bitmap sourceBitmap = new Bitmap(content))
{
Bitmap bitSource = new Bitmap(sourceBitmap, sourceBitmap.Width, sourceBitmap.Height);
Rectangle cropRect = new Rectangle(x, y, cropWidth, cropHeight);
using (Bitmap newBitMap = new Bitmap(cropWidth, cropHeight))
{
newBitMap.SetResolution(sourceBitmap.HorizontalResolution, sourceBitmap.VerticalResolution);
using (Graphics g = Graphics.FromImage(newBitMap))
{
g.InterpolationMode = InterpolationMode.HighQualityBicubic;
g.SmoothingMode = SmoothingMode.HighQuality;
g.PixelOffsetMode = PixelOffsetMode.HighQuality;
g.CompositingQuality = CompositingQuality.HighQuality;
g.DrawImage(bitSource, new Rectangle(0, 0, newBitMap.Width, newBitMap.Height), cropRect, GraphicsUnit.Pixel);
return BitmapToBytes(newBitMap);
}
}
}
}
/// <summary>
/// 图片转到byte数组
/// </summary>
/// <param name="source"></param>
/// <returns></returns>
public static string BitmapToBytes(Bitmap source)
{
ImageCodecInfo codec = ImageCodecInfo.GetImageEncoders()[4];
EncoderParameters parameters = new EncoderParameters(1);
parameters.Param[0] = new EncoderParameter(Encoder.Quality, 100L);
using (MemoryStream tmpStream = new MemoryStream())
{
source.Save(tmpStream, codec, parameters);
byte[] data = new byte[tmpStream.Length];
tmpStream.Seek(0, SeekOrigin.Begin);
tmpStream.Read(data, 0, (int)tmpStream.Length);
return SaveImageToLocal(data);
}
}
/// <summary>
/// 存储图片到本地文件系统
/// </summary>
/// <param name="binary"></param>
public static string SaveImageToLocal(byte[] binary)
{
//根据用户信息生成图片名 todo
var path = Path.Combine(AppDomain.CurrentDomain.BaseDirectory, @"Content\avatar.png");
File.WriteAllBytes(path, binary);
return "data:images/png;base64," + Convert.ToBase64String(binary);//Data URI Scheme形式
//return @"/Content/avatar.png";//Url形式
}
}
最后这一步可以控制你需要的形式,是要使用路径形式还是Data URI Scheme形式。
第一个方法将图片根据获得的位置信息,进行比例缩放,然后一系列处理得到新图片。再将图片返回给前端展示。
裁剪信息的类我是这样设计的,但是里面的内容可以全部自定义,是由前端传递过来的信息决定的,应该属于ViewModel这一类的。
/// <summary>
/// 前端裁剪信息及前端图片展示规格
/// </summary>
public class TailorInfo
{
public string PictureWidth { get; set; }
public string PictureHeight { get; set; }
public int CoordinateX { get; set; }
public int CoordinateY { get; set; }
public int CoordinateWidth { get; set; }
public int CoordinateHeight { get; set; }
}
五、成果展示

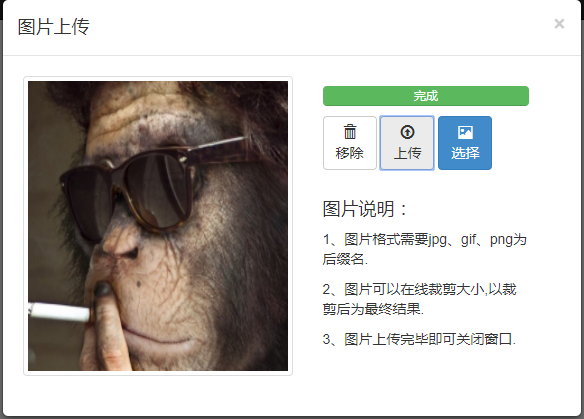
至此图片的在线裁剪搞定了。
六、 asp.net core下的后端设计
由于core并还没有将图片相关的类库移植到core下,但是社区上有大神们已经完成了core下的图片处理的类库,我使用的是SixLabors.ImageSharp
地址:https://www.nuget.org/packages/SixLabors.ImageSharp其中介绍了怎么样安装的方法,不再陈述。
在asp.net core下,我只实现了一个图片缩放的代码,如有更多需要,可以联系我,我将尝试尝试。
前端页面无需做改动,后端代码我们需要改变了,需要用到ImageSharp中的一些方法和属性。
asp.net core取文件的方式变了。
var file = HttpContext.Request.Form.Files["txt_file"];
pictureUrl = "data:images/png;base64," + ImageHelper.ImageCompress(file.OpenReadStream());//图片缩放到一定规格
在图片辅助类中,通过ImageSharp进行处理即可将图片缩放,当然也可以裁剪,但是我没有去设计了:
public static string ImageCompress(Stream content)
{
var imageString = string.Empty;
using (Image<Rgba32> image = Image.Load(content))
{
image.Mutate(x => x
.Resize(image.Width / 5, image.Height / 5)
.Grayscale());
imageString = image.ToBase64String(ImageFormats.Bmp);
}
return imageString;
}
在此,感谢几位博友的文章:
@梦游的龙猫 https://www.cnblogs.com/wuxinzhe/p/6198506.html
https://yq.aliyun.com/ziliao/1140
2018-3-31,望技术有成后能回来看见自己的脚步
循序渐进学.Net Core Web Api开发系列【2】:利用Swagger调试WebApi
系列目录
本系列涉及到的源码下载地址:https://github.com/seabluescn/Blog_WebApi
一、概述
既然前后端开发完全分离,那么接口的测试和文档就显得非常重要,文档维护是一件比较麻烦的事情,特别是变更的文档,这时采用Swagger就会非常方便,同时解决了测试和接口文档两个问题。
二、使用NuGet获取包
使用NuGet搜索包:Swashbuckle.aspnetcore并安装。
三、添加代码
在Startup类的ConfigureServices方法内添加下面代码(加粗部分)
public void ConfigureServices(IServiceCollection services)
{
services.AddMvc();
services.AddSwaggerGen(option =>
{
option.SwaggerDoc("v1", new Info
{
Version = "v1",
Title = "SaleService接口文档",
Description = "RESTful API for SaleService.",
TermsOfService = "None",
Contact = new Contact { Name = "seabluescn", Email = "seabluescn@163.com", Url = "" }
});
//Set the comments path for the swagger json and ui.
var basePath = PlatformServices.Default.Application.ApplicationBasePath;
var xmlPath = Path.Combine(basePath, "SaleService.xml");
option.IncludeXmlComments(xmlPath);
});
}
在Startup类的Configure方法内添加下面代码(加粗部分)
public void Configure(IApplicationBuilder app, IHostingEnvironment env)
{
app.UseMvcWithDefaultRoute();
app.UseSwagger();
app.UseSwaggerUI(option =>
{
option.ShowExtensions();
option.SwaggerEndpoint("/swagger/v1/swagger.json", "SaleService V1");
});
}
四、配置
需要在生成配置选项内勾选XML文档文件,项目编译时会生成该文件。Debug和Release模式都设置一下。否则会报一个System.IO.FileNotFoundException的错误。

五、启动
启动项目,浏览器输入:http://localhost:50793/swagger/ 即可。
也可以修改launchsettings.json文件,默认项目启动时运行swagger
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
{ "iisSettings": { "windowsAuthentication": false, "anonymousAuthentication": true, "iisExpress": { "applicationUrl": "http://localhost:50792/", "sslPort": 0 } }, "profiles": { "IIS Express": { "commandName": "IISExpress", "launchBrowser": true, "launchUrl": "api/values", "environmentVariables": { "ASPNETCORE_ENVIRONMENT": "Development" } }, "SaleService": { "commandName": "Project", "launchBrowser": true, "launchUrl": "swagger", "environmentVariables": { "ASPNETCORE_ENVIRONMENT": "Development" }, "applicationUrl": "http://localhost:50793/" } }} |
如果你对你的控制器方法进行了注释,swagger接口页面就会体现出来。
/// <summary>
/// 根据产品编号查询产品信息
/// </summary>
/// <param name="code">产品编码</param>
/// <returns>产品信息</returns>
[HttpGet("{code}")]
public Product GetProduct(String code)
{
var product = new Product
{
ProductCode = code,
ProductName = "啫喱水"
};
return product;
}
下面为Swagger的首页:可以用它进行API的调试了。


