

你所不知道的库存超限做法 服务器一般达到多少qps比较好[转] JAVA格物致知基础篇:你所不知道的返回码 深入了解EntityFramework Core 2.1延迟加载(Lazy Loading) EntityFramework 6.x和EntityFramework Core关系映射中导航属性必须是public? 藏在正则表达式里的陷阱 两道面试题,带你解析Java类加载机制
在互联网企业中,限购的做法,多种多样,有的别出心裁,有的因循守旧,但是种种做法皆想达到的目的,无外乎几种,商品卖的完,系统抗的住,库存不超限。虽然短短数语,却有着说不完,道不尽,轻者如释重负,重者涕泪横流的架构体验。 但是,在实际开发过程中,库存超限,作为其中最核心的一员,到底该怎么做,如何做才会是最合适的呢?
今天这篇文章,我将会展示给大家库存限购的五种常见的做法,并对其利弊一一探讨,由于这五种做法,有的在设计之初当做提案被否定掉的,有的在线上跑着,但是在没有任何单元测试和压测情况下,这几种超限控制的做法也许是不符合你的业务的,所以不建议直接用于生产环境。我这里权当是做抛砖引玉,期待大家更好的做法。
工欲善其事必先利其器,在这里,我们将利用一台测试环境的redis服务器当做库存超限控制的主战场,先设置库存量为10进去,然后根据此库存量,一一展开,设置库存代码如下:
1: def set_storage():
2: conn = redis_conn()
3: key = "storage_seckill"
4: current_storage = conn.get(key)
5: if current_storage == None:
6: conn.set(key, 10)
为了方便性,我这里使用了python语言来书写逻辑,但是今天我们只是讲解思想,语言这类的,大家可以自己尝试转一下。
上面就是我们的设置库存到redis中的做法,很简单,就是在redis中设置一个storage_seckill的库存key,然后里面放上库存量10.
超限限制做法一:先获取当前库存值进行比对,然后进行扣减操作
1: def storage_scenario_one():
2: conn = redis_conn()
3: key = "storage_seckill"
4: current_storage = conn.get(key)
5: current_storage_int = int(current_storage)
6: if current_storage_int<=0 :
7: return 0
8: result = conn.decr(key)
9: return result
首先,我们拿到当前的库存值,然后看看是否已经扣减到了零,如果扣减到了零,则不继续扣减,直接返回;如果库存还有,则利用decr原子操作进行扣减,同时返回扣减后的库存值。
此种做法在小并发量下访问,问题不大;在对库存量控制不严格的业务中,问题也不大。但是如果并发量比较大一些,同时业务要求严格控制库存,那么此种做法是非常不合适的,原因在于,在高并发情况下,get命令,decr命令,都是分开发给redis的,这样会导致比对的时候,很容易出现限制不住的情况,也就是会造成第六行的比对失效。
设想如下一个场景,AB两个请求进来,A获取的库存值为1,B获取的库存值为1,然后两个请求都被发到redis中进行扣减操作,然后这种场景下,A最后得到的库存值为0;但是B最后得到的库存值为-1,超限。
所以此种场景,由于在高并发下,get和decr操作不是一组原子性操作,会引发超限问题,被直接pass。
超限限制做法二:先扣减库存,然后比对,最后根据情况回滚
1: def storage_scenario_two():
2: conn = redis_conn()
3: key = "storage_seckill"
4: current = conn.decr(key)
5: if current>=0:
6: return current
7: else:
8: #回滚库存
9: conn.incr(key)
10: return 0
首先,请求进来,直接对库存值进行扣减,然后得到当前的库存值;然后,对此库存值进行校验,如果库存还有,则返回库存值,如果库存没有了,则回滚库存,以便于防止负库存量的存在。
此做法,相比做法一,要稍微可靠一些,由于redis的decr操作直接返回真实的库存值,所以每个请求进来,只要执行了decr操作,拿到的肯定是当前最准确的库存值。然后进行比对,如果库存值大于等于零,返回当前库存值,如果小于零,则将库存进行回滚。
此种做法,最大的一个问题就是,如果大批量的并发请求过来,redis承受的写操作的量,相对于方法一来说,是加倍的,因为回滚库存的存在导致的。所以这种情况下,高并发量进来,极有可能将redis的写操作打出极限值,然后会出现很多redis写失败的错误警告。 另一个问题和做法一是一样的,就是第五行的比对在高并发下,也是限不住的,具体的压测结果请看我的这篇stackoverflow的提问:Will redis incr command can be limitation to specific number?
所以此种场景,虽然在高并发情况下避免了redis命令的分开操作,但是却大大增加了redis的写并发量,被pass。
超限限制做法三:先递减库存,然后通过整数溢出控制,最后根据情况回滚
1: def storage_scenario_three():
2: conn = redis_conn()
3: key = "storage_seckill"
4: current = conn.decr(key)
5: #通过整数控制溢出的做法
6: if storage_overflow_checker(current):
7: return current
8: else:
9: #回滚库存
10: conn.incr(key)
11: return 0
12:
13: def storage_overflow_checker(current_storage):
14: #如果当前库存未被递减到0,则check_number为int类型,isinstance方法检测结果为true
15: #如果当前库存已被递减到负数,则check_number为long类型,isinstance方法检测结果为false
16: check_number = sys.maxint - current_storage
17: check_result = isinstance(check_number,int)
18: return check_result
说明一下,当前库存,如果为负数,则利用python的isinstance(check_number,int)检测的时候,check_result返回是false;如果为非负数,则检测的时候,check_result返回的是true,上面的storage_overflow_checker的做法,和下面的C#语言的做法是一样的,利用C#语言描述,大家可能对上面的代码更清晰一些:
1: /**
2: * 通过让Integer溢出的方式来控制数量超卖(递减导致溢出)
3: * @param current
4: * @return
5: */
6: public boolean StorageOverFillChecker(long current) {
7: try {
8: //当前数值的结果计算
9: Long value = Integer.MAX_VALUE - current;
10: //尝试转变为Inter类型,如果超卖,则转换会出错;如果未超卖,则转换不会出错
11: Integer.parseInt(value.toString());
12: } catch (Exception ex) {
13: //值溢出
14: return true;
15: }
16:
17: return false;
18: }
可以看出,此种做法和方法二很相似,只是比对部分由,直接和零比对,变成了通过检测integer是否溢出的方式来进行。这样就彻底解决了高并发情况下,直接和零比对,限制不住的问题了。
虽然此种做法,相对于做法二说来,要靠谱很多,但是仍然解决不了在高并发情况下,redis写并发量加倍的问题,极有可能某个促销活动,在开始的那一刻,直接将redis的写操作打出问题来。
超限限制做法四:共享锁
1: def storage_scenario_four():
2: conn = redis_conn()
3: key = "storage_seckill"
4: key_lock = key + "_lock"
5: if conn.setnx(key_lock, "1"):
6: #客户端挂掉,设置过期时间,防止其不释放锁
7: conn.pexpire(key_lock, 5)
8: current_storage = conn.get(key)
9: if int(current_storage)<=0 :
10: return 0
11: result = conn.decr(key)
12: #客户端正常,删除共享锁,提高性能
13: conn.delete(key_lock)
14: return result
15: else :
16: return "someone in it"
前面三种,由于在高并发下都有问题,所以本做法,主要是通过setnx设置共享锁,然后请求到锁的用户请求,正常进行库存扣减操作;请求不到锁的用户请求,则直接提示有其他人在操作库存。
由于setnx的特殊性,当客户端挂掉的时候,是不会释放这个锁的,所以当请求进来的时候,首先通过pexpire命令,为锁设置过期时间,防止死锁不释放。然后执行正常的库存扣减操作,当操作完毕,删掉共享锁,可以极大的提高程序性能,否则只能等待锁慢慢过期了。
此种做法相对于上面的三种操作,通过采用共享锁,牺牲了部分性能,来规避了高并发的问题,比较推荐,但是由于redis操作命令还是很多,并且每条都要发送到redis端执行,所以在网络传输上,耗费的时间开销是不小的。这是后面需要着力优化的方向。
看了上面四种做法,都不是很完美,其中最大的问题在于,高并发情况下,多条redis命令分开操作库存,极容易发生库存限不住的问题;同时,由于加了rollback库存操作,极容易由于redis写命令的操作数加倍导致压垮redis的风险。加了锁,虽然牺牲了部分性能,规避了高并发问题,但是redis命令操作量过多。
其实我上面一直在强调高并发,高并发。上面的四个场景,只有在高并发的情况下,才会出现问题,如果你的用户请求量没有那么多,那么采用上面四种方式之一,也不是不可以。但是如何才能知道采用起来没问题呢?其实最简单的一个方式,就是在你们自己的集群机器上,模拟活动的真实用户量,进行压测,看看会不会超限就行了,不超限的话,上面四种做法完全满足需求。
那么,就没有比较好一些的解决方案了吗?
也不是,虽然解决这个问题,没有绝对好用的银弹,但是有相对好用的大蒜和圣水。下面的讲解,会涉及到Redisson的Redlock的源码实现,当然也会涉及一点lua方面的知识,还请提前预备一下。
偶然在研究分布式锁的时候,尝试翻阅过Redisson的Redlock的实现,并对其底层的实现方式有所记录,我们先来看看其加锁过程的源码实现:

从上面的方法中,我们可以看到,分布式锁的上锁过程,是首先判断一个key存不存在,如果不存在,则设置这个key,然后pexpire设置一个过期时间,来防止客户端访问的时候,挂掉了后,不释放锁的问题。为什么这段lua代码就能实现分布式锁的核心呢? 原因就是,这段代码放到一个lua脚本中,那么这段lua脚本就是一个原子性的操作。redis在执行这段lua脚本的过程中,不会掺杂任何其他的命令。所以从根本上避免了并发操作命令的问题。
我们都知道,一个key如果设置了过期时间,key过期后,redis是不会删掉这个key的,只有用户访问才会删除掉这个key,所以,当使用分布式锁的时候,如果设置的pexpire过期时间为5ms,那么一秒钟只能处理200个并发,性能非常低。如何解决这种性能问题呢?来看来解锁的操作:

从上面解锁的方法中,我们可以看到,如果这个锁用完了之后,Redisson的做法是是直接删除掉的。这样可以提高不少的性能。(源码参阅,属于我自己的理解,如有谬误,还请指教)
那么按照上面这种设计思路,新的超限做法就出来了。
超限做法五:基于lua的共享锁
1: def storage_scenario_five():
2: conn = redis_conn()
3: key = "storage_seckill"
4: key_lock = key + "_lock"
5: key_val = "get_the_key"
6: lua = """
7: local key = KEYS[1]
8: local expire = KEYS[2]
9: local value = KEYS[3]
10:
11: local result = redis.call('setnx',key,value)
12: if result == 1 then
13: redis.call('pexpire', key, expire)
14: end
15: return result
16: """
17: locked = conn.eval(lua, 3, key_lock, 5, key_val)
18: print (locked == 1)
19: if locked == 1:
20: val = storage_scenario_one()
21: print("val:"+str(val))
22: #删掉共享key,用以提高性能, 否则只能默默的等其过期
23: conn.delete(key_lock)
24: return val
25: else:
26: return "someone in it"
这种做法,其实是做法四的衍生优化版本,优化的地方在于,将多条redis操作命令多次发送,改成了将多条redis操作命令放在了一个原子性操作事务中一次性执行完毕,省去了很多的网络请求。如果可以,其实你也可以将业务逻辑糅合到上面的lua代码中,这样一来,性能当然会更好。
上面这种做法,如果 storage_scenario_one()这种操作是直接操作的mysql库存,则非常推荐这种做法,但是如果storage_scenario_one()这种操作直接操作的redis中的虚拟库存,则不是很推荐这种做法,不如直接用限流操作。
超限做法六: All In Lua
1: def storage_scenario_six():
2: conn = redis_conn()
3: lua = """
4: local storage = redis.call('get','storage_seckill')
5: if storage ~= false then
6: if tonumber(storage) > 0 then
7: return redis.call('decr','storage_seckill')
8: else
9: return 'storage is zero now, can't perform decr action'
10: end
11: else
12: return redis.call('set','storage_seckill',10)
13: end
14: """
15: result = conn.eval(lua,0)
16: print(result)
此种做法是当前最好的做法,所有的库存扣减操作都放在lua脚本中进行,形成一个原子性操作,redis在执行上面的lua脚本的时候,是不会掺杂任何其他的执行命令的。所以这样从根本上避免了高并发下,多条命令执行带来的问题。而且上面的redis命令执行,都直接在redis服务器上,省去了网络传输时间,也没有共享锁的限制,从性能上而言,是最好的。但是,业务逻辑的lua化,相对而言是比较麻烦的,所以对于追求极限库存控制的业务,可以考虑这种做法。
好了,这就是我今天为大家带来的六种库存超限的做法,每种做法都有自己的优缺点,好使的限不住,限的住的性能不行,性能好的又需要引入lua,真心不知道如何选择了。
声明:上面六种库存超限做法,有些属于本人的推理,线上并未实际用过,如果你贸然使用而未经过压测,由此造成的损失,找老板去讨论吧。
参考资源:
redis lua can't work properly due to wrong type comparison
《深入理解redis》
Edit:2018年2月9日11:19:35
修改了第五种方法中的说明部分。
你好,每秒查询率QPS是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准,在因特网上,作为域名系统服务器的机器的性能经常用每秒查询率来衡量。
原理:每天80%的访问集中在20%的时间里,这20%时间叫做峰值时间
公式:( 总PV数 * 80% ) / ( 每天秒数 * 20% ) = 峰值时间每秒请求数(QPS)
机器:峰值时间每秒QPS / 单台机器的QPS = 需要的机器
问:每天300w PV 的在单台机器上,这台机器需要多少QPS?
答:( 3000000 * 0.8 ) / (86400 * 0.2 ) = 139 (QPS)
问:如果一台机器的QPS是58,需要几台机器来支持?
答:139 / 58 = 3
楼主可以根据以上回答来做判断。天互数据 为您解答,希望能帮到你!
上篇我们主要讲解利用Jersey组件如何来写一个能保证基本运行的Rest Service, 之所以说能够基本运行是因为接口暴露及其简易,一旦遇到其他的情况了,就无法正确的处理我们的请求。同时,这个接口返回内容太简单了,如果调用失败,调用者根本无法准确的知道具体的错误信息。那么这节,我们将完善接口,为调用者提供 400-Bad Request, 500-Server Error, 304-Not Modified, 200-Response OK, 404-Not Found的识别标志,让调用者能够明白是什么错误,错在了什么地方。
返回码概览
1.400-Bad Request: 这种错误码一般是请求错误,比如说我的UserID需要传入UUID类型的,但是我传入了不符合要求的数据,比如说Int类型,那么服务端收到这种请求,可以直接给客户端返回这个错误代码并附加上相应的错误说明,那么客户端就能明白错在什么地方了。
2.500-Bad Request: 这种错误码一般是处理错误,也就是对整个处理管道异常处理的捕捉,我们可以在catch里面抛出这种错误给用户并附加上相应的错误代码。
3.404-Not Found: 这种错误码一般是找不到内容所致。也就是说如果请求方发给的请求,但是在数据库中找不到相关信息,则可以返回这种错误。
4.200-Response OK: 当客户端发起请求,服务端成功响应,则可以发送这种状态码。
5.304-Not Modified: 这种返回码是通过计算ETag来进行的,具体的流程如下: 客户端首先向服务器端发送请求,服务器端收到请求,然后计算出Etag,附加到header中传递给客户端。客户端以后再请求的话,需要附带上 If-None-Match:Etag值,发送给服务器端,服务器接收到这个值后,然后重新生成Etag值,最后做比对,如果没变,则返回客户端304;如果有变化,则需要从数据库提取数据,返回给客户端200状态码。
代码设计
在这里我们不在详细说明具体的设计步骤,我只展示具体的代码。
首先,我们定义一个Get的API操作方法:
|
1
2
3
4
5
6
7
|
/** * Provide the endpoint used to get the summary of the user progress */@GET@Path("{"+ PtsResourcePaths.PROGRESS_SUMMARY_ROOT_PATH_RESOURCE+"}/"+ PtsResourcePaths.PROGRESS_SUMMARY_BINARY_PATH_RESOURCE)@Produces(MediaType.APPLICATION_JSON)Response UserLearningSummaryRequest(@PathParam(PtsResourcePaths.PROGRESS_SUMMARY_ROOT_PATH_RESOURCE) String titanUserId, @Context Request request); |
从上面的定义中,我们可以看到其接收两个参数,一个是用户ID,另外一个是客户端请求上下文(Request对象可以进行ETag值的计算)。
然后,我们来看看数据库Bean处理:
|
1
2
3
4
|
@Overridepublic List<UserLearningCourse> findLearnerProgressSummaryByTitanUserIdent(String titanUserId) { return userLearningCourseDao.fetchSummaryProgressByUserIdent(titanUserId);} |
是不是很简单,数据库处理这块直接从数据库获取数据集合,返回即可。
然后,我们来看看业务Bean处理:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
|
@Override public GenericResponseWrapperDto<UserLearningCoursesResponse> processUserLearningSummaryRequest(String titanUserId, Request request) throws DataValidationException { GenericResponseWrapperDto<UserLearningCoursesResponse> responseWrapper = new GenericResponseWrapperDto<UserLearningCoursesResponse>(); UserLearningCoursesResponseDto userLearningCoursesResponseDto = new UserLearningCoursesResponseDto(); List userLearningSummaryDtoCollection = new ArrayList(); //if the titanUserId match the uuid format if (!titanUserId.matches("[0-9a-fA-F]{8}-[0-9a-fA-F]{4}-[0-9a-fA-F]{4}-[0-9a-fA-F]{4}-[0-9a-fA-F]{12}")) { responseWrapper.setHttpStatusCode(PtsErrors.ErrorEnum.TITAN_USER_IDENT_INVALID.getStatus().getStatusCode()); responseWrapper.setErrorMessage(PtsErrors.ErrorEnum.TITAN_USER_IDENT_INVALID.getErrorMessage()); responseWrapper.setErrorCode(PtsErrors.ErrorEnum.TITAN_USER_IDENT_INVALID.getErrorCode()); return responseWrapper; } List<UserLearningCourse> resultCollection = userLearningSummaryBean.findLearnerProgressSummaryByTitanUserIdent(titanUserId); if (resultCollection == null || resultCollection.size()==0) { responseWrapper.setHttpStatusCode(PtsErrors.ErrorEnum.USER_LEARNING_COURSE_SUMMARY_EMPTY.getStatus().getStatusCode()); responseWrapper.setErrorMessage(PtsErrors.ErrorEnum.USER_LEARNING_COURSE_SUMMARY_EMPTY.getErrorMessage()); responseWrapper.setErrorCode(PtsErrors.ErrorEnum.USER_LEARNING_COURSE_SUMMARY_EMPTY.getErrorCode()); return responseWrapper; } //mapper between the response entity and responsedto entity String etagStr = ""; for (UserLearningCourse userLearningCourse : resultCollection) { UserLearningCourseResponseDto userLearningCourseResponseDto = new UserLearningCourseResponseDto(); userLearningCourseResponseDto.setCourseId(userLearningCourse.getCourseIdentifier()); userLearningCourseResponseDto.setBestGrade(userLearningCourse.getBestCourseGrade()); userLearningCourseResponseDto.setLatestGrade(userLearningCourse.getLatestCourseGrade()); List<UserLearningSequence> userLearningSequences = userLearningCourse.getUserLearningSequences(); List<UserLearningSequenceResponse> userLearningSequenceResponses = new ArrayList<UserLearningSequenceResponse>(); if (userLearningSequences != null && userLearningSequences.size() > 0) { for (UserLearningSequence userLearningSequence : userLearningSequences) { UserLearningSequenceResponseDto userLearningSequenceResponse = new UserLearningSequenceResponseDto(); userLearningSequenceResponse.setSequenceId(userLearningSequence.getSequenceIdentifier()); userLearningSequenceResponse.setBestGrade(userLearningSequence.getBestSequenceGrade()); userLearningSequenceResponse.setLatestGrade(userLearningSequence.getLatestSequenceGrade()); userLearningSequenceResponses.add(userLearningSequenceResponse); } } userLearningCourseResponseDto.setSequences(userLearningSequenceResponses); userLearningSummaryDtoCollection.add(userLearningCourseResponseDto); //calculate the ETAG etagStr += formatDate(userLearningCourse.getlastModifiedAt()); } userLearningCoursesResponseDto.setUserId(titanUserId); userLearningCoursesResponseDto.setCourses(userLearningSummaryDtoCollection); //the hashcode should based on the last_modify_date in database. EntityTag eTag = new EntityTag(etagStr.hashCode() + ""); //verify if it matched with etag available in http request Response.ResponseBuilder builder = request.evaluatePreconditions(eTag); //set Etag value setETag(eTag); if (builder != null) { //304 here, Not modified,directly return responseWrapper.setHttpStatusCode(Response.Status.NOT_MODIFIED.getStatusCode()); } else { //200 here, Content changed responseWrapper.setHttpStatusCode(Response.Status.OK.getStatusCode()); responseWrapper.setPayload(userLearningCoursesResponseDto); } return responseWrapper; } |
从上面的代码中,我们可以看到,ETAG的计算是把LastModifiyAt的时间相加,然后通过HashCode方法得到处理结果,然后发送给客户端。客户端再次请求发送Etag过来的时候,我们可以通过request.evaluatePreconditions(eTag)来计算当前的ETag和客户端发来的ETag是否相等,如果一致则返回304状态码,如果不一致,则表明数据库数据有变化,则直接从数据库重新获取数据,然后发送给客户端。
最后我们看看服务端如何把ETag附加给客户端:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
@Override public Response UserLearningSummaryRequest(String titanUserId,Request request) { GenericResponseWrapper<?> responseWrapper = userLearningSummaryHandlerBean .processUserLearningSummaryRequest(titanUserId, request); ResponseBuilder responseBuilder = Response.status(responseWrapper.getHttpStatusCode()); responseBuilder.entity(responseWrapper); //Send ETag back to client responseBuilder.tag(userLearningSummaryHandlerBean.getETag()); return responseBuilder.build(); } |
通过responseBuilder即可返回,responseBuilder是对Jersey的Client对象的封装。
接口调试
1.正常请求,200状态码返回:

然后我们看看Header的内容:

很清晰的看到了ETag的返回值。
2.用户ID不是UUID类型的时候,400状态码返回:

3.用户ID在数据库中不存在的时候,由于查询不到数据,404状态码返回:

4.用户附加ETag,请求相同的数据的时候,由于服务器之前返回过一致的内容了,所以这里不必再返回,直接返回304状态码提示数据未更新:

5.用户附加错误的ETag(未加双引号),导致服务端解析出错,直接返回500状态码提示错误:

深入了解EntityFramework Core 2.1延迟加载(Lazy Loading)
前言
接下来会陆续详细讲解EF Core 2.1新特性,本节我们来讲讲EF Core 2.1新特性延迟加载,如果您用过EF 6.x就知道滥用延迟加载所带来的灾难,同时呢,对此深知的童鞋到了EF Core中也就造成了极大的心里阴影面积,那么到底该不该用呢?当然,完全取决于您。
如果初学者从未接触过EF 6.x,我们知道EF 6.x默认启用了延迟加载,所以这似乎有点强人所难的意味,在EF Core 2.1对于是否启用延迟加载通过单独提供包的形式来供我们所需,二者相对而言,EF 6.x对于延迟加载的使用是不明确、含糊其辞的,而EF Core 2.1对于延迟加载是很具体、明确的,如此一来至少不会造成滥用的情况。
深入理解EF Core 2.1延迟加载
在我个人公众号发过一篇文章也通过示例讲解了EF Core延迟加载的雏形早就有了,这里再稍微给个示例解释EF Core 2.1之前延迟加载的影子在哪里呢?我们依然给出已经用烂了的两个Blog和Post这两个类,如下:

public class Blog
{
public int Id { get; set; }
public string Name { get; set; }
public string Url { get; set; }
public DateTime CreatedTime { get; set; }
public DateTime ModifiedTime { get; set; }
public byte Status { get; set; }
public bool IsDeleted { get; set; }
public ICollection<Post> Posts { get; set; } = new List<Post>();
}
public class Post
{
public int Id { get; set; }
public string Name { get; set; }
public DateTime CreatedTime { get; set; }
public DateTime ModifiedTime { get; set; }
public int? BlogId { get; set; }
public Blog Blog { get; set; }
}
接下来我们进行如下查询,我们能够看到此时并未利用Include显式加载Posts,通过如下查询EF Core内部会进行关系修正从而查询出Posts。
var dbContext = new EFCoreDbContext();
var blog = dbContext.Blogs.FirstOrDefault();
var posts = dbContext.Posts.Where(d => d.Blog.Id == blog.Id).ToList();

在EF Core 2.1中我们需要下载【Microsoft.EntityFrameworkCore.Proxies】包,同时在OnConfiguring方法中配置启用延迟加载代理,如下:

除了通过如上配置外导航属性必须用virtual关键字修饰(如上示例类未添加,请自行添加),否则将抛出异常,你懂的。接下来在完全配置好延迟加载的前提下再来进行如下查询,此时在我们需要用到Posts时才会去数据库中查询。
var dbContext = new EFCoreDbContext();
var blog = dbContext.Blogs.FirstOrDefault();
var posts = blog.Posts.ToList();


对于EF Core中的延迟加载和EF 6.x使用方式无异,接下来我们再来看看官网给出了未启用代理也可进行延迟加载,通过安装【Microsoft.EntityFrameworkCore.Abstractions 】包引用ILazyLoader服务进行实现,如下:
public class Blog
{
private ILazyLoader LazyLoader { get; set; }
public Blog(ILazyLoader lazyLoader)
{
LazyLoader = lazyLoader;
}
public int Id { get; set; }
public string Name { get; set; }
public string Url { get; set; }
public DateTime CreatedTime { get; set; }
public DateTime ModifiedTime { get; set; }
public byte Status { get; set; }
public bool IsDeleted { get; set; }
private ICollection<Post> _posts;
public ICollection<Post> Posts
{
get => LazyLoader?.Load(this, ref _posts);
set => _posts = value;
}
}
public class Post
{
private ILazyLoader LazyLoader { get; set; }
public Post(ILazyLoader lazyLoader)
{
LazyLoader = lazyLoader;
}
public int Id { get; set; }
public string Name { get; set; }
public DateTime CreatedTime { get; set; }
public DateTime ModifiedTime { get; set; }
public int? BlogId { get; set; }
private Blog _blog;
public Blog Blog
{
get => LazyLoader?.Load(this, ref _blog);
set => _blog = value;
}
}
通过如上注入ILazyLoader服务依附于实体上最终实现延迟加载,这么做对于启用延迟加载代理的最大好处在于只针对特定实体进行延迟加载,而使用延迟加载代理则是全局配置,所有实体都必须通过virtual关键字修饰且都会实现延迟加载。同时呢,通过如下图可知,此时ILazyLoader依附在上下文中也就是说一旦创建实体实例将实现延迟加载。

当然无论是EF 6.x还是EF Core 2.1进行如下查询,那么结果对于如下第二次查询的导航属性将不会再去数据库中查询,因为主体对应的导航属性在内存中已存在,此时将直接返回,也就是说主体查询两次,而依赖实体则将只执行一次查询。
var dbContext = new EFCoreDbContext();
var blog = dbContext.Blogs.FirstOrDefault();
var posts = blog.Posts.ToList();
var blog1 = dbContext.Blogs.FirstOrDefault();
var posts1 = blog1.Posts.ToList();
接下来我们再来看看在上下文实例池中启用延迟加载并结合显式加载看看EF Core执行策略是怎样的呢?
var services = new ServiceCollection();
services.AddDbContextPool<EFCoreDbContext>(options =>
{
var loggerFactory = new LoggerFactory();
loggerFactory.AddConsole(LogLevel.Debug);
options.UseLazyLoadingProxies().UseLoggerFactory(loggerFactory).UseSqlServer("data source=WANGPENG;User Id=sa;Pwd=sa123;initial catalog=EFCore2xDb;integrated security=True;MultipleActiveResultSets=True;");
});
var serviceProvider = services.BuildServiceProvider();
var dbContext = serviceProvider.GetRequiredService<EFCoreDbContext>();
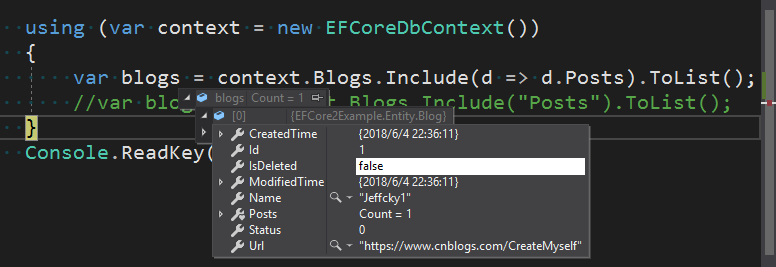
var blog = dbContext.Blogs.Include(d => d.Posts).Last();
var posts = blog.Posts.FirstOrDefault();
var blog1 = dbContext.Blogs.FirstOrDefault();
var posts1 = blog1.Posts.FirstOrDefault();




上述查询并结合最终生成的SQL得知:当没有执行显式加载时若我们启用延迟加载则强制执行延迟加载,否则执行显式加载,同时我们通过验证也得知注入ILazyLoader服务后并调用Load方法加载关联实体内部本质则是若要访问的关联实体在内存中不存在时则执行RPC加载关联实体,否则将从内存中获取。
如上所述若我们没有显式进行饥饿加载,那么在启用延迟加载的前提下对于任何关联实体是否都会执行延迟加载呢?比如复杂属性呢?我们再来看看如下示例(请自行在上述配置上下文实例池中启用延迟加载代理)。
public class StreetAddress
{
public string Street { get; set; }
public string City { get; set; }
}
public class Order
{
public int Id { get; set; }
public virtual StreetAddress ShippingAddress { get; set; }
}
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
modelBuilder.Entity<Order>(e =>
{
e.ToTable("Orders");
e.HasKey(k => k.Id);
e.OwnsOne(o => o.ShippingAddress);
});
}
var order = dbContext.Orders.FirstOrDefault();
var shippingAddress = order.ShippingAddress;

我们从如上图生成的SQL得知:对于复杂属性即通过OwnOne配置的复杂属性在查询时,EF Core会一次性将复杂属性值全部返回(也就是说复杂属性值总是会加载),所以对于启用延迟加载不会起到任何作用,即使是通过Include进行显式加载都是多此一举。
延迟加载避免循环引用
无论是EF 6.x还是EF Core 2.1中的延迟加载都无法避免循环引用问题,若在.NET Core Web应用程序中启用了延迟加载,我们需要在ConfigureServices方法中进行如下配置才行。
public void ConfigureServices(IServiceCollection services)
{
services.AddMvc().AddJsonOptions(
options => options.SerializerSettings.ReferenceLoopHandling = ReferenceLoopHandling.Ignore);
}
在写博客期间有一些童鞋在评论中留言问我是如何学习的,每个人学习方式肯定不一样,但是绝对少不了多敲代码,这里就有一个实际例子(这里不是批评那位童鞋哈),有一位童鞋购买了我写的书(首先感谢那位童鞋),看到某一章节问我那里是不是错了,我一看大概就问了那位童鞋是不是没敲代码,个人觉得无论是看技术书还是看技术博客,还是要敲一遍为好,因为那个章节的某一个类是在某一命名空间下的,估计那位童鞋没见过所以以为错了,别光顾着看,多敲敲代码验证验证总没错的。
EntityFramework 6.x和EntityFramework Core关系映射中导航属性必须是public?
前言
不知我们是否思考过一个问题,在关系映射中对于导航属性的访问修饰符是否一定必须为public呢?如果从未想过这个问题,那么我们接下来来探讨这个问题。
EF 6.x和EF Core 何种情况下必须配置映射关系?
在EF 6.x中我们创建如下示例类。
public partial class Customer
{
public int Id { get; set; }
public string Name { get; set; }
public string Email { get; set; }
public ICollection<Order> Orders { get; set; } = new List<Order>();
}
public class Order : BaseEntity
{
public int Quantity { get; set; }
public string Code { get; set; }
public decimal Price { get; set; }
public int CustomerId { get; set; }
public Customer Customer { get; set; }
}
上述我们不显式配置映射关系,EF和EF Core会根据约定来配置,同样达到如我们期望的,无论是EF 6.x还是EF Core中通过Inlcude进行显式加载有两种方式,一种是基于字符串,另外一种则是通过lamda表达式的方式(命名空间存在于System.Data.Entity),接下来我们来看下:
using (var ctx = new EfDbContext())
{
ctx.Database.Log = Console.WriteLine;
var customers = ctx.Customers.Include(d => d.Orders).ToList();
};
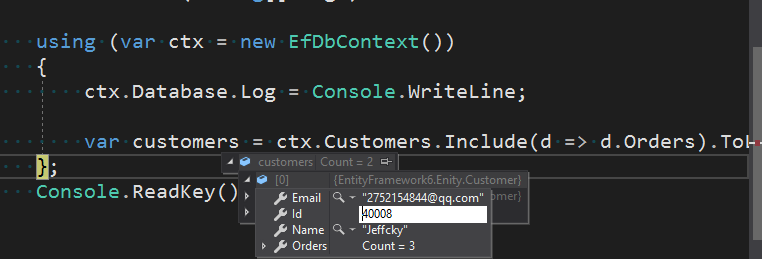
这样是我们一直以来最正常的操作,如前言所叙,那么导航属性难道必须是public吗?接下来我们来试试。我们尝试将Orders导航属性配置成如下私有的。
private ICollection<Order> Orders { get; set; } = new List<Order>();
因为其为私有,若通过lambda表达式肯定是访问受限制,那么我们改为通过基于字符串的方式来显式加载,如下:
using (var ctx = new EfDbContext())
{
ctx.Database.Log = Console.WriteLine;
var customers = ctx.Customers.Include("Orders").ToList();
};
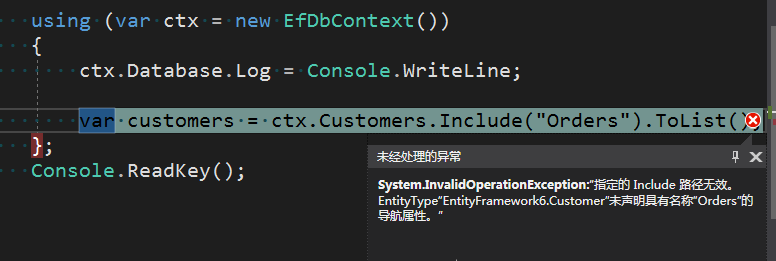
如上则抛出异常找不到Orders导航属性,是不是到此下结论而定导航属性必须是public呢?访问修饰符除了public,还有protected、internal以及protected internal。通过实践验证若导航属性为private、protected访问修饰符肯定不行,若为internal和protected internal则可以,前提是必须显式配置映射关系,否则也不行,如下:
protected internal ICollection<Order> Orders { get; set; } = new List<Order>();
HasMany(p => p.Orders).WithRequired(p => p.Customer).HasForeignKey(k => k.CustomerId);
那么在EF Core是否也和EF 6.x一样呢?我们继续来看看在EF Core中的情况,示例类为Blog和Post,这两个类已经在博客文章多次被用到,就不再给出,我们只关系导航属性访问修饰符的配置,如下:
private ICollection<Post> Posts { get; set; } = new List<Post>();
using (var context = new EFCoreDbContext())
{
var blogs = context.Blogs.Include("Posts").ToList();
}
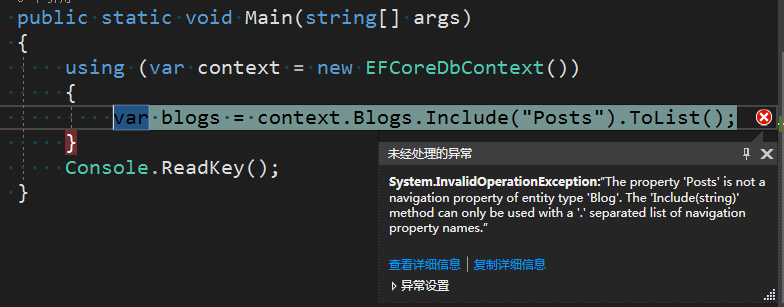
此时会同样抛出异常,只不过异常信息大意是Posts不是Blog导航属性的一部分,对于基于字符串的Include方法,导航属性名称要以点分隔开,最终结果还是是找不到Posts导航属性,接下来我们将访问修饰符改为internal看看。
internal ICollection<Post> Posts { get; set; } = new List<Post>();
using (var context = new EFCoreDbContext())
{
var blogs = context.Blogs.Include(d => d.Posts).ToList();
//var blogs1 = context.Blogs.Include("Posts").ToList();
}
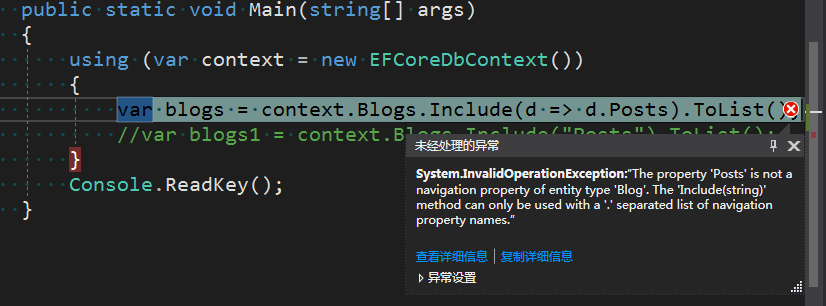
此时我们再来显式配置映射关系则好使。
builder.HasMany(m => m.Posts)
.WithOne(o => o.Blog);
总结
对于EF和EF Core中通过Include方法进行显式加载具体实现没有去看源码,完全通过实践得到的结论是:无论是EntityFramework还是EntityFramework Core,在关系映射中导航属性不一定必须是public修饰符,也可以为internal和protected internal,但是前提是必须显式配置映射关系,否则将抛出无法找到导航属性异常。
藏在正则表达式里的陷阱
文章首发于【博客园-陈树义】,点击跳转到原文《藏在正则表达式里的陷阱》
前几天线上一个项目监控信息突然报告异常,上到机器上后查看相关资源的使用情况,发现 CPU 利用率将近 100%。通过 Java 自带的线程 Dump 工具,我们导出了出问题的堆栈信息。
![]()
我们可以看到所有的堆栈都指向了一个名为 validateUrl 的方法,这样的报错信息在堆栈中一共超过 100 处。通过排查代码,我们知道这个方法的主要功能是校验 URL 是否合法。
很奇怪,一个正则表达式怎么会导致 CPU 利用率居高不下。为了弄清楚复现问题,我们将其中的关键代码摘抄出来,做了个简单的单元测试。
public static void main(String[] args) {
String badRegex = "^([hH][tT]{2}[pP]://|[hH][tT]{2}[pP][sS]://)(([A-Za-z0-9-~]+).)+([A-Za-z0-9-~\\\\/])+$";
String bugUrl = "http://www.fapiao.com/dddp-web/pdf/download?request=6e7JGxxxxx4ILd-kExxxxxxxqJ4-CHLmqVnenXC692m74H38sdfdsazxcUmfcOH2fAfY1Vw__%5EDadIfJgiEf";
if (bugUrl.matches(badRegex)) {
System.out.println("match!!");
} else {
System.out.println("no match!!");
}
}当我们运行上面这个例子的时候,通过资源监视器可以看到有一个名为 java 的进程 CPU 利用率直接飙升到了 91.4% 。
![]()
看到这里,我们基本可以推断,这个正则表达式就是导致 CPU 利用率居高不下的凶手!
于是,我们将排错的重点放在了那个正则表达式上:
^([hH][tT]{2}[pP]://|[hH][tT]{2}[pP][sS]://)(([A-Za-z0-9-~]+).)+([A-Za-z0-9-~\\/])+$这个正则表达式看起来没什么问题,可以分为三个部分:
第一部分匹配 http 和 https 协议,第二部分匹配 www. 字符,第三部分匹配许多字符。我看着这个表达式发呆了许久,也没发现没有什么大的问题。
其实这里导致 CPU 使用率高的关键原因就是:Java 正则表达式使用的引擎实现是 NFA 自动机,这种正则表达式引擎在进行字符匹配时会发生回溯(backtracking)。而一旦发生回溯,那其消耗的时间就会变得很长,有可能是几分钟,也有可能是几个小时,时间长短取决于回溯的次数和复杂度。
看到这里,可能大家还不是很清楚什么是回溯,还有点懵。没关系,我们一点点从正则表达式的原理开始讲起。
正则表达式引擎
正则表达式是一个很方便的匹配符号,但要实现这么复杂,功能如此强大的匹配语法,就必须要有一套算法来实现,而实现这套算法的东西就叫做正则表达式引擎。简单地说,实现正则表达式引擎的有两种方式:DFA 自动机(Deterministic Final Automata 确定型有穷自动机)和 NFA 自动机(Non deterministic Finite Automaton 不确定型有穷自动机)。
对于这两种自动机,他们有各自的区别,这里并不打算深入将它们的原理。简单地说,DFA 自动机的时间复杂度是线性的,更加稳定,但是功能有限。而 NFA 的时间复杂度比较不稳定,有时候很好,有时候不怎么好,好不好取决于你写的正则表达式。但是胜在 NFA 的功能更加强大,所以包括 Java 、.NET、Perl、Python、Ruby、PHP 等语言都使用了 NFA 去实现其正则表达式。
那 NFA 自动机到底是怎么进行匹配的呢?我们以下面的字符和表达式来举例说明。
text="Today is a nice day."
regex="day"要记住一个很重要的点,即:NFA 是以正则表达式为基准去匹配的。也就是说,NFA 自动机会读取正则表达式的一个一个字符,然后拿去和目标字符串匹配,匹配成功就换正则表达式的下一个字符,否则继续和目标字符串的下一个字符比较。或许你们听不太懂,没事,接下来我们以上面的例子一步步解析。
- 首先,拿到正则表达式的第一个匹配符:d。于是那去和字符串的字符进行比较,字符串的第一个字符是 T,不匹配,换下一个。第二个是 o,也不匹配,再换下一个。第三个是 d,匹配了,那么就读取正则表达式的第二个字符:a。
- 读取到正则表达式的第二个匹配符:a。那着继续和字符串的第四个字符 a 比较,又匹配了。那么接着读取正则表达式的第三个字符:y。
- 读取到正则表达式的第三个匹配符:y。那着继续和字符串的第五个字符 y 比较,又匹配了。尝试读取正则表达式的下一个字符,发现没有了,那么匹配结束。
上面这个匹配过程就是 NFA 自动机的匹配过程,但实际上的匹配过程会比这个复杂非常多,但其原理是不变的。
文章首发于【博客园-陈树义】,点击跳转到原文《藏在正则表达式里的陷阱》
NFA自动机的回溯
了解了 NFA 是如何进行字符串匹配的,接下来我们就可以讲讲这篇文章的重点了:回溯。为了更好地解释回溯,我们同样以下面的例子来讲解。
text="abbc"
regex="ab{1,3}c"上面的这个例子的目的比较简单,匹配以 a 开头,以 c 结尾,中间有 1-3 个 b 字符的字符串。NFA 对其解析的过程是这样子的:
- 首先,读取正则表达式第一个匹配符 a 和 字符串第一个字符 a 比较,匹配了。于是读取正则表达式第二个字符。
- 读取正则表达式第二个匹配符 b{1,3} 和字符串的第二个字符 b 比较,匹配了。但因为 b{1,3} 表示 1-3 个 b 字符串,以及 NFA 自动机的贪婪特性(也就是说要尽可能多地匹配),所以此时并不会再去读取下一个正则表达式的匹配符,而是依旧使用 b{1,3} 和字符串的第三个字符 b 比较,发现还是匹配。于是继续使用 b{1,3} 和字符串的第四个字符 c 比较,发现不匹配了。此时就会发生回溯。
- 发生回溯是怎么操作呢?发生回溯后,我们已经读取的字符串第四个字符 c 将被吐出去,指针回到第三个字符串的位置。之后,程序读取正则表达式的下一个操作符 c,读取当前指针的下一个字符 c 进行对比,发现匹配。于是读取下一个操作符,但这里已经结束了。
下面我们回过头来看看前面的那个校验 URL 的正则表达式:
^([hH][tT]{2}[pP]://|[hH][tT]{2}[pP][sS]://)(([A-Za-z0-9-~]+).)+([A-Za-z0-9-~\\/])+$出现问题的 URL 是:
http://www.fapiao.com/dzfp-web/pdf/download?request=6e7JGm38jfjghVrv4ILd-kEn64HcUX4qL4a4qJ4-CHLmqVnenXC692m74H5oxkjgdsYazxcUmfcOH2fAfY1Vw__%5EDadIfJgiEf我们把这个正则表达式分为三个部分:
- 第一部分:校验协议。
^([hH][tT]{2}[pP]://|[hH][tT]{2}[pP][sS]://)。 - 第二部分:校验域名。
(([A-Za-z0-9-~]+).)+。 - 第三部分:校验参数。
([A-Za-z0-9-~\\/])+$。
我们可以发现正则表达式校验协议 http:// 这部分是没有问题的,但是在校验 www.fapiao.com 的时候,其使用了 xxxx. 这种方式去校验。那么其实匹配过程是这样的:
- 匹配到 www.
- 匹配到 fapiao.
- 匹配到
com/dzfp-web/pdf/download?request=6e7JGm38jf.....,你会发现因为贪婪匹配的原因,所以程序会一直读后面的字符串进行匹配,最后发现没有点号,于是就一个个字符回溯回去了。
这是这个正则表达式存在的第一个问题。
另外一个问题是在正则表达式的第三部分,我们发现出现问题的 URL 是有下划线(_)和百分号(%)的,但是对应第三部分的正则表达式里面却没有。这样就会导致前面匹配了一长串的字符之后,发现不匹配,最后回溯回去。
这是这个正则表达式存在的第二个问题。
解决方案
明白了回溯是导致问题的原因之后,其实就是减少这种回溯,你会发现如果我在第三部分加上下划线和百分号之后,程序就正常了。
public static void main(String[] args) {
String badRegex = "^([hH][tT]{2}[pP]://|[hH][tT]{2}[pP][sS]://)(([A-Za-z0-9-~]+).)+([A-Za-z0-9-~_%\\\\/])+$";
String bugUrl = "http://www.fapiao.com/dddp-web/pdf/download?request=6e7JGxxxxx4ILd-kExxxxxxxqJ4-CHLmqVnenXC692m74H38sdfdsazxcUmfcOH2fAfY1Vw__%5EDadIfJgiEf";
if (bugUrl.matches(badRegex)) {
System.out.println("match!!");
} else {
System.out.println("no match!!");
}
}运行上面的程序,立刻就会打印出match!!。
但这是不够的,如果以后还有其他 URL 包含了乱七八糟的字符呢,我们难不成还再修改一遍。肯定不现实嘛!
其实在正则表达式中有这么三种模式:贪婪模式、懒惰模式、独占模式。
在关于数量的匹配中,有 + ? * {min,max} 四种两次,如果只是单独使用,那么它们就是贪婪模式。
如果在他们之后加多一个 ? 符号,那么原先的贪婪模式就会变成懒惰模式,即尽可能少地匹配。但是懒惰模式还是会发生回溯现象的。TODO例如下面这个例子:
text="abbc"
regex="ab{1,3}?c"正则表达式的第一个操作符 a 与 字符串第一个字符 a 匹配,匹配成。于是正则表达式的第二个操作符 b{1,3}? 和 字符串第二个字符 b 匹配,匹配成功。因为最小匹配原则,所以拿正则表达式第三个操作符 c 与字符串第三个字符 b 匹配,发现不匹配。于是回溯回去,拿正则表达式第二个操作符 b{1,3}? 和字符串第三个字符 b 匹配,匹配成功。于是再拿正则表达式第三个操作符 c 与字符串第四个字符 c 匹配,匹配成功。于是结束。
如果在他们之后加多一个 + 符号,那么原先的贪婪模式就会变成独占模式,即尽可能多地匹配,但是不回溯。
于是乎,如果要彻底解决问题,就要在保证功能的同时确保不发生回溯。我将上面校验 URL 的正则表达式的第二部分后面加多了个 + 号,即变成这样:
^([hH][tT]{2}[pP]://|[hH][tT]{2}[pP][sS]://)
(([A-Za-z0-9-~]+).)++ --->>> (这里加了个+号)
([A-Za-z0-9-~\\/])+$这样之后,运行原有的程序就没有问题了。
最后推荐一个网站,这个网站可以检查你写的正则表达式和对应的字符串匹配时会不会有问题。
Online regex tester and debugger: PHP, PCRE, Python, Golang and JavaScript
例如我本文中存在问题的那个 URL 使用该网站检查后会提示:catastrophic backgracking(灾难性回溯)。
![]()
当你点击左下角的「regex debugger」时,它会告诉你一共经过多少步检查完毕,并且会将所有步骤都列出来,并标明发生回溯的位置。
![]()
本文中的这个正则表达式在进行了 11 万步尝试之后,自动停止了。这说明这个正则表达式确实存在问题,需要改进。
但是当我用我们修改过的正则表达式进行测试,即下面这个正则表达式。
^([hH][tT]{2}[pP]:\/\/|[hH][tT]{2}[pP][sS]:\/\/)(([A-Za-z0-9-~]+).)++([A-Za-z0-9-~\\\/])+$工具提示只用了 58 步就完成了检查。
![]()
一个字符的差别,性能就差距了好几万倍。
树义有话说
一个小小的正则表达式竟然能够把 CPU 拖垮,也是很神奇了。这也给平时写程序的我们一个警醒,遇到正则表达式的时候要注意贪婪模式和回溯问题,否则我们每写的一个表达式都是一个雷。
通过查阅网上资料,我发现深圳阿里中心 LAZADA 的同学也在 17 年遇到了这个问题。他们同样也是在测试环境没有发现问题,但是一到线上的时候就发生了 CPU 100% 的问题,他们遇到的问题几乎跟我们的一模一样。有兴趣的朋友可以点击阅读原文查看他们后期总结的文章:一个由正则表达式引发的血案 - 明志健致远 - 博客园
虽然把这篇文章写完了,但是关于 NFA 自动机的原理方面,特别是关于懒惰模式、独占模式的解释方面还是没有解释得足够深入。因为 NFA 自动机确实不是那么容易理解,所以在这方面还需要不断学习加强。欢迎有懂行的朋友来学习交流,互相促进。
文章首发于【博客园-陈树义】,点击跳转到原文《藏在正则表达式里的陷阱》
关键词:正则表达式(regex express)、CPU异常(cpu abnormal)、100%CPU、回溯陷阱(backtracking)。
两道面试题,带你解析Java类加载机制
文章首发于【博客园-陈树义】,点击跳转到原文《两道面试题,带你解析Java类加载机制》
在许多Java面试中,我们经常会看到关于Java类加载机制的考察,例如下面这道题:
class Grandpa
{
static
{
System.out.println("爷爷在静态代码块");
}
}
class Father extends Grandpa
{
static
{
System.out.println("爸爸在静态代码块");
}
public static int factor = 25;
public Father()
{
System.out.println("我是爸爸~");
}
}
class Son extends Father
{
static
{
System.out.println("儿子在静态代码块");
}
public Son()
{
System.out.println("我是儿子~");
}
}
public class InitializationDemo
{
public static void main(String[] args)
{
System.out.println("爸爸的岁数:" + Son.factor); //入口
}
}请写出最后的输出字符串。
正确答案是:
爷爷在静态代码块
爸爸在静态代码块
爸爸的岁数:25我相信很多同学看到这个题目之后,表情是崩溃的,完全不知道从何入手。有的甚至遇到了几次,仍然无法找到正确的解答思路。
其实这种面试题考察的就是你对Java类加载机制的理解。
如果你对Java加载机制不理解,那么你是无法解答这道题目的。
所以这篇文章,我先带大家学习Java类加载的基础知识,然后再实战分析几道题目让大家掌握思路。
下面我们先来学习下Java类加载机制的七个阶段。
Java类加载机制的七个阶段
当我们的Java代码编译完成后,会生成对应的 class 文件。接着我们运行java Demo命令的时候,我们其实是启动了JVM 虚拟机执行 class 字节码文件的内容。而 JVM 虚拟机执行 class 字节码的过程可以分为七个阶段:加载、验证、准备、解析、初始化、使用、卸载。
加载
下面是对于加载过程最为官方的描述。
加载阶段是类加载过程的第一个阶段。在这个阶段,JVM 的主要目的是将字节码从各个位置(网络、磁盘等)转化为二进制字节流加载到内存中,接着会为这个类在 JVM 的方法区创建一个对应的 Class 对象,这个 Class 对象就是这个类各种数据的访问入口。
其实加载阶段用一句话来说就是:把代码数据加载到内存中。这个过程对于我们解答这道问题没有直接的关系,但这是类加载机制的一个过程,所以必须要提一下。
验证
当 JVM 加载完 Class 字节码文件并在方法区创建对应的 Class 对象之后,JVM 便会启动对该字节码流的校验,只有符合 JVM 字节码规范的文件才能被 JVM 正确执行。这个校验过程大致可以分为下面几个类型:
- JVM规范校验。JVM 会对字节流进行文件格式校验,判断其是否符合 JVM 规范,是否能被当前版本的虚拟机处理。例如:文件是否是以
0x cafe bene开头,主次版本号是否在当前虚拟机处理范围之内等。 - 代码逻辑校验。JVM 会对代码组成的数据流和控制流进行校验,确保 JVM 运行该字节码文件后不会出现致命错误。例如一个方法要求传入 int 类型的参数,但是使用它的时候却传入了一个 String 类型的参数。一个方法要求返回 String 类型的结果,但是最后却没有返回结果。代码中引用了一个名为 Apple 的类,但是你实际上却没有定义 Apple 类。
当代码数据被加载到内存中后,虚拟机就会对代码数据进行校验,看看这份代码是不是真的按照JVM规范去写的。这个过程对于我们解答问题也没有直接的关系,但是了解类加载机制必须要知道有这个过程。
准备(重点)
当完成字节码文件的校验之后,JVM 便会开始为类变量分配内存并初始化。这里需要注意两个关键点,即内存分配的对象以及初始化的类型。
- 内存分配的对象。Java 中的变量有「类变量」和「类成员变量」两种类型,「类变量」指的是被 static 修饰的变量,而其他所有类型的变量都属于「类成员变量」。在准备阶段,JVM 只会为「类变量」分配内存,而不会为「类成员变量」分配内存。「类成员变量」的内存分配需要等到初始化阶段才开始。
例如下面的代码在准备阶段,只会为 factor 属性分配内存,而不会为 website 属性分配内存。
public static int factor = 3;
public String website = "www.cnblogs.com/chanshuyi";- 初始化的类型。在准备阶段,JVM 会为类变量分配内存,并为其初始化。但是这里的初始化指的是为变量赋予 Java 语言中该数据类型的零值,而不是用户代码里初始化的值。
例如下面的代码在准备阶段之后,sector 的值将是 0,而不是 3。
public static int sector = 3;但如果一个变量是常量(被 static final 修饰)的话,那么在准备阶段,属性便会被赋予用户希望的值。例如下面的代码在准备阶段之后,number 的值将是 3,而不是 0。
public static final int number = 3;之所以 static final 会直接被复制,而 static 变量会被赋予零值。其实我们稍微思考一下就能想明白了。
两个语句的区别是一个有 final 关键字修饰,另外一个没有。而 final 关键字在 Java 中代表不可改变的意思,意思就是说 number 的值一旦赋值就不会在改变了。既然一旦赋值就不会再改变,那么就必须一开始就给其赋予用户想要的值,因此被 final 修饰的类变量在准备阶段就会被赋予想要的值。而没有被 final 修饰的类变量,其可能在初始化阶段或者运行阶段发生变化,所以就没有必要在准备阶段对它赋予用户想要的值。
解析
当通过准备阶段之后,JVM 针对类或接口、字段、类方法、接口方法、方法类型、方法句柄和调用点限定符 7 类引用进行解析。这个阶段的主要任务是将其在常量池中的符号引用替换成直接其在内存中的直接引用。
其实这个阶段对于我们来说也是几乎透明的,了解一下就好。
初始化(重点)
到了初始化阶段,用户定义的 Java 程序代码才真正开始执行。在这个阶段,JVM 会根据语句执行顺序对类对象进行初始化,一般来说当 JVM 遇到下面 5 种情况的时候会触发初始化:
- 遇到 new、getstatic、putstatic、invokestatic 这四条字节码指令时,如果类没有进行过初始化,则需要先触发其初始化。生成这4条指令的最常见的Java代码场景是:使用new关键字实例化对象的时候、读取或设置一个类的静态字段(被final修饰、已在编译器把结果放入常量池的静态字段除外)的时候,以及调用一个类的静态方法的时候。
- 使用 java.lang.reflect 包的方法对类进行反射调用的时候,如果类没有进行过初始化,则需要先触发其初始化。
- 当初始化一个类的时候,如果发现其父类还没有进行过初始化,则需要先触发其父类的初始化。
- 当虚拟机启动时,用户需要指定一个要执行的主类(包含main()方法的那个类),虚拟机会先初始化这个主类。
- 当使用 JDK1.7 动态语言支持时,如果一个 java.lang.invoke.MethodHandle实例最后的解析结果 REF_getstatic,REF_putstatic,REF_invokeStatic 的方法句柄,并且这个方法句柄所对应的类没有进行初始化,则需要先出触发其初始化。
看到上面几个条件你可能会晕了,但是不要紧,不需要背,知道一下就好,后面用到的时候回到找一下就可以了。
使用
当 JVM 完成初始化阶段之后,JVM 便开始从入口方法开始执行用户的程序代码。这个阶段也只是了解一下就可以。
卸载
当用户程序代码执行完毕后,JVM 便开始销毁创建的 Class 对象,最后负责运行的 JVM 也退出内存。这个阶段也只是了解一下就可以。
看完了Java的类加载机智之后,是不是有点懵呢。不怕,我们先通过一个小例子来醒醒神。
public class Book {
public static void main(String[] args)
{
System.out.println("Hello ShuYi.");
}
Book()
{
System.out.println("书的构造方法");
System.out.println("price=" + price +",amount=" + amount);
}
{
System.out.println("书的普通代码块");
}
int price = 110;
static
{
System.out.println("书的静态代码块");
}
static int amount = 112;
}思考一下上面这段代码输出什么?
给你5分钟思考,5分钟后交卷,哈哈。
怎么样,想好了吗,公布答案了。
书的静态代码块
Hello ShuYi.怎么样,你答对了吗?是不是和你想得有点不一样呢。
下面我们来简单分析一下,首先根据上面说到的触发初始化的5种情况的第4种(当虚拟机启动时,用户需要指定一个要执行的主类(包含main()方法的那个类),虚拟机会先初始化这个主类),我们会进行类的初始化。
那么类的初始化顺序到底是怎么样的呢?
重点来了!
重点来了!
重点来了!
在我们代码中,我们只知道有一个构造方法,但实际上Java代码编译成字节码之后,是没有构造方法的概念的,只有类初始化方法 和 对象初始化方法 。
那么这两个方法是怎么来的呢?
- 类初始化方法。编译器会按照其出现顺序,收集类变量的赋值语句、静态代码块,最终组成类初始化方法。类初始化方法一般在类初始化的时候执行。
上面的这个例子,其类初始化方法就是下面这段代码了:
static
{
System.out.println("书的静态代码块");
}
static int amount = 112;- 对象初始化方法。编译器会按照其出现顺序,收集成员变量的赋值语句、普通代码块,最后收集构造函数的代码,最终组成对象初始化方法。对象初始化方法一般在实例化类对象的时候执行。
上面这个例子,其对象初始化方法就是下面这段代码了:
{
System.out.println("书的普通代码块");
}
int price = 110;
System.out.println("书的构造方法");
System.out.println("price=" + price +",amount=" + amount);类初始化方法 和 对象初始化方法 之后,我们再来看这个例子,我们就不难得出上面的答案了。
但细心的朋友一定会发现,其实上面的这个例子其实没有执行对象初始化方法。
因为我们确实没有进行 Book 类对象的实例化。如果你在 main 方法中增加 new Book() 语句,你会发现对象的初始化方法执行了!
感兴趣的朋友可以自己动手试一下,我这里就不执行了。
通过了上面的理论和简单例子,我们下面进入更加复杂的实战分析吧!
实战分析
class Grandpa
{
static
{
System.out.println("爷爷在静态代码块");
}
}
class Father extends Grandpa
{
static
{
System.out.println("爸爸在静态代码块");
}
public static int factor = 25;
public Father()
{
System.out.println("我是爸爸~");
}
}
class Son extends Father
{
static
{
System.out.println("儿子在静态代码块");
}
public Son()
{
System.out.println("我是儿子~");
}
}
public class InitializationDemo
{
public static void main(String[] args)
{
System.out.println("爸爸的岁数:" + Son.factor); //入口
}
}思考一下,上面的代码最后的输出结果是什么?
最终的输出结果是:
爷爷在静态代码块
爸爸在静态代码块
爸爸的岁数:25也许会有人问为什么没有输出「儿子在静态代码块」这个字符串?
这是因为对于静态字段,只有直接定义这个字段的类才会被初始化(执行静态代码块)。因此通过其子类来引用父类中定义的静态字段,只会触发父类的初始化而不会触发子类的初始化。
对面上面的这个例子,我们可以从入口开始分析一路分析下去:
- 首先程序到 main 方法这里,使用标准化输出 Son 类中的 factor 类成员变量,但是 Son 类中并没有定义这个类成员变量。于是往父类去找,我们在 Father 类中找到了对应的类成员变量,于是触发了 Father 的初始化。
- 但根据我们上面说到的初始化的 5 种情况中的第 3 种(当初始化一个类的时候,如果发现其父类还没有进行过初始化,则需要先触发其父类的初始化)。我们需要先初始化 Father 类的父类,也就是先初始化 Grandpa 类再初始化 Father 类。于是我们先初始化 Grandpa 类输出:「爷爷在静态代码块」,再初始化 Father 类输出:「爸爸在静态代码块」。
- 最后,所有父类都初始化完成之后,Son 类才能调用父类的静态变量,从而输出:「爸爸的岁数:25」。
怎么样,是不是觉得豁然开朗呢。
我们再来看一下一个更复杂点的例子,看看输出结果是啥。
class Grandpa
{
static
{
System.out.println("爷爷在静态代码块");
}
public Grandpa() {
System.out.println("我是爷爷~");
}
}
class Father extends Grandpa
{
static
{
System.out.println("爸爸在静态代码块");
}
public Father()
{
System.out.println("我是爸爸~");
}
}
class Son extends Father
{
static
{
System.out.println("儿子在静态代码块");
}
public Son()
{
System.out.println("我是儿子~");
}
}
public class InitializationDemo
{
public static void main(String[] args)
{
new Son(); //入口
}
}输出结果是:
爷爷在静态代码块
爸爸在静态代码块
儿子在静态代码块
我是爷爷~
我是爸爸~
我是儿子~文章首发于【博客园-陈树义】,点击跳转到原文《两道面试题,带你解析Java类加载机制》
怎么样,是不是觉得这道题和上面的有所不同呢。
让我们仔细来分析一下上面代码的执行流程:
- 首先在入口这里我们实例化一个 Son 对象,因此会触发 Son 类的初始化,而 Son 类的初始化又会带动 Father 、Grandpa 类的初始化,从而执行对应类中的静态代码块。因此会输出:「爷爷在静态代码块」、「爸爸在静态代码块」、「儿子在静态代码块」。
- 当 Son 类完成初始化之后,便会调用 Son 类的构造方法,而 Son 类构造方法的调用同样会带动 Father、Grandpa 类构造方法的调用,最后会输出:「我是爷爷~」、「我是爸爸~」、「我是儿子~」。
看完了两个例子之后,相信大家都胸有成足了吧。
下面给大家看一个特殊点的例子,有点难哦!
public class Book {
public static void main(String[] args)
{
staticFunction();
}
static Book book = new Book();
static
{
System.out.println("书的静态代码块");
}
{
System.out.println("书的普通代码块");
}
Book()
{
System.out.println("书的构造方法");
System.out.println("price=" + price +",amount=" + amount);
}
public static void staticFunction(){
System.out.println("书的静态方法");
}
int price = 110;
static int amount = 112;
}上面这个例子的输出结果是:
书的普通代码块
书的构造方法
price=110,amount=0
书的静态代码块
书的静态方法下面我们一步步来分析一下代码的整个执行流程。
在上面两个例子中,因为 main 方法所在类并没有多余的代码,我们都直接忽略了 main 方法所在类的初始化。
但在这个例子中,main 方法所在类有许多代码,我们就并不能直接忽略了。
- 当 JVM 在准备阶段的时候,便会为类变量分配内存和进行初始化。此时,我们的 book 实例变量被初始化为 null,amount 变量被初始化为 0。
- 当进入初始化阶段后,因为 Book 方法是程序的入口,根据我们上面说到的类初始化的五种情况的第四种(当虚拟机启动时,用户需要指定一个要执行的主类(包含main()方法的那个类),虚拟机会先初始化这个主类)。所以JVM 会初始化 Book 类,即执行类构造器 。
- JVM 对 Book 类进行初始化首先是执行类构造器(按顺序收集类中所有静态代码块和类变量赋值语句就组成了类构造器 ),后执行对象的构造器(按顺序收集成员变量赋值和普通代码块,最后收集对象构造器,最终组成对象构造器 )。
对于 Book 类,其类构造方法()可以简单表示如下:
static Book book = new Book();
static
{
System.out.println("书的静态代码块");
}
static int amount = 112;于是首先执行static Book book = new Book();这一条语句,这条语句又触发了类的实例化。于是 JVM 执行对象构造器 ,收集后的对象构造器 代码:
{
System.out.println("书的普通代码块");
}
int price = 110;
Book()
{
System.out.println("书的构造方法");
System.out.println("price=" + price +", amount=" + amount);
}于是此时 price 赋予 110 的值,输出:「书的普通代码块」、「书的构造方法」。而此时 price 为 110 的值,而 amount 的赋值语句并未执行,所以只有在准备阶段赋予的零值,所以之后输出「price=110,amount=0」。
当类实例化完成之后,JVM 继续进行类构造器的初始化:
static Book book = new Book(); //完成类实例化
static
{
System.out.println("书的静态代码块");
}
static int amount = 112;即输出:「书的静态代码块」,之后对 amount 赋予 112 的值。
- 到这里,类的初始化已经完成,JVM 执行 main 方法的内容。
public static void main(String[] args)
{
staticFunction();
}即输出:「书的静态方法」。
方法论
从上面几个例子可以看出,分析一个类的执行顺序大概可以按照如下步骤:
- 确定类变量的初始值。在类加载的准备阶段,JVM 会为类变量初始化零值,这时候类变量会有一个初始的零值。如果是被 final 修饰的类变量,则直接会被初始成用户想要的值。
- 初始化入口方法。当进入类加载的初始化阶段后,JVM 会寻找整个 main 方法入口,从而初始化 main 方法所在的整个类。当需要对一个类进行初始化时,会首先初始化类构造器(),之后初始化对象构造器()。
- 初始化类构造器。JVM 会按顺序收集类变量的赋值语句、静态代码块,最终组成类构造器由 JVM 执行。
- 初始化对象构造器。JVM 会按照收集成员变量的赋值语句、普通代码块,最后收集构造方法,将它们组成对象构造器,最终由 JVM 执行。
如果在初始化 main 方法所在类的时候遇到了其他类的初始化,那么就先加载对应的类,加载完成之后返回。如此反复循环,最终返回 main 方法所在类。
树义有话说
看完了上面的解析之后,再去看看开头那道题是不是觉得简单多了呢。很多东西就是这样,掌握了一定的方法和知识之后,原本困难的东西也变得简单许多了。
一时没有看懂也不要灰心,毕竟我也是用了不少的时间才弄懂的。不懂的话可以多看几遍,或者加入树义的技术交流群,和小伙们一起交流。

