你真的了解字典(Dictionary)吗? C# Memory Cache 踩坑记录 .net 泛型 结构化CSS设计思维 WinForm POST上传与后台接收 高效实用的.NET开源项目 .net 笔试面试总结(3) .net 笔试面试总结(2) 依赖注入 C# RSA 加密 C#与Java AES 加密解密
你真的了解字典(Dictionary)吗?
从一道亲身经历的面试题说起
半年前,我参加我现在所在公司的面试,面试官给了一道题,说有一个Y形的链表,知道起始节点,找出交叉节点.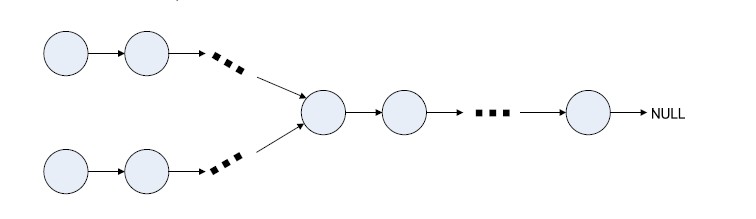
为了便于描述,我把上面的那条线路称为线路1,下面的称为线路2.
思路1
先判断线路1的第一个节点的下级节点是否是线路2的第一个节点,如果不是,再判断是不是线路2的第二个,如果也不是,判断是不是第三个节点,一直到最后一个.
如果第一轮没找到,再按以上思路处理线路一的第二个节点,第三个,第四个... 找到为止.
时间复杂度n2,相信如果我用的是这种方法,可肯定被Pass了.
思路2
首先,我遍历线路2的所有节点,把节点的索引作为key,下级节点索引作为value存入字典中.
然后,遍历线路1中节点,判断字典中是否包含该节点的下级节点索引的key,即dic.ContainsKey((node.next) ,如果包含,那么该下级节点就是交叉节点了.
时间复杂度是n.
那么问题来了,面试官问我了,为什么时间复杂度n呢?你有没有研究过字典的ContainsKey这个方法呢?难道它不是通过遍历内部元素来判断Key是否存在的呢?如果是的话,那时间复杂度还是n2才是呀?
我当时支支吾吾,确实不明白字典的工作原理,厚着面皮说 "不是的,它是通过哈希表直接拿出来的,不用遍历",面试官这边是敷衍过去了,但在我心里却留下了一个谜,已经入职半年多了,欠下的技术债是时候还了.
带着问题来阅读
在看这篇文章前,不知道您使用字典的时候是否有过这样的疑问.
- 字典为什么能无限地Add呢?
- 从字典中取Item速度非常快,为什么呢?
- 初始化字典可以指定字典容量,这是否多余呢?
- 字典的桶
buckets长度为素数,为什么呢?
不管您以前有没有在心里问过自己这些问题,也不管您是否已经有了自己得答案,都让我们带着这几个问题接着往下走.
从哈希函数说起
什么是哈希函数?
哈希函数又称散列函数,是一种从任何一种数据中创建小的数字“指纹”的方法。
下面,我们看看JDK中Sting.GetHashCode()方法.
public int hashCode() {
int h = hash;
//hash default value : 0
if (h == 0 && value.length > 0) {
//value : char storage
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
可以看到,无论多长的字符串,最终都会返回一个int值,当哈希函数确定的情况下,任何一个字符串的哈希值都是唯一且确定的.
当然,这里只是找了一种最简单的字符数哈希值求法,理论上只要能把一个对象转换成唯一且确定值的函数,我们都可以把它称之为哈希函数.
这是哈希函数的示意图.
所以,一个对象的哈希值是确定且唯一的!.
字典
如何把哈希值和在集合中我们要的数据的地址关联起来呢?解开这个疑惑前我来看看一个这样不怎么恰当的例子:
有一天,我不小心干了什么坏事,警察叔叔没有逮到我本人,但是他知道是一个叫阿宇的干的,他要找我肯定先去我家,他怎么知道我家的地址呢?他不可能在全中国的家庭一个个去遍历,敲门,问阿宇是你们家的熊孩子吗?
正常应该是通过我的名字,找到我的身份证号码,然后我的身份证上登记着我的家庭地址(我们假设一个名字只能找到一张身份证).
阿宇-----> 身份证(身份证号码,家庭住址)------>我家
我们就可以把由阿宇找到身份证号码的过程,理解为哈希函数,身份证存储着我的号码的同时,也存储着我家的地址,身份证这个角色在字典中就是 bucket,它起一个桥梁作用,当有人要找阿宇家在哪时,直接问它,准备错的,字典中,bucket存储着数据的内存地址(索引),我们要知道key对应的数据的内存地址,问buckets要就对了.
key--->bucket的过程 ~= 阿宇----->身份证 的过程.
警察叔叔通过家庭住址找到了我家之后,我家除了住我,还住着我爸,我妈,他敲门的时候,是我爸开门,于是问我爸爸,阿宇在哪,我爸不知道,我爸便问我妈,儿子在哪?我妈告诉警察叔叔,我在书房呢.很好,警察叔叔就这样把我给逮住了.
字典也是这样,因为key的哈希值范围很大的,我们不可能声明一个这么大的数组作为buckets,这样就太浪费了,我们做法时HashCode%BucketSize作为bucket的索引.
假设Bucket的长度3,那么当key1的HashCode为2时,它数据地址就问buckets2要,当key2的HashCode为5时,它的数据地址也是问buckets2要的.
这就导致同一个bucket可能有多个key对应,即下图中的Johon Smith和Sandra Dee,但是bucket只能记录一个内存地址(索引),也就是警察叔叔通过家庭地址找到我家时,正常来说,只有一个人过来开门,那么,如何找到也在这个家里的我的呢?我爸记录这我妈在厨房,我妈记录着我在书房,就这样,我就被揪出来了,我爸,我妈,我 就是字典中的一个entry.

如果有一天,我妈妈老来得子又生了一个小宝宝,怎么办呢?很简单,我妈记录小宝宝的位置,那么我的只能巴结小宝宝,让小宝宝来记录我的位置了.

既然大的原理明白了,是不是要看看源码,来研究研究代码中字典怎么实现的呢?
DictionaryMini
上次在苏州参加苏州微软技术俱乐部成立大会时,有幸参加了蒋金楠 老师讲的Asp .net core框架解密,蒋老师有句话让我印象很深刻,"学好一门技术的最好的方法,就是模仿它的样子,自己造一个出来"于是他弄了个Asp .net core mini,所以我效仿蒋老师,弄了个DictionaryMini
其源代码我放在了Github仓库,有兴趣的可以看看:https://github.com/liuzhenyulive/DictionaryMini
我觉得字典这几个方面值得了解一下:
- 数据存储的最小单元的数据结构
- 字典的初始化
- 添加新元素
- 字典的扩容
- 移除元素
字典中还有其他功能,但我相信,只要弄明白的这几个方面的工作原理,我们也就恰中肯綮,他么问题也就迎刃而解了.
数据存储的最小单元(Entry)的数据结构
private struct Entry
{
public int HashCode;
public int Next;
public TKey Key;
public TValue Value;
}一个Entry包括该key的HashCode,以及下个Entry的索引Next,该键值对的Key以及数据Vaule.
字典初始化
private void Initialize(int capacity)
{
int size = HashHelpersMini.GetPrime(capacity);
_buckets = new int[size];
for (int i = 0; i < _buckets.Length; i++)
{
_buckets[i] = -1;
}
_entries = new Entry[size];
_freeList = -1;
}字典初始化时,首先要创建int数组,分别作为buckets和entries,其中buckets的index是key的哈希值%size,它的value是数据在entries中的index,我们要取的数据就存在entries中.当某一个bucket没有指向任何entry时,它的value为-1.
另外,很有意思得一点,buckets的数组长度是多少呢?这个我研究了挺久,发现取的是大于capacity的最小质数.
添加新元素
private void Insert(TKey key, TValue value, bool add)
{
if (key == null)
{
throw new ArgumentNullException();
}
//如果buckets为空,则重新初始化字典.
if (_buckets == null) Initialize(0);
//获取传入key的 哈希值
var hashCode = _comparer.GetHashCode(key);
//把hashCode%size的值作为目标Bucket的Index.
var targetBucket = hashCode % _buckets.Length;
//遍历判断传入的key对应的值是否已经添加字典中
for (int i = _buckets[targetBucket]; i > 0; i = _entries[i].Next)
{
if (_entries[i].HashCode == hashCode && _comparer.Equals(_entries[i].Key, key))
{
//当add为true时,直接抛出异常,告诉给定的值已存在在字典中.
if (add)
{
throw new Exception("给定的关键字已存在!");
}
//当add为false时,重新赋值并退出.
_entries[i].Value = value;
return;
}
}
//表示本次存储数据的数据在Entries中的索引
int index;
//当有数据被Remove时,freeCount会加1
if (_freeCount > 0)
{
//freeList为上一个移除数据的Entries的索引,这样能尽量地让连续的Entries都利用起来.
index = _freeList;
_freeList = _entries[index].Next;
_freeCount--;
}
else
{
//当已使用的Entry的数据等于Entries的长度时,说明字典里的数据已经存满了,需要对字典进行扩容,Resize.
if (_count == _entries.Length)
{
Resize();
targetBucket = hashCode % _buckets.Length;
}
//默认取未使用的第一个
index = _count;
_count++;
}
//对Entries进行赋值
_entries[index].HashCode = hashCode;
_entries[index].Next = _buckets[targetBucket];
_entries[index].Key = key;
_entries[index].Value = value;
//用buckets来登记数据在Entries中的索引.
_buckets[targetBucket] = index;
}字典的扩容
private void Resize()
{
//获取大于当前size的最小质数
Resize(HashHelpersMini.GetPrime(_count), false);
}
private void Resize(int newSize, bool foreNewHashCodes)
{
var newBuckets = new int[newSize];
//把所有buckets设置-1
for (int i = 0; i < newBuckets.Length; i++) newBuckets[i] = -1;
var newEntries = new Entry[newSize];
//把旧的的Enties中的数据拷贝到新的Entires数组中.
Array.Copy(_entries, 0, newEntries, 0, _count);
if (foreNewHashCodes)
{
for (int i = 0; i < _count; i++)
{
if (newEntries[i].HashCode != -1)
{
newEntries[i].HashCode = _comparer.GetHashCode(newEntries[i].Key);
}
}
}
//重新对新的bucket赋值.
for (int i = 0; i < _count; i++)
{
if (newEntries[i].HashCode > 0)
{
int bucket = newEntries[i].HashCode % newSize;
newEntries[i].Next = newBuckets[bucket];
newBuckets[bucket] = i;
}
}
_buckets = newBuckets;
_entries = newEntries;
}移除元素
//通过key移除指定的item
public bool Remove(TKey key)
{
if (key == null)
throw new Exception();
if (_buckets != null)
{
//获取该key的HashCode
int hashCode = _comparer.GetHashCode(key);
//获取bucket的索引
int bucket = hashCode % _buckets.Length;
int last = -1;
for (int i = _buckets[bucket]; i >= 0; last = i, i = _entries[i].Next)
{
if (_entries[i].HashCode == hashCode && _comparer.Equals(_entries[i].Key, key))
{
if (last < 0)
{
_buckets[bucket] = _entries[i].Next;
}
else
{
_entries[last].Next = _entries[i].Next;
}
//把要移除的元素置空.
_entries[i].HashCode = -1;
_entries[i].Next = _freeList;
_entries[i].Key = default(TKey);
_entries[i].Value = default(TValue);
//把该释放的索引记录在freeList中
_freeList = i;
//把空Entry的数量加1
_freeCount++;
return true;
}
}
}
return false;
}我对.Net中的Dictionary的源码进行了精简,做了一个DictionaryMini,有兴趣的可以到我的github查看相关代码.
https://github.com/liuzhenyulive/DictionaryMini
答疑时间
字典为什么能无限地Add呢
向Dictionary中添加元素时,会有一步进行判断字典是否满了,如果满了,会用Resize对字典进行自动地扩容,所以字典不会向数组那样有固定的容量.
为什么从字典中取数据这么快
Key-->HashCode-->HashCode%Size-->Bucket Index-->Bucket-->Entry Index-->Value
整个过程都没有通过遍历来查找数据,一步到下一步的目的性时非常明确的,所以取数据的过程非常快.
初始化字典可以指定字典容量,这是否多余呢
前面说过,当向字典中插入数据时,如果字典已满,会自动地给字典Resize扩容.
扩容的标准时会把大于当前前容量的最小质数作为当前字典的容量,比如,当我们的字典最终存储的元素为15个时,会有这样的一个过程.
new Dictionary()------------------->size:3
字典添加低3个元素---->Resize--->size:7
字典添加低7个元素---->Resize--->size:11
字典添加低11个元素--->Resize--->size:23
可以看到一共进行了三次次Resize,如果我们预先知道最终字典要存储15个元素,那么我们可以用new Dictionary(15)来创建一个字典.
new Dictionary(15)---------->size:23
这样就不需要进行Resize了,可以想象,每次Resize都是消耗一定的时间资源的,需要把OldEnties Copy to NewEntries 所以我们在创建字典时,如果知道字典的中要存储的字典的元素个数,在创建字典时,就传入capacity,免去了中间的Resize进行扩容.
Tips:
即使指定字典容量capacity,后期如果添加的元素超过这个数量,字典也是会自动扩容的.
为什么字典的桶buckets 长度为素数
我们假设有这样的一系列keys,他们的分布范围时K={ 0, 1,..., 100 },又假设某一个buckets的长度m=12,因为3是12的一个因子,当key时3的倍数时,那么targetBucket也将会是3的倍数.
Keys {0,12,24,36,...}
TargetBucket将会是0.
Keys {3,15,27,39,...}
TargetBucket将会是3.
Keys {6,18,30,42,...}
TargetBucket将会是6.
Keys {9,21,33,45,...}
TargetBucket将会是9.如果Key的值是均匀分布的(K中的每一个Key中出现的可能性相同),那么Buckets的Length就没有那么重要了,但是如果Key不是均匀分布呢?
想象一下,如果Key在3的倍数时出现的可能性特别大,其他的基本不出现,TargetBucket那些不是3的倍数的索引就基本不会存储什么数据了,这样就可能有2/3的Bucket空着,数据大量第聚集在0,3,6,9中.
这种情况其实时很常见的。 例如,又一种场景,您根据对象存储在内存中的位置来跟踪对象,如果你的计算机的字节大小是4,而且你的Buckets的长度也为4,那么所有的内存地址都会时4的倍数,也就是说key都是4的倍数,它的HashCode也将会时4的倍数,导致所有的数据都会存储在TargetBucket=0(Key%4=0)的bucket中,而剩下的3/4的Buckets都是空的. 这样数据分布就非常不均匀了.
K中的每一个key如果与Buckets的长度m有公因子,那么该数据就会存储在这个公因子的倍数为索引的bucket中.为了让数据尽可能地均匀地分布在Buckets中,我们要尽量减少m和K中的key的有公因子出现的可能性.那么,把Bucket的长度设为质数就是最佳选择了,因为质数的因子时最少的.这就是为什么每次利用Resize给字典扩容时会取大于当前size的最小质数的原因.
确实,这一块可能有点难以理解,我花了好几天才研究明白,如果小伙伴们没有看懂建议看看这里.
https://cs.stackexchange.com/questions/11029/why-is-it-best-to-use-a-prime-number-as-a-mod-in-a-hashing-function/64191#64191
最后,感谢大家耐着性子把这篇文章看完,欢迎fork DictionaryMini进行进一步的研究,谢谢大家的支持.
https://github.com/liuzhenyulive/DictionaryMini
C# Memory Cache 踩坑记录
背景
前些天公司服务器数据库访问量偏高,运维人员收到告警推送,安排我团队小伙伴排查原因.
我们发现原来系统定期会跑一个回归测试,该测运行的任务较多,每处理一条任务都会到数据库中取相关数据,高速地回归测试也带来了高频率的数据库读取.
解决方案1
我们认为每个任务要取的数据大相径庭,因此我们考虑对这个过程进行修改,加入MemoryCache把数据库中读取到的数据进行缓存.
整个修改非常简单,相信对常年混迹在博客园中的各位大佬来说小菜一碟,因此小弟不再叙述添加缓存的步骤细节.
从缓存的添加,代码提交,Teamcity 编译通过,到测试环境,QA环境的安装无比流畅,一切显得如手到擒来.
嗯,优秀是一种习惯, 没有一点办法.
人生如戏,当我们还沉浸在"我加的Cache不可能又BUG"的自信中时,QA传来噩耗,回归测试大量未通过 ....
故障排查
之前习惯了使用Redis缓存,因此,常识告诉我们 --- 在数据库中数据没有改动的前提下,加了缓存后读取的数据的效果和从数据库中读取的效果是一模一样的.
除非 ,,, 除非 这个常识是错误的....
因此我们加了日志,对写入缓存前后读取出来的数据进行了对比,结果出人意料.

该死 MemoryCache 毁我老脸,丢我精度,拿命来!!!!!
从日志中看到,第一行是从数据库中读取的结果,第二行是从cache中读取的,前两条数据完全一致,到了第三条,第四条,第五条,仔细观察发现,在小数点后面,居然有些小数点后比较微小的变化,不管变化的大小但数据确实发生改变了,所以MemoryCache会影响数据精度??这样会改变数据精度的MemoryCache又有何用??
机智的我,似乎早已看穿了一切,这肯定不是MenoryCache的锅!!!
不一样的MemoryCache
我从https://referencesource.microsoft.com 中扒出了MemoryCache的源码一探究竟.

定位到MemoryCache中的AddOrGetExisting方法,我们看到,其实我们把数据存储到该缓存的过程本质是把该对象存到一个名为_entries的 Hashtable 中,同样,取数据也是通过Key到该Hashtable中取出来,整个过程并没有对该对象进行序列化反序列等,也没有对该对象进行clone操作.这就意味着我们之前存入的,和后面取出的(不管我们从MemoryCache中取数据取多少次),永远只取出同一个对象.
这一点,和我之前使用的RedisCache是有很大区别的.我们在Redis中存入数据,是把对象序列化后存到Redis中,取数据是把Redis中的字节数据反序列成对象,意味着前一次存入的,和后一次取出的,已经不是同一个对象了,因此Redis中的数据是安全的.
猜想
我做出了一个大胆的猜想,之前从MemoryCache中取出来的数据之所以变化了,可能是取出对象后,复杂的处理过程中对该对象进行了什么修改操作,所以后期,再次从数据库中读取数据,读出来的已经已经不是最初存入的数据,而是前一次修改之后的数据.带着这个猜想,我对代码进行了修改.
解决方案2
从MenoryCache中取到数据后对结果进行clone(),这样即使程序对取出来的结果进行了修改也不会影响Cache中的数据了.
又是一次提心掉到的提交,编译,安装后, 回归测试顺利通过.
感觉人生到达了高潮 -_-
把踩得坑分享出来,希望后面的小伙伴引以为鉴,
.net 泛型
结构化CSS设计思维
LESS、SASS等预处理器给CSS开发带来了语法的灵活和便利,其本身却没有给我们带来结构化设计思维。很少有人讨论CSS的架构设计,而很多框架本身,如Bootstrap确实有架构设计思维作为根基。 要理解这些框架,高效使用这些框架,甚至最后实现自己的框架,必须要了解结构化CSS设计思想。
我不是前端专家,但是我想,是否一定要等成为了专家才能布道?那是不是太晚了。 所以我是作为一个CSS的学习者,给其他CSS学习者分享一下结构化CSS设计的学习心得。 我更多的是一个后端开发者,后端开发的成熟思想必定能给前端带来新鲜血液。
前言
CSS从根本来讲就是一系列的规则,对Html(作为内容标识和呈现)的风格化得一系列规则,因此,语法级别也就是两个重要因素:选择器和应用的风格。 简单而超能。
一开始,CSS很容易学习,容易上手。当我们的网站成长为企业级网站时,我们的CSS开始成为臃肿、重复和难以为维护的一个混沌 。这种状态在软件开发中被称为Big ball of mud ,更为常见的讲法是面条式代码,是一种缺乏良好架构和设计的表象。 解决这个问题的方法和思维在后台软件开发中已经是比较多的讨论也相对成熟。同为软件开发的CSS开发,毋庸置疑,却可以这些借鉴思维。
面向方面
如前所述,CSS只是一系列规则,这是对CSS的初步认识,但我们不能停留在这个认识。如同,我们认识到所有物体都由原子组成,但是这个认识并不完全能够替代化学在分子级别的研究。
这些规则必须要进一步分化,各自有不同作用和角色,不能平面化。表面上同是选择器+风格化的CSS规则,根据它们的业务意义,应该划分为不同的类别或者方面 (Aspect 参考用词Aspect-oriented programming)。
这些方面分别是:
- 基本(元素)
- 布局
- 模块
- 状态
- 主题
明确的分析你要写的CSS规则属于哪个方面,在实现上区分这些方面并保持这样的分离,
是往结构化走的重要一步。
基本(元素)规则和布局规则
之所以把这两类单独提出来,是因为这是我们平时理解的css似乎就完全只有这两类。 我们对那些划归这两类的风格没有异议,而对那些属于这两类的反而不太理解。 还是先简单了解一下这两类本身的范围。
基本规则
是应用于基本元素级别的规则,作用于全局统一(默认)的风格。 最好的一个案例:CSS的重置框架reset.css以及bootstrap的改进方案normalize.css, 就完全是基本风格规则,不包含任何其他类型的规则。 虽然其作用和我们平时项目中的基本风格不相同,用来理解基本风格的范畴是及其恰当的。
布局规则
在我们一开始谈前端的结构化时,脑海中第一浮现的设计就是这个分层结构树(或则分形的思维):
页面 Page => 布局 Layout => 模块 Module => 元素 Element 。
一个页面由布局组成,每个布局局部由一个或多个模块组成,一个模块有n个元素组成,看上去简单而完美,真正的结构化、模块化。 然而,现实世界总是非线性的。在实际的项目中,严格的层次关系设计,遇到了各类“特例”需要打破这个结构。
比如,AngularJS是MVC架构,更准确一些,它是层次结构化MVC, 一个大的MVC又由其它几个粒度更小的MVC组成, 特别是ui-router的嵌套状态和视图把这个结构表达的更清楚。 从设计的思维上,称之为分形更恰当。
当需要模块与模块之间的通信和信息交流时,这种结构却不能自然的支持,于是,有一个事件系统创造出来弥补这个缺陷。
之所以有这些“特例”,根本原因就是分形思维只适合在模块这一级别,而不能往上扩展到布局和页面界别,也不能往下扩展到元素级别。
布局就是布局,应该作为一个独立的方面存在。
布局规则中,我们之关注组件之间的相互关系,不关心组件自身的设计,也不关心布局所在的位置。
比如,用list(ol或者ul)做布局用时:
.layout-grid{
margin: 0;
padding: 0;
list-style-type: none;
}
.layout-grid > li {
display: inline-block;
margin: 0 0 10px 10px;
}'list-style-type'和'display'的设置,我们可以明显看出是布局,'margin'和'padding'似乎更像基本风格规则。 然而,从使用的目的来看,它们都是用于布局的方面。
这个例子,我们可以看出对规则的划分不是按CSS的技术特性,而是按业务特性:它们的作用,它们的“含义”。
模块规则
这个类别含义是很明确清楚,只是强调一下,模块可以放在布局的组件中,也可以放在另外一个模块内部,是嵌套的,就是前面说的分形。
用class和语义标签
我们一般都用class来定义模块,如果需要用到标签则只能是有语义的标签。如heading系列:
.module > h2{
padding: ......
}用subclass定义嵌套元素风格
如bootstrap的listgroup:
<ul class="list-group">
<li class="list-group-item">First item</li>
<li class="list-group-item">Second item</li>
<li class="list-group-item">Third item</li>
</ul>可以看到,在list-group之外,它又另外定义了list-group-item来修饰li,而不是用以下方式省略掉子类的声明和使用:
.list-group > li {
...
}
为什么要这样? 可以作为一个思考题放在这。
状态规则
状态和子模块有时候很相似,却有亮的明显区别:
- 状态改变布局风格或模块风格
- 状态大部分时候和Javascript相联系
这是什么意思呢,我们看看例子:
最经典的案例就是表单数据的有效性,一般都会引入class定义,类似is-valid;还有就是tab当前激活的状态is-tab-active等。 前者,会改变表单的布局:增加warning信息;后者,会改变tab模块的显示背景来表明当前tab是被选中的。
而以上两个类也都会由javascript根据用户操作,动态的添加到相应的DOM元素中去。
从状态规则的两个关键词:改变和javascript,我们能很明显的看出它如其他规则的区别,仍然重点在它的用途和业务含义。 它最重要的一个业务逻辑就是:状态规则与时间相关,这也足以给它一个独立的地位,与模块规则的维度呈正交关系。
正交设计的延伸阅读:
主题规则
主题是整个网站的风格全面的改变,可以跨项目的才改一次,因而可以在编译阶段进行 如bootstrap的customize用于这种场景;还有就是在一个项目之内也容许用户动态改变。 这些绝对是与其他规则不在一个方面,必定要独立出来。
这类规则会涉及到所有其他类型的规则,如:基本,模块甚至布局和状态,虽然代码量和工作量都较大,概念上却很清楚,这里就不再展开。
基本规则和模块规则的正交案例
在比较中,我们看看类别之间的区别。
场景
比如说我们网页中需要一个表格来显示一些信息,如iPhone 7的产品参数 https://www.apple.com/cn/iphone-7/specs/
为它写一个简单的风格, 没有任何问题:
table{
width: 100%;
border-collapse: collapse;
border: 1px solid #000;
border-width: 1px 1px;
}
td{
border: 1px solid #000;
border-width: 1px 1px;
}
之后我们拿到一个新的需求,同样用表格但是用来比较不同型号的产品的参数,如 https://www.apple.com/cn/iphone/compare/
为了给客户更好的体验,需要对表格风格做相应的调整,如相间隔的列用不同的背景色区分,表格的行之间需要实线间隔,而列之间则不要。 而且,这些修改不能影响之前信息表格的风格。
覆盖方式解决表格的变体
直观的解决方案,我们引用一个类comparison来覆盖之前的基本规则 :
.comparision {
border-width: 0px 0;
}
.comparison tr > td:nth-child(even){
background-color: #AAA;
}
.comparison tr > td {
border-width: 1px 0;
}完全依照新需求,做了三件事情: 1. 去标题的间隔线 2. 去掉了内容行之间的竖线间隔 3. 双列背景灰显。 点击参看在线Demo。
模块方式解决表格变体
然而,用模块的方式更为清楚,更容易扩展。
基本风格(全局)
首先,与OO中提出基类的思维类似,这里我们也提出公共的风格部分:
table {
width: 100%;
border-collapse: collapse;
}信息表风格类info
然后,为原来的信息表格写出一个分支风格(OO中的子类)
.info {
border: 1px solid #000;
border-width: 1px 1px;
}
.info tr > td {
border: 1px solid #000;
border-width: 1px 1px;
}比较表信息类comparison
最后,为新的比较表格写出另外一个分支风格
.comparison tr > td {
border: 1px solid #666;
border-width: 1px 0;
}
.comparison tr > td:nth-child(even){
background-color: #AAA;
}点击参看在线Demo
比较分析
- 覆盖的方式中,尽管也用了类
comparison,从设计的概念和使用的方式可以看到,和模块中的comparison还是不同的,其业务的语义性弱化很多,以至于作为开发者对其命名的准确程度都不太在意了。 这是一个很不好的倾向。 - 基本风格的
width和border-collapse确确实实是全局的风格,不多一点也不少一点 - 结构非常清晰,风格之间没有复杂的覆盖关系: 比如比较表格中的
border-width不会像前面的实现那样,先td{border-width: 1px 1px;}然后又.comparison tr > td {border-width: 1px 0;}覆盖掉。 可以想象在实际项目中,更多层次的覆盖和更多规则的引入会带来多少的复杂度和差错率,你怎么能准确的判断到底是那个规则再起作用?
状态规则和模块规则的正交案例
因为时间问题,这个案例需要到下次再整理了。
设计思维回顾:
分形:
非常强大的思维,对它本身似乎有点陌生,当说起递归、全息理论是否更熟悉一些? 这些都可以看作是分形思维的应用。
面向方面编程:
有时候又称为面向切面编程,曾经是个炙手可热的名词,现在好像没怎么提起,不是不再适用而是思维已经进入常用编程思维,不再需要强调了。
正交设计
和面向方面有些雷同,在这重复也算一个强调吧。 另外,面向方面只能算正交设计的一种实现方式吧。
语义性
当你看到这“蓝色 ”两个字时, 你脑子里想到的是“蓝色”还是“红色”?
语义设计就是要让命名和内容一致,不要扭曲人性。 提升一个层次:我们要让代码文档化。
覆盖和模块
覆盖是无结构,典型的“修补”编程法,甚至当不同需求被引入的前后顺序不同时,会导致不同的代码结构,随意性太强。 模块有设计,有业务含义,可维护性很强。
WinForm POST上传与后台接收
前端
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Windows.Forms;
using System.Net;
using System.IO;
using System.Collections.Specialized;
namespace WindowsFormsApp1
{
public partial class Form1 : Form
{
WebRequest webRequest = WebRequest.Create("http://localhost/");
public Form1()
{
InitializeComponent();
}
private void button1_Click(object sender, EventArgs e)
{
Encoding myEncoding = Encoding.GetEncoding("utf-8");
//中文参数 string address = "http://www.jb51.net/?" + HttpUtility.UrlEncode("参数一", myEncoding) + "=" + HttpUtility.UrlEncode("值一", myEncoding);
HttpWebRequest req = (HttpWebRequest)HttpWebRequest.Create("http://localhost/WinFormPOST/default.aspx?act=aabbcc");
req.Method = "GET";
using (WebResponse wr = req.GetResponse())
{
//在这里对接收到的页面内容进行处理
using (StreamReader reader = new StreamReader(wr.GetResponseStream(),myEncoding))
{
string body = reader.ReadToEnd();
reader.Close();
MessageBox.Show(body);
}
}
}
private void button2_Click(object sender, EventArgs e)
{
//post
string parmer = "act=send&name=abcd";
byte[] bytes = Encoding.ASCII.GetBytes(parmer);
HttpWebRequest req = (HttpWebRequest)HttpWebRequest.Create("http://localhost/WinFormPost/Default.aspx");
req.Method = "POST";
req.ContentType = "application/x-www-form-urlencoded";
req.ContentLength = bytes.Length;
using (Stream reqStream = req.GetRequestStream())
{
reqStream.Write(bytes, 0, bytes.Length);
}
using (WebResponse wr = req.GetResponse())
{
using (StreamReader sr = new StreamReader(wr.GetResponseStream()))
{
MessageBox.Show(sr.ReadToEnd());
}
}
}
private void button3_Click(object sender, EventArgs e)
{
HttpWebRequest req = (HttpWebRequest)HttpWebRequest.Create("http://localhost/WinFormPost/Default.aspx");
req.Method = "POST";
FileStream fs = new FileStream("D:\\12.jpg", FileMode.Open, FileAccess.Read);
byte[] postdatabyte = new byte[fs.Length];
fs.Read(postdatabyte, 0, postdatabyte.Length);
req.ContentLength = postdatabyte.Length;
Stream stream = req.GetRequestStream();
stream.Write(postdatabyte, 0, postdatabyte.Length);
stream.Close();
using (WebResponse wr = req.GetResponse())
{
using (StreamReader sr = new StreamReader(wr.GetResponseStream()))
{
MessageBox.Show(sr.ReadToEnd());
}
}
}
private void button4_Click(object sender, EventArgs e)
{
UploadImage("D:\\常用软件\\数据库\\SQL2008FULL_CHS.iso");
}
/// <summary>
/// 通过http上传图片及传参数
/// </summary>
/// <param name="imgPath">图片地址(绝对路径:D:\demo\img\123.jpg)</param>
public void UploadImage(string imgPath)
{
var uploadUrl = "http://localhost/winformpost/UP.aspx";
Dictionary<string, string> dic = new Dictionary<string, string>() {
{"p1",1.ToString() },
{"p2",2.ToString() },
{"p3",3.ToString() },
};
var postData = "p1=1&fname=SQL2008FULL_CHS.iso&p3=3";// Utils.BuildQuery(dic);//转换成:para1=1¶2=2¶3=3,后台获取参数将以QueryString方式 ,而非 Form方式
var postUrl = string.Format("{0}?{1}", uploadUrl, postData);//拼接url
HttpWebRequest request = WebRequest.Create(postUrl) as HttpWebRequest;
request.AllowAutoRedirect = true;
request.Method = "POST";
string boundary = DateTime.Now.Ticks.ToString("X"); // 随机分隔线
request.ContentType = "multipart/form-data;charset=utf-8;boundary=" + boundary;
byte[] itemBoundaryBytes = Encoding.UTF8.GetBytes("\r\n--" + boundary + "\r\n");
byte[] endBoundaryBytes = Encoding.UTF8.GetBytes("\r\n--" + boundary + "--\r\n");
int pos = imgPath.LastIndexOf("\\");
string fileName = imgPath.Substring(pos + 1);
//请求头部信息
StringBuilder sbHeader = new StringBuilder(string.Format("Content-Disposition:form-data;name=\"file\";filename=\"{0}\"\r\nContent-Type:application/octet-stream\r\n\r\n", fileName));
byte[] postHeaderBytes = Encoding.UTF8.GetBytes(sbHeader.ToString());
Stream postStream = request.GetRequestStream();
using (FileStream fs = new FileStream(imgPath, FileMode.Open, FileAccess.Read))
{
//发送分隔符
postStream.Write(itemBoundaryBytes, 0, itemBoundaryBytes.Length);
//发送头部信息
postStream.Write(postHeaderBytes, 0, postHeaderBytes.Length);
//写文件
byte[] fileBytes = new byte[1024];
int fileByteRead = 0;
while ((fileByteRead =fs.Read(fileBytes,0,fileBytes.Length)) !=0 )
{
postStream.Write(fileBytes, 0, fileByteRead);
}
}
//发送分隔符
postStream.Write(endBoundaryBytes, 0, endBoundaryBytes.Length);
postStream.Close();
HttpWebResponse response = request.GetResponse() as HttpWebResponse;
//Stream instream = response.GetResponseStream();
//StreamReader sr = new StreamReader(instream, Encoding.UTF8);
//string content = sr.ReadToEnd();
//MessageBox.Show(content);
using (Stream responseStream = response.GetResponseStream())
{
using (StreamReader myStreamReader = new StreamReader(responseStream, Encoding.GetEncoding("utf-8")))
{
string retString = myStreamReader.ReadToEnd();
MessageBox.Show( retString);
}
}
}
private void button5_Click(object sender, EventArgs e)
{
OpenFileDialog openFileDialog1 = new OpenFileDialog();
openFileDialog1.InitialDirectory = "c:\\";//注意这里写路径时要用c:\\而不是c:\
openFileDialog1.Filter = "图片|*.jpg|PNG|*.png|所有文件|*.*";
openFileDialog1.RestoreDirectory = true;
openFileDialog1.FilterIndex = 1;
if (openFileDialog1.ShowDialog() == DialogResult.OK)
{
try
{
string path = openFileDialog1.FileName;
WebClient wc = new WebClient();
wc.Credentials = CredentialCache.DefaultCredentials;
wc.Headers.Add("Content-Type", "application/x-www-form-urlencoded");
// wc.Headers.Add("Content-Type", "multipart/form-data");
//wc.QueryString["fname"] = openFileDialog1.SafeFileName;//没用
//MessageBox.Show(openFileDialog1.SafeFileName);
byte[] fileb = wc.UploadFile(new Uri(@"http://localhost/winformpost/up.aspx?p1=webClient&fname=" + openFileDialog1.SafeFileName), "POST", path);
string res = Encoding.GetEncoding("gb2312").GetString(fileb);
wc.Dispose();
MessageBox.Show(res);
}
catch (Exception ex)
{
MessageBox.Show(ex.Message);
}
}
}
//上传文件:要设置共享文件夹是否有创建的权限,否则无法上传文件UpLoadFile("d:\\1.jpg", "http://localhost/winformpost/up.aspx", "", "");
public void UpLoadFile(string fileNamePath, string urlPath, string User, string Pwd)
{
string newFileName = fileNamePath.Substring(fileNamePath.LastIndexOf(@"\") + 1);//取文件名称
MessageBox.Show(newFileName);
if (urlPath.EndsWith(@"\") == false) urlPath = urlPath + @"\";
urlPath = urlPath + newFileName;
WebClient myWebClient = new WebClient();
//NetworkCredential cread = new NetworkCredential(User, Pwd, "Domain");
//myWebClient.Credentials = cread;
FileStream fs = new FileStream(fileNamePath, FileMode.Open, FileAccess.Read);
BinaryReader r = new BinaryReader(fs);
try
{
byte[] postArray = r.ReadBytes((int)fs.Length);
Stream postStream = myWebClient.OpenWrite(urlPath);
// postStream.m
if (postStream.CanWrite)
{
postStream.Write(postArray, 0, postArray.Length);
MessageBox.Show("文件上传成功!", "提醒", MessageBoxButtons.OK, MessageBoxIcon.Information);
}
else
{
MessageBox.Show("文件上传错误!", "警告", MessageBoxButtons.OK, MessageBoxIcon.Warning);
}
postStream.Close();
}
catch (Exception ex)
{
MessageBox.Show(ex.Message, "错误");
}
}
}
}
后端
using System;
using System.Collections.Generic;
using System.Linq;
using System.Web;
using System.Web.UI;
using System.Web.UI.WebControls;
namespace WinFormPOST
{
public partial class UP : System.Web.UI.Page
{
protected void Page_Load(object sender, EventArgs e)
{
HttpPostedFile f;
if (Request.Files.Count > 0)
{
for (int i = 0; i < Request.Files.Count; i++)
{
f = Request.Files[i];
string fName = Request.QueryString["fname"];
if (string.IsNullOrEmpty(fName) == false)
f.SaveAs(Server.MapPath("~/UploadFiles/") + fName);
else
{
Random rnd = new Random();
f.SaveAs(Server.MapPath("~/UploadFiles/") +rnd.Next(99999)+ "_002.jpg");
}
}
}
string p1 = Request["p1"];
if (string.IsNullOrEmpty(p1)==false)
{
Response.Write("p1=" + p1);
}
Response.Write("\r\nEnd");
Response.End();
}
}
}
很多人也想了解一下最新和感觉有用的.NET开源项目,最近准备面试为了有料说,在网上找到了一些开源的项目,个人觉得还不错,所以给大家分享一下,共同进步。
- Akka.NET:
概述:更轻松地构建强大的并发和分布式应用。
简介:Akka.NET是一个用于在.NET和Mono上构建高度并发,分布式和容错的事件驱动应用程序的工具包和运行时。
- Topshelf:
概述:使用.NET构建Windows服务的简单服务托管框架。
简介:Topshelf是托管使用.NET框架编写的服务的框架。服务的创建被简化,允许开发人员创建一个简单的控制台应用程序,可以使用Topshelf作为服务安装。原因很简单:调试控制台应用程序比服务容易得多。一旦应用程序经过测试并可以进行生产,Topshelf可以轻松安装应用程序作为服务。
-
概述:OpenID Connect Provider和用于ASP.NET 4.x / Katana的OAuth 2.0授权服务器框架。
简介:IdentityServer是一个基于.NET / Katana的框架和可托管组件,允许使用OpenID Connect和OAuth2等协议实现对现代Web应用程序和API的单一登录和访问控制。它支持广泛的客户端,如移动,Web,SPA和桌面应用程序,并且是可扩展的,可以集成到新的和现有的架构中。
-
MediatR:
概述:在.NET中简单的中介器实现。
简介:进程内消息传递,无依赖关系。支持请求/响应,命令,查询,通知和事件,通过C#通用方差进行智能调度的同步和异步。
-
MassTransit:
概述:.NET的分布式应用程序框架。
简介:MassTransit可以轻松创建应用和服务,利用基于消息的松散耦合的异步通信,实现更高的可用性,可靠性和可扩展性。
- microdot:
概述:一个开源的.NET微服务框架。
简介:Microdot框架可帮助您创建可扩展和可靠的微服务(“微服务机架”),让您专注于编写定义服务逻辑的代码,而无需解决开发分布式系统的无数挑战。Microdot还可以很好地与 Orleans虚拟演员框架相结合,让您轻松地编写基于 Orleans微型服务。
- Docker.DotNet:
概述:用于Docker API的.NET(C#)客户端库。
简介:与 .NET应用程序中的Docker Remote API端点进行交互。它是完全异步的,旨在以非阻塞和面向对象的方式通过编程方式与Docker守护程序进行交互。
- Z.ExtensionMethods
概述:C#扩展方法| .NET开源和免费库
简介:通过超过1000种扩展方法增强.NET Framework。
- SuperWebSocket
概述:SuperWebSocket是WebSocket服务器的.NET实现。
简介:WebSocket是通过单个传输控制协议(TCP)插座提供双向,全双工通信信道的技术。它被设计为在Web浏览器和Web服务器中实现,但它可以被任何客户端或服务器应用程序使用。SuperWebSocket被合并到SuperSocket作为附加模块SuperSocket.WebSocket。您可以使用SuperSocket.WebSocket用相同的方式SuperWebSocket但有不同的命名空间。
-
Seal-Report:
概述:开放数据库报表工具(.Net)
简介:Seal-Report提供了一个完整的框架,用于从任何数据库生成日常报告和仪表板。Seal-Report是Microsoft .NET Framework完全用C#编写的开源工具。
- accord-net-extensions
概述:先进的图像处理和计算机视觉算法作为流畅的扩展而构建为可移植性。
简介:Accord.NET Extensions是Accord.NET和AForge.NET的扩展框架。框架集中将.NET本地数组作为主要成像对象,并提供大多数构建为扩展的计算机视觉算法。
-
MediaToolkit:
概述:用于转换和处理所有视频和音频文件的.NET库。
简介:MediaToolkit为处理媒体数据提供了一个简单的界面,完成了轻松转换,切片和编辑音频和视频等任务。在引擎盖下,MediaToolkit是一个用于FFmpeg的.NET包装器; 一个包含多个音频和视频编解码器的免费(LGPLv2.1)多媒体框架,支持多种媒体格式的多路复用,解复用和转码任务。(从视频抓住缩略图,检索元数据,基本转换,将Flash视频转换为DVD,转码选项FLV到MP4,将视频缩小到较小的长度)
- htmldiff.net:
概述:.NET的Html Diff算法。
简介:用于比较两个HTML文件/片段的库,并使用简单的HTML突出显示差异。这个HTML Diff实现是在这里找到的ruby实现的C#端口。
-
CalbucciLib.ExtensionsGalore:
概述:.NET中内置类型和类的扩展的100个扩展。
简介:ExtensionsGalore是一个库,可以扩展.NET的许多常见类型和类别,以便快速方便地访问Web和移动开发的常见场景。换句话说,它可以帮助您编写更少的代码行,并将更多的焦点集中在应用程序中。
开源地址:https://github.com/calbucci/CalbucciLib.ExtensionsGalore
- Dapper:
概述:Dapper - 一个简单的对象映射器.Net
简介:Dapper的一个关键特性是性能。用于ORM映射
- FluentValidation
概述:.NET的一个小型验证库,它使用流畅的界面和lambda表达式来构建验证规则。
简介:.NET的一个小型验证库,它使用流畅的界面和lambda表达式来构建验证规则。由Jeremy Skinner(http://www.jeremyskinner.co.uk)撰写,并在Apache 2下授权。
- Accord.NET Framework:
概述:机器学习,计算机视觉,统计学和.NET的一般科学计算。
简介:Accord.NET项目为.NET提供机器学习,统计,人工智能,计算机视觉和图像处理方法。它可以在Microsoft Windows,Xamarin,Unity3D,Windows Store应用程序,Linux或移动设备上使用。在与AForge.NET项目合并之后,该框架现在提供了一个用于学习/训练机器学习模型的统一API,其易于使用和可扩展。
- Lucene.Net
概述:Apache Lucene.Net镜像
简介:Apache Lucene.Net是一个.NET全文搜索引擎框架,是流行的Apache Lucene项目的C#端口。Apache Lucene.Net不是一个完整的应用程序,而是一个可以轻松地用于向应用程序添加搜索功能的代码库和API。
-
CommonMark.NET:
概述:在C#中实现CommonMark规范,将Markdown文档转换为HTML。针对最大的性能和可移植性进行了优化。
简介:在C#中实现CommonMark规范(通过0.27版的测试)将Markdown文档转换为HTML。
-
WebApiThrottle:
概述:用于IIS和Owin托管的ASP.NET Web API速率限制器。
简介:ASP.NET Web API调节处理程序,OWIN中间件和过滤器旨在根据IP地址,客户端API密钥和请求路由来控制客户端对Web API的请求速率。(基于IP的全局调节,基于IP的端点限制,端点限制基于IP和客户端密钥,IP和/或客户端密钥白名单,IP和/或客户端密钥自 定义速率限制,端点自定义速率限制,堆栈拒绝请求,在web.config或app.config中定义速率限制,检索API客户端密钥,存储油门指标,运行时更新速率限制,记录限制的请求,基于属性的速率限制与ThrottlingFilter和EnableThrottlingAttribute,速度限制与ThrottlingMiddleware,自定义ip地址解析)
以上只是简单的介绍了一些开源项目,让大家一起学习。
- 什么是Sql注入?如何避免Sql注入?
用户根据系统的程序构造非法的参数从而导致程序执行不是程序期望的恶意Sql语句。
使用参数化的Sql就可以避免Sql注入。
- 数据库三范式是什么?
第一范式:字段不能有冗余信息,所有字段都是必不可少的。
第二范式:满足第一范式并且表必须有主键。
第三范式:满足第二范式并且引用其他的表必须通过主键引用。
eg: 员工内部->自己的老大->外部的老大
记忆顺序:自己内部不重复->别人引用自己->自己引用别人
- Application 、Cookie和 Session 两种会话有什么不同?
Application是用来存取整个网站全局的信息,而Session是用来存取与具体某个访问者关联的信息。Cookie是保存在客户端的,机密信息不能保存在Cookie中,只能放小数据;Session是保存在服务器端的,比较安全,可以放大数据。
谈到Session的时候就侃Session和Cookie的关系:Cookie中的SessionId。和别人对比说自己懂这个原理而给工作带来的方便之处。
- 在.net 中类(class) 与结构(Struct)的异同。
Class 可以被实例化,属于引用类型,是分配在内存的堆上的。类是引用传递的。
Struct 属于值类型,是分配在内存的栈上的。结构体是复制传递的。
Boolean等属于结构体。
- 堆和栈的区别
栈是编译期间就分配好的内存空间,因此你的代码中必须就栈的大小有明确的定义;局部值类型变量、值类型参数等都在栈内存 中。
堆是程序运行期间动态分配的内存空间,你可以根据程序的运行情况确定要分配的堆内存大小。
- GC是什么?为什么要有GC?
GC是垃圾收集器(Garbage Collection) 程序员不用担心内存管理,因为垃圾收集器会自动进行管理。GC只能处理托管内存资源的 释放,对于非托管资源 则不能使用GC进行回收,必须由程序员手动回收,一个例子就是FileStream 或者SqlConnection 需要程序 员调用Dispose进行资源的回收。
- 值类型和引用类型的区别?
- 将一个值类型变量赋值给另一个值类型变量时,将复制包含的值。引用类型变量的赋值只复制对对象的引用,而不复制对象本身。
- 值类型不可能派生出新的类型:所有的值类型均隐式派生自System.ValueType。但与引用类型相同的是,结构也可以实现接口。
- 值类型不可能包含null值;然而,可空类型功能允许将null 赋给值类型。
- 每种值类型均有一个隐式的默认构造函数来初始化该类型的默认值。
- C# 中的接口和类有什么异同。
不同点: 不能直接实例化接口。 接口不包含方法的实现。 接口可以多继承,类只能单继承。 类定义可在不同的源文件之间进行拆分。
相同点: 接口、类和结构体都可以从多个接口继承。接口类似于抽象基类:继承接口的任何非抽象类型都必须实现接口所有成员。
接口和类都可以包含事件、索引器、方法和属性。
- abstract class 和interface 有什么区别?
相同点:都不能被直接实例化,都可以通过继承实现其抽象的方法。
不同点: 接口支持多继承;抽象类不能实现多继承。接口只能定义行为;抽象类既可以定义行为,还可以提供实现。
接口只包含方法(Method) 、属性(Property)、索引器(Index) 、事件(Event)的签名定义字段和包含实现方法。
接口可以作用于值类型(Struct)和引用类型(Class);抽象类只能作用于引用类型。例如,Struct就可以继承接口,而不能继承类。
加分的补充回答:讲设计模式的时候SettingsProvider的例子。
- 软件设计模式
为了更好地理解依赖注入的概念,首先了解一下软件设计模式是很有必要的。软件设计模式主要用来规范问题及其解决方案的描述,以简化开发人员对常见问题及其对应解决方案的标识与交流。
- 控制反转IOC
几乎每个人都看过或是自己写过下面代码的经历


1 public class EmailService
2 {
3 public void SendMsg()
4 {
5 Console.WriteLine("Hello world !!!");
6 }
7 }
8
9 /// <summary>
10 /// 耦合实现
11 /// </summary>
12 public class NotificationSys
13 {
14 private EmailService svc;
15
16 public NotificationSys()
17 {
18 svc = new EmailService();
19 }
20
21 public void InterestingEventHappened()
22 {
23 svc.SendMsg();
24 }
25 }
上述代码中,NotificationSys 类依赖EmailService类,当一个组件依赖其他组件称之耦合。在软件设计过程,高耦合通常认为是软件设计的责任。当一个类精确地知道另一个类的设计和实现时,就会增加软件修改的负担,因为修改一个类很有可能破坏依赖它的另一个类。为降低组件之间的耦合程序,一般采取两个独立但相关的步骤:
1.在两块代码之间引入抽象层,所以上述代码可修改为以下
1 public interface IEmailService
2 {
3 void SendMsg();
4 }
5 public class EmailService : IEmailService
6 {
7 public void SendMsg()
8 {
9 Console.WriteLine("Hello world !!!");
10 }
11 }
12 /// <summary>
13 /// 抽象接口来实现
14 /// (把抽象实现的责任移到消费者的外部)
15 /// </summary>
16 public class NotificationSys1
17 {
18 private IEmailService svc;
19 public NotificationSys1()
20 {
21 svc = new EmailService1();
22 }
23 public void InterestingEventHappened()
24 {
25 svc.SendMsg();
26 }
27 }
2.把选择抽象实现的责任移到消费者类的外部。
控制反转(IOC)模式是抽象的;把依赖的创建移到使用这些的类的外部,这称为控制反转模式,之所以以这样命名,是因为反转的是依赖的创建,正因为如此,才消除消费类对依赖创建的控制。
- 依赖注入DI
依赖注入是另一种控制反转模式形式,它没有像服务器定位器一样的中间对象。相反,组件以一种允许依赖的方式编写,通常由构造函数参数或属性设置器来显式表示。
1. 构造函数注入
DI 的最常见形式是构造函数注入。该技术需要我们为类创建一个显示表示所以依赖的构造函数。
1 /// <summary>
2 /// 构造注入
3 /// </summary>
4 public class NotificationSys
5 {
6 private IEmailService _svc;
7
8 public NotificationSys(IEmailService svc)
9 {
10 _svc =svc ;
11 }
12 public void InterestingEventHappened()
13 {
14 _svc.SendMsg();
15 }
16 }
优点: 极大简化构造函数的实现;减少了NotificationSys类需要知道的信息量;需求的透明性,任何想创建NotificationSys类实例的代码都能查看构造函数,并精确的知道哪些内容是消费者必须的。
2.属性注入
属性注入是一种不太常见的依赖注入方式。顾名思义,该方式是通过设置对象上公共属性而不是通过使用构造函数参数来注入依赖。
public class NotificationSys
{
private IEmailService svc{get;set;}
public void InterestingEventHappened()
{
svc.SendMsg();
}
}
显而易见,这里我们已经减少了需求的透明性,而且绝对比构造函数注入更容易产生错误。
选择属性注入原因:
如果依赖在某种意义上是真正可选的,即在消费者类不提供依赖时,也有相应的处理,属性注入是个不错的选择
类的实例可能需要在我们还没有控制调用的构造函数的情况下被创建
- 依赖注入容器
依赖注入容器是一个可以作为组件工厂使用的软件库,它可以自动检测和满足里面元素的依赖需求。常见的DI容器有 CastleWindsor,Unity,Autofac, ObjectBuilder,StructureMap,Spring.Net
C# RSA 加密
class Sign_verifySign
{
#region prepare string to sign.
//example format: a=123&b=xxx&c (with sort)
private static string encrypt<T>(T body)
{
var mType = body.GetType();
var props = mType.GetProperties().OrderBy(x => x.Name).ToArray();
StringBuilder sb = new StringBuilder();
foreach (var p in props)
{
if (p.Name != "sign" && p.Name != "signType" && p.GetValue(body, null) != null && p.GetValue(body, null).ToString() != "")
{
sb.Append(string.Format("{0}={1}&", p.Name, p.GetValue(body, null)));
}
}
var tmp = sb.ToString();
return tmp.Substring(0, tmp.Length - 1);
}
#endregion
#region sign
public static string sign(string content, string privateKey, string input_charset)
{
byte[] Data = Encoding.GetEncoding(input_charset).GetBytes(content);
RSACryptoServiceProvider rsa = DecodePemPrivateKey(privateKey);
SHA1 sh = new SHA1CryptoServiceProvider();
byte[] signData = rsa.SignData(Data, sh);
//get base64string -> ASCII byte[]
var base64ToByte = Encoding.ASCII.GetBytes(Convert.ToBase64String(signData));
string signresult = BitConverter.ToString(base64ToByte).Replace("-", string.Empty);
return signresult;
}
private static RSACryptoServiceProvider DecodePemPrivateKey(String pemstr)
{
byte[] pkcs8privatekey; pkcs8privatekey = Convert.FromBase64String(pemstr);
if (pkcs8privatekey != null)
{
RSACryptoServiceProvider rsa = DecodePrivateKeyInfo(pkcs8privatekey);
return rsa;
}
else return null;
}
private static RSACryptoServiceProvider DecodePrivateKeyInfo(byte[] pkcs8)
{
byte[] SeqOID = { 0x30, 0x0D, 0x06, 0x09, 0x2A, 0x86, 0x48, 0x86, 0xF7, 0x0D, 0x01, 0x01, 0x01, 0x05, 0x00 };
byte[] seq = new byte[15]; MemoryStream mem = new MemoryStream(pkcs8);
int lenstream = (int)mem.Length; BinaryReader binr = new BinaryReader(mem); //wrap Memory Stream with BinaryReader for easy reading
byte bt = 0;
ushort twobytes = 0;
try
{
twobytes = binr.ReadUInt16();
if (twobytes == 0x8130) //data read as little endian order (actual data order for Sequence is 30 81)
binr.ReadByte(); //advance 1 byte
else if (twobytes == 0x8230)
binr.ReadInt16(); //advance 2 bytes
else
return null;
bt = binr.ReadByte();
if (bt != 0x02)
return null;
twobytes = binr.ReadUInt16();
if (twobytes != 0x0001)
return null;
seq = binr.ReadBytes(15); //read the Sequence OID
if (!CompareBytearrays(seq, SeqOID)) //make sure Sequence for OID is correct
return null;
bt = binr.ReadByte();
if (bt != 0x04) //expect an Octet string
return null;
bt = binr.ReadByte(); //read next byte, or next 2 bytes is 0x81 or 0x82; otherwise bt is the byte count
if (bt == 0x81)
binr.ReadByte();
else
if (bt == 0x82)
binr.ReadUInt16(); //------ at this stage, the remaining sequence should be the RSA private key
byte[] rsaprivkey = binr.ReadBytes((int)(lenstream - mem.Position));
RSACryptoServiceProvider rsacsp = DecodeRSAPrivateKey(rsaprivkey);
return rsacsp;
}
catch (Exception)
{return null;
}
finally
{
binr.Close();
}
}
private static bool CompareBytearrays(byte[] a, byte[] b)
{
if (a.Length != b.Length) return false;
int i = 0; foreach (byte c in a)
{ if (c != b[i]) return false; i++; }
return true;
}
private static RSACryptoServiceProvider DecodeRSAPrivateKey(byte[] privkey)
{
byte[] MODULUS, E, D, P, Q, DP, DQ, IQ;
// --------- Set up stream to decode the asn.1 encoded RSA private key ------
MemoryStream mem = new MemoryStream(privkey);
BinaryReader binr = new BinaryReader(mem); //wrap Memory Stream with BinaryReader for easy reading
byte bt = 0;
ushort twobytes = 0;
int elems = 0;
try
{
twobytes = binr.ReadUInt16();
if (twobytes == 0x8130) //data read as little endian order (actual data order for Sequence is 30 81)
binr.ReadByte(); //advance 1 byte
else if (twobytes == 0x8230)
binr.ReadInt16(); //advance 2 bytes
else
return null;
twobytes = binr.ReadUInt16();
if (twobytes != 0x0102) //version number
return null;
bt = binr.ReadByte();
if (bt != 0x00)
return null;
//------ all private key components are Integer sequences ----
elems = GetIntegerSize(binr);
MODULUS = binr.ReadBytes(elems);
elems = GetIntegerSize(binr);
E = binr.ReadBytes(elems);
elems = GetIntegerSize(binr);
D = binr.ReadBytes(elems);
elems = GetIntegerSize(binr);
P = binr.ReadBytes(elems);
elems = GetIntegerSize(binr);
Q = binr.ReadBytes(elems);
elems = GetIntegerSize(binr);
DP = binr.ReadBytes(elems);
elems = GetIntegerSize(binr);
DQ = binr.ReadBytes(elems);
elems = GetIntegerSize(binr);
IQ = binr.ReadBytes(elems);
// ------- create RSACryptoServiceProvider instance and initialize with public key -----
RSACryptoServiceProvider RSA = new RSACryptoServiceProvider();
RSAParameters RSAparams = new RSAParameters();
RSAparams.Modulus = MODULUS;
RSAparams.Exponent = E;
RSAparams.D = D;
RSAparams.P = P;
RSAparams.Q = Q;
RSAparams.DP = DP;
RSAparams.DQ = DQ;
RSAparams.InverseQ = IQ;
RSA.ImportParameters(RSAparams);
return RSA;
}
catch (Exception e)
{
return null;
}
finally { binr.Close(); }
}
private static int GetIntegerSize(BinaryReader binr)
{
byte bt = 0;
byte lowbyte = 0x00;
byte highbyte = 0x00;
int count = 0;
bt = binr.ReadByte();
if (bt != 0x02) //expect integer
return 0;
bt = binr.ReadByte();
if (bt == 0x81)
count = binr.ReadByte(); // data size in next byte
else
if (bt == 0x82)
{
highbyte = binr.ReadByte(); // data size in next 2 bytes
lowbyte = binr.ReadByte();
byte[] modint = { lowbyte, highbyte, 0x00, 0x00 };
count = BitConverter.ToInt32(modint, 0);
}
else
{
count = bt; // we already have the data size
}while (binr.ReadByte() == 0x00)
{ //remove high order zeros in data
count -= 1;
}
binr.BaseStream.Seek(-1, SeekOrigin.Current); //last ReadByte wasn't a removed zero, so back up a byte
return count;
}
#endregion
#region verifySign
//onepay verify
public static bool verifyFromHexAscii(string sign, string publicKey, string content, string charset)
{
string decSign = System.Text.Encoding.UTF8.GetString(fromHexAscii(sign));
return verify(content, decSign, publicKey, charset);
}
public static byte[] fromHexAscii(string s)
{
try
{
int len = s.Length;
if ((len % 2) != 0)
throw new Exception("Hex ascii must be exactly two digits per byte.");
int out_len = len / 2;
byte[] out1 = new byte[out_len];
int i = 0;
StringReader sr = new StringReader(s);
while (i < out_len)
{
int val = (16 * fromHexDigit(sr.Read())) + fromHexDigit(sr.Read());
out1[i++] = (byte)val;
}
return out1;
}
catch (IOException e)
{
throw new Exception("IOException reading from StringReader?!?!");
}
}
private static int fromHexDigit(int c)
{
if (c >= 0x30 && c < 0x3A)
return c - 0x30;
else if (c >= 0x41 && c < 0x47)
return c - 0x37;
else if (c >= 0x61 && c < 0x67)
return c - 0x57;
else
throw new Exception('\'' + c + "' is not a valid hexadecimal digit.");
}
public static bool verify(string content, string signedString, string publicKey, string input_charset)
{
signedString = signedString.Replace("*", "+");
signedString = signedString.Replace("-", "/");
return JiJianverify(content, signedString, publicKey, input_charset);
}
public static bool JiJianverify(string content, string signedString, string publicKey, string input_charset)
{
bool result = false;
byte[] Data = Encoding.GetEncoding(input_charset).GetBytes(content);
byte[] data = Convert.FromBase64String(signedString);
RSAParameters paraPub = ConvertFromPublicKey(publicKey);
RSACryptoServiceProvider rsaPub = new RSACryptoServiceProvider();
rsaPub.ImportParameters(paraPub);
SHA1 sh = new SHA1CryptoServiceProvider();
result = rsaPub.VerifyData(Data, sh, data);
return result;
}
private static RSAParameters ConvertFromPublicKey(string pemFileConent)
{
byte[] keyData = Convert.FromBase64String(pemFileConent);
if (keyData.Length < 162)
{
throw new ArgumentException("pem file content is incorrect.");
}
RsaKeyParameters publicKeyParam = (RsaKeyParameters)PublicKeyFactory.CreateKey(keyData);
RSAParameters para = new RSAParameters();
para.Modulus = publicKeyParam.Modulus.ToByteArrayUnsigned();
para.Exponent = publicKeyParam.Exponent.ToByteArrayUnsigned();
return para;
}
#endregion
}
C#与Java AES 加密解密
参考文档:https://www.cnblogs.com/xbzhu/p/7064642.html
前几天对接Java接口,需要C#加密参数,Java解密。奈何网上找了一堆大同小异的加解密方法都跟Jaca加密的密文不一致,Java接口也无法解密,直到看见上面链接的第二种方法。能够正常的解密Java加密的密文,说明此方法有效,但这里只有解密,我需要的是加密方法(伸手党做习惯了),没办法读读代码看看是怎么解密的,巧了看到了 CreateDecryptor 改一下 试一下解密 跟Java完全一致 成功!感谢博主!
这是参考文档的博主写的Demo:https://github.com/zhu-xb/AES-Cryptography
/// <summary>
/// AES解密
/// </summary>
/// <param name="data"></param>
/// <param name="key"></param>
/// <returns></returns>
public static string AESDecrypt(string content, string key)
{
KeyGenerator kgen = KeyGenerator.getInstance("AES");
SecureRandom secureRandom = SecureRandom.getInstance("SHA1PRNG");
secureRandom.setSeed(Encoding.ASCII.GetBytes(key));
kgen.init(128, secureRandom);
SecretKey secretKey = kgen.generateKey();
byte[] enCodeFormat = secretKey.getEncoded();
using (AesCryptoServiceProvider aesProvider = new AesCryptoServiceProvider())
{
aesProvider.Key = enCodeFormat;
aesProvider.Mode = CipherMode.ECB;
aesProvider.Padding = PaddingMode.PKCS7;
using (ICryptoTransform cryptoTransform = aesProvider.CreateDecryptor())
{
byte[] inputBuffers = Convert.FromBase64String(content);
byte[] results = cryptoTransform.TransformFinalBlock(inputBuffers, 0, inputBuffers.Length);
aesProvider.Clear();
return Encoding.UTF8.GetString(results);
}
}
}
/// <summary>
/// AES加密
/// </summary>
/// <param name="data"></param>
/// <param name="key"></param>
/// <returns></returns>
public static string AESEncrypt(string content, string key)
{
KeyGenerator kgen = KeyGenerator.getInstance("AES");
SecureRandom secureRandom = SecureRandom.getInstance("SHA1PRNG");
secureRandom.setSeed(Encoding.ASCII.GetBytes(key));
kgen.init(128, secureRandom);
SecretKey secretKey = kgen.generateKey();
byte[] enCodeFormat = secretKey.getEncoded();
using (AesCryptoServiceProvider aesProvider = new AesCryptoServiceProvider())
{
aesProvider.Key = enCodeFormat;
aesProvider.Mode = CipherMode.ECB;
aesProvider.Padding = PaddingMode.PKCS7;
using (ICryptoTransform cryptoTransform = aesProvider.CreateEncryptor())
{
byte[] inputBuffers = Encoding.UTF8.GetBytes(content);
byte[] results = cryptoTransform.TransformFinalBlock(inputBuffers, 0, inputBuffers.Length);
aesProvider.Clear();
return Convert.ToBase64String(results);
}
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号