c#代码 天气接口 一分钟搞懂你的博客为什么没人看 看完python这段爬虫代码,java流泪了c#沉默了 图片二进制转换与存入数据库相关 C#7.0--引用返回值和引用局部变量 JS直接调用C#后台方法(ajax调用) Linq To Json SqlServer 递归查询
天气预报的程序。程序并不难。
看到这个需求第一个想法就是只要找到合适天气预报接口一切都是小意思,说干就干,立马跟学生沟通价格。
![]()
![]() 不过谈报价的过程中,差点没让我一口老血喷键盘上,话说我们程序猿的人工什么时候这么低廉了。。。oh my god
不过谈报价的过程中,差点没让我一口老血喷键盘上,话说我们程序猿的人工什么时候这么低廉了。。。oh my god

![]()
![]() 50十块,你跟我开什么国际玩笑!!不够意外惊喜还是有的,居然是个妹子嘿嘿,哎呀什么钱不钱的多伤感情。
50十块,你跟我开什么国际玩笑!!不够意外惊喜还是有的,居然是个妹子嘿嘿,哎呀什么钱不钱的多伤感情。
老哥送你一套代码,小妹妹以后你好好学习,不懂得问老哥,然后顺利的家了微信(妹子很漂亮)。
![]()
废话不多说开干,这个程序最大的难点就是找一个合适的天气预报接口,以前没有做过类似的程序,导致70%时间浪费在找接口以及调试接口上,不过也算我运气好,找到了一个免费接口,接口的技术兄弟人也超棒,大大的赞。
在这里分享给大家 https://www.tianqiapi.com/?action=doc(刚两天界面就改版了,差点以为我访问错了)。
作为一个免费的接口,数据详细到这种程度,大大的良心,应付一个大学生的期末作业,简直大材小用。

![]()
找接口后,立马开始写代码,由于女学生要的紧,哦,不催得紧,所以代码一切从简,只保留核心功能,锦上添花的东西一律不要,首先搞定http请求类。

public class HttpHelper
{
/// <summary>
/// 发送请求的方法
/// </summary>
/// <param name="Url">地址</param>
/// <param name="postDataStr">数据</param>
/// <returns></returns>
private string HttpPost(string Url, string postDataStr)
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(Url);
request.Method = "POST";
request.ContentType = "application/x-www-form-urlencoded";
request.ContentLength = Encoding.UTF8.GetByteCount(postDataStr);
Stream myRequestStream = request.GetRequestStream();
StreamWriter myStreamWriter = new StreamWriter(myRequestStream,
Encoding.GetEncoding("gb2312"));
myStreamWriter.Write(postDataStr);
myStreamWriter.Close();
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream myResponseStream = response.GetResponseStream();
StreamReader myStreamReader = new StreamReader(myResponseStream, Encoding.GetEncoding("utf-8"));
string retString = myStreamReader.ReadToEnd();
myStreamReader.Close();
myResponseStream.Close();
return retString;
}
public string HttpGet(string Url, string postDataStr)
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(Url + (postDataStr == "" ? "" : "?") + postDataStr);
request.Method = "GET";
request.ContentType = "text/html;charset=UTF-8";
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream myResponseStream = response.GetResponseStream();
StreamReader myStreamReader = new StreamReader(myResponseStream, Encoding.GetEncoding("utf-8"));
string retString = myStreamReader.ReadToEnd();
myStreamReader.Close();
myResponseStream.Close();
return retString;
}
}
http请求搞定,接下来获取所有的城市,主要为了效验用户的输入,不可能你输入什么我都去查天气,就算你是女学生也不行,大家伙说对不?
https://cdn.huyahaha.com/tianqiapi/city.json 全国所有城市接口。
https://www.tianqiapi.com/api/ 天气接口,下为参数列表。
| 参数 | 名称 | 备注 |
|---|---|---|
| version | 版本标识 必填字段 | 目前可用值: v1 |
| callback | jsonp参数 | 如: jQuery.Callbacks |
| 以下参数三选一 | ||
| cityid | 城市编号 | 如: 101120201 |
| city | 城市名称 | 如: 海淀,青岛,大连 (不要带市和区) |
| ip | IP地址 | 此IP地区的天气 |
大家可以自行查看下接口的返回值,简直详细到丧心病狂。
添加几个model类用来序列化json
public class City
{
public string cityZh { get; set; }
public string id { get; set; }
}
public class Data
{
public string day { get; set; }
public string date { get; set; }
public string week { get; set; }
public string wea { get; set; }
public string air { get; set; }
public string air_level { get; set; }
public string air_tips { get; set; }
public string tem { get; set; }
public string tem1 { get; set; }
public string tem2 { get; set; }
public string win_speed { get; set; }
}
public class Weather
{
public string cityid { get; set; }
public string update_time { get; set; }
public string city { get; set; }
public List<Data> data { get; set; }
}
准备工作完成,开始调用接口,由于只有两个接口,接口文档又很清楚,对方技术兄弟也很给力。没费什么劲接口调试成功,于是写了下面两个方法。
public class Weather
{
HttpHelper http = new HttpHelper();
List<City> citys = new List<City>();
public model.Weather GetWeather(string name)
{
if (!citys.Any(a => a.cityZh == name.Trim()))
{
throw new KeyNotFoundException("未找到相关城市,请您检查城市名");
}
var data = http.HttpGet($"https://www.tianqiapi.com/api/?version=v1&city={name}", "").TrimStart('(');
return JsonConvert.DeserializeObject<model.Weather>(data);
}
public void GetCity()
{
var data = http.HttpGet(" https://cdn.huyahaha.com/tianqiapi/city.json", "");
citys = JsonConvert.DeserializeObject<List<City>>(data);
}
}
然后就是界面设计,为了省时间没有使用更强大的wpf,而使用更简单快捷的winform5分钟界面撸完。
为了方便连控件名都没有改(如果在公司这么做,codereview一定会被骂)label3显示当前城市,6个groupbox为6天的天气,一个查询一个退出,界面搞定。
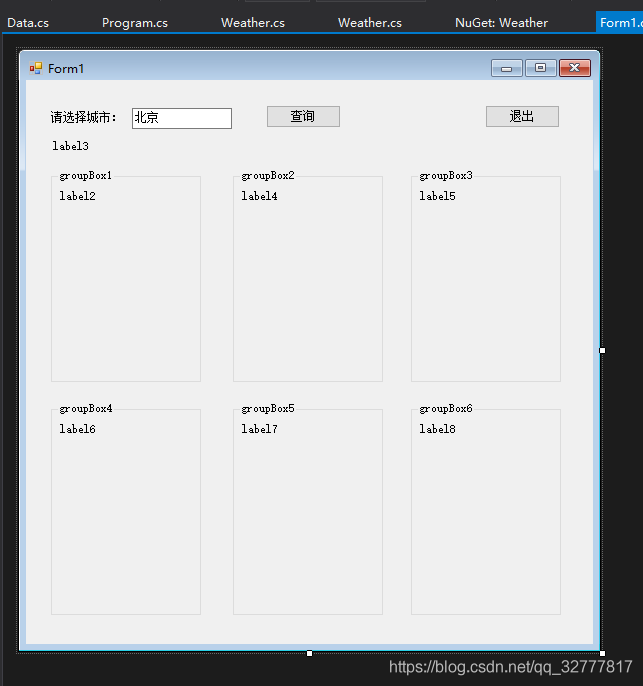
![]()
然后编写按钮事件,绑定数据,没什么难度。
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
AllCity();
}
Weather weather = new Weather();
private void Form1_Load(object sender, EventArgs e)
{
BindData(city_name.Text.Trim());
}
private void AllCity()
{
weather.GetCity();
}
private void label1_Click(object sender, EventArgs e)
{
}
private void select_Click(object sender, EventArgs e)
{
BindData(city_name.Text.Trim());
}
private void BindData(string city)
{
model.Weather w = null;
try
{
w = weather.GetWeather(city);
}
catch (KeyNotFoundException ex)
{
MessageBox.Show(ex.Message);
}
catch (Exception)
{
MessageBox.Show("查询失败请重试");
}
if (w != null)
{
SetView(w);
}
}
private void SetCurrentCity(string city)
{
label3.Text = city;
}
private void SetView(model.Weather model)
{
SetCurrentCity(model.city);
SetLable(model.data);
SetGroupBox(model.data);
}
private void SetLable(List<Data> model)
{
var d = model[0];
label2.Text = WeaderString(model[0]);
label4.Text = WeaderString(model[1]); ;
label5.Text = WeaderString(model[2]); ;
label6.Text = WeaderString(model[3]); ;
label7.Text = WeaderString(model[4]); ;
label8.Text = WeaderString(model[5]); ;
}
private string WeaderString(Data d)
{
string txt = $"日期:{d.date}\r\n天气:{d.wea}\r\n当前温度:{d.tem}\r\n温度:{d.tem1} - {d.tem2}\r\n空气质量:{d.air_level}\r\n空气指数:{d.air}\r\n风力:{d.win_speed}";
return txt;
}
private void SetGroupBox(List<Data> model)
{
groupBox1.Text = model[0].week;
groupBox2.Text = model[1].week;
groupBox3.Text = model[2].week;
groupBox4.Text = model[3].week;
groupBox5.Text = model[4].week;
groupBox6.Text = model[5].week;
}
private void button1_Click(object sender, EventArgs e)
{
Application.Exit();
}
}
搞定了,来看下运行效果,界面虽然简单可是功能完美实现。
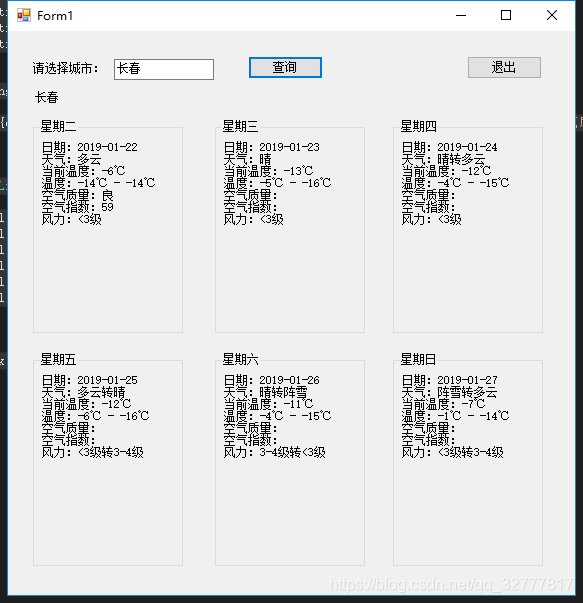
![]()
代码下载 https://pan.baidu.com/s/1jOX52_w3VEgGBEPkLbOXXw
一分钟搞懂你的博客为什么没人看
关于博客访问量的问题,影响因素有很多,例如你的权重,你的博客数量,包括你的标题是否吸引人都是一个衡量的标准。
这些东西需要的是日积月累,今天我们从其中的一个维度入手:发帖时间。相信大家都明白,不论是csdn,博客园这种技术博客
还是今日头条百度贴吧或者抖音快手这种娱乐论坛,都有自己的在线高峰期。例如百度贴吧,用户年龄段普遍偏小,“夜猫子”占据主力。
21-23点是在线高峰期,这个时间的阅读量以及评论量也是最多的,自媒体人肯定会选择在这个时间发帖已得到更多的阅读及评论。
那我们的博客园呢?目前我们还不知道,既然园子里面都是程序猿,数据统计咱就要拿出点技术人员该有的样子,接下来我们
写一个爬虫统计所有的发帖时间以及阅读数量。
所需语言:
python
c#
sql server
- 爬取数据
我们打开博客园首页,首页的文章列表有发帖时间,阅读数,博客园最多只有200页,我们只要将这200页的所有文章阅读数,发帖时间爬取到就ok。

下面我们用python+scrapy 来编写爬虫代码。
环境配置:
pip install scrapy 安装爬虫框架,scrapy安装容易遇到坑,scrapy教程与常见坑,不懂scrapy看链接。
scrapy startproject csblog 创建项目
scrapy gensider scblogSpider “csblogs.com” 创建爬虫文件
修改csblog下面的items.py
title:文章标题
read:阅读数
date:发帖时间
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class CnblogsItem(scrapy.Item):
title = scrapy.Field()
read = scrapy.Field()
date = scrapy.Field()
然后我们编写爬虫代码,首先审查下首页的html结构。
首先吐槽下翻页遇到的坑,https://www.cnblogs.com/#p4,表面看上去#p4是页码,但是多次尝试变化页码爬取,都无效果,始终为第一页。
经过调试工具查看请求才发现,这个url是被重写过得,想要翻页得这么发请求。

接下来就容易多了,向这个地址发请求,在返回的html中取得相应的数据就好了,贴代码。
# -*- coding: utf-8 -*-
import scrapy
from cnblogs.items import CnblogsItem
class CsblogSpider(scrapy.Spider):
name = 'csblog'
allowed_domains = ['cnblogs.com']
start_urls= ['https://www.cnblogs.com/mvc/AggSite/PostList.aspx']
PageIndex = 1
def start_requests(self):
url = self.start_urls[0]
#因为博客园只允许200页
for each in range(1,200):
print("抓取页码")
print(each)
post_data ={
'CategoryId':'808',
'CategoryType':"SiteHome",
'ItemListActionName':"PostList",
'PageIndex':str(each),
'ParentCategoryId':'0',
'TotalPostCount':'400'
}
yield scrapy.FormRequest(url=url, formdata=post_data)
def parse(self, response):
items = []
#所有文章都在<div class="post_item">中
for each in response.xpath("/html/body/div[@class='post_item']"):
#提取标题
title = each.xpath('div[@class="post_item_body"]/h3/a/text()').extract()
#提取发布日期
date = each.xpath('div[@class="post_item_body"]/div/text()').extract()
#提取阅读数
read = each.xpath('div[@class="post_item_body"]/div/span[@class="article_view"]/a/text()').extract()
title = title[0]
#去除无用的字符
date = str(date).replace("[' \\r\\n ', ' \\r\\n",'').replace(" \\r\\n ']","").replace("发布于 ","").lstrip()
read = read[0].replace("阅读(","").replace(")","")
item = CnblogsItem()
item['title'] = title
item['read'] = read
item['date'] = date
items.append(item)
return items
爬虫的代码很简单,这也是python的强大之处。
运行 scrapy crawl csblog -o data.xml 将爬取到的数据保存为xml。

我们已经将抓取到的数据保存到本地xml了,接下来要做的事情就是数据统计了。所谓“术业有专攻”,做统计没有比sql 更强大的语言了,python的任务到此结束。
- 数据存储
为了方便的对数据进项统计查询,我们把xml保存到MS Sql Server中,做个这个事情没有比Sql server的老伙计C#更合适的了,没啥好说的简简单单的几个方法。
static void Main(string[] args)
{
data d = (data)Deserialize(typeof(data), File.OpenRead(@"D:/MyCode/cnblogs/cnblogs/data.xml"));
DataTable dt = ToDataTable<data.item>(d.items);
dt.TableName = "t_article";
dt.Columns.Remove("date");
SqlHelper.ExecuteNonQuery(dt);
}
/// <summary>
/// Convert a List{T} to a DataTable.
/// </summary>
private static DataTable ToDataTable<T>(List<T> items)
{
var tb = new DataTable(typeof(T).Name);
PropertyInfo[] props = typeof(T).GetProperties(BindingFlags.Public | BindingFlags.Instance);
foreach (PropertyInfo prop in props)
{
Type t = GetCoreType(prop.PropertyType);
tb.Columns.Add(prop.Name, t);
}
foreach (T item in items)
{
var values = new object[props.Length];
for (int i = 0; i < props.Length; i++)
{
values[i] = props[i].GetValue(item, null);
}
tb.Rows.Add(values);
}
return tb;
}
/// <summary>
/// Determine of specified type is nullable
/// </summary>
public static bool IsNullable(Type t)
{
return !t.IsValueType || (t.IsGenericType && t.GetGenericTypeDefinition() == typeof(Nullable<>));
}
/// <summary>
/// Return underlying type if type is Nullable otherwise return the type
/// </summary>
public static Type GetCoreType(Type t)
{
if (t != null && IsNullable(t))
{
if (!t.IsValueType)
{
return t;
}
else
{
return Nullable.GetUnderlyingType(t);
}
}
else
{
return t;
}
}
/// 反序列化
/// </summary>
/// <param name="type"></param>
/// <param name="xml"></param>
/// <returns></returns>
public static object Deserialize(Type type, Stream stream)
{
XmlSerializer xmldes = new XmlSerializer(type);
return xmldes.Deserialize(stream);
}

数据已经成功的存储到sql server,接下来的数据统计是重头戏了。
- 数据统计
--200页码帖子总数量 select COUNT(*) from t_article

--查询的哪个时间段阅读量最多 --查询结果显示早9点阅读量是最多的,并不意外 --而早6点(5180)与7点(55144)相差了近10倍 --7点与8点相比差了也有三倍,这说明程序猿们陆续 --开始上班了,上班敲代码一定是查资料的高峰期, --果不其然,8,9,10,11,15,16是阅读量最高峰的几个时间段 --都分布在上班时间,而出乎意料的事22点的阅读量也不低 --看来程序猿们回家后也很努力的嘛(应该是在加班) select CONVERT(INT, CONVERT(varchar(2),time, 108)) as count, SUM([read]) as [read] from t_article group by CONVERT(INT, CONVERT(varchar(2),time, 108)) order by [read] desc

--查询阅读量在一个星期内的分布情况 --结果一点都不意外,星期三比另六天 --高得多,星期一到星期五是工作日 --每天的阅读量都很高,周末阅读量下滑 --的厉害,因为休息了嘛(居然没在加班) select datename(weekday, time) as weekday, SUM([read]) as [read] from t_article group by datename(weekday, time) order by [read] desc

--按照阅读数量排行 --阅读数量与发帖时间基本成正比 --这意味着,你辛辛苦苦写的文章 --没人看,没有关系。时间不会辜负你 select CONVERT(varchar(100), time, 111), sum([read]) from t_article group by CONVERT(varchar(100), time, 111) order by sum([read])

- 总结
阅读的最高峰时段是早9点,所以这也是发帖的最优时间,8,9,10都是不错的时间,如果你想要更多的阅读,不要错过呦。
阅读数量最少的是星期六跟星期日,这两天可以不用发帖了,可以给自己放个假。
阅读数量会随着时间慢慢变多,也就是说一开始没有阅读也没关系,只要帖子里有干货,随着时间推移依然还会有许多阅读从搜索引擎跳转过来,阅读量会慢慢上去的。
看完python这段爬虫代码,java流泪了c#沉默了
哈哈,其实很简单,寥寥几行代码网页爬一部小说,不卖关子,立刻开始。
首先安装所需的包,requests,BeautifulSoup4
控制台执行
pip install requests
pip install BeautifulSoup4
如果不能正确安装,请检查你的环境变量,至于环境变量配置,在这里不再赘述,相关文章有很多。
两个包的安装命令都结束后,输入pip list

可以看到,两个包都成功安装了。
好的,我们立刻开始编写代码。
我们的目标是抓取这个链接下所有小说的章节 https://book.qidian.com/info/1013646681#Catalog
我们访问页面,用chrome调试工具查看元素,查看各章节的html属性。我们发现所有章节父元素是<ul class="cf">这个元素,章节的链接以及标题,在子<li>下的<a>标签内。

那我们第一步要做的事,就是要提取所有章节的链接。
'用于进行网络请求'
import requests
chapter = requests.get("https://book.qidian.com/info/1013646681#Catalog")
print(chapter.text)

页面顺利的请求到了,接下来我们从页面中抓取相应的元素
'用于进行网络请求'
import requests
'用于解析html'
from bs4 import BeautifulSoup
chapter = requests.get("https://book.qidian.com/info/1013646681#Catalog")
ul_bs = BeautifulSoup(chapter.text)
'提取class为cf的ul标签'
ul = ul_bs.find_all("ul",class_="cf")
print(ul)

ul也顺利抓取到了,接下来我们遍历<ul>下的<a>标签取得所有章节的章节名与链接
'用于进行网络请求'
import requests
'用于解析html'
from bs4 import BeautifulSoup
chapter = requests.get("https://book.qidian.com/info/1013646681#Catalog")
ul_bs = BeautifulSoup(chapter.text)
'提取class为cf的ul标签'
ul = ul_bs.find_all("ul",class_="cf")
ul_bs = BeautifulSoup(str(ul[0]))
'找到<ul>下的<a>标签'
a_bs = ul_bs.find_all("a")
'遍历<a>的href属性跟text'
for a in a_bs:
href = a.get("href")
text = a.get_text()
print(href)
print(text)

ok,所有的章节链接搞定,我们去看想想章节详情页面长什么样,然后我们具体制定详情页面的爬取计划。
打开一个章节,用chrome调试工具审查一下。文章标题保存在<h3 class="j_chapterName">中,正文保存在<div class="read-content j_readContent">中。
我们需要从这两个标签中提取内容。

'用于进行网络请求'
import requests
'用于解析html'
from bs4 import BeautifulSoup
chapter = requests.get("https://book.qidian.com/info/1013646681#Catalog")
ul_bs = BeautifulSoup(chapter.text)
'提取class为cf的ul标签'
ul = ul_bs.find_all("ul",class_="cf")
ul_bs = BeautifulSoup(str(ul[0]))
'找到<ul>下的<a>标签'
a_bs = ul_bs.find_all("a")
detail = requests.get("https:"+a_bs[0].get("href"))
text_bs = BeautifulSoup(detail.text)
text = text_bs.find_all("div",class_ = "read-content j_readContent")
print(text)

正文页很顺利就爬取到了,以上代码仅是用第一篇文章做示范,通过调试文章已经可以爬取成功,所有下一步我们只要把所有链接遍历逐个提取就好了
'用于进行网络请求'
import requests
'用于解析html'
from bs4 import BeautifulSoup
chapter = requests.get("https://book.qidian.com/info/1013646681#Catalog")
ul_bs = BeautifulSoup(chapter.text)
'提取class为cf的ul标签'
ul = ul_bs.find_all("ul",class_="cf")
ul_bs = BeautifulSoup(str(ul[0]))
'找到<ul>下的<a>标签'
a_bs = ul_bs.find_all("a")
'遍历所有<href>进行提取'
for a in a_bs:
detail = requests.get("https:"+a.get("href"))
d_bs = BeautifulSoup(detail.text)
'正文'
content = d_bs.find_all("div",class_ = "read-content j_readContent")
'标题'
name = d_bs.find_all("h3",class_="j_chapterName")[0].get_text()
在上图中我们看到正文中的每一个<p>标签为一个段落,提取的文章包含很多<p>标签这也是我们不希望的,接下来去除p标签。
但是去除<p>标签后文章就没有段落格式了呀,这样的阅读体验很不爽的,我们只要在每个段落的结尾加一个换行符就好了
'用于进行网络请求'
import requests
'用于解析html'
from bs4 import BeautifulSoup
chapter = requests.get("https://book.qidian.com/info/1013646681#Catalog")
ul_bs = BeautifulSoup(chapter.text)
'提取class为cf的ul标签'
ul = ul_bs.find_all("ul",class_="cf")
ul_bs = BeautifulSoup(str(ul[0]))
'找到<ul>下的<a>标签'
a_bs = ul_bs.find_all("a")
'遍历所有<href>进行提取'
for a in a_bs:
detail = requests.get("https:"+a.get("href"))
d_bs = BeautifulSoup(detail.text)
'正文'
content = d_bs.find_all("div",class_ = "read-content j_readContent")
'标题'
name = d_bs.find_all("h3",class_="j_chapterName")[0].get_text()
txt = ""
p_bs = BeautifulSoup(str(content))
'提取每个<p>标签的内容'
for p in p_bs.find_all("p"):
txt = txt + p.get_text()+"\r\n"
去掉<p>标签了,所有的工作都做完了,我们只要把文章保存成一个txt就可以了,txt的文件名以章节来命名。
'用于进行网络请求'
import requests
'用于解析html'
from bs4 import BeautifulSoup
def create_txt(path,txt):
fd = None
try:
fd = open(path,'w+',encoding='utf-8')
fd.write(txt)
except:
print("error")
finally:
if (fd !=None):
fd.close()
chapter = requests.get("https://book.qidian.com/info/1013646681#Catalog")
ul_bs = BeautifulSoup(chapter.text)
'提取class为cf的ul标签'
ul = ul_bs.find_all("ul",class_="cf")
ul_bs = BeautifulSoup(str(ul[0]))
'找到<ul>下的<a>标签'
a_bs = ul_bs.find_all("a")
'遍历所有<href>进行提取'
for a in a_bs:
detail = requests.get("https:"+a.get("href"))
d_bs = BeautifulSoup(detail.text)
'正文'
content = d_bs.find_all("div",class_ = "read-content j_readContent")
'标题'
name = d_bs.find_all("h3",class_="j_chapterName")[0].get_text()
path = 'F:\\test\\'
path = path + name+".txt"
txt = ""
p_bs = BeautifulSoup(str(content))
'提取每个<p>标签的内容'
for p in p_bs.find_all("p"):
txt = txt + p.get_text()+"\r\n"
create_txt(path,txt)
print(path+"保存成功")

图片二进制转换与存入数据库相关
关于转换问题,刚开始我需要从数据库读出一个二进制数据流,并将其转换成一个Image格式。
在不涉及数据库的情况下,我先将一个图片转换成一个二进制数组显示出来,再写一个方法将其转换成图片image格式。
一、 先不涉及数据库,将图片转换成二进制,在将二进制转换成图片。
1.protected void Button1_Click(object sender, EventArgs e)
{
string str = null;
PictureToBinary ptb = new PictureToBinary();
// str = Convert.ToBase64String( ptb.Data("E:/workspace/asp/TEST/PictureTurnToBinary/PictureTurnToBinary/img/Tulips.jpg"));
Image newImage = Image.FromFile(Server.MapPath("Tulips.jpg"));
str =Convert.ToBase64String( ptb.PhotoImageInsert(newImage));
Label1.Text = str;
//label可以用response代替(response.write(str);)
}
第一步,我将图片转换成二进制数组,并转换成string格式,用一个Label展现(也可以用Response直接输出到页面显示)。产生的数组并不是二进制构成的数据流而是一串字节,如下:

所以建议先将图片压缩一下,不然会很大。
第二步,将得到的二进制字节码转换为图片格式。
2. protected void Button2_Click(object sender, EventArgs e)
{
PictureToBinary ptb = new PictureToBinary();
Image newImage = Image.FromFile(Server.MapPath("Tulips.jpg"));
WritePhoto(ptb.PhotoImageInsert(newImage));
}
//图片输出到页面
public void WritePhoto(byte[] streamByte)
{
Response.ContentType = "image/JPEG";
Response.BinaryWrite(streamByte);
}
public class PictureToBinary
{
public PictureToBinary()
{
//
// TODO: 在此处添加构造函数逻辑
//
}
public byte[] PhotoImageInsert(System.Drawing.Image imgPhoto)
{
//将Image转换成二进制流数据
MemoryStream mstream = new MemoryStream();
imgPhoto.Save(mstream, System.Drawing.Imaging.ImageFormat.Bmp);
byte[] myData = new Byte[mstream.Length];
mstream.Position = 0;
mstream.Read(myData, 0, myData.Length);
mstream.Close();
return myData;
}
}
结果如下:

二、将得到的二进制数据保存到数据库,再将其读出。
需要用到这么几个控件:一个fileLoad控件,两个按钮,分别是存入和读取。

存入图片到数据库:
protected void Saveintodatabase_Click(object sender, EventArgs e)
{
//将图片保存到数据库
//加载文件,并以字节数组格式存入数据库
HttpPostedFile loadPhoto = FileUpload1.PostedFile;
//获取记载图片内容长度
int photoLength = loadPhoto.ContentLength;
//存为字节数组
byte[] photoArray = new byte[photoLength];
Stream photoStream = loadPhoto.InputStream;
photoStream.Read(photoArray, 0, photoLength);
//连接数据库读取文件
SqlConnection conn = new SqlConnection();
conn.ConnectionString = "Data Source=localhost;Database=Test;User Id=sa;Pwd=123456789";
string sql = "insert into Test_Picture values(@image,3)";
SqlCommand cmd = new SqlCommand(sql,conn);
cmd.CommandType = System.Data.CommandType.Text;
cmd.Parameters.Add("@image",SqlDbType.Image);
cmd.Parameters["@image"].Value = photoArray;
conn.Open();
//执行sql,成功执行返回1,否则返回0(insert,update,delete),其他命令返回-1
int row = cmd.ExecuteNonQuery();
Response.Write(row);
conn.Close();
}
读取文件:
protected void PhotoShowInWebSite_Click(object sender, EventArgs e)
{
//读取数据库图片文件,并保存到本地。
SqlConnection conn = new SqlConnection();
conn.ConnectionString = "Data Source=localhost;Database=Test;User Id=sa;Pwd=123456789";
//选择你需要的字段值,这边就直接赋值了
string sql = "select Picture from Test_Picture where Number = 3";
SqlCommand cmd = new SqlCommand(sql, conn);
byte[] MyData = new byte[0];
try
{
conn.Open();
SqlDataReader mySqlDataReader;
mySqlDataReader = cmd.ExecuteReader(CommandBehavior.CloseConnection);
if (mySqlDataReader.Read())
{
Response.Clear();
Response.ContentType = "image/JPEG";
Response.BinaryWrite((byte[])mySqlDataReader["Picture"]);
/*将图片写入到本地d盘
//图片字节流
MyData = (byte[])mySqlDataReader["Picture"];
int ArraySize = MyData.GetUpperBound(0);
FileStream fs = new FileStream(@"d:\02.jpg", FileMode.OpenOrCreate, FileAccess.Write);
fs.Write(MyData, 0, ArraySize);
fs.Close();
*/
}
} catch (SqlException SQLexc)
{
Response.Write(SQLexc.ToString());
}
conn.Close();
}
以上为整理的为图片二进制转换与存取数据库相关的内容。
C#7.0--引用返回值和引用局部变量
一、在C#7.0以上版本中,方法的返回值可以通过关键字ref指定为返回变量的引用(而不是值)给调用方,这称为引用返回值(Reference Return Value,或ref returns);
1.与引用参数一样,使用关键字ref声明引用返回值:
public ref int MyFunc(int[] nums)
{
//do…
return ref nums[0];
}
2.使用引用返回值避免了值类型在方法返回时的浅拷贝操作,提高了效率;
3.使用引用返回值通常是为了让调用方有权访问(和修改)此变量,因此引用返回值不支持无返回值方法(即返回值类型为void);
引用返回值所返回变量指向对象的生命周期必须大于方法,即不能返回指向值类型局部变量的变量(值类型局部变量会在方法执行完返回时进行回收),可以返回指向引用类型局部变量的变量、传递给方法的引用参数、静态字段和实例字段;
※引用返回值不可以返回字面量、常量、枚举或按值返回的方法、属性,但可以返回当前值为null的符合上述条件的变量;
※异步方法不能使用引用返回值,因为异步方法可能会在执行尚未完成且返回值未知时就返回;
4.查看声明引用返回值方法的IL代码:
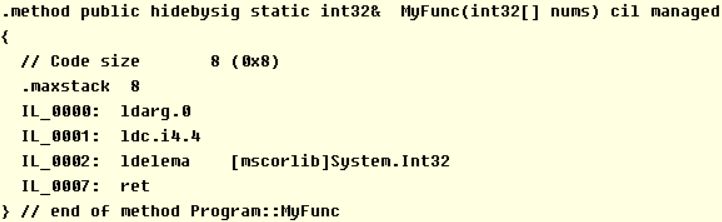
5.在调用引用返回值的方法时,调用方可以选择将方法返回的变量当作按值返回或是按引用返回处理,如果是按值返回处理,则与调用普通方法一样:
int[] myNums = new int[] { 1, 2, 3, 4, 5 };
int myNum = MyFunc(myNums);
6.如果是按引用返回处理,则调用方需要使用引用局部变量(Reference Local Variable,或ref locals)接收,保留对方法返回变量的引用:
ref int myNum = ref MyFunc(myNums);
二、可以使用关键字ref声明引用局部变量、初始化引用局部变量及调用引用返回值的方法:
ref int myNum = ref myNums[0]; //此时引用局部变量myNum保存的是数组myNums中索引0的内存地址
1.使用引用局部变值避免了值类型在赋值时的浅拷贝操作,提高了效率;
2.引用局部变量必须在声明时进行初始化,初始化时会确认该引用局部变量的作用范围,这个作用范围决定该引用局部变量能否作为引用返回值返回;
对引用局部变量的赋值操作,将直接改变该变量所指向内存地址中对象的值:
myNum = 10; Console.WriteLine(myNums[0]); //10
3.对引用局部变量的读取操作与普通局部变量一样,将访问该变量所指向内存地址中对象的值:
int num = myNum + 10; //20
4.引用局部变量可以作为引用参数的实参传递,同样需要使用修饰符ref修饰,对于给定的方法:
public void MyFunc(ref int num) { }
//使用时:
MyFunc(ref myNum);
5.在C#7.3以上版本中,可以对引用局部变量重新分配其它引用:
myNum = ref MyFunc(myNums);
※给引用局部变量重新分配不能改变该引用局部变量在声明时确认的作用范围,因此不能给一个作用范围较大的局部引用变量赋值一个作用范围较小的变量;
一、操作系统用进程(Processe)分隔正在执行的程序,用线程(Thread)作为操作系统分配处理器时间的基本单元,进程上下文中可以运行多个线程,进程的所有线程共享其虚拟地址空间,所有线程均可执行程序代码中的任意部分,包括其他线程正在执行的代码;
1.默认情况下,.NET程序只启动单个线程,被称为主线程(Primary Thread),也可以在运行时开启其它线程,与主线程并行同时执行代码,这些线程被称为工作线程(Worker Thread);由.Net开启和管理的线程通常称为托管线程(Managed Thread);
2.托管线程又分为前台线程和后台线程,两者类似,但前台线程会阻止进程停止,而后台线程不会,即当进程的Main方法结束后,只有在所有前台线程都停止时,CLR才会结束该进程,此时会对仍处于活动状态的后台线程调用Abort方法来结束所有后台进程;
※关闭程序如遇到无法关闭所有线程时,可以在Main方法结束前通过以下代码强制关闭所有线程,详见:
System.Environment.Exit(0);
二、在使用多线程时,不同线程不仅可以同时执行同一段代码,还可以同时访问同一内存中的数据,所以会存在一定的数据冲突问题,称为争用条件(Race Condition):
static int MyNum;
static int RaceConditionCount;
static void MyFunc()
{
while (true)
{
if (MyNum == 0)
{
MyNum++;
if (MyNum == 0)
{
RaceConditionCount++; //只有在出现争用条件时才会执行此语句
}
}
MyNum = 0;
}
}
static void Main(string[] args)
{
for (int i = 0; i < 2; i++)
{
Thread thread = new Thread(MyFunc);
thread.Start();
}
Thread.Sleep(1000);
Console.WriteLine(RaceConditionCount); //输出1秒内产生争用条件的次数
Console.Read();
}
1.对于争用条件的发生频率,发布版本比调试版本的出现次数多(发布版本编译出的代码被优化过而且开启了JIT优化),多核CPU比单核CPU的出现次数多(多核CPU中多个线程可以同时运行,单核CPU的线程调度是抢占式的,也会出现此问题,只是次数较少);
三、为了避免产生争用条件,需要注意数据的同步问题,可以通过给对象加锁,使同一时间内只有一个线程可以执行加锁对象所锁定的代码;
JS直接调用C#后台方法(ajax调用)
1. 先手动引用DLL或者通过NuGet查找引用,这里提供一个AjaxPro.2.dll的下载;
2. 之后的的过程不想写了,网上都大同小异的,直接参考以前大佬写的:
AjaxPro2完整入门教程
Linq To Json
using Newtonsoft.Json.Linq;
/// <summary>
/// 递归生成部门树
/// </summary>
/// <param name="depList">部门列表</param>
/// <param name="parentId">用户部门的父级部门Id</param>
/// <returns></returns>
private JArray ConvertDepartTree(IList<AspSysDepartmentDto> depList, int parentId)
{
var jArray = new JArray(from a in depList
where a.ParentId == parentId
select new JObject(
new JProperty("id", a.Id),
new JProperty("text", a.Name),
new JProperty("children", ConvertDepartTree(depList, a.Id)
)));
return jArray;
}
JSON.net Linq To Json文档地址:https://www.newtonsoft.com/json/help/html/CreatingLINQtoJSON.htm
SqlServer 递归查询
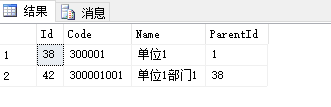
--查询部门及下属部门列表
WITH TEMP --递归
AS (SELECT Id,
Code,
Name,
ParentId
FROM [dbo].[AspSysDepartments]
WHERE Id = 38 --查询当前部门
UNION ALL
SELECT B.Id, --查询子部门
B.Code,
B.Name,
B.ParentId
FROM TEMP A
INNER JOIN [dbo].[AspSysDepartments] B
ON B.ParentId = A.Id)
SELECT Id,
Code,
Name,
ParentId
FROM TEMP --获取递归后的集合
结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号